Black Box optimization library.

Project description
benderopt
benderopt is a black box optimization library.
GitHub repo: https://github.com/vthorey/benderopt/
For asynchronous use, a web client using this library is available in open access at bender.dreem.com
The algorithm implemented "parzen_estimator" is similar to TPE described in: Bergstra, James S., et al. “Algorithms for hyper-parameter optimization.” Advances in Neural Information Processing Systems.
Installation
pip install benderopt
or from the sources
Demo
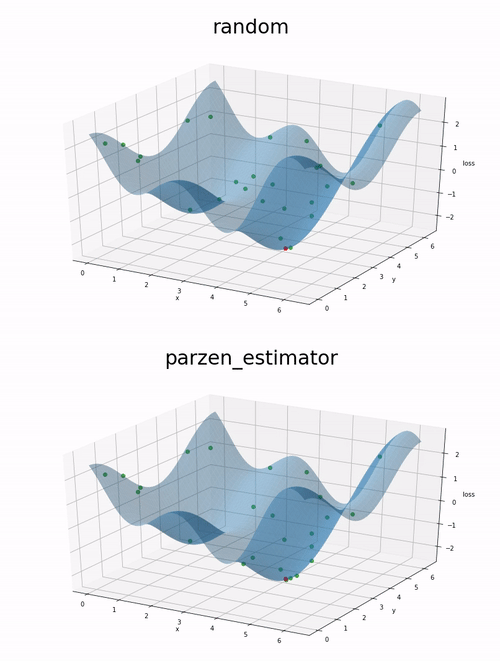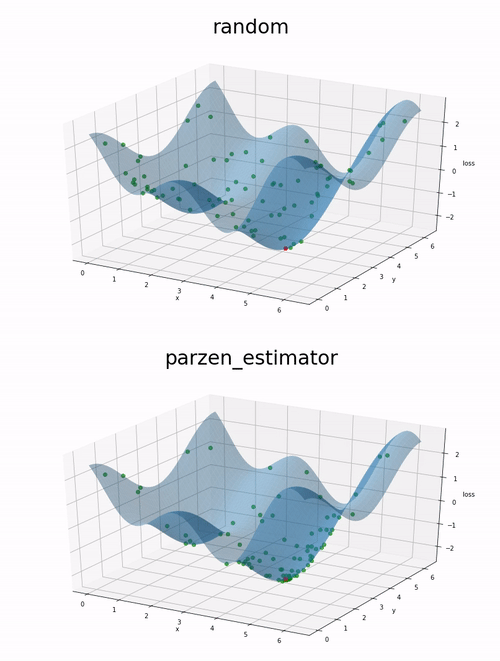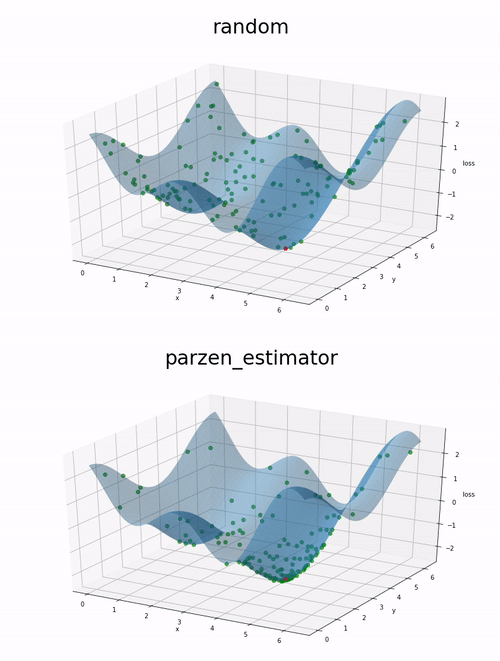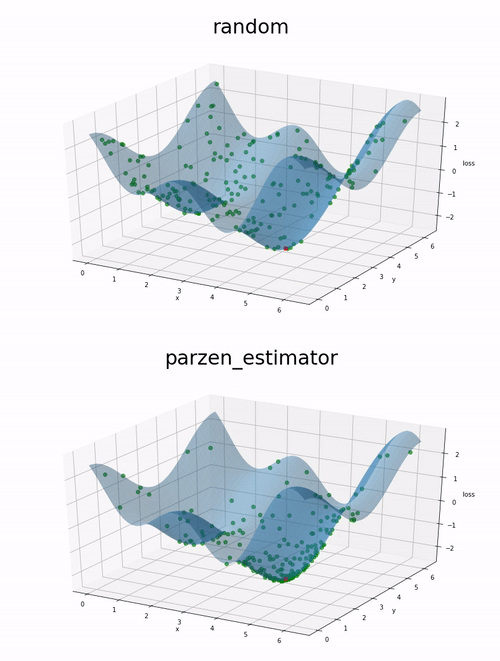
Here is a comparison on 200 evaluations of a function we want to minimize. First a random estimator is used to select random evaluation point. Then the parzen_estimator implemented in benderopt is used to select evaluation points.
