Multi-tier exact-match cache for AI agent workloads backed by Valkey. LLM responses, tool results, and session state with built-in OpenTelemetry and Prometheus instrumentation.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
betterdb-agent-cache





A standalone, framework-agnostic, multi-tier exact-match cache for AI agent workloads backed by Valkey (or Redis). Three cache tiers behind one connection: LLM responses, tool results, and session state. Built-in OpenTelemetry tracing and Prometheus metrics. No modules required — works on vanilla Valkey 7+, ElastiCache, Memorystore, MemoryDB, and any Redis-compatible endpoint.
See it live in BetterDB Monitor
BetterDB Monitor auto-discovers every betterdb-agent-cache instance on your Valkey - zero configuration, the library already registers itself - and turns its stats into live dashboards:
- AI Cache & Memory - hit rate, cost saved, evictions, and index size across all your caches and memory stores, with history.
- AI Traces - OpenTelemetry waterfalls for each request, correlated with live Valkey state to explain every cache hit and miss.
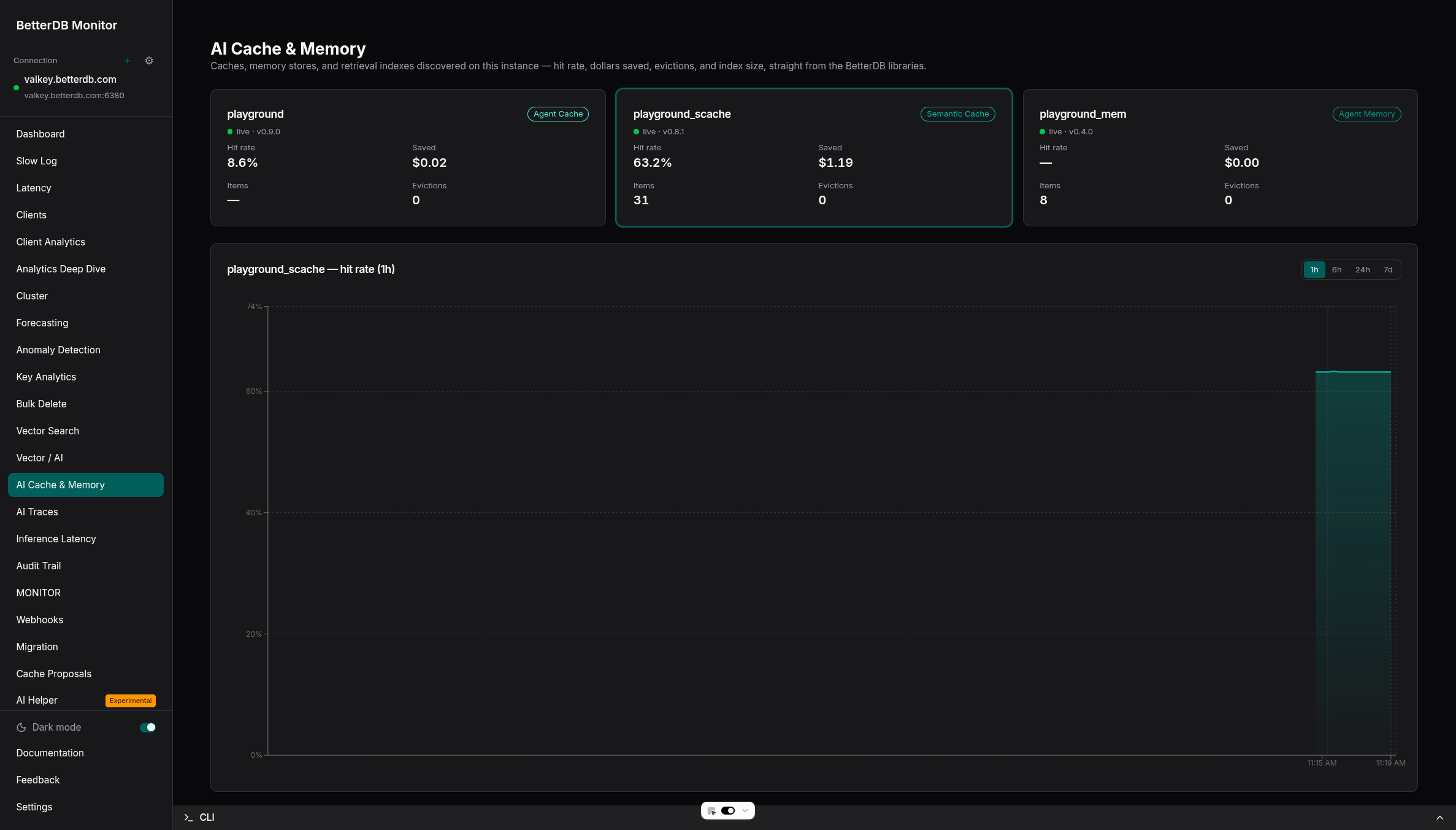
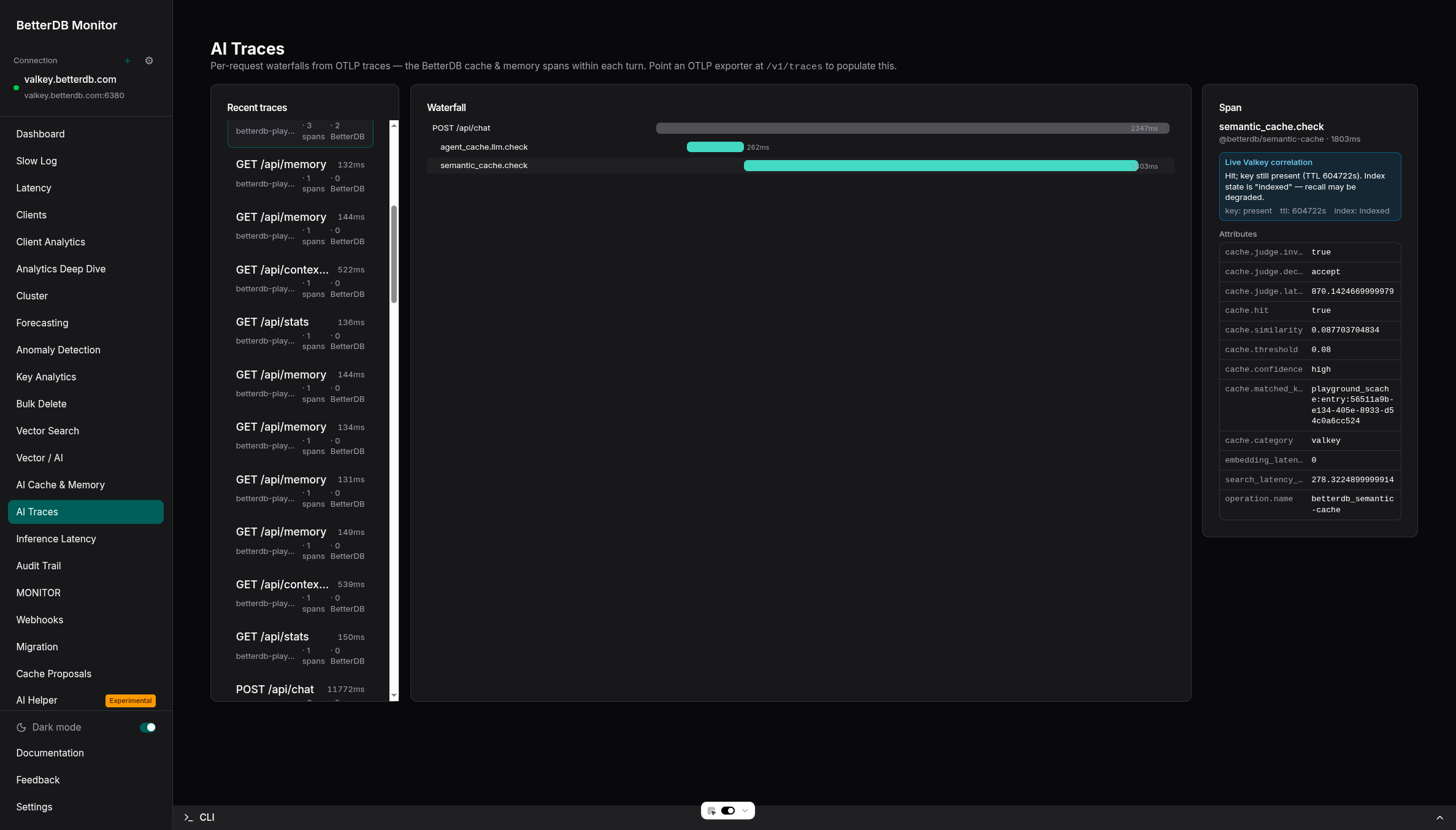
Run it self-hosted (docker run -p 3001:3001 betterdb/monitor), or use BetterDB Cloud - which can also provision a managed, TLS-enabled Valkey instance (Search module included) in one click.
