A simple and extensible library to create Bayesian Neural Network Layers on PyTorch without trouble and with full integration with nn.Module and nn.Sequential.

Project description
Blitz - Bayesian Layers in Torch Zoo

BLiTZ is a simple and extensible library to create Bayesian Neural Network Layers (based on whats proposed in Weight Uncertainty in Neural Networks paper) on PyTorch. By using BLiTZ layers and utils, you can add uncertanity and gather the complexity cost of your model in a simple way that does not affect the interaction between your layers, as if you were using standard PyTorch.
By using our core weight sampler classes, you can extend and improve this library to add uncertanity to a bigger scope of layers as you will in a well-integrated to PyTorch way. Also pull requests are welcome.
Our objective is empower people to apply Bayesian Deep Learning by focusing rather on their idea, and not the hard-coding part.
Index
- Install
- Documentation
- A simple example for regression
- Bayesian Deep Learning in a Nutshell
- First of all, a deterministic NN layer linear-transformation
- The purpose of Bayesian Layers
- Weight sampling on Bayesian Layers
- It is possible to optimize our trainable weights
- It is also true that there is complexity cost function differentiable along its variables
- To get the whole cost function at the nth sample
- Some notes and wrap up
- Citing
- References
Install
To install BLiTZ you can use pip command:
pip install blitz-bayesian-pytorch
Or, via conda:
conda install -c conda-forge blitz-bayesian-pytorch
You can also git-clone it and pip-install it locally:
conda create -n blitz python=3.6
conda activate blitz
git clone https://github.com/piEsposito/blitz-bayesian-deep-learning.git
cd blitz-bayesian-deep-learning
pip install .
Documentation
Documentation for our layers, weight (and prior distribution) sampler and utils:
- Bayesian Layers
- Weight and prior distribution samplers
- Utils (for easy integration with PyTorch)
- Losses
A simple example for regression
(You can see it for your self by running this example on your machine).
We will now see how can Bayesian Deep Learning be used for regression in order to gather confidence interval over our datapoint rather than a pontual continuous value prediction. Gathering a confidence interval for your prediction may be even a more useful information than a low-error estimation.
I sustain my argumentation on the fact that, with good/high prob a confidence interval, you can make a more reliable decision than with a very proximal estimation on some contexts: if you are trying to get profit from a trading operation, for example, having a good confidence interval may lead you to know if, at least, the value on which the operation wil procees will be lower (or higher) than some determinate X.
Knowing if a value will be, surely (or with good probability) on a determinate interval can help people on sensible decision more than a very proximal estimation that, if lower or higher than some limit value, may cause loss on a transaction. The point is that, sometimes, knowing if there will be profit may be more useful than measuring it.
In order to demonstrate that, we will create a Bayesian Neural Network Regressor for the Boston-house-data toy dataset, trying to create confidence interval (CI) for the houses of which the price we are trying to predict. We will perform some scaling and the CI will be about 75%. It will be interesting to see that about 90% of the CIs predicted are lower than the high limit OR (inclusive) higher than the lower one.
Importing the necessary modules
Despite from the known modules, we will bring from BLiTZ athe variational_estimatordecorator, which helps us to handle the BayesianLinear layers on the module keeping it fully integrated with the rest of Torch, and, of course, BayesianLinear, which is our layer that features weight uncertanity.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from blitz.modules import BayesianLinear
from blitz.utils import variational_estimator
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
Loading and scaling data
Nothing new under the sun here, we are importing and standard-scaling the data to help with the training.
X, y = load_boston(return_X_y=True)
X = StandardScaler().fit_transform(X)
y = StandardScaler().fit_transform(np.expand_dims(y, -1))
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=.25,
random_state=42)
X_train, y_train = torch.tensor(X_train).float(), torch.tensor(y_train).float()
X_test, y_test = torch.tensor(X_test).float(), torch.tensor(y_test).float()
Creating our variational regressor class
We can create our class with inhreiting from nn.Module, as we would do with any Torch network. Our decorator introduces the methods to handle the bayesian features, as calculating the complexity cost of the Bayesian Layers and doing many feedforwards (sampling different weights on each one) in order to sample our loss.
@variational_estimator
class BayesianRegressor(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
#self.linear = nn.Linear(input_dim, output_dim)
self.blinear1 = BayesianLinear(input_dim, 512)
self.blinear2 = BayesianLinear(512, output_dim)
def forward(self, x):
x_ = self.blinear1(x)
x_ = F.relu(x_)
return self.blinear2(x_)
Defining a confidence interval evaluating function
This function does create a confidence interval for each prediction on the batch on which we are trying to sample the label value. We then can measure the accuracy of our predictions by seeking how much of the prediciton distributions did actually include the correct label for the datapoint.
def evaluate_regression(regressor,
X,
y,
samples = 100,
std_multiplier = 2):
preds = [regressor(X) for i in range(samples)]
preds = torch.stack(preds)
means = preds.mean(axis=0)
stds = preds.std(axis=0)
ci_upper = means + (std_multiplier * stds)
ci_lower = means - (std_multiplier * stds)
ic_acc = (ci_lower <= y) * (ci_upper >= y)
ic_acc = ic_acc.float().mean()
return ic_acc, (ci_upper >= y).float().mean(), (ci_lower <= y).float().mean()
Creating our regressor and loading data
Notice here that we create our BayesianRegressor as we would do with other neural networks.
regressor = BayesianRegressor(13, 1)
optimizer = optim.Adam(regressor.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()
ds_train = torch.utils.data.TensorDataset(X_train, y_train)
dataloader_train = torch.utils.data.DataLoader(ds_train, batch_size=16, shuffle=True)
ds_test = torch.utils.data.TensorDataset(X_test, y_test)
dataloader_test = torch.utils.data.DataLoader(ds_test, batch_size=16, shuffle=True)
Our main training and evaluating loop
We do a training loop that only differs from a common torch training by having its loss sampled by its sample_elbo method. All the other stuff can be done normally, as our purpose with BLiTZ is to ease your life on iterating on your data with different Bayesian NNs without trouble.
Here is our very simple training loop:
iteration = 0
for epoch in range(100):
for i, (datapoints, labels) in enumerate(dataloader_train):
optimizer.zero_grad()
loss = regressor.sample_elbo(inputs=datapoints,
labels=labels,
criterion=criterion,
sample_nbr=3)
loss.backward()
optimizer.step()
iteration += 1
if iteration%100==0:
ic_acc, under_ci_upper, over_ci_lower = evaluate_regression(regressor,
X_test,
y_test,
samples=25,
std_multiplier=3)
print("CI acc: {:.2f}, CI upper acc: {:.2f}, CI lower acc: {:.2f}".format(ic_acc, under_ci_upper, over_ci_lower))
print("Loss: {:.4f}".format(loss))
Bayesian Deep Learning in a Nutshell
A very fast explanation of how is uncertainity introduced in Bayesian Neural Networks and how we model its loss in order to objectively improve the confidence over its prediction and reduce the variance without dropout.
First of all, a deterministic NN layer linear transformation
As we know, on deterministic (non bayesian) neural network layers, the trainable parameters correspond directly to the weights used on its linear transformation of the previous one (or the input, if it is the case). It corresponds to the following equation:
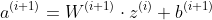
(Z correspond to the activated-output of the layer i)
The purpose of Bayesian Layers
Bayesian layers seek to introduce uncertainity on its weights by sampling them from a distribution parametrized by trainable variables on each feedforward operation.
This allows we not just to optimize the performance metrics of the model, but also gather the uncertainity of the network predictions over a specific datapoint (by sampling it much times and measuring the dispersion) and aimingly reduce as much as possible the variance of the network over the prediction, making possible to know how much of incertainity we still have over the label if we try to model it in function of our specific datapoint.
Weight sampling on Bayesian Layers
To do so, on each feedforward operation we sample the parameters of the linear transformation with the following equations (where ρ parametrizes the standard deviation and μ parametrizes the mean for the samples linear transformation parameters) :
For the weights:
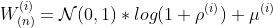
Where the sampled W corresponds to the weights used on the linear transformation for the ith layer on the nth sample.
For the biases:
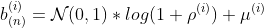
Where the sampled b corresponds to the biases used on the linear transformation for the ith layer on the nth sample.
It is possible to optimize our trainable weights
Even tough we have a random multiplier for our weights and biases, it is possible to optimize them by, given some differentiable function of the weights sampled and trainable parameters (in our case, the loss), summing the derivative of the function relative to both of them:
- Let
- Let
- Let
- Let
be differentiable relative to its variables
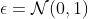
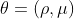
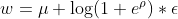
Therefore:
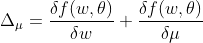
and
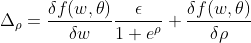
It is also true that there is complexity cost function differentiable along its variables
It is known that the crossentropy loss (and MSE) are differentiable. Therefore if we prove that there is a complexity-cost function that is differentiable, we can leave it to our framework take the derivatives and compute the gradients on the optimization step.
The complexity cost is calculated, on the feedforward operation, by each of the Bayesian Layers, (with the layers pre-defined-simpler apriori distribution and its empirical distribution). The sum of the complexity cost of each layer is summed to the loss.
As proposed in Weight Uncertainty in Neural Networks paper, we can gather the complexity cost of a distribution by taking the Kullback-Leibler Divergence from it to a much simpler distribution, and by making some approximation, we will can differentiate this function relative to its variables (the distributions):
-
Let
be a low-entropy distribution pdf set by hand, which will be assumed as an "a priori" distribution for the weights
-
Let
be the a posteriori empirical distribution pdf for our sampled weights, given its parameters.
Therefore, for each scalar on the W sampled matrix:
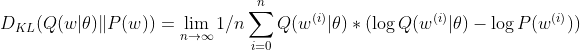
By assuming a very large n, we could approximate:
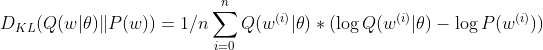
and therefore:
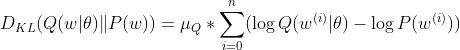
As the expected (mean) of the Q distribution ends up by just scaling the values, we can take it out of the equation (as there will be no framework-tracing). Have a complexity cost of the nth sample as:
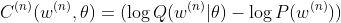
Which is differentiable relative to all of its parameters.
To get the whole cost function at the nth sample:
- Let a performance (fit to data) function be:
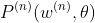
Therefore the whole cost function on the nth sample of weights will be:
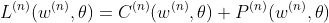
We can estimate the true full Cost function by Monte Carlo sampling it (feedforwarding the netwok X times and taking the mean over full loss) and then backpropagate using our estimated value. It works for a low number of experiments per backprop and even for unitary experiments.
Some notes and wrap up
We came to the and of a Bayesian Deep Learning in a Nutshell tutorial. By knowing what is being done here, you can implement your bnn model as you wish.
Maybe you can optimize by doing one optimize step per sample, or by using this Monte-Carlo-ish method to gather the loss some times, take its mean and then optimizer. Your move.
FYI: Our Bayesian Layers and utils help to calculate the complexity cost along the layers on each feedforward operation, so don't mind it to much.
References:
Citing
If you use BLiTZ in your research, you can cite it as follows:
@misc{esposito2020blitzbdl,
author = {Piero Esposito},
title = {BLiTZ - Bayesian Layers in Torch Zoo (a Bayesian Deep Learing library for Torch)},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/piEsposito/blitz-bayesian-deep-learning/}},
}
Special thanks to Intel Student Ambassador program
Made by Pi Esposito


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file blitz-bayesian-pytorch-0.2.8.tar.gz.
File metadata
- Download URL: blitz-bayesian-pytorch-0.2.8.tar.gz
- Upload date:
- Size: 41.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.10.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0ef8373d438cc895de5c260dd0d82d8d83ec33ad347b118ddc1525d2b0cc21dd
|
|
| MD5 |
bbccb97617174f4367f8e1ab2e142437
|
|
| BLAKE2b-256 |
7622e7c7312bed027fdb05b6efd59cd65703e00d12ca3a4f2871cea34a97592a
|
File details
Details for the file blitz_bayesian_pytorch-0.2.8-py3-none-any.whl.
File metadata
- Download URL: blitz_bayesian_pytorch-0.2.8-py3-none-any.whl
- Upload date:
- Size: 48.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.10.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ab2f43dc9412da5535c07906efc33a8c3d5adf35ce5da6c5f77bfe833a5f4e3a
|
|
| MD5 |
1c2df44e4942f806e45e152f6d38fdfd
|
|
| BLAKE2b-256 |
c8c52461416d1a32c0cd5aa4235b6dc62d20e46d3c12cd69fcaa2c0fecf70f38
|