The function to minimize is the following: cos(x) + cos(2 * x + 1) + cos(y).
The red point correspond to the location of the global minima between 0 and 2pi for x and y.
The code to generate the video can be found in benchmark/benchmark_sinus2D
We can observe on this example that the parzen estimator tends to explore more the local minimum than the random approach. This might lead to a better optimization given a fixed number of evaluations.
The goal
In Black box optimization, we have a function to optimize but cannot compute the gradient, and evaluation is expensive in term of time / ressource. So we want to find a good exploration-exploitation trade off to get the best hyperparameters in as few evaluations as possible. Use case are:
- Optimization of a machine learning model (number of layers of a neural network, function of activation, etc.
- Business optimization (marketing campain, a/b testing)
Code Minimal Example
One of the advantage of benderopt is that it uses JSON-like object representation making it easier for a user to define parameters to optimize. This also allows an easy to integratation with an asynchrounous system such as bender.dreem.com.
Here is a minimal example.
from benderopt import minimize
import numpy as np
import logging
logging.basicConfig(level=logging.DEBUG) # logging.INFO will print less information
# We want to minimize the sinus function between 0 and 2pi
def f(x):
return np.sin(x)
# We define the parameters we want to optimize:
optimization_problem_parameters = [
{
"name": "x",
"category": "uniform",
"search_space": {
"low": 0,
"high": 2 * np.pi,
}
}
]
# We launch the optimization
best_sample = minimize(f, optimization_problem_parameters, number_of_evaluation=50)
print(best_sample["x"], 3 * np.pi / 2)
> 4.710390692396651 4.71238898038469
Minimal Documentation:
Optimization Problem
An optimization problem contains:
- A list of parameters (i.e. parameters with their search space)
- A list of observation (i.e. values for each parameter of the list and a corresponding loss)
We use JSON-like representation for each of them e.g.
optimization_problem_data = {
"parameters": [
{
"name": "parameter_1",
"category": "uniform",
"search_space": {"low": 0, "high": 2 * np.pi, "step": 0.1}
},
{
"name": "parameter_2",
"category": "categorical",
"search_space": {"values": ["a", "b", "c"]}
}
],
"observations": [
{
"sample": {"parameter_1": 0.4, "parameter_2": "a"},
"loss": 0.08
},
{
"sample": {"parameter_1": 3.4, "parameter_2": "a"},
"loss": 0.1
},
{
"sample": {"parameter_1": 4.1, "parameter_2": "c"},
"loss": 0.45
},
]
}
Optimizer
An optimizer takes an optimization problem and suggest new_predictions. In other words, an optimizer takes a list of parameters with their search space and a history of past evaluations to suggest a new one.
Using the optimization_problem_data from the previous example:
from benderopt.base import OptimizationProblem, Observation
from benderopt.optimizer import optimizers
optimization_problem = OptimizationProblem.from_json(optimization_problem_data)
optimizer = optimizers["parzen_estimator"](optimization_problem)
sample = optimizer.suggest()
print(sample)
> {"parameter_1": 3.9, "parameter_2": "b"}
Optimizers currently available are random and parzen_estimator.
Benderopt allows to add a new optimizer really easily by inheriting an optimizer from BaseOptimizer class.
You can check benderopt/optimizer/random.py for a minimal example.
Minimize function
Minimize function shown above in the minimal example section implementation is quite strateforward:
optimization_problem = OptimizationProblem.from_list(optimization_problem_parameters)
optimizer = optimizers["parzen_estimator"](optimization_problem)
for _ in range(number_of_evaluation):
sample = optimizer.suggest()
loss = f(**sample)
observation = Observation.from_dict({"loss": loss, "sample": sample})
optimization_problem.add_observation(observation)
The optimization_problem's observation history list is extended with a new observations at each iteration. This allows the optimizer to take them into account for the next suggestion.