Prerequisites
- Valkey 7+ or Redis 6.2+ (no modules, no RediSearch, no RedisJSON)
- Or Amazon ElastiCache for Valkey / Redis
- Or Google Cloud Memorystore for Valkey
- Or Amazon MemoryDB
- Python >= 3.11
Installation
pip install betterdb-agent-cache
Optional extras install the provider SDKs alongside the library:
pip install "betterdb-agent-cache[openai]"
pip install "betterdb-agent-cache[openai_agents]"
pip install "betterdb-agent-cache[anthropic]"
pip install "betterdb-agent-cache[langchain]"
pip install "betterdb-agent-cache[langgraph]"
pip install "betterdb-agent-cache[llamaindex]"
Why betterdb-agent-cache
As of 2026, no existing caching solution for AI agents provides all three of the following: multi-tier caching (LLM responses, tool results, and session state in one package), built-in observability (OpenTelemetry spans and Prometheus metrics at the cache operation level), and no module requirements (works on vanilla Valkey without RedisJSON or RediSearch). This package fills that gap.
| Capability | betterdb-agent-cache | LangChain RedisCache | LangGraph checkpoint-redis | LiteLLM Redis |
|---|---|---|---|---|
| Multi-tier (LLM + Tool + State) | ✅ | ❌ LLM only | ❌ State only | ❌ LLM only |
| Built-in OTel + Prometheus | ✅ | ❌ | ❌ | ⚠️ Partial |
| No modules required | ✅ | ✅ | ❌ Requires Redis 8 + modules | ✅ |
| Framework adapters | ✅ OpenAI, OpenAI Agents SDK, Anthropic, LangChain, LangGraph, LlamaIndex | ❌ LangChain only | ❌ LangGraph only | ❌ LiteLLM proxy only |
Design tradeoffs
Individual keys vs Redis hashes for session state
Session fields are stored as individual Valkey keys ({name}:session:{threadId}:{field}), not as fields inside a single Redis HASH per thread. This allows per-field TTL and atomic operations on individual fields, which matters when different parts of agent state have different freshness requirements. The trade-off is that get_all() and destroy_thread() require a SCAN + pipeline instead of a single HGETALL or DEL. For typical agent sessions with dozens of fields, this is negligible.
Plain JSON strings vs RedisJSON for LangGraph checkpoints
The LangGraph adapter stores checkpoints as plain JSON strings via SET/GET, not via RedisJSON path operations. This is the decision that makes the adapter work on vanilla Valkey 7+ and every managed service without module configuration. The trade-off is that list() with filtering requires SCAN + parse instead of indexed queries. For typical checkpoint volumes (hundreds to low thousands per thread), this is fast enough.
Counter-based stats vs event streams
Cache statistics are stored as atomic counters in a single Valkey hash (HINCRBY), not as event streams. This means rates are computed by diffing counter values over time windows rather than reading individual events. The trade-off is no per-request event detail — you get aggregate hit rates and cost savings, not a log of every cache operation.
Sorted-key canonical JSON for cache key hashing
Tool args and LLM params are serialized with recursively sorted object keys before SHA-256 hashing. This means {"city": "Sofia", "units": "metric"} and {"units": "metric", "city": "Sofia"} produce the same cache key.
