A high-level Web Crawling and Web Scraping framework

Project description
boris-spider

boris-spider是一款使用Python语言编写的爬虫框架,于多年的爬虫业务中不断磨合而诞生,相比于scrapy,该框架更易上手,且又满足复杂的需求,支持分布式及批次采集。
官方文档:https://spider-doc.readthedocs.io
爬虫开发的一些经验分享:https://mp.weixin.qq.com/s/cIUNatRCUtlAi0HAkbmcwA
特性
1. 支持周期性采集
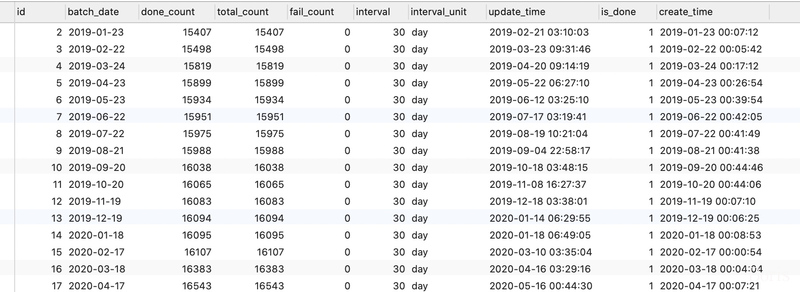
周期性抓取是爬虫中常见的需求,如每日抓取一次商品的销量等,我们把每个周期称为一个批次。
这类爬虫,普遍做法是设置个定时任务,每天启动一次。但你有没有想过,若由于某种原因,定时任务启动程序时没启动起来怎么办?比如服务器资源不够了,启动起来直接被kill了。
另外如何保证每条数据在每个批次内都得以更新呢?
本框架支持批次采集,引入了批次表的概念,详细记录了每一批次的抓取状态
2. 支持分布式
面对海量的数据,分布式采集必不可少的,本框架原生支持分布式,且可随时重启爬虫,任务不丢失
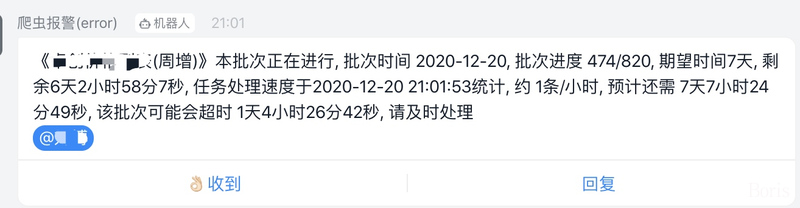
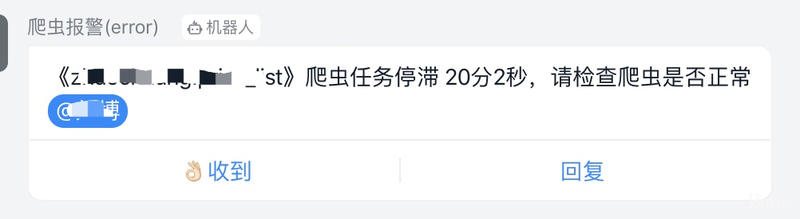
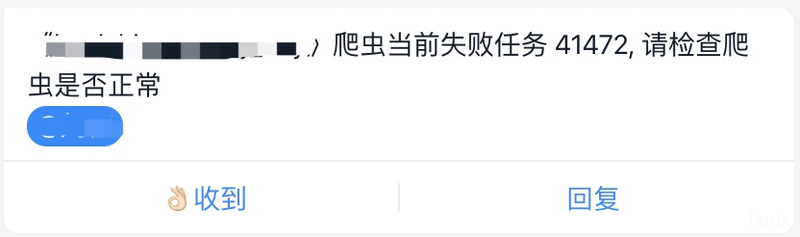
3. 完善的报警机制
为了保证数据的全量性、准确性、时效性,本框架内置报警机制,有了这些报警,我们可以实时掌握爬虫状态
框架流程图
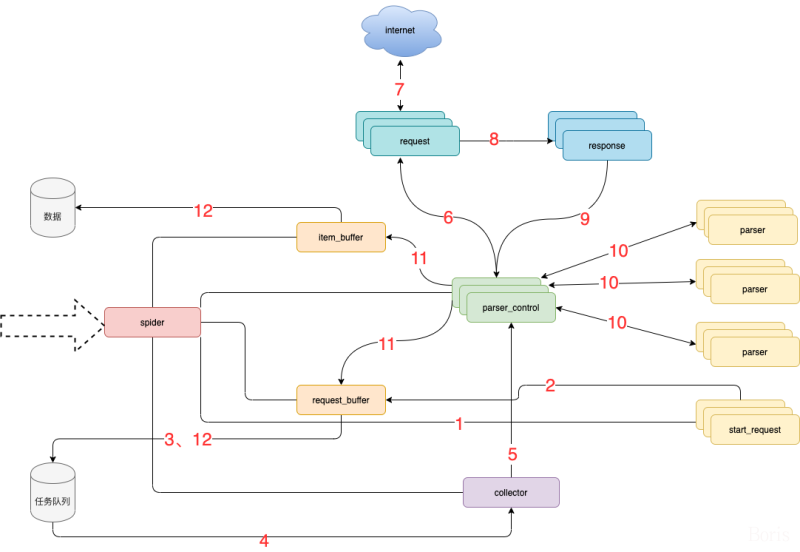
模块说明:
- spider 框架调度核心
- parser_control 模版控制器,负责调度parser
- collector 任务收集器,负责从任务队里中批量取任务到内存,以缓冲对任务队列数据库的访问频率及并发量
- parser 数据解析器
- start_request 初始任务下发函数
- item_buffer 数据缓冲队列,批量将数据存储到数据库中
- request_buffer 请求任务缓冲队列,批量将请求任务存储到任务队列中
- request 数据下载器,封装了requests,用于从互联网上下载数据
- response 数据返回体,封装了response, 支持xpath、css、re等解析方式。自动处理中文乱码
流程说明
- spider调度start_request生产任务
- start_request下发任务到request_buffer中
- spider调度request_buffer批量将任务存储到任务队列数据库中
- spider调度collector从任务队列中批量获取任务到内存队列
- spider调度parser_control从collector的内存队列中获取任务
- parser_control调度request请求数据
- request请求与下载数据
- request将下载后的数据给response,进一步封装
- 将封装好的response返回给parser_control(图示为多个parser_control,表示多线程)
- parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)
- parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_buffer
- spider调度item_buffer与request_buffer将数据批量入库
环境要求:
- Python 3.6.0+
- Works on Linux, Windows, macOS
安装
From PyPi:
pip3 install boris-spider
From Git:
pip3 install git+https://github.com/Boris-code/boris-spider.git
快速上手
创建爬虫
spider create -p first_spider
创建后的爬虫代码如下:
import spider
class FirstSpider(spider.SingleSpider):
def start_requests(self, *args, **kws):
yield spider.Request("https://www.baidu.com")
def parser(self, request, response):
# print(response.text)
print(response.xpath('//input[@type="submit"]/@value').extract_first())
if __name__ == "__main__":
FirstSpider().start()
直接运行,打印如下:
Thread-2|2020-05-19 18:23:41,128|request.py|get_response|line:283|DEBUG|
-------------- FirstSpider.parser request for ----------------
url = https://www.baidu.com
method = GET
body = {'timeout': 22, 'stream': True, 'verify': False, 'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36'}}
百度一下
Thread-2|2020-05-19 18:23:41,727|parser_control.py|run|line:415|INFO| parser 等待任务 ...
FirstSpider|2020-05-19 18:23:44,735|single_spider.py|run|line:83|DEBUG| 无任务,爬虫结束
福利
框架内的utils/tools.py模块下积累了作者多年的工具类函数,种类达到100+,且之后还会不定期更新,具有搬砖价值!
学习交流
想了解更多框架使用详情,可访问官方文档:https://spider-doc.readthedocs.io
如学习中遇到问题,可加下面的QQ群
群号:750614606

知识星球:

星球会不定时分享爬虫技术干货,涉及的领域包括但不限于js逆向技巧、爬虫框架刨析、爬虫技术分享等
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file boris-spider-1.1.3.tar.gz.
File metadata
- Download URL: boris-spider-1.1.3.tar.gz
- Upload date:
- Size: 93.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.6.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ef465294fabcc358905c66c207bc70e0861b8b10dc198f6e66976e18efca0323
|
|
| MD5 |
7d9cd8fdfcefe1ec4611a2adea759d3e
|
|
| BLAKE2b-256 |
65d7b997311224cf874bb150dd4a65fba43638c986a5d661fed76c0302a2dbca
|
File details
Details for the file boris_spider-1.1.3-py3-none-any.whl.
File metadata
- Download URL: boris_spider-1.1.3-py3-none-any.whl
- Upload date:
- Size: 115.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.6.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b9093daf0ceabda7922bb336a3d003f7a40710569ffaad8c38c11533f324f507
|
|
| MD5 |
495af6c1ed96566aa7a342d2f037451c
|
|
| BLAKE2b-256 |
12653bff6c0c09e1b1a0b2fffd4184c27e0b7d0f7c2da60058e7e0da7650d67a
|