Uniform Parameter
| parameter | type | default | comments |
|---|---|---|---|
| low | mandatory | - | lowest possible value: all values will be greater than or equal to low |
| high | mandatory | - | highest value: all values will be stricly less than high |
| step | optionnal | None | discretize the set of possible values: all values will follow 'value = low + k * step with k belonging to [0, K]' |
e.g.
{
"name": "x",
"category": "uniform",
"search_space": {
"low": 0,
"high": 2 * np.pi,
# "step": np.pi / 8
}
}
Log-Uniform Parameter
| parameter | type | default | comments |
|---|---|---|---|
| low | mandatory | - | lowest possible value: all values will be greater than or equal to low |
| high | mandatory | - | highest value: all values will be stricly less than high |
| step | optionnal | None | "discretize the set of possible values: all values will follow 'value = low + k * step with k belonging to [0, K]'" |
| base | optional | 10 | logarithmic base to use |
e.g.
{
"name": "x",
"category": "loguniform",
"search_space": {
"low": 1e-4,
"high": 1e-2,
# "step": 1e-5,
# "base": 10,
}
}
Normal Parameter
| parameter | type | default | comments |
|---|---|---|---|
| low | optionnal | -inf | lowest possible value: all values will be greater than or equal to low |
| high | optionnal | inf | highest value: all values will be stricly less than high |
| mu | mandatory | - | mean value: all values will be initially drawn following a gaussian centered at mu with sigma variance |
| sigma | mandatory | - | sigma value: all values will be initially drawn following a gaussian centered at mu with sigma variance |
| step | optionnal | None | "discretize the set of possible values: all values will follow 'value = low + k * step with k belonging to [0, K]'" |
e.g.
{
"name": "x",
"category": "normal",
"search_space": {
# "low": 0,
# "high": 10,
"mu": 5,
"sigma": 1
# "step": 0.01,
}
}
Log-Normal Parameter
| parameter | type | default | comments |
|---|---|---|---|
| low | optionnal | -inf | lowest possible value: all values will be greater than or equal to low |
| high | optionnal | inf | highest value: all values will be stricly less than high |
| mu | mandatory | - | mean value: all values will be initially drawn following a gaussian centered at mu with sigma variance |
| sigma | mandatory | - | sigma value: all values will be initially drawn following a gaussian centered at mu with sigma variance |
| step | optionnal | None | "discretize the set of possible values: all values will follow 'value = low + k * step with k belonging to [0, K]'" |
| base | optional | 10 | logarithmic base to use |
e.g.
{
"name": "x",
"category": "lognormal",
"search_space": {
# "low": 1e-6,
# "high": 1e0,
"mu": 1e-3,
"sigma": 1e-2
# "step": 1e-7,
# "base": 10,
}
}
Categorical Parameter
| parameter | type | default | comments |
|---|---|---|---|
| values | mandatory | - | list of categories: all values will be sampled from this list |
| probabilities | optionnal | number_of_values * [1 / number_of_values] | list of probabilities: all values will be initially drawn following this probability list |
e.g.
{
"name": "x",
"category": "categorical",
"search_space": {
"values": ["a", "b", "c", "d"],
# "probabilities": [0.1, 0.2, 0.2, 0.2, 0.3]
}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file benderopt-1.4.2.tar.gz.
File metadata
- Download URL: benderopt-1.4.2.tar.gz
- Upload date:
- Size: 19.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df8825097dabd906844c2444ff649539a54b661a9a388b304ad9dc5262b99a16
|
|
| MD5 |
e1922182a56b5083e7612b565478868a
|
|
| BLAKE2b-256 |
3e12c70a0e5500e3348a01611b9fea9b9641c1ba9a537b929321d9e089bbe87f
|
File details
Details for the file benderopt-1.4.2-py3-none-any.whl.
File metadata
- Download URL: benderopt-1.4.2-py3-none-any.whl
- Upload date:
- Size: 25.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cb0cc8d518e386403b0ade941edd6780c770ef3a0a3488ff80df09bb8cba1148
|
|
| MD5 |
f8e9004b99d9e9c6c9692a01ec057c23
|
|
| BLAKE2b-256 |
d913f3ca9f3cf99d9445586e8d915abf1ceec7d14f8fa1089c7b376e0ae6d0d3
|







