BGmi is a cli tool for subscribed bangumi.


Project description
BGmi
BGmi 是一个用来追番的命令行程序.




TODO
更新日志
v4
- 命令自动补全,使用
bgmi completion zsh/bash生成 - 添加
mikan_url配置,用于配置蜜柑计划镜像站。 - 添加
proxy设置 - 新 WEB UI
- 将配置项
transmission.rpc_url重命名为transmission.rpc_host. - 修复 Transmission 配置的默认值.
v3
- 新增配置项
global_include_keywords,用于设置全局包含关键词。 - 新增配置项
save_path_map,用于设置不同动画的下载路径。 - 使用 TOML 作为配置文件
- 不再支持 python3.7
- 不再支持 python3.6
- 支持扩展下载方式
- 移除迅雷离线
- 支持 qbittorrent-webapi
- 停止支持 python2,3.4 和 3.5
- Transmission rpc 认证设置
- 支持 deluge-rpc
- 使用最大和最小集数筛选搜索结果
特性
- 多个数据源可选: bangumi_moe, mikan_project 或者dmhy
- 使用 aria2, transmission, qbittorrent 或者 deluge 来下载你的番剧.
- 提供一个管理和观看订阅番剧的前端.
- 弹幕支持
- 提供 uTorrent 支持的 RSS Feed 和移动设备支持的 ICS 格式日历.
- Bangumi Script: 添加自己的番剧解析器
- 番剧放松列表和剧集信息
- 下载番剧时的过滤器(支持关键词,字幕组和正则)
- 多平台支持: Windows, *nux 以及 Router system

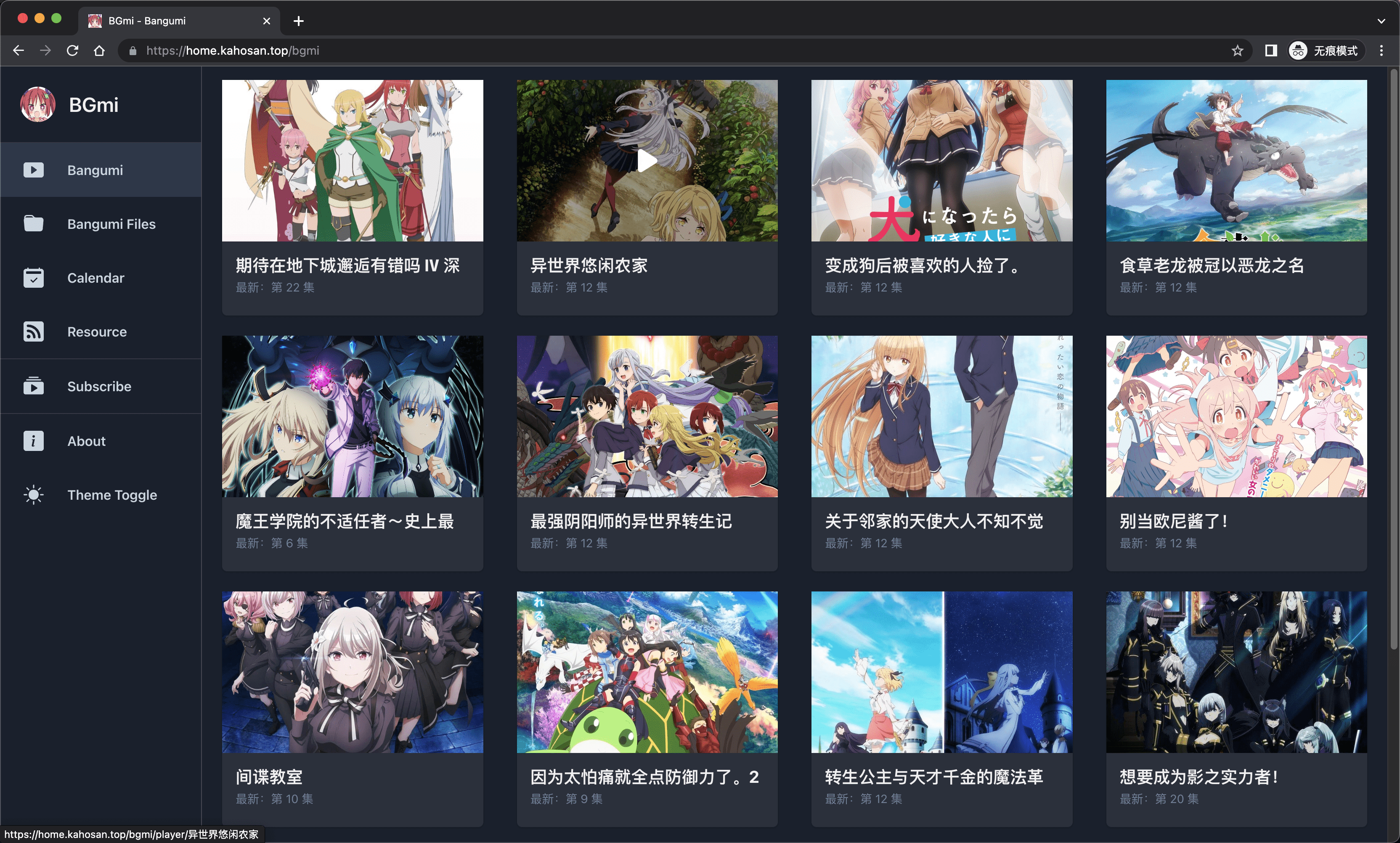
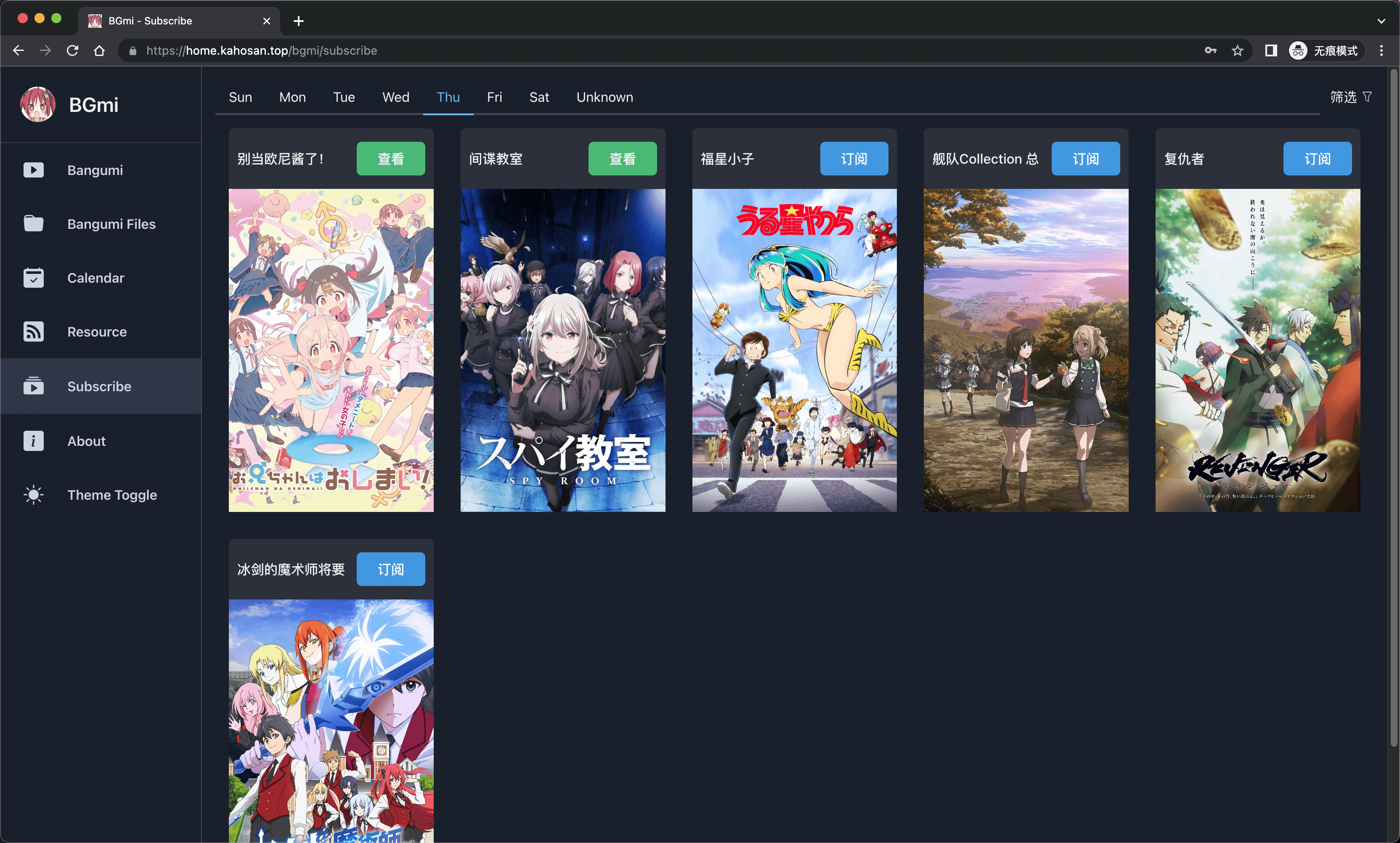
安装
使用 pipx 安装(推荐):
pipx install bgmi
使用 pip 安装稳定版本:
pip install bgmi
或者从源码安装(不推荐)
git clone https://github.com/BGmi/BGmi
cd BGmi
git checkout master
python -m pip install -U pip
pip install .
初始化BGmi
bgmi install
升级(仅 pipx 安装)
pipx upgrade bgmi
bgmi upgrade
升级(仅 pip 安装)
pip install bgmi -U
bgmi upgrade
在升级后请确保运行bgmi upgrade
使用 Docker
使用
查看可用的命令
bgmi --help
--help选项同样适用于所有的子命令,readme 仅介绍了一些基础用法。
命令自动补全
bash
bgmi completion bash > ~/.bash_completion.d/bgmi
zsh
oh-my-zsh
bgmi completion zsh > .oh-my-zsh/completions/_bgmi
我不使用其他的 zsh 插件管理器,具体的安装方法请查询你使用的插件管理器文档
配置 BGmi
BGmi 提供两种方式配置BGmi的各项运行参数,分别为配置文件与环境变量。
配置文件
bgmi 的配置文件位于 ${BGMI_PATH}/config.toml, 在未设置 BGMI_PATH 环境变量时,${BGMI_PATH} 默认为 ~/.bgmi/。
查看当前 BGmi 设置:
bgmi config # 查看当前各项设置默认值.
data_source = "bangumi_moe" # bangumi source,!!! 请不要手动修改此选项 !!!
