BDL Benchmarks

Project description
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
Our BDL benchmarks should
- provide a transparent, modular and consistent interface for the evaluation of deep probabilistic models on a variety of downstream tasks;
- rely on expert-driven metrics of uncertainty quality (actual applications making use of BDL uncertainty in the real-world), but abstract away the expert-knowledge and eliminate the boilerplate steps necessary for running experiments on real-world datasets;
- make it easy to compare the performance of new models against well tuned baselines, models that have been well-adopted by the machine learning community, under a fair and realistic setting (e.g., computational resources, model sizes, datasets);
- provide reference implementations of baseline models (e.g., Monte Carlo Dropout Inference, Mean Field Variational Inference, Deep Ensembles), enabling rapid prototyping and easy development of new tools;
- be independent of specific deep learning frameworks (e.g., not depend on
TensorFlow,PyTorch, etc.), and integrate with the SciPy ecosystem (i.e.,NumPy,Pandas,Matplotlib). Benchmarks are framework-agnostic, while baselines are framework-dependent.
In this repo we strive to provide such well-needed benchmarks for the BDL community, and collect and maintain new baselines and benchmarks contributed by the community. A colab notebook demonstrating the MNIST-like workflow of our benchmarks is available here.
We highly encourage you to contribute your models as new baselines for others to compete against, as well as contribute new benchmarks for others to evaluate their models on!
List of Benchmarks
Bayesian Deep Learning Benchmarks (BDL Benchmarks or bdlb for short), is an open-source framework that aims to bridge the gap between the design of deep probabilistic machine learning models and their application to real-world problems. Our currently supported benchmarks are:
-
Diabetic Retinopathy Diagnosis (in
alpha, following Leibig et al.)- Deterministic
- Monte Carlo Dropout (following Gal and Ghahramani, 2015)
- Mean-Field Variational Inference (following Peterson and Anderson, 1987, Wen et al., 2018)
- Deep Ensembles (following Lakshminarayanan et al., 2016)
