CJK Line Break Organizer

Project description


English text has many clues, like spacing and hyphenation, that enable beautiful and legible line breaks. Some CJK languages lack these clues, and so are notoriously more difficult to process. Without a more careful approach, breaks can occur randomly and usually in the middle of a word. This is a long-standing issue with typography on the web and results in a degradation of readability.
Budou automatically translates CJK sentences into HTML with
lexical chunks wrapped in non-breaking markup, so as to semantically control line
breaks. Budou uses word segmenters to analyze input sentences. It can also
concatenate proper nouns to produce meaningful chunks utilizing
part-of-speech (pos) tagging and other syntactic information. Processed chunks are
wrapped with the SPAN tag. These semantic units will no longer be split at
the end of a line if given a CSS display property set to inline-block.
Installation
The package is listed in the Python Package Index (PyPI), so you can install it with pip:
$ pip install budouOutput
Budou outputs an HTML snippet wrapping chunks with span tags:
<span><span class="ww">常に</span><span class="ww">最新、</span>
<span class="ww">最高の</span><span class="ww">モバイル。</span></span>Semantic chunks in the output HTML will not be split at the end of line by
configuring each span tag with display: inline-block in CSS.
.ww {
display: inline-block;
}By using the output HTML from Budou and the CSS above, sentences on your webpage will be rendered with legible line breaks:
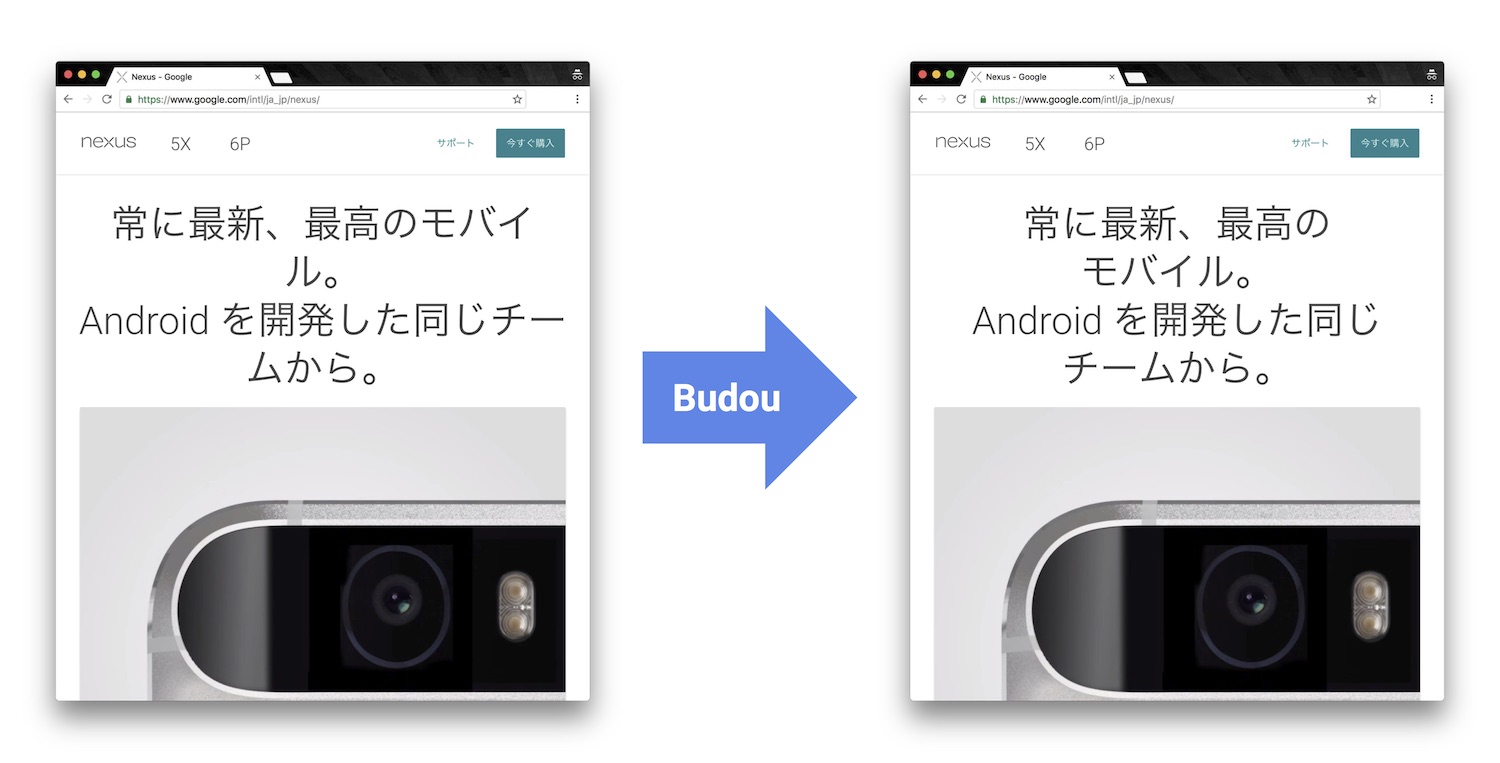
Using as a command-line app
You can process your text by running the budou command:
$ budou 渋谷のカレーを食べに行く。The output is:
<span><span class="ww">渋谷の</span><span class="ww">カレーを</span>
<span class="ww">食べに</span><span class="ww">行く。</span></span>You can also configure the command with optional parameters.
For example, you can change the backend segmenter to MeCab and change the
class name to wordwrap by running:
$ budou 渋谷のカレーを食べに行く。 --segmenter=mecab --classname=wordwrapThe output is:
<span><span class="wordwrap">渋谷の</span><span class="wordwrap">カレーを</span>
<span class="wordwrap">食べに</span><span class="wordwrap">行く。</span></span>Run the help command budou -h to see other available options.
Using programmatically
You can use the budou.parse method in your Python scripts.
import budou
results = budou.parse('渋谷のカレーを食べに行く。')
print(results['html_code'])
# <span><span class="ww">渋谷の</span><span class="ww">カレーを</span>
# <span class="ww">食べに</span><span class="ww">行く。</span></span>You can also make a parser instance to reuse the segmenter backend with the same configuration. If you want to integrate Budou into your web development framework in the form of a custom filter or build process, this would be the way to go.
import budou
parser = budou.get_parser('mecab')
results = parser.parse('渋谷のカレーを食べに行く。')
print(results['html_code'])
# <span><span class="ww">渋谷の</span><span class="ww">カレーを</span>
# <span class="ww">食べに</span><span class="ww">行く。</span></span>
for chunk in results['chunks']:
print(chunk.word)
# 渋谷の 名詞
# カレーを 名詞
# 食べに 動詞
# 行く。 動詞(deprecated) authenticate method
authenticate, which had been the method used to create a parser in
previous releases, is now deprecated.
The authenticate method is now a wrapper around the get_parser method
that returns a parser with the
Google Cloud Natural Language API
segmenter backend.
The method is still available, but it may be removed in a future release.
import budou
parser = budou.authenticate('/path/to/credentials.json')
# This is equivalent to:
parser = budou.get_parser(
'nlapi', credentials_path='/path/to/credentials.json')Available segmenter backends
You can choose different segmenter backends depending on the needs of your environment. Currently, the segmenters below are supported.
Name |
Identifier |
Supported Languages |
|---|---|---|
nlapi |
Chinese, Japanese, Korean |
|
mecab |
Japanese |
|
tinysegmenter |
Japanese |
Specify the segmenter when you run the budou command or load a parser.
For example, you can run the budou command with the MeCab segmenter by
passing the --segmenter=mecab parameter:
$ budou 今日も元気です --segmenter=mecabYou can pass segmenter parameter when you load a parser:
import budou
parser = budou.get_parser('mecab')
parser.parse('今日も元気です')If no segmenter is specified, the Google Cloud Natural Language API is used as the default.
Google Cloud Natural Language API Segmenter
The Google Cloud Natural Language API (https://cloud.google.com/natural-language/) (NL API) analyzes input sentences using machine learning technology. The API can extract not only syntax but also entities included in the sentence, which can be used for better quality segmentation (see more at Entity mode). Since this is a simple REST API, you don’t need to maintain a dictionary. You can also support multiple languages using one single source.
Supported languages
Simplified Chinese (zh)
Traditional Chinese (zh-Hant)
Japanese (ja)
Korean (ko)
For those considering using Budou for Korean sentences, please refer to the Korean support section.
Authentication
The NL API requires authentication before use. First, create a Google Cloud Platform project and enable the Cloud Natural Language API. Billing also needs to be enabled for the project. Then, download a credentials file for a service account by accessing the Google Cloud Console and navigating through “API & Services” > “Credentials” > “Create credentials” > “Service account key” > “JSON”.
Budou will handle authentication once the path to the credentials file is set
in the GOOGLE_APPLICATION_CREDENTIALS environment variable.
$ export GOOGLE_APPLICATION_CREDENTIALS='/path/to/credentials.json'You can also pass the path to the credentials file when you initialize the parser.
parser = budou.get_parser(
'nlapi', credentials_path='/path/to/credentials.json')The NL API segmenter uses Syntax Analysis and incurs costs according to monthly usage. The NL API has free quota to start testing the feature without charge. Please refer to https://cloud.google.com/natural-language/pricing for more detailed pricing information.
Caching system
Parsers using the NL API segmenter cache responses from the API in order to
prevent unnecessary requests to the API and to make processing faster. If you want to
force-refresh the cache, set use_cache to False.
parser = budou.get_parser(segmenter='nlapi', use_cache=False)
result = parser.parse('明日は晴れるかな')In the Google App Engine Python 2.7 Standard Environment, Budou tries to use the memcache service to cache output efficiently across instances. In other environments, Budou creates a cache file in the python pickle format in your file system.
Entity mode
The default parser only uses results from Syntactic Analysis for parsing, but you can also utilize results from Entity Analysis by specifying use_entity=True. Entity Analysis will improve the accuracy of parsing for some phrases, especially proper nouns, so it is recommended if your target sentences include names of individual people, places, organizations, and so on.
Please note that Entity Analysis will result in additional pricing because it requires additional requests to the NL API. For more details about API pricing, please refer to https://cloud.google.com/natural-language/pricing.
import budou
# Without Entity mode (default)
result = budou.parse('六本木ヒルズでご飯を食べます。', use_entity=False)
print(result['html_code'])
# <span class="ww">六本木</span><span class="ww">ヒルズで</span>
# <span class="ww">ご飯を</span><span class="ww">食べます。</span>
# With Entity mode
result = budou.parse('六本木ヒルズでご飯を食べます。', use_entity=True)
print(result['html_code'])
# <span class="ww">六本木ヒルズで</span>
# <span class="ww">ご飯を</span><span class="ww">食べます。</span>MeCab Segmenter
MeCab (https://github.com/taku910/mecab) is an open source text segmentation library for the Japanese language. Unlike the Google Cloud Natural Language API segmenter, the MeCab segmenter does not require any billed API calls, so you can process sentences for free and without an internet connection. You can also customize the dictionary by building your own.
Supported languages
Japanese
Installation
You need to have MeCab installed to use the MeCab segmenter in Budou. You can install MeCab with an IPA dictionary by running
$ make install-mecabin the project’s home directory after cloning this repository.
TinySegmenter-based Segmenter
TinySegmenter (http://chasen.org/~taku/software/TinySegmenter/) is a compact Japanese tokenizer originally created by (c) 2008 Taku Kudo. It tokenizes sentences by matching against a combination of patterns carefully designed using machine learning. This means that you can use this backend without any additional setup!
Supported languages
Japanese
Korean support
Korean has spaces between chunks, so you can perform line breaking simply by putting word-break: keep-all in your CSS. We recommend that you use this technique instead of using Budou.
Use cases
Budou is designed to be used mostly in eye-catching sentences such as titles and headings on the assumption that split chunks would stand out negatively at larger font sizes.
Accessibility
Some screen reader software packages read Budou’s wrapped chunks one by one. This may degrade the user experience for those who need audio support. You can attach any attribute to the output chunks to enhance accessibility. For example, you can make screen readers read undivided sentences by combining the aria-describedby and aria-label attributes in the output.
<p id="description" aria-label="やりたいことのそばにいる">
<span class="ww" aria-describedby="description">やりたい</span>
<span class="ww" aria-describedby="description">ことの</span>
<span class="ww" aria-describedby="description">そばに</span>
<span class="ww" aria-describedby="description">いる</span>
</p>This functionality is currently nonfunctional due to the html5lib sanitizer’s behavior, which strips ARIA-related attributes from the output HTML. Progress on this issue is tracked at https://github.com/google/budou/issues/74
Disclaimer
This library is authored by a Googler and copyrighted by Google, but is not an official Google product.
License
Copyright 2018 Google LLC
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License. You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file budou-0.9.8.tar.gz.
File metadata
- Download URL: budou-0.9.8.tar.gz
- Upload date:
- Size: 22.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.37.0 CPython/3.7.5rc1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25c473f1fe7b2e4aac40e58de2544e2b9b29c3d39cb60d7f1b3745332928b6ea
|
|
| MD5 |
0ecb564679445cecf6b7eeae9488bd73
|
|
| BLAKE2b-256 |
474edd1ea384ce12e3ede48f882c0a3253ee45c91e3922fb391179773b13ad22
|
File details
Details for the file budou-0.9.8-py2.py3-none-any.whl.
File metadata
- Download URL: budou-0.9.8-py2.py3-none-any.whl
- Upload date:
- Size: 28.6 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.37.0 CPython/3.7.5rc1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0397dd010d1c8d0292b243853cbd6d0e8bf0946abbf56fbc7eb22623e179ec7a
|
|
| MD5 |
308c6fc8d52866229d17775a86537717
|
|
| BLAKE2b-256 |
7a03f0d9c8356054bd499a13782bd7cbf702130451134a424c4b8c94353b3326
|