download_delegate = "aria2-rpc" # 番剧下载工具 (aria2-rpc, transmission-rpc, deluge-rpc, qbittorrent-webapi)
tmp_path = "tmp/tmp" # tmp dir
save_path = "tmp/bangumi" # 下载番剧保存地址
max_path = 3 # 抓取数据时每个番剧最大抓取页数
bangumi_moe_url = "https://bangumi.moe"
share_dmhy_url = "https://share.dmhy.org"
mikan_url = "https://mikanani.me"
mikan_username = "" # 蜜柑计划的用户名
mikan_password = "" # 蜜柑计划的密码
enable_global_filters = true
global_filters = [
"Leopard-Raws",
"hevc",
"x265",
"c-a Raws",
"U3-Web",
]
proxy = '' # http proxy example: http://127.0.0.1:1080
[save_path_map] # 针对每部番剧设置下载路径
'致不灭的你 第二季' = '/home/trim21/downloads/bangumi/致不灭的你/s2/' # 如果使用绝对路径,可能导致 web-ui 无法正确显示视频文件。
'致不灭的你 第三季' = './致不灭的你/s3/' # 以 save_path 为基础路径的相对路径
[http]
admin_token = "dYMj-Z4bDRoQfd3x" # web ui 的密码
danmaku_api_url = ""
serve_static_files = false
[aria2]
rpc_url = "http://localhost:6800/rpc" # aria2c RPC URL (不是 jsonrpc URL, 如果你的 aria2c 运行在 localhost:6800, 对应的链接为 `http://localhost:6800/rpc`)
rpc_token = "token:" # aria2c RPC token (如果没有设置 token, 留空或者设置为 `token:`)
[transmission]
rpc_host = "127.0.0.1"
rpc_port = 9091
rpc_username = "your_username"
rpc_password = "your_password"
rpc_path = "/transmission/rpc" # transmission http rpc 的请求路径
[qbittorrent]
rpc_host = "127.0.0.1"
rpc_port = 8080
rpc_username = "admin"
rpc_password = "adminadmin"
category = ""
[deluge]
rpc_url = "http://127.0.0.1:8112/json"
rpc_password = "deluge"
环境变量
当 BGmi 的配置文件还未初始化时,各项运行参数可由环境变量进行配置
环境变量以 BGMI_ 开头,全大写命名,且各级配置以 _ 进行分割,如:
BGMI_DATA_SOURCE=bangumi_moe # 对应配置文件中的 data_source = "bangumi_moe"
BGMI_HTTP_ADMIN_TOKEN=dYMj-Z4bDRoQfd3x # 对应配置文件 [http] 分段中的 admin_token = "dYMj-Z4bDRoQfd3x"
...
环境变量 暂不支持 配置以下项目
enable_global_include_keywords
enable_global_filters
global_include_keywords
global_filters
[save_path_map]
注: 当配置文件生成完毕后,运行配置将会以配置文件为准,环境变量仅用于生成第一份配置文件。
修改配置
使用 bgmi config set ...keys --value '...' 命令可以修改配置。
如:
bgmi config set http admin_token --value 'my super secret token'
或者
bgmi config set max_path --value '3'
不能用来修改复杂配置,如 global_filters,请手动修改配置文件。
支持的数据源
更换换数据源
更换数据源会清空番剧数据库, 但是 bgmi script 不受影响. 之前下载的视频文件不会删除, 但是不会在前端显示
如果更换的源为 mikan_project, 请先配置 MIKAN_USERNAME 和 MIKAN_PASSWORD, 其它源不受影响
bgmi source mikan_project
切换数据源必需使用bgmi source命令,不能手动修改配置文件。手动修改配置文件会导致 bgmi 报错
设置下载方式
修改配置文件和对应的配置项
download_delegate = "aria2-rpc" # download delegate
内置可用的选项包括 aria2-rpc, transmission-rpc, qbittorrent-webapi 以及 deluge-rpc。
查看目前正在更新的新番
bgmi cal
订阅番剧:
bgmi add "进击的巨人 第三季" "刃牙" "哆啦A梦"
bgmi add "高分少女" --episode 0
添加番剧的同时设置下载路径:
bgmi add "高分少女" --episode 0 --save-path './高分少女/S1/'
退订:
bgmi delete "Re:CREATORS"
更新番剧列表并且下载番剧:
bgmi update --download # update all
bgmi update "从零开始的魔法书" --download
设置筛选条件:
bgmi list # 列出目前订阅的番剧
bgmi fetch "Re:CREATORS"
# include和exclude会忽略大小写。`720p`和`720P`的效果是相同的
bgmi filter "Re:CREATORS" --subtitle "DHR動研字幕組,豌豆字幕组" --include 720P --exclude BIG5
bgmi fetch "Re:CREATORS"
# 删除subtitle,include和exclude,添加正则匹配
bgmi filter "Re:CREATORS" --subtitle "" --include "" --exclude "" --regex "..."
bgmi filter "Re:CREATORS" --regex "(DHR動研字幕組|豌豆字幕组).*(720P)"
bgmi fetch "Re:CREATORS"
设置全局过滤关键词
包含
默认不启用全局包含关键词,你可以设置 enable_global_include_keywords = true 启动此功能。
enable_global_include_keywords = true
global_include_keywords = ['1080']
排除
有一些默认定义的全局过滤关键词,默认会排除标题包含以下关键词的种子。
可以使用 enable_global_filters = false 禁止过滤全局关键词,
enable_global_filters = true
global_filters = [
"Leopard-Raws",
"hevc",
"x265",
"c-a Raws",
"U3-Web",
]
最后使用bgmi fetch来看看筛选的结果.
搜索番剧并下载:
bgmi search '为美好的世界献上祝福!' --regex-filter '.*动漫国字幕组.*为美好的世界献上祝福!].*720P.*'
使用--min-episode和--max-episode来根据集数筛选下载结果
bgmi search 海贼王 --min-episode 800 --max-episode 820
# 下载
bgmi search 海贼王 --min-episode 800 --max-episode 820 --download
bgmi search命令默认不会显示重复的集数, 如果要显示重复的集数来方便过滤, 在命令后加上--dupe来显示全部的搜索结果
手动修改最近下载的剧集
bgmi list
bgmi mark "Re:CREATORS" 1
使用bgmi_http
1.先下载所有更新中番剧的封面
bgmi cal --download-cover
2.根据你是否使用 nginx, 设置serve_static_files(使用 nginx 的情况下使用默认设置false, 不使用的情况下设置为true)
3.下载前端的静态文件(你可能在安装的时候已经下载过了):
bgmi install
4.在8888端口启动 BGmi HTTP 服务器:
bgmi_http --port=8888 --address=0.0.0.0
在 Windows 上使用bgmi_http
参照上面启动服务器, 然后访问http://localhost:8888/.
在*nux 上使用 bgmi_http
可以让BGmi帮助你生成对应的 nginx 配置文件
bgmi gen nginx.conf --server-name bgmi.whatever.com
你也可以手动写一份 nginx 配置, 来满足你的更多需求(比如启用 https), 这是一份例子
server {
listen 80;
server_name bgmi;
autoindex on;
charset utf-8;
location /bangumi {
# ~/.bgmi/bangumi
# alias到你的`SAVE_PATH` 注意以/结尾
alias /path/to/bangumi/;
}
location /api {
proxy_pass http://127.0.0.1:8888;
}
location /resource {
proxy_pass http://127.0.0.1:8888;
}
location / {
# alias到你的`BGMI_PATH/front_static/`注意以/结尾
alias /path/to/front_static/;
}
}
或者添加一个 aria2c 前端之类的, 具体办法百度上有很多,不在此赘述.
macOS launchctl service controller
参照 issue #77自行设置
弹幕支持
BGmi 使用DPlayer做为前端播放器
如果你想要添加弹幕支持, 在这里DPlayer#related-projects选择一个后端自行搭建, 或者使用DPlayer提供的现成接口https://api.prprpr.me/dplayer/
然后修改配置文件:
[bgmi_http]
danmaku_api_url = "https://api.prprpr.me/dplayer/" # This api is provided by dplayer official
设置你的bgmi_http, 享受弹幕支援吧.
调试
log 文件位于{BGMI_PATH}/tmp/
卸载
由于 pip 的限制, 你需要手动清理BGmi产生的位于~/.bgmi的文件
同样, BMmi添加到你系统的定时任务也不会被自动删除, 请手动删除.
*nix:
请手动清理crontab
windows:
schtasks /Delete /TN 'bgmi updater'
如果你对 python 有一点了解, 并且觉得还不够的话, 下面是为你准备的.
