BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection

Project description
BLOCK: Bilinear Superdiagonal Fusion for VQA and VRD

In Machine Learning, an important question is "How to fuse two modalities in a same space". For instance, in Visual Question Answering, one must fuse the image and the question embeddings in a same bi-modal space. This multimodal embedding is latter classified to provide the answer.
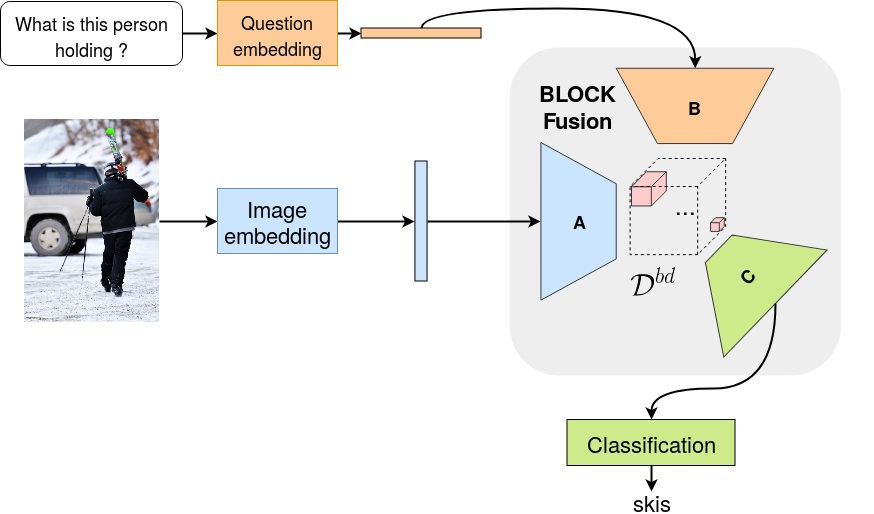
We introduce a novel module (BLOCK) to fuse two representations together. First, we experimentaly demonstrate that it is better than any available fusion for our tasks. Secondly, we provide a theoritical-grounded analysis around the notion of tensor complexity. For further details, please see our AAAI 2019 paper and poster.
In this repo, we make our BLOCK fusion available via pip install including several powerful fusions from the state-of-the-art (MLB, MUTAN, MCB, MFB, MFH, etc.). Also, we provide pretrained models and all the code needed to reproduce our experiments.
Summary
- Installation
- Quick start
- Reproduce results
- Pretrained models
- Fusions
- Useful commands
- Citation
- Poster
- Authors
- Acknowledgment
Installation
1. Python 3 & Anaconda
We don't provide support for python 2. We advise you to install python 3 with Anaconda. Then, you can create an environment.
2. As standalone project
conda create --name block python=3
source activate block
git clone --recursive https://github.com/Cadene/block.bootstrap.pytorch.git
cd block.bootstrap.pytorch
pip install -r requirements.txt
3. Download datasets
Download annotations, images and features for VRD experiments:
bash block/datasets/scripts/download_vrd.sh
Download annotations, images and features for VQA experiments:
bash block/datasets/scripts/download_vqa2.sh
bash block/datasets/scripts/download_vgenome.sh
bash block/datasets/scripts/download_tdiuc.sh
Note: The features have been extracted from a pretrained Faster-RCNN with caffe. We don't provide the code for pretraining or extracting features for now.
(2. As a python library)
By importing the block python module, you can access every fusions, datasets and models in a simple way:
import torch
from block import fusions
mm = fusions.Block([100,100], 300)
inputs = [torch.randn(10,100), torch.randn(10,100)]
out = mm(inputs) # torch.Size([10,300])
# ...
fusions.LinearSum
fusions.ConcatMLP
fusions.MLB
fusions.Mutan
fusions.Tucker
fusions.BlockTucker
fusions.MFB
fusions.MFH
fusions.MCB
# ...
from block.datasets.vqa2 import VQA2
from block.datasets.tdiuc import TDIUC
from block.datasets.vg import VG
from block.datasets.vrd import VRD
# ...
from block.models.networks.vqa_net import VQANet
from block.models.networks.vrd_net import VRDNet
# ...
To be able to do so, you can use pip:
pip install block.bootstrap.pytorch
Or install from source:
git clone https://github.com/Cadene/block.bootstrap.pytorch.git
python setup.py install
Quick start
Train a model
The boostrap/run.py file load the options contained in a yaml file, create the corresponding experiment directory and start the training procedure. For instance, you can train our best model on VRD by running:
python -m bootstrap.run -o block/options/vrd/block.yaml
Then, several files are going to be created in logs/vrd/block:
- options.yaml (copy of options)
- logs.txt (history of print)
- logs.json (batchs and epochs statistics)
- view.html (learning curves)
- ckpt_last_engine.pth.tar (checkpoints of last epoch)
- ckpt_last_model.pth.tar
- ckpt_last_optimizer.pth.tar
- ckpt_best_eval_epoch.predicate.R_50_engine.pth.tar (checkpoints of best epoch)
- ckpt_best_eval_epoch.predicate.R_50_model.pth.tar
- ckpt_best_eval_epoch.predicate.R_50_optimizer.pth.tar
Many options are available in the options directory.
Evaluate a model
At the end of the training procedure, you can evaluate your model on the testing set. In this example, boostrap/run.py load the options from your experiment directory, resume the best checkpoint on the validation set and start an evaluation on the testing set instead of the validation set while skipping the training set (train_split is empty). Thanks to --misc.logs_name, the logs will be written in the new logs_predicate.txt and logs_predicate.json files, instead of being appended to the logs.txt and logs.json files.
python -m bootstrap.run \
-o logs/vrd/block/options.yaml \
--exp.resume best_eval_epoch.predicate.R_50 \
--dataset.train_split \
--dataset.eval_split test \
--misc.logs_name predicate
Reproduce results
VRD dataset
Train and evaluate on VRD
- Train block on trainset with early stopping on valset
- Evaluate the best checkpoint on testset (Predicate Prediction)
- Evaluate the best checkpoint on testset (Relationship and Phrase Detection)
python -m bootstrap.run \
-o block/options/vrd/block.yaml \
--exp.dir logs/vrd/block
python -m bootstrap.run \
-o logs/vrd/block/options.yaml \
--dataset.train_split \
--dataset.eval_split test \
--exp.resume best_eval_epoch.predicate.R_50 \
--misc.logs_name predicate
python -m bootstrap.run \
-o logs/vrd/block/options.yaml \
--dataset.train_split \
--dataset.eval_split test \
--dataset.mode rel_phrase \
--model.metric.name vrd_rel_phrase \
--exp.resume best_eval_epoch.predicate.R_50 \
--misc.logs_name rel_phrase
Note: You can copy past the three commands at once in the terminal to run one after each other seamlessly.
Note: Block is not the only option available. You can find several others here.
Note: Learning curves can be viewed in the experiment directy (logs/vrd/block/view.html). An example is available here.
Note: In our article, we report result for a negative sampling ratio of 0.5. Better results in Predicate Prediction can be achieve with a ratio of 0.0. Better results in Phrase Detection and Relationship Detection can be achieve with a ratio of 0.8. You can change the ratio by doing so:
python -m bootstrap.run \
-o block/options/vrd/block.yaml \
--exp.dir logs/vrd/block_ratio,0.0 \
--dataset.neg_ratio 0.0
Compare experiments on VRD
Finally you can compare experiments on the valset or testset metrics:
python -m block.compare_vrd_val -d \
logs/vrd/block \
logs/vrd/block_tucker \
logs/vrd/mutan \
logs/vrd/mfh \
logs/vrd/mlb
python -m block.compare_vrd_test -d \
logs/vrd/block \
logs/vrd/block_tucker
Example:
## eval_epoch.predicate.R_50
Place Method Score Epoch
------- ------------ ------- -------
1 block 86.3708 13
2 block_tucker 86.2529 9
## eval_epoch.predicate.R_100
Place Method Score Epoch
------- ------------ ------- -------
1 block 92.4588 13
2 block_tucker 91.5816 9
## eval_epoch.phrase.R_50
Place Method Score Epoch
------- ------------ ------- -------
1 block 25.4779 13
2 block_tucker 23.7759 9
## eval_epoch.phrase.R_100
Place Method Score Epoch
------- ------------ ------- -------
1 block 29.7198 13
2 block_tucker 27.9131 9
## eval_epoch.rel.R_50
Place Method Score Epoch
------- ------------ ------- -------
1 block 18.0806 13
2 block_tucker 17.0856 9
## eval_epoch.rel.R_100
Place Method Score Epoch
------- ------------ ------- -------
1 block 21.1181 13
2 block_tucker 19.7565 9
VQA2 dataset
Training and evaluation (train/val)
We use this simple setup to tune our hyperparameters on the valset.
python -m bootstrap.run \
-o block/options/vqa2/block.yaml \
--exp.dir logs/vqa2/block
Training and evaluation (train+val/val/test)
This heavier setup allows us to train a model on 95% of the concatenation of train and val sets, and to evaluate it on the 5% rest. Then we extract the predictions of our best checkpoint on the testset. Finally, we submit a json file on the EvalAI web site.
python -m bootstrap.run \
-o block/options/vqa2/block.yaml \
--exp.dir logs/vqa2/block_trainval \
--dataset.proc_split trainval
python -m bootstrap.run \
-o logs/vqa2/block_trainval/options.yaml \
--exp.resume best_eval_epoch.accuracy_top1 \
--dataset.train_split \
--dataset.eval_split test \
--misc.logs_name test
Training and evaluation (train+val+vg/val/test)
Same, but we add pairs from the VisualGenome dataset.
python -m bootstrap.run \
-o block/options/vqa2/block.yaml \
--exp.dir logs/vqa2/block_trainval_vg \
--dataset.proc_split trainval \
--dataset.vg True
python -m bootstrap.run \
-o logs/vqa2/block_trainval_vg/options.yaml \
--exp.resume best_eval_epoch.accuracy_top1 \
--dataset.train_split \
--dataset.eval_split test \
--misc.logs_name test
Compare experiments on valset
You can compare experiments by displaying their best metrics on the valset.
python -m block.compare_vqa_val -d logs/vqa2/block logs/vqa2/mutan
Submit predictions on EvalAI
It is not possible to automaticaly compute the accuracies on the testset. You need to submit a json file on the EvalAI platform. The evaluation step on the testset creates the json file that contains the prediction of your model on the full testset. For instance: logs/vqa2/block_trainval_vg/results/test/epoch,19/OpenEnded_mscoco_test2015_model_results.json. To get the accuracies on testdev or test sets, you must submit this file.
TDIUC dataset
Training and evaluation (train/val/test)
The full training set is split into a trainset and a valset. At the end of the training, we evaluate our best checkpoint on the testset. The TDIUC metrics are computed and displayed at the end of each epoch. They are also stored in logs.json and logs_test.json.
python -m bootstrap.run \
-o block/options/tdiuc/block.yaml \
--exp.dir logs/tdiuc/block
python -m bootstrap.run \
-o logs/tdiuc/block/options.yaml \
--exp.resume best_eval_epoch.accuracy_top1 \
--dataset.train_split \
--dataset.eval_split test \
--misc.logs_name test
Compare experiments
You can compare experiments by displaying their best metrics on the valset or testset.
python -m block.compare_tdiuc_val -d logs/tdiuc/block logs/tdiuc/mutan
python -m block.compare_tdiuc_test -d logs/tdiuc/block logs/tdiuc/mutan
Pretrained models
Note: These pretrained models have been trained using the Pytorch 1.0 to make sure that our results are reproducible in this version. We also used a more efficient learning rate scheduling strategy which turned out to give slightly better results.
VRD
Download Block:
mkdir -p logs/vrd
cd logs/vrd
wget http://data.lip6.fr/cadene/block/vrd/block.tar.gz
tar -xzvf block.tar.gz
Results python -m block.compare_vrd_test -d logs/vrd/block:
- predicate.R_50: 86.3708
- predicate.R_100: 92.4588
- phrase.R_50: 25.4779
- phrase.R_100: 29.7198
- rel.R_50: 18.0806
- rel.R_100: 21.1181
VQA2
Download Block train/val:
mkdir -p logs/vqa2
cd logs/vqa2
wget http://data.lip6.fr/cadene/block/vqa2/block.tar.gz
tar -xzvf block.tar.gz
Results val (python -m block.compare_vqa2_val -d logs/vqa2/block):
- overall (oe): 63.6
- accuracy_top1: 54.4254
Download Block train+val/val/test:
mkdir -p logs/vqa2
cd logs/vqa2
wget http://data.lip6.fr/cadene/block/vqa2/block_trainval.tar.gz
tar -xzvf block_trainval.tar.gz
Results test-dev (EvalAI):
- overall: 66.74
- yes/no: 83.73
- number: 46.51
- other: 56.84
Download Block train+val+vg/val/test:
mkdir -p logs/vqa2
cd logs/vqa2
wget http://data.lip6.fr/cadene/block/vqa2/block_trainval_vg.tar.gz
tar -xzvf block_trainval_vg.tar.gz
Results test-dev (EvalAI):
- overall: 67.41
- yes/no: 83.89
- number: 46.22
- other: 58.18
TDIUC
Download Block train+val/val/test:
mkdir -p logs/tdiuc
cd logs/tdiuc
wget http://data.lip6.fr/cadene/block/tdiuc/block_trainval.tar.gz
tar -xzvf block_trainval.tar.gz
Results val (python -m block.compare_tdiuc_val -d logs/tdiuc/block):
- accuracy_top1: 88.0195
- acc_mpt_a: 72.2555
- acc_mpt_h: 59.9484
- acc_mpt_a_norm: 60.9635
- acc_mpt_h_norm: 44.7724
Results test (python -m block.compare_tdiuc_test -d logs/tdiuc/block):
- accuracy_top1: 86.3242
- acc_mpt_a: 72.4447
- acc_mpt_h: 66.15
- acc_mpt_a_norm: 58.5728
- acc_mpt_h_norm: 38.8279
Fusions
Block



fusion = fusions.Block([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal the sum of output dimensions of all the D_c tensors (default:
1600) - chunks: number of blocks in the block-diagonal tensor. Equal to C in the previous equations (default:
20) - rank: upper-bound of the rank of mode-3 slice matrices of D_c tensors (default:
15) - shared: boolean that specifies if we want to share the values of input mono-modal projections (default:
False) - dropout_input: dropout rate right after the input projections (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the output linear (default:
0.) - pos_norm: string that specifies if the signed-square root - l2 normalization should be done on every chunk outputs or on the concatenations of every outputs. Accepted values:
'before_cat' and 'after_cat'. (default:'before_cat')
Reference: BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection, *Hedi Ben-younes, Rémi Cadene, Nicolas Thome, Matthieu Cord *
LinearSum

fusion = fusions.LinearSum([100, 100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space (default:
1200) - activ_input: name of the activation function that follows mono-modal projections, before the sum (default:
relu) - activ_output: name of the activation function that follows output projection (default:
relu) - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the activ_input (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the activ_output (default:
0.)
ConcatMLP

fusion = fusions.ConcatMLP([100, 100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- dimensions: list of hidden dimensions (default:
[500,500]) - activation: stringname of the activation function of the network, applied at each layer but the last (default:
'relu') - dropout: dropout rate, applied at each layer but the last (default:
0.)
MLB

fusion = fusions.MLB([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space (default:
1200) - activ_input: name of the activation function that follows mono-modal projections, before the element-wise product (default:
'relu') - activ_output: name of the activation function that follows output projection (default:
'relu') - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the activ_input (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the activ_output (default:
0.)
Reference: Hadamard Product for Low-rank Bilinear Pooling, Jin-Hwa Kim, Kyoung-Woon On, Woosang Lim, Jeonghee Kim, Jung-Woo Ha, Byoung-Tak Zhang
Mutan


fusion = fusions.Mutan([100, 100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal to the output dimensions of the D tensor (default:
1600) - rank: upper-bound of the rank of mode-3 slice matrices of the D tensor (default:
15) - shared: boolean that specifies if we want to share the values of input mono-modal projections (default:
False) - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the input projections (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the output linear (default:
0.)
Reference: MUTAN: Multimodal Tucker Fusion for Visual Question Answering, Hedi Ben-younes*, Rémi Cadene*, Nicolas Thome, Matthieu Cord
Tucker
This module correponds to Mutan without the low-rank constraint on third-mode slices of the D tensor.
fusion = fusions.Tucker([100, 100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal to the output dimensions of the D tensor (default:
1600) - shared: boolean that specifies if we want to share the values of input mono-modal projections (default:
False) - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the input projections (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the output linear (default:
0.)
Reference: MUTAN: Multimodal Tucker Fusion for Visual Question Answering, Hedi Ben-younes*, Rémi Cadene*, Nicolas Thome, Matthieu Cord
BlockTucker
This module correponds to Block without the low-rank constraint on third-mode slices of D_c tensors
fusion = fusions.BlockTucker([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal the sum of output dimensions of all the D_c tensors (default:
1600) - chunks: number of blocks in the block-diagonal tensor. Equal to C in the previous equations (default:
20) - shared: boolean that specifies if we want to share the values of input mono-modal projections (default:
False) - dropout_input: dropout rate right after the input projections (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the output linear (default:
0.) - pos_norm: string that specifies if the signed-square root - l2 normalization should be done on every chunk outputs or on the concatenations of every outputs. Accepted values:
'before_cat' and 'after_cat'. (default:'before_cat')
Reference: BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection, *Hedi Ben-younes, Rémi Cadene, Nicolas Thome, Matthieu Cord *
MFB

fusion = fusions.MFB([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal to the output dimension of the MFB layer (default:
1200) - factor: MFB factor (default:
2) - activ_input: name of the activation function that follows mono-modal projections, before the element-wise product (default:
'relu') - activ_output: name of the activation function that follows output projection (default:
'relu') - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the activ_input (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the activ_output (default:
0.)
Reference: Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering, *Zhou Yu, Jun Yu, Jianping Fan, Dacheng Tao *
MFH

fusion = fusions.MFH([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal to the output dimension of the MFH layer (default:
1200) - factor: MFB factor (default:
2) - activ_input: name of the activation function that follows mono-modal projections, before the element-wise product (default:
'relu') - activ_output: name of the activation function that follows output projection (default:
'relu') - normalize: boolean that specifies whether or not we want to apply the signed square root - l2 normalization (default:
False) - dropout_input: dropout rate right after the activ_input (default:
0.) - dropout_pre_lin: dropout rate just before the output linear (default:
0.) - dropout_output: dropout rate right after the activ_output (default:
0.)
Reference: Beyond Bilinear: Generalized Multi-modal Factorized High-order Pooling for Visual Question Answering, Zhou Yu, Jun Yu, Chenchao Xiang, Jianping Fan, Dacheng Tao
MCB
/!\ Not available in pytorch 1.0 - Avaiable in pytorch 0.3 and 0.4

fusion = fusions.MCB([100,100], 300)
Parameters:
- input_dims: list containing the dimensions of each input vector
- output_dim: desired output dimension
- mm_dim: dimension of the multi-modal space. Here, it is equal to the output dimension of the MCB layer (default:
16000) - activ_output: name of the activation function that follows output projection (default:
'relu') - dropout_output: dropout rate right after the activ_output (default:
0.)
Reference: Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding, Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, Marcus Rohrbach
Useful commands
Use tensorboard instead of plotly
Instead of creating a view.html file, a tensorboard file will be created:
python -m bootstrap.run -o block/options/vqa2/block.yaml \
--view.name tensorboard
tensorboard --logdir=logs/vqa2
You can use plotly and tensorboard at the same time by updating the yaml file like this one.
Use a specific GPU
For a specific experiment:
CUDA_VISIBLE_DEVICES=0 python -m boostrap.run -o block/options/vqa2/block.yaml
For the current terminal session:
export CUDA_VISIBLE_DEVICES=0
Overwrite an option
The boostrap.pytorch framework makes it easy to overwrite a hyperparameter. In this example, we run an experiment with a non-default learning rate. Thus, I also overwrite the experiment directory path:
python -m bootstrap.run -o block/options/vqa2/block.yaml \
--optimizer.lr 0.0003 \
--exp.dir logs/vqa2/block_lr,0.0003
Resume training
If a problem occurs, it is easy to resume the last epoch by specifying the options file from the experiment directory while overwritting the exp.resume option (default is None):
python -m bootstrap.run -o logs/vqa2/block/options.yaml \
--exp.resume last
Web API
TODO
Extract your own image features
TODO
Citation
@InProceedings{BenYounes_2019_AAAI,
author = {Ben-Younes, Hedi and Cadene, Remi and Thome, Nicolas and Cord, Matthieu},
title = {BLOCK: {B}ilinear {S}uperdiagonal {F}usion for {V}isual {Q}uestion {A}nswering and {V}isual {R}elationship {D}etection},
booktitle = {The Thirty-Third AAAI Conference on Artificial Intelligence},
year = {2019},
url = {http://remicadene.com/pdfs/paper_aaai2019.pdf}
}
Poster
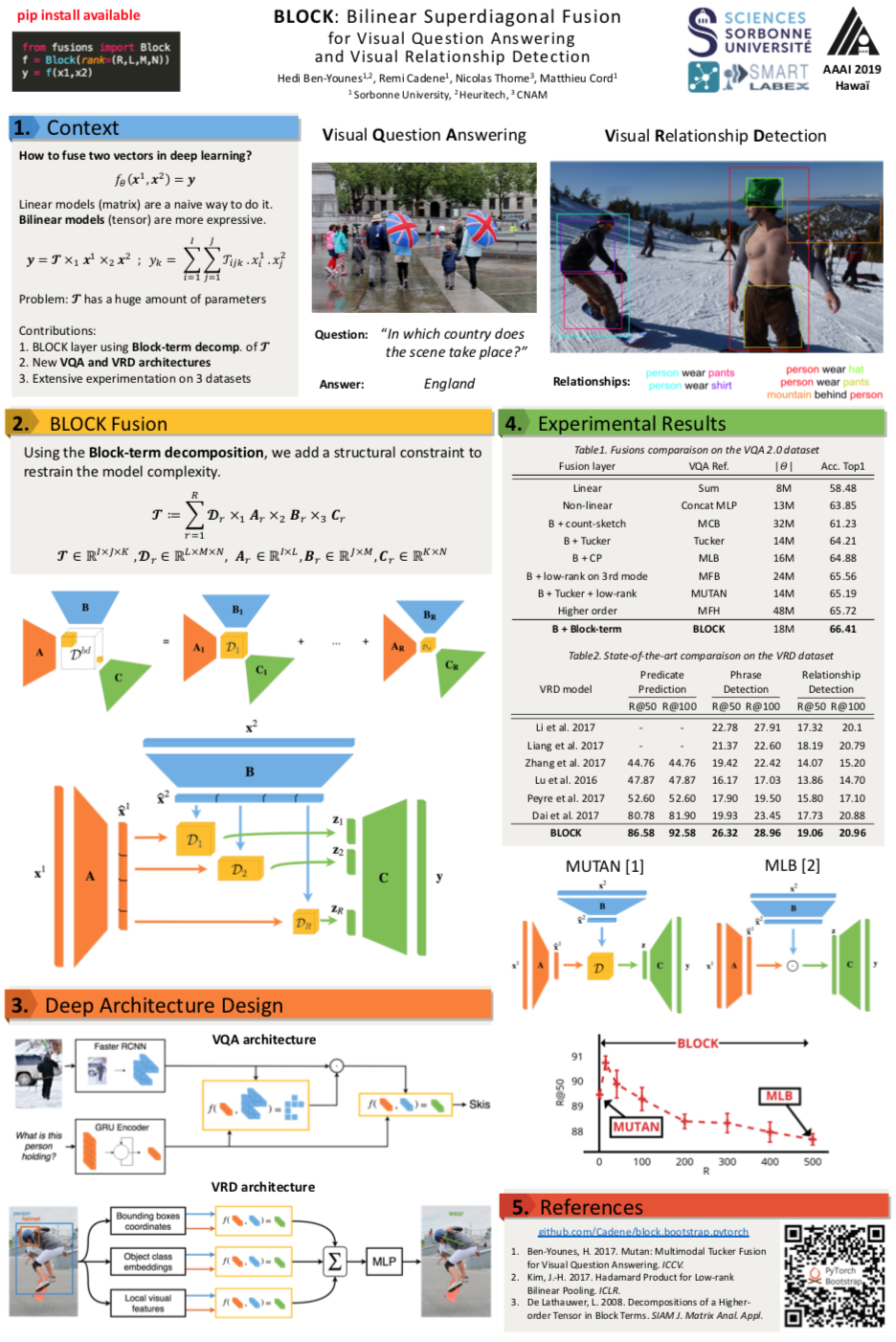
Authors
This code was made available by Hedi Ben-Younes (Sorbonne-Heuritech), Remi Cadene (Sorbonne), Matthieu Cord (Sorbonne) and Nicolas Thome (CNAM).
Acknowledgment
Special thanks to the authors of VQA2, TDIUC, VisualGenome and VRD, the datasets used in this research project.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file block.bootstrap.pytorch-0.1.6.tar.gz.
File metadata
- Download URL: block.bootstrap.pytorch-0.1.6.tar.gz
- Upload date:
- Size: 51.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
91d137248c23970e058195ae20531e83257d3cbca83278e21faafac96f4000fb
|
|
| MD5 |
980d254d839f41e410035ac72d2020af
|
|
| BLAKE2b-256 |
3ab345138c54b7263f460e758f191632c40483fff1d47aa34ed2eb390abb8532
|