Approximate active session tracking
The active_sessions Prometheus gauge is approximate — it tracks threads seen via an in-memory set, incremented on first write, decremented on destroy_thread(). It does not survive process restarts and may drift if threads expire via TTL without an explicit destroy.
Quick start
import asyncio
import valkey.asyncio as valkey_client
from betterdb_agent_cache import AgentCache, TierDefaults
from betterdb_agent_cache.types import AgentCacheOptions
client = valkey_client.Valkey(host="localhost", port=6379)
cache = AgentCache(AgentCacheOptions(
client=client,
tier_defaults={
"llm": TierDefaults(ttl=3600),
"tool": TierDefaults(ttl=300),
"session": TierDefaults(ttl=1800),
},
# cost_table is pre-defined for GPT-4o, Claude, Gemini, and 1,900+ others
))
async def main():
# LLM response caching
params = {
"model": "gpt-4o",
"messages": [{"role": "user", "content": "What is Valkey?"}],
"temperature": 0,
}
result = await cache.llm.check(params)
if not result.hit:
response = await call_llm(params)
await cache.llm.store(params, response)
# Tool result caching
weather = await cache.tool.check("get_weather", {"city": "Sofia"})
if not weather.hit:
data = await get_weather(city="Sofia")
await cache.tool.store("get_weather", {"city": "Sofia"}, json.dumps(data))
# Session state
await cache.session.set("thread-1", "last_intent", "book_flight")
intent = await cache.session.get("thread-1", "last_intent")
asyncio.run(main())
Configuration reference
| Option | Type | Default | Description |
|---|---|---|---|
client |
valkey.asyncio.Valkey |
— | Valkey async client instance (required) |
name |
str |
'betterdb_ac' |
Key prefix for all Valkey keys |
default_ttl |
int | None |
None |
Default TTL in seconds. None = no expiry |
tier_defaults["llm"].ttl |
int | None |
None |
Default TTL for LLM cache entries |
tier_defaults["tool"].ttl |
int | None |
None |
Default TTL for tool cache entries |
tier_defaults["session"].ttl |
int | None |
None |
Default TTL for session entries |
cost_table |
dict[str, ModelCost] |
{} |
Model pricing overrides. Merged on top of the built-in default table. |
use_default_cost_table |
bool |
True |
Use bundled default cost table sourced from LiteLLM. Set to False to disable. |
telemetry.tracer_name |
str |
'@betterdb/agent-cache' |
OpenTelemetry tracer name |
telemetry.metrics_prefix |
str |
'agent_cache' |
Prometheus metric name prefix |
telemetry.registry |
CollectorRegistry | None |
default registry | prometheus_client registry |
ModelCost format
from betterdb_agent_cache import ModelCost
cost_table = {
"gpt-4o": ModelCost(input_per_1k=0.0025, output_per_1k=0.01),
"gpt-4o-mini": ModelCost(input_per_1k=0.00015, output_per_1k=0.0006),
}
Default cost table
A default cost table sourced from LiteLLM's model_prices_and_context_window.json is bundled with the package and refreshed on every release. Cost tracking works out of the box for 1,900+ models — no cost_table configuration required.
To override a specific model's pricing without losing the defaults for others:
cache = AgentCache(AgentCacheOptions(
client=client,
cost_table={"gpt-4o": ModelCost(input_per_1k=0.002, output_per_1k=0.008)},
))
To disable the default table entirely:
cache = AgentCache(AgentCacheOptions(
client=client,
use_default_cost_table=False,
cost_table={...},
))
The bundled table is also exported directly:
from betterdb_agent_cache import DEFAULT_COST_TABLE
Cache tiers
LLM cache
Caches LLM responses by exact match on model, messages, temperature, top_p, max_tokens, and tools.