Bangumi Script
你可以写一个BGmi Script来解析你自己的想看的番剧或者美剧. BGmi 会加载你的 script, 视作一个番剧来对待. 而你所需要做的只是继承ScriptBase类, 然后实现特定的方法, 再把你的 script 文件放到BGMI_PATH/script文件夹内.
Example: ./tests/script_example.py
get_download_url()返回一个dict, 以对应集数为键, 对应的下载链接为值
{
1: 'http://example.com/Bangumi/1/1.mp4',
2: 'http://example.com/Bangumi/1/2.torrent',
3: 'http://example.com/Bangumi/1/3.mp4'
}
Download hook
你可以在下载完成前或下载完成后执行一些操作, 比如移动文件, 重命名文件等等. 将你的 hook 文件放到BGMI_PATH/hooks文件夹内即可.
from loguru import logger
from bgmi.script import HookBase
# 只需要继承 HookBase 类,实现里面的方法即可,类名字可任意设置
class Hook(HookBase):
# 在添加了下载任务之后执行
def post_add_download(self) -> None:
logger.info('post add download')
# 在更新了状态,下载之前进行执行
def pre_add_download(self) -> None:
logger.info('pre add download')
BGmi 数据源
通过扩展bgmi.website.base.BaseWebsite类并且实现对应的三个方法,你也可以简单的添加一个数据源
每个方法具体的意义和返回值格式请参照每个方法对应的注释
from typing import List, Optional
from bgmi.website.base import BaseWebsite
from bgmi.website.model import Episode, WebsiteBangumi
class DataSource(BaseWebsite):
def search_by_keyword(
self, keyword: str, count: int
) -> List[Episode]: # pragma: no cover
"""
:param keyword: search key word
:param count: how many page to fetch from website
:return: list of episode search result
"""
raise NotImplementedError
def fetch_bangumi_calendar(self,) -> List[WebsiteBangumi]: # pragma: no cover
"""
return a list of all bangumi and a list of all subtitle group
list of bangumi dict:
update time should be one of ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Unknown']
"""
raise NotImplementedError
def fetch_episode_of_bangumi(
self, bangumi_id: str, max_page: int, subtitle_list: Optional[List[str]] = None
) -> List[Episode]: # pragma: no cover
"""
get all episode by bangumi id
:param bangumi_id: bangumi_id
:param subtitle_list: list of subtitle group
:type subtitle_list: list
:param max_page: how many page you want to crawl if there is no subtitle list
:type max_page: int
:return: list of bangumi
"""
raise NotImplementedError
def fetch_single_bangumi(self, bangumi_id: str) -> WebsiteBangumi:
"""
fetch bangumi info when updating
:param bangumi_id: bangumi_id, or bangumi['keyword']
:type bangumi_id: str
:rtype: WebsiteBangumi
"""
# return WebsiteBangumi(keyword=bangumi_id) if website don't has a page contains episodes and info
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file bgmi-4.5.1.tar.gz.
File metadata
- Download URL: bgmi-4.5.1.tar.gz
- Upload date:
- Size: 55.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
26f0250124ea4e13f2dc227aa548f021a1c21d4a21398d220f7e4d3343676ff7
|
|
| MD5 |
c6ec519aa99929cd102bc5ea334c05d4
|
|
| BLAKE2b-256 |
1b70cf34f613249ca29d6b37a279f9d7f163cc22b73db372cea496391e57ca01
|
File details
Details for the file bgmi-4.5.1-py3-none-any.whl.
File metadata
- Download URL: bgmi-4.5.1-py3-none-any.whl
- Upload date:
- Size: 61.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
31a93f0b5afc1e02da3364ff737b51dc598e1963cfd9a2dce6d4d6e43c297249
|
|
| MD5 |
a7bf9cc58ed7f82064ed970ae7c5ddf2
|
|
| BLAKE2b-256 |
b81dbf18f1f13936f001692663feb76b849db16c9be88895764c9e2c85aa7dc9
|