- Ensemble MC Dropout (following Smith and Gal, 2018)
-
Autonomous Vehicle's Scene Segmentation (in
pre-alpha, following Mukhoti et al.) -
Galaxy Zoo (in
pre-alpha, following Walmsley et al.) -
Fishyscapes (in
pre-alpha, following Blum et al.)
Installation
BDL Benchmarks is shipped as a PyPI package (Python3 compatible) installable as:
pip3 install git+https://github.com/OATML/bdl-benchmarks.git
The data downloading and preparation is benchmark-specific, and you can follow the relevant guides at baselines/<benchmark>/README.md (e.g. baselines/diabetic_retinopathy_diagnosis/README.md).
Examples
For example, the Diabetic Retinopathy Diagnosis benchmark comes with several baselines, including MC Dropout, MFVI, Deep Ensembles, and more. These models are trained with images of blood vessels in the eye:
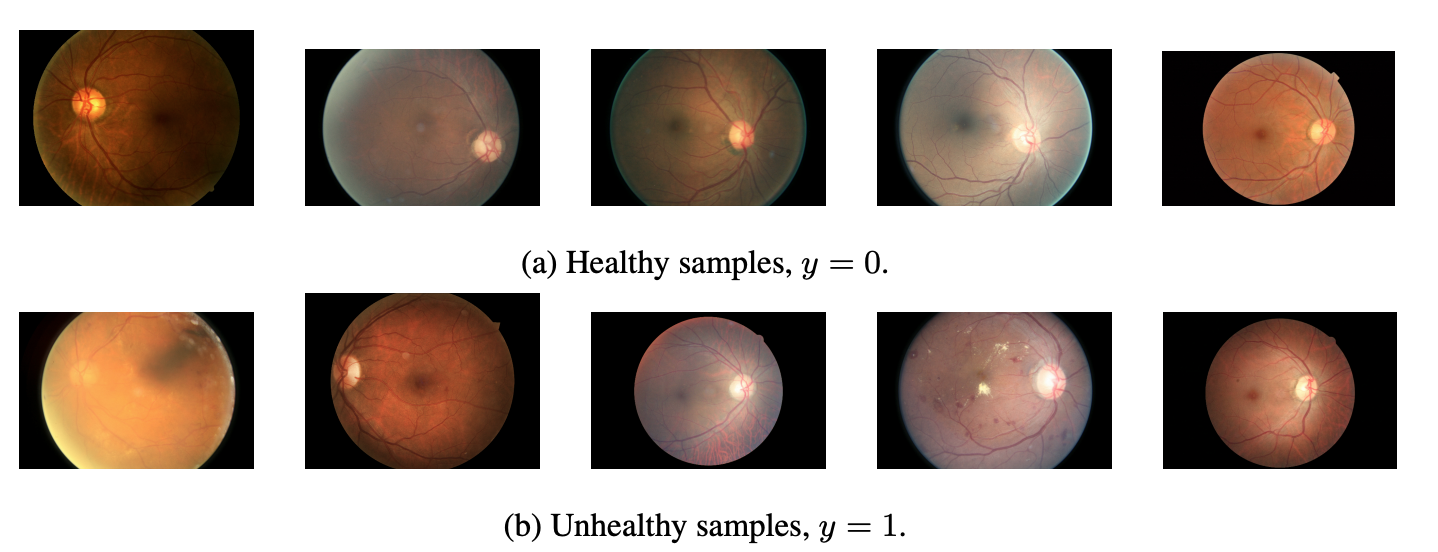
The models try to predict diabetic retinopathy, and use their uncertainty for prescreening (sending patients the model is uncertain about to an expert for further examination). When you implement a new model, you can easily benchmark your model against existing baseline results provided in the repo, and generate plots using expert metrics (such as the AUC of retained data when referring 50% most uncertain patients to an expert):
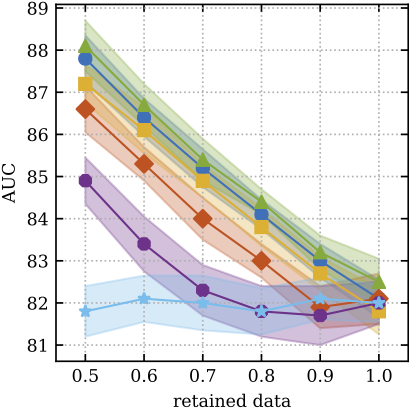
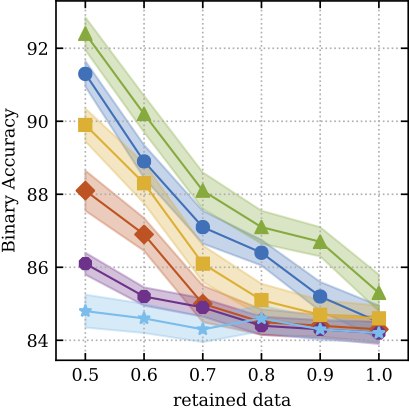

You can even play with a colab notebook to see the workflow of the benchmark, and contribute your model for others to benchmark against.
Cite as
Please cite individual benchmarks when you use these, as well as the baselines you compare against. For the Diabetic Retinopathy Diagnosis benchmark please see here.
Contact Us
The repository is developed and maintained by the Oxford Applied and Theoretical Machine Learning group. Email us for questions or submit any issues to improve the framework.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file bdl-benchmarks-0.0.1.tar.gz.
File metadata
- Download URL: bdl-benchmarks-0.0.1.tar.gz
- Upload date:
- Size: 15.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3ba3230ad1264e0c699b8bf3d58669259da38b2cd0821f1739d5013deb633d4e
|
|
| MD5 |
ab9994b878121f9b2a19bbe0e0162d05
|
|
| BLAKE2b-256 |
68eec4d21ecd4d7dd05fca8b5bd85d57ddd3f0fd7f5dd3b2b35af771e8b76be2
|