Key format: {name}:llm:{hash}
# Check for cached response
result = await cache.llm.check({
"model": "gpt-4o",
"messages": [{"role": "user", "content": "Hello"}],
"temperature": 0,
})
# Store a response
await cache.llm.store(params, response, LlmStoreOptions(
ttl=3600,
tokens={"input": 10, "output": 50}, # for cost tracking
))
# Store multi-part (text + tool calls)
await cache.llm.store_multipart(params, blocks, LlmStoreOptions(...))
# Invalidate by model
deleted = await cache.llm.invalidate_by_model("gpt-4o")
TTL precedence: per-call ttl > tier_defaults["llm"].ttl > default_ttl
Tool cache
Caches tool/function call results by tool name and argument hash.
Key format: {name}:tool:{tool_name}:{hash}
# Check for cached result
result = await cache.tool.check("get_weather", {"city": "Sofia"})
# Store a result
await cache.tool.store("get_weather", {"city": "Sofia"}, json_result, ToolStoreOptions(
ttl=300,
cost=0.001, # API call cost in dollars
))
# Set per-tool TTL policy
await cache.tool.set_policy("get_weather", ToolPolicy(ttl=600))
# Invalidate all results for a tool
deleted = await cache.tool.invalidate_by_tool("get_weather")
# Invalidate a specific call
existed = await cache.tool.invalidate("get_weather", {"city": "Sofia"})
TTL precedence: per-call ttl > tool policy > tier_defaults["tool"].ttl > default_ttl
Session store
Key-value storage for agent session state with sliding window TTL.
Key format: {name}:session:{thread_id}:{field}
# Get/set individual fields
await cache.session.set("thread-1", "last_intent", "book_flight")
intent = await cache.session.get("thread-1", "last_intent")
# Get all fields for a thread
all_fields = await cache.session.get_all("thread-1")
# Delete a field
await cache.session.delete("thread-1", "last_intent")
# Destroy entire thread (including LangGraph checkpoints)
deleted = await cache.session.destroy_thread("thread-1")
# Refresh TTL on all fields
await cache.session.touch("thread-1")
TTL behaviour: get() refreshes TTL on hit (sliding window). set() sets TTL. touch() refreshes TTL on all fields.
Stats and self-optimisation
stats()
stats = await cache.stats()
# AgentCacheStats(
# llm=TierStats(hits=150, misses=50), # hit_rate=0.75
# tool=TierStats(hits=300, misses=100), # hit_rate=0.75
# session=SessionStats(reads=1000, writes=500),
# cost_saved_micros=12500000, # $12.50 in microdollars
# per_tool={
# "get_weather": ToolStats(hits=200, misses=50, ttl=300, cost_saved_micros=5000000),
# }
# )
tool_effectiveness()
entries = await cache.tool_effectiveness()
# [
# ToolEffectivenessEntry(tool="get_weather", hit_rate=0.85, cost_saved=5.00, recommendation="increase_ttl"),
# ToolEffectivenessEntry(tool="search", hit_rate=0.60, cost_saved=2.50, recommendation="optimal"),
# ToolEffectivenessEntry(tool="rare_api", hit_rate=0.10, cost_saved=0.10, recommendation="decrease_ttl_or_disable"),
# ]
Recommendations:
increase_ttl— hit rate > 80% and current TTL < 1 houroptimal— hit rate 40–80%decrease_ttl_or_disable— hit rate < 40%
Provider adapters
OpenAI Chat Completions
from betterdb_agent_cache.adapters.openai import prepare_params, OpenAIPrepareOptions
from betterdb_agent_cache import compose_normalizer, hash_base64
opts = OpenAIPrepareOptions(normalizer=compose_normalizer({"base64": hash_base64}))
cache_params = await prepare_params(openai_params, opts)
result = await cache.llm.check(cache_params)
OpenAI Responses API
from betterdb_agent_cache.adapters.openai_responses import prepare_params, OpenAIResponsesPrepareOptions
opts = OpenAIResponsesPrepareOptions(normalizer=compose_normalizer({"base64": hash_base64}))
cache_params = await prepare_params(responses_params, opts)
OpenAI Agents SDK
Caches at the Agents SDK Model.get_response() level, so agent runs that replay the same tool-call sequences (evaluation, testing, multi-agent orchestration) skip the API. Requires pip install "betterdb-agent-cache[openai_agents]".
Wrap the model provider (recommended) so every model an agent run resolves is cache-enabled:
from agents import Runner, RunConfig
from betterdb_agent_cache.adapters.openai_agents import CachedModelProvider
cached_provider = CachedModelProvider(provider, cache=cache)
result = await Runner.run(agent, "Hello", run_config=RunConfig(model_provider=cached_provider))
Or wrap a single model directly:
from agents import Agent
from agents.models.openai_chatcompletions import OpenAIChatCompletionsModel
from betterdb_agent_cache.adapters.openai_agents import CachedModel
base_model = OpenAIChatCompletionsModel(model="gpt-4o", openai_client=client)
agent = Agent(name="Assistant", model=CachedModel(base_model, cache=cache))
stream_response() is delegated uncached (matching the streaming convention), and stores fail open — a Valkey error logs and returns the live response rather than crashing the run.
Anthropic
from betterdb_agent_cache.adapters.anthropic import prepare_params
cache_params = await prepare_params(anthropic_params)
LlamaIndex
from betterdb_agent_cache.adapters.llamaindex import prepare_params
cache_params = await prepare_params(messages)
LangChain
from betterdb_agent_cache.adapters.langchain import BetterDBLlmCache
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-4o-mini",
cache=BetterDBLlmCache(cache=cache),
)
LangGraph
Works on vanilla Valkey 7+ with no modules. Unlike langgraph-checkpoint-redis, this does not require Redis 8.0+, RedisJSON, or RediSearch.
from betterdb_agent_cache.adapters.langgraph import BetterDBSaver
from langgraph.graph import StateGraph
checkpointer = BetterDBSaver(cache=cache)
graph = StateGraph(schema).add_node("agent", agent_node).compile(checkpointer=checkpointer)
Pluggable binary normalizer
Controls how binary content (images, audio, documents) is reduced to a stable string before hashing. Zero-latency by default — no network calls.
from betterdb_agent_cache import compose_normalizer, hash_base64, fetch_and_hash
# Hash base64 image bytes for stable keys
normalizer = compose_normalizer({"base64": hash_base64})
# Fetch and hash remote image URLs (requires aiohttp)
normalizer = compose_normalizer({"url": fetch_and_hash})
Prometheus metrics
All metric names are prefixed with agent_cache_ by default (configurable via telemetry.metrics_prefix).
| Metric | Type | Labels | Description |
|---|---|---|---|
agent_cache_requests_total |
Counter | cache_name, tier, result, tool_name |
Total cache requests. result is hit or miss |
agent_cache_operation_duration_seconds |
Histogram | cache_name, tier, operation |
Duration of cache operations in seconds |
agent_cache_cost_saved_total |
Counter | cache_name, tier, model, tool_name |
Estimated cost saved in dollars from cache hits |
agent_cache_stored_bytes_total |
Counter | cache_name, tier |
Total bytes stored in cache |
agent_cache_active_sessions |
Gauge | cache_name |
Approximate number of active session threads |
OpenTelemetry tracing
Every public method emits an OTel span. Spans require an OpenTelemetry SDK to be configured in the host application.
| Span name | Attributes |
|---|---|
agent_cache.llm.check |
cache.key, cache.model, cache.hit |
agent_cache.llm.store |
cache.key, cache.model, cache.ttl, cache.bytes |
agent_cache.llm.invalidate_by_model |
cache.model, cache.deleted_count |
agent_cache.tool.check |
cache.key, cache.tool_name, cache.hit |
agent_cache.tool.store |
cache.key, cache.tool_name, cache.ttl, cache.bytes |
agent_cache.tool.invalidate_by_tool |
cache.tool_name, cache.deleted_count |
agent_cache.session.get |
cache.key, cache.thread_id, cache.field, cache.hit |
agent_cache.session.set |
cache.key, cache.thread_id, cache.field, cache.ttl, cache.bytes |
agent_cache.session.get_all |
cache.thread_id, cache.field_count |
agent_cache.session.destroy_thread |
cache.thread_id, cache.deleted_count |
agent_cache.session.touch |
cache.thread_id, cache.touched_count_approx |
Cluster support
Pass a ValkeyCluster client and all SCAN-based operations (flush, invalidate_by_model, invalidate_by_tool, destroy_thread, touch) automatically iterate all master nodes. No configuration changes needed.
from valkey.asyncio.cluster import ValkeyCluster
client = ValkeyCluster(host="my-cluster.example.com", port=6379)
cache = AgentCache(AgentCacheOptions(client=client, ...))
BetterDB Monitor integration
Connect BetterDB Monitor to the same Valkey instance and it will automatically detect the agent cache stats hash and surface hit rates, cost savings, and per-tool effectiveness in the dashboard.
Known limitations
- Session
get_all(): SCAN-based. Fine for dozens of fields per thread; consider Redis HASH if you have thousands. - LangGraph
list(): Loads all checkpoint data for a thread into memory before filtering. Acceptable for hundreds of checkpoints per thread. For millions, uselanggraph-checkpoint-rediswith Redis 8+ instead. active_sessionsgauge: Approximate and does not survive process restarts.- Streaming responses: Not cached by any adapter. Accumulate the full response before storing.
License
MIT
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file betterdb_agent_cache-0.12.0.tar.gz.
File metadata
- Download URL: betterdb_agent_cache-0.12.0.tar.gz
- Upload date:
- Size: 107.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
762a03b160857bcdee03440fdb62e3481f3f8332e7c3498209e1a6269402244a
|
|
| MD5 |
103b62930addde1aedef3b79747c20b9
|
|
| BLAKE2b-256 |
e35294df7f640568b7c5404a9ffea4a38828c0a8f0ef6e8ff01d824230a4505c
|
Provenance
The following attestation bundles were made for betterdb_agent_cache-0.12.0.tar.gz:
Publisher:
agent-cache-py-release.yml on BetterDB-inc/monitor
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
betterdb_agent_cache-0.12.0.tar.gz -
Subject digest:
762a03b160857bcdee03440fdb62e3481f3f8332e7c3498209e1a6269402244a - Sigstore transparency entry: 2226096600
- Sigstore integration time:
-
Permalink:
BetterDB-inc/monitor@69d8073b2bd1810e8621612abe509220987104d5 -
Branch / Tag:
refs/tags/agent-cache-py-v0.12.0 - Owner: https://github.com/BetterDB-inc
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
agent-cache-py-release.yml@69d8073b2bd1810e8621612abe509220987104d5 -
Trigger Event:
push
-
Statement type:
File details
Details for the file betterdb_agent_cache-0.12.0-py3-none-any.whl.
File metadata
- Download URL: betterdb_agent_cache-0.12.0-py3-none-any.whl
- Upload date:
- Size: 80.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
408bf3ff408615a9b75b4b10b2254d9dd642131a0c09a1519cde95e5da936a08
|
|
| MD5 |
eec7d5efc661edf5741ffb31cd38ec66
|
|
| BLAKE2b-256 |
68ece0d189bc390ed36dd0bd0c4f0b8404718d52bf33b7e11e3d0de78e445517
|
Provenance
The following attestation bundles were made for betterdb_agent_cache-0.12.0-py3-none-any.whl:
Publisher:
agent-cache-py-release.yml on BetterDB-inc/monitor
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
betterdb_agent_cache-0.12.0-py3-none-any.whl -
Subject digest:
408bf3ff408615a9b75b4b10b2254d9dd642131a0c09a1519cde95e5da936a08 - Sigstore transparency entry: 2226096815
- Sigstore integration time:
-
Permalink:
BetterDB-inc/monitor@69d8073b2bd1810e8621612abe509220987104d5 -
Branch / Tag:
refs/tags/agent-cache-py-v0.12.0 - Owner: https://github.com/BetterDB-inc
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
agent-cache-py-release.yml@69d8073b2bd1810e8621612abe509220987104d5 -
Trigger Event:
push
-
Statement type:







