Structured parsing, normalisation, and resolution of German federal law references
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
bundesrecht
Python package for parsing, normalising, and resolving German federal law references.
Zero dependencies. Pure Python 3.10+.
Contents
- Simplified architecture
- Installation
- Parsing references
- Data model
- Normalising references
- What the normaliser handles
- Resolving references
- Corpus cache
- QueryResult
- LawData
- Resolved depth reference
- Complete example
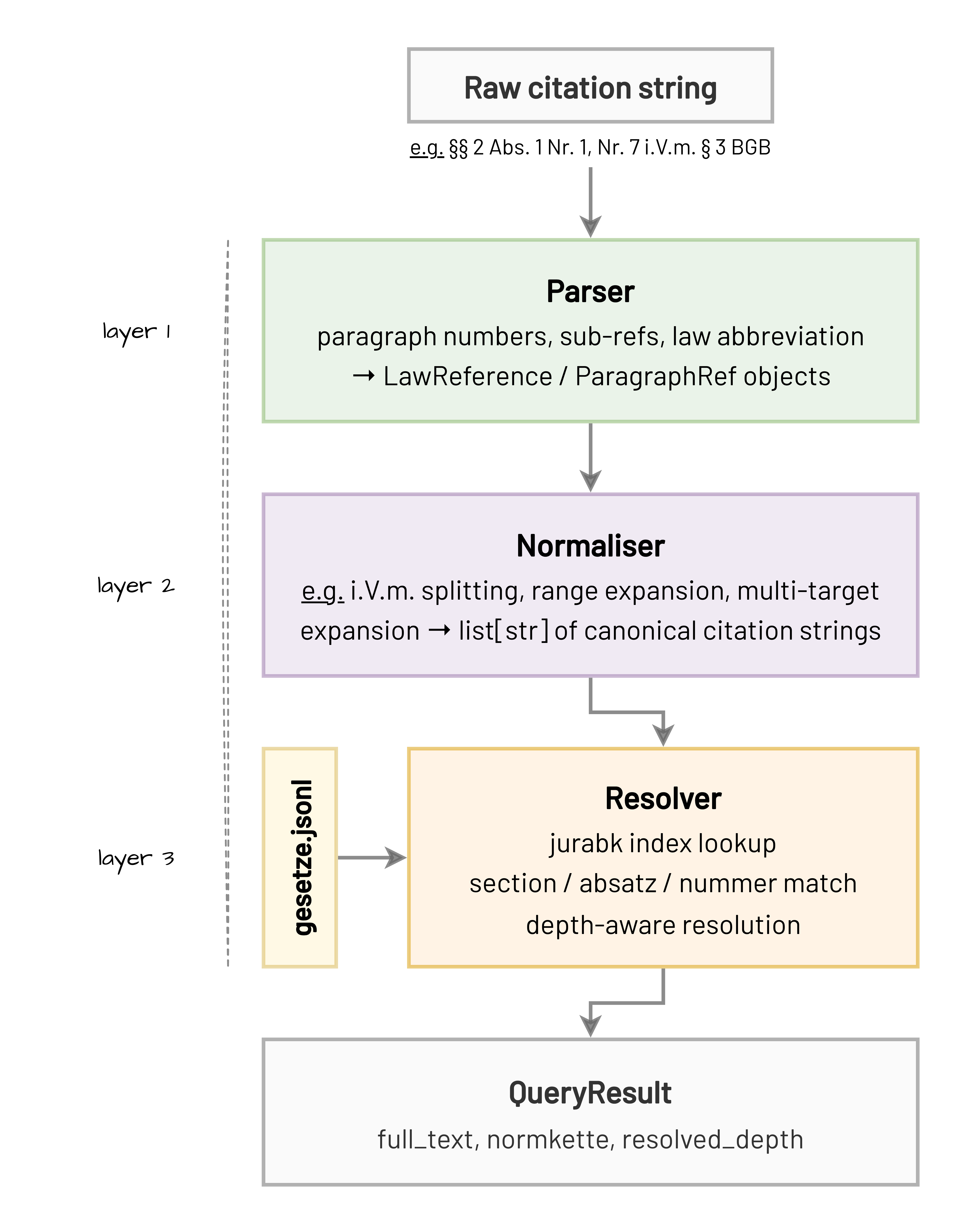
Simplified architecture
The library is built in three layers. The parser is the foundational brick, identifying the structure of any German citation string. The normaliser builds on the parser to handle expansion and produce canonical strings. The resolver builds on both to look up actual statutory text from the corpus.
All three layers are exposed as public APIs. Use parse_reference() when you only need structured extraction. Use normalise() when you need canonical strings without corpus lookup. Use query() when you need the actual statutory text.
Installation
pip install bundesrecht
Parsing references
Parses a raw citation string into a structured LawReference object
without resolving it against any law data.
from bundesrecht import parse_reference
ref = parse_reference('§ 2 Abs. 1 Nr. 1 UrhG')
ref.law # → 'UrhG'
ref.paragraphs # → [ParagraphRef(...)]
str(ref) # → '§ 2 Abs. 1 Nr. 1 UrhG'
para = ref.paragraphs[0]
para.paragraph # → '2'
para.sub_refs # → [SubReference(Abs, '1'), SubReference(Nr, '1')]
str(para.sub_refs[0]) # → 'Abs. 1'
str(para.sub_refs[1]) # → 'Nr. 1'
Data model
Three dataclasses represent a parsed reference at increasing levels of specificity.
These objects are returned by parse_reference() and are also exposed through QueryResult.reference.
LawReference
@dataclass
class LawReference:
paragraphs: list[ParagraphRef] # one or more paragraphs
law: str | None # e.g. 'BGB', 'UrhG'
raw: str # original input string
ParagraphRef
@dataclass
class ParagraphRef:
paragraph: str # '312', '312a', '1'
sub_refs: list[SubReference] # Abs, Satz, Nr, Buchst, etc.
range_end: str | None # set for '§ 312 bis 314'
is_ff: bool # § 312 ff.
is_f: bool # § 312 f.
ivm_refs: list[SubReference] # sub-refs after 'iVm' within a paragraph
SubReference
@dataclass
class SubReference:
level: str # 'Abs', 'Satz', 'Nr', 'Buchst', 'Alt', 'Halbsatz'
number: str # '1', '2', 'a', '1a'
range_end: str # set for 'Abs. 2 bis 4'
String representations:
| level | example output |
|---|---|
| Abs | Abs. 2 |
| Satz | Satz 1 |
| Nr | Nr. 3 |
| Buchst | Buchst. a |
| Alt | Alt. 1 |
| Halbsatz | Halbsatz 2 |
Normalising references
Available directly without loading any law data.
from bundesrecht import normalise
normalise('§ 312 i.V.m. § 355 BGB')
# → ['§ 312 BGB', '§ 355 BGB']
normalise('§§ 12-15 BGB')
# → ['§ 12 BGB', '§ 13 BGB', '§ 14 BGB', '§ 15 BGB']
normalise('§ 2 Abs. 1 Nr. 1, Nr. 7, Abs. 2 UrhG')
# → ['§ 2 Abs. 1 Nr. 1 UrhG', '§ 2 Abs. 1 Nr. 7 UrhG', '§ 2 Abs. 2 UrhG']
normalise('§§ 137 S. 2, 398, 903 BGB')
# → ['§ 137 Satz 2 BGB', '§ 398 BGB', '§ 903 BGB']
normalise('§§ 46 Abs. 2 ArbGG, 91 Abs. 1 ZPO')
# → ['§ 46 Abs. 2 ArbGG', '§ 91 Abs. 1 ZPO']
# iVm variants - all recognised
normalise('§ 1 iVm § 2 BGB')
normalise('§ 1 i.V.m. § 2 BGB')
normalise('§ 1 i. V. m. § 2 BGB')
# → ['§ 1 BGB', '§ 2 BGB'] in all cases
# S. expands to Satz
normalise('§ 1 S. 2 BGB')
# → ['§ 1 Satz 2 BGB']
# f. always expands to exactly 2 paragraphs
normalise('§ 312 f. BGB')
# → ['§ 312 BGB', '§ 313 BGB']
# ff. is preserved by default - pass ff_expansion to expand
normalise('§ 312 ff. BGB')
# → ['§ 312 ff. BGB']
normalise('§ 312 ff. BGB', ff_expansion=3)
# → ['§ 312 BGB', '§ 313 BGB', '§ 314 BGB']
normalise('§ 312 ff. BGB', ff_expansion=5)
# → ['§ 312 BGB', '§ 313 BGB', '§ 314 BGB', '§ 315 BGB', '§ 316 BGB']
What the normaliser handles
| Input form | Output |
|---|---|
§ 312 i.V.m. § 355 BGB |
['§ 312 BGB', '§ 355 BGB'] |
§ 312 iVm § 355 BGB |
['§ 312 BGB', '§ 355 BGB'] |
§§ 12-15 BGB |
['§ 12 BGB', ..., '§ 15 BGB'] |
§§ 12 bis 15 BGB |
same |
§§ 137 S. 2, 398 BGB |
['§ 137 Satz 2 BGB', '§ 398 BGB'] |
§§ 46 Abs. 2 ArbGG, 91 ZPO |
['§ 46 Abs. 2 ArbGG', '§ 91 ZPO'] |
§ 2 Abs. 1 Nr. 1, Nr. 7, Abs. 2 |
three separate canonical refs |
§ 1 S. 2 BGB |
['§ 1 Satz 2 BGB'] |
§ 312 f. BGB |
['§ 312 BGB', '§ 313 BGB'] |
§ 312 ff. BGB |
['§ 312 ff. BGB'] (preserved by default) |
§ 312 ff. BGB (ff_expansion=3) |
['§ 312 BGB', '§ 313 BGB', '§ 314 BGB'] |
§312 BGB (no space) |
['§ 312 BGB'] |
Ranges with letter suffixes (§§ 12a-12c) are left unchanged because
intermediate values are not predictable.
Resolving references
Bundesrecht is the dataset-backed entry point for resolving references.
Load once, query as many times as you like.
from bundesrecht import Bundesrecht
lib = Bundesrecht()
By default, Bundesrecht() uses the corpus version pinned to the installed
package. It loads the compatible cached corpus if present, or downloads the
matching public gesetze.jsonl from Hugging Face on first use.
For offline or reproducible work with an explicit corpus file:
lib = Bundesrecht(local_path='data/gesetze.jsonl')
lib.query(raw)
Normalises a raw citation string and resolves each canonical reference.
Returns list[QueryResult].
# Simple paragraph
results = lib.query('§ 242 BGB')
# Paragraph + Absatz
results = lib.query('§ 433 Abs. 1 BGB')
# Paragraph + Absatz + Nummer
results = lib.query('§ 2 Abs. 1 Nr. 1 UrhG')
# Multi-target: expands into 3 separate results
results = lib.query('§ 2 Abs. 1 Nr. 1, Nr. 7, Abs. 2 UrhG')
# → QueryResult for § 2 Abs. 1 Nr. 1 UrhG
# → QueryResult for § 2 Abs. 1 Nr. 7 UrhG
# → QueryResult for § 2 Abs. 2 UrhG
# i.V.m.: expands into 2 separate results
results = lib.query('§ 312 i.V.m. § 355 BGB')
# → QueryResult for § 312 BGB
# → QueryResult for § 355 BGB
# §§ range: expands into one result per paragraph
results = lib.query('§§ 12-15 BGB')
# → § 12, § 13, § 14, § 15
# §§ with separate laws per chunk
results = lib.query('§§ 46 Abs. 2 ArbGG, 91 Abs. 1 ZPO')
# → § 46 Abs. 2 ArbGG
# → § 91 Abs. 1 ZPO
# Satz reference
results = lib.query('§ 1 Satz 2 BGB')
# Buchstabe reference
results = lib.query('§ 2 Abs. 1 Nr. 1 Buchst. a UrhG')
lib.query_canonical(canonical)
Skips normalisation and resolves a pre-cleaned reference directly. Use this when you have already normalised the string yourself.
results = lib.query_canonical('§ 2 Abs. 1 Nr. 1 UrhG')
lib.normalise(raw)
Normalises a citation string without resolving it.
Returns list[str] of canonical strings.
lib.normalise('§ 312 i.V.m. § 355 BGB')
# → ['§ 312 BGB', '§ 355 BGB']
lib.normalise('§§ 12-15 BGB')
# → ['§ 12 BGB', '§ 13 BGB', '§ 14 BGB', '§ 15 BGB']
lib.normalise('§ 2 Abs. 1 Nr. 1, Nr. 7, Abs. 2 UrhG')
# → ['§ 2 Abs. 1 Nr. 1 UrhG', '§ 2 Abs. 1 Nr. 7 UrhG', '§ 2 Abs. 2 UrhG']
lib.get_law(abbreviation)
Returns a LawData object for a law by its abbreviation. Case-insensitive.
Returns None if not found.
bgb = lib.get_law('BGB')
bgb = lib.get_law('bgb') # same result
lib.available_laws
Sorted list of all law abbreviations currently loaded.
lib.available_laws[:5]
# → ['1-DM-GOLDMÜNZG', '1. BESVNG', '1. BIMSCHV', '1. BMELDDÜV', '1. DV LUFTBO']
lib.law_count
Number of distinct laws loaded.
lib.law_count # → 6873
Corpus cache
The PyPI package ships code only. It does not bundle the full corpus and does not download data during installation.
On first Bundesrecht() use, the package checks a commit-keyed cache:
~/.cache/bundesrecht/<pinned-data-commit>/gesetze.jsonl
If the compatible file is missing, it downloads the exact Hugging Face dataset commit pinned by this package version and validates the JSONL structure before loading it. Later calls reuse the cached file.
To choose a different cache root, set:
export BUNDESRECHT_CACHE_DIR=/path/to/cache
To avoid network access entirely, pass a local file:
lib = Bundesrecht(local_path='data/gesetze.jsonl')
Local files are validated before loading. If a local file does not match the
expected corpus shape, use Bundesrecht() to load the package-managed corpus.
QueryResult
Returned by query() and query_canonical(). One object per resolved reference.
r = lib.query('§ 433 Abs. 1 BGB')[0]
r.full_text()
Returns the text at the resolved depth - Satz text if a Satz was resolved, Nummer text if a Nummer was resolved, Absatz text if an Absatz was resolved, or the full section content if only the paragraph was found.
r.full_text()
# → 'Durch den Kaufvertrag wird der Verkäufer einer Sache verpflichtet...'
r.titel()
Returns the section heading (Überschrift), if one exists.
r.titel()
# → 'Vertragstypische Pflichten beim Kaufvertrag'
r.resolved_depth
String indicating how deeply the reference was resolved.
One of: 'section', 'absatz', 'satz', 'nummer', 'buchstabe', 'unterbuchstabe'.
r.resolved_depth # → 'absatz' (Absatz found, but no Nummer requested)
r.resolution_note
Human-readable explanation when the requested depth was not fully resolved. Empty string when resolution was complete.
r.resolution_note
# → '' (fully resolved)
# → 'Buchstabe c not found in Nr. 1' (partial resolution)
r.reference
The parsed LawReference object for this result.
r.reference.law # → 'BGB'
r.reference.paragraphs # → [ParagraphRef(paragraph='433', ...)]
str(r.reference) # → '§ 433 Abs. 1 BGB'
r.law_data
The LawData object for the parent statute.
r.law_data.jurabk # → 'BGB'
r.law_data.gesetze_id # → 'BGB::BJNR001950896'
r.law_data.metadaten.get('langtitel') # → 'Bürgerliches Gesetzbuch'
r.law_data.metadaten.get('ausfertigung_datum') # → '1896-08-18'
len(r.law_data.sections) # → 2541
r.section
Raw dict of the resolved section, or None if not found.
r.section.get('titel') # same as r.titel()
r.section.get('content') # list of content blocks
r.resolved_para
The specific ParagraphRef that was matched (after multi-target expansion).
str(r.resolved_para) # → '433 Abs. 1'
LawData
Returned by lib.get_law() and available as result.law_data.
bgb = lib.get_law('BGB')
Attributes
bgb.jurabk # → 'BGB' abbreviation
bgb.gesetze_id # → 'BGB::BJNR001950896' internal corpus ID
bgb.metadaten # → dict full metadata
bgb.sections # → dict all sections keyed by paragraph string
bgb.fussnoten # → list footnotes at law level
bgb.quelle # → dict source metadata
Useful metadaten keys
bgb.metadaten.get('langtitel') # → 'Bürgerliches Gesetzbuch'
bgb.metadaten.get('kurztitel') # short title if present
bgb.metadaten.get('ausfertigung_datum') # → '1896-08-18'
bgb.metadaten.get('fundstelle', {}).get('periodikum') # → 'RGBl'
bgb.metadaten.get('fundstelle', {}).get('zitstelle') # → '1896, 195'
bgb.get_section(paragraph)
Look up a section by paragraph number string.
sec = bgb.get_section('433')
sec['titel'] # → 'Vertragstypische Pflichten beim Kaufvertrag'
sec['content'] # → list of Absatz dicts
bgb.get_absatz(paragraph, absatz)
Look up a specific Absatz within a section.
abs1 = bgb.get_absatz('433', 1)
abs1 = bgb.get_absatz('433', '1') # string also works
Resolved depth reference
resolved_depth |
Meaning |
|---|---|
'section' |
Only the paragraph was found (no sub-ref match) |
'absatz' |
Absatz resolved, Nummer was not requested/found |
'nummer' |
Nummer resolved, Buchstabe not requested/found |
'buchstabe' |
Buchstabe resolved, Unterbuchstabe not requested/found |
'unterbuchstabe' |
Fully resolved to Unterbuchstabe level (aa), bb)) |
Complete example
from bundesrecht import Bundesrecht, normalise, parse_reference
# Load
lib = Bundesrecht()
print(lib) # → Bundesrecht(6873 laws loaded)
# Parse only
ref = parse_reference('§ 433 Abs. 1 Satz 1 BGB')
ref.law # → 'BGB'
ref.paragraphs[0].paragraph # → '433'
ref.paragraphs[0].sub_refs # → [SubReference(Abs,1), SubReference(Satz,1)]
# Normalise only
normalise('§ 2 Abs. 1 Nr. 1, Nr. 7, Abs. 2 UrhG')
# → ['§ 2 Abs. 1 Nr. 1 UrhG', '§ 2 Abs. 1 Nr. 7 UrhG', '§ 2 Abs. 2 UrhG']
# Resolve
results = lib.query('§ 433 Abs. 1 BGB')
r = results[0]
r.titel() # → 'Vertragstypische Pflichten beim Kaufvertrag'
r.full_text() # → actual statutory text of Abs. 1
r.resolved_depth # → 'absatz' (Absatz found, but no Nummer requested)
str(r.reference) # → '§ 433 Abs. 1 BGB'
# Inspect a law directly
bgb = lib.get_law('BGB')
bgb.metadaten.get('langtitel') # → 'Bürgerliches Gesetzbuch'
bgb.metadaten.get('ausfertigung_datum') # → '1896-08-18'
len(bgb.sections) # → 2541
# List all laws
lib.available_laws[:5] # → ['1-DM-GOLDMÜNZG', '1. BESVNG', ...]
lib.law_count # → 6873
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file bundesrecht-0.1.0.tar.gz.
File metadata
- Download URL: bundesrecht-0.1.0.tar.gz
- Upload date:
- Size: 33.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
abcf3ecf03c3398a457e6c48d24a1e1c13100636695aad852cfc4af2b634779a
|
|
| MD5 |
b4249f9aaaa6f3647edbe05ef884f4ee
|
|
| BLAKE2b-256 |
629e941ea92c4092e02cb05802133a60fd8c04a1676b58c317c94f6ff3b7c4b9
|
Provenance
The following attestation bundles were made for bundesrecht-0.1.0.tar.gz:
Publisher:
release.yml on harshildarji/bundesrecht
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
bundesrecht-0.1.0.tar.gz -
Subject digest:
abcf3ecf03c3398a457e6c48d24a1e1c13100636695aad852cfc4af2b634779a - Sigstore transparency entry: 1647746142
- Sigstore integration time:
-
Permalink:
harshildarji/bundesrecht@295748b50d0fc2c1b4f9ee8b55ff30d277bd18b1 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/harshildarji
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@295748b50d0fc2c1b4f9ee8b55ff30d277bd18b1 -
Trigger Event:
release
-
Statement type:
File details
Details for the file bundesrecht-0.1.0-py3-none-any.whl.
File metadata
- Download URL: bundesrecht-0.1.0-py3-none-any.whl
- Upload date:
- Size: 32.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
81584bef4aee69871630615a6cc30296d2f4df21c6d7983755d212860925ce7e
|
|
| MD5 |
339b8e3568a2ee6140c7ce13fed5e068
|
|
| BLAKE2b-256 |
c2cd75d6c68648aef29a84a85b0c56c93e454de800b80ca38de0646377f8e7d9
|
Provenance
The following attestation bundles were made for bundesrecht-0.1.0-py3-none-any.whl:
Publisher:
release.yml on harshildarji/bundesrecht
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
bundesrecht-0.1.0-py3-none-any.whl -
Subject digest:
81584bef4aee69871630615a6cc30296d2f4df21c6d7983755d212860925ce7e - Sigstore transparency entry: 1647746481
- Sigstore integration time:
-
Permalink:
harshildarji/bundesrecht@295748b50d0fc2c1b4f9ee8b55ff30d277bd18b1 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/harshildarji
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@295748b50d0fc2c1b4f9ee8b55ff30d277bd18b1 -
Trigger Event:
release
-
Statement type:







