Cache-DiT: A PyTorch-native Inference Engine with Cache, Parallelism and Quantization for Diffusion Transformers.

Project description
 ⚡️🎉A PyTorch-native Inference Engine with Cache,
⚡️🎉A PyTorch-native Inference Engine with Cache,
Parallelism, Quantization for Diffusion Transformers





🤗Why Cache-DiT❓❓Cache-DiT is built on top of the 🤗Diffusers library and now supports nearly ALL DiTs from Diffusers. It provides hybrid cache acceleration (DBCache, TaylorSeer, SCM, etc.) and comprehensive parallelism optimizations, including Context Parallelism, Tensor Parallelism, hybrid 2D or 3D parallelism, and dedicated extra parallelism support for Text Encoder, VAE, and ControlNet.
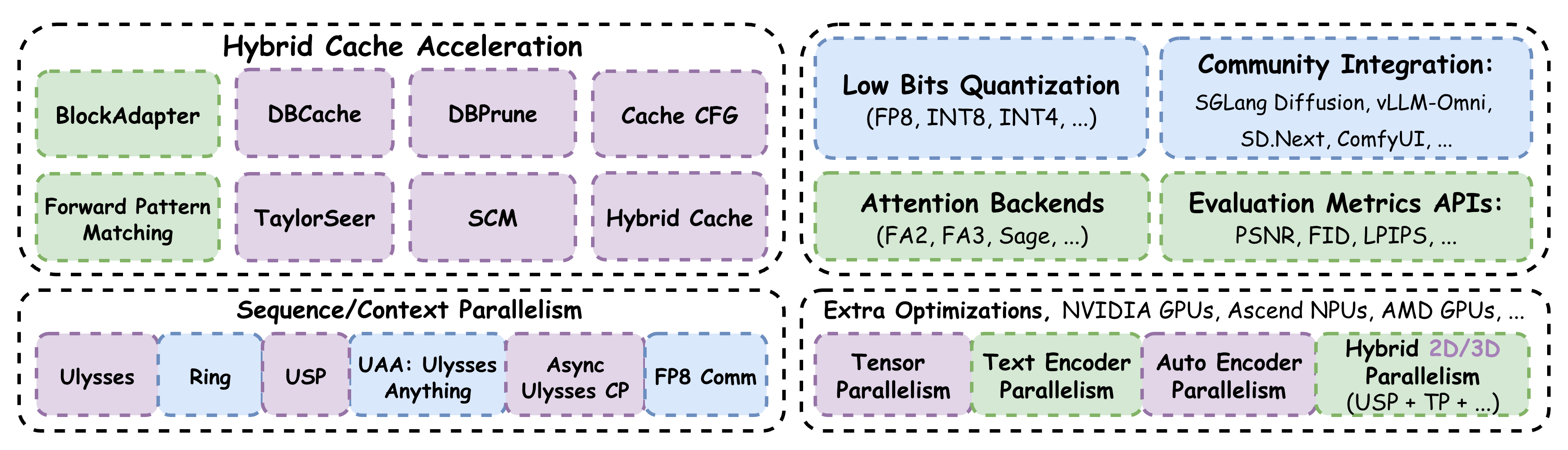
Cache-DiT is compatible with compilation, CPU Offloading, and quantization, fully integrates with SGLang Diffusion, vLLM-Omni, TensorRT-LLM, ComfyUI, and runs natively on NVIDIA GPUs, Ascend NPUs and AMD GPUs. Cache-DiT is fast, easy to use, and flexible for various DiTs (online docs at 📘cache-dit.io).
⚡️9x speedup by Cache-DiT with Cache, Context Parallelism and Compilation

🚀Quick Start: Cache, Parallelism and Quantization
First, you can install the cache-dit from PyPI or install from source:
uv pip install -U cache-dit # PyPI, stable release.
uv pip install git+https://github.com/vipshop/cache-dit.git # latest
Then, try to accelerate your DiTs with just ♥️one line♥️ of code ~
>>> import cache_dit
>>> from diffusers import DiffusionPipeline
>>> pipe = DiffusionPipeline.from_pretrained(...).to("cuda")
>>> cache_dit.enable_cache(pipe) # Cache Acceleration with One-line code.
>>> from cache_dit import DBCacheConfig, ParallelismConfig
>>> cache_dit.enable_cache( # Or, Hybrid Cache Acceleration + Parallelism.
... pipe, cache_config=DBCacheConfig(), # w/ default
... parallelism_config=ParallelismConfig(ulysses_size=2))
>>> from cache_dit import DBCacheConfig, ParallelismConfig, QuantizeConfig
>>> cache_dit.enable_cache( # Or, Hybrid Cache + Parallelism + Quantization.
... pipe, cache_config=DBCacheConfig(), # w/ default
... parallelism_config=ParallelismConfig(ulysses_size=2),
... quantize_config=QuantizeConfig(quant_type=...))
>>> output = pipe(...) # Then, just call the pipe as normal.
🚀Quick Start: SVDQuant (W4A4) PTQ/DQ workflow
First, install Cache-DiT with SVDQuant support (Experimental):
# Required: CUDA 13.0+, PyTorch 2.11+, Ubuntu 22.04+ (GLIBC 2.32+).
uv pip install -U cache-dit-cu13 # PyPI, stable release with SVDQ.
CACHE_DIT_BUILD_SVDQUANT=1 uv pip install -e ".[quantization]" # latest
Then, try to quantize your model with just ♥️a few lines♥️ of codes ~
>>> from cache_dit import QuantizeConfig
>>> pipe = DiffusionPipeline.from_pretrained(...).to("cuda")
>>> # Apply quantization with `cache_dit.quantize(...)` API.
>>> pipe.transformer = cache_dit.quantize(
... pipe.transformer, quant_config=QuantizeConfig(
... quant_type="svdq_{int4|nvfp4}_r128_dq", # _r{rank}, e.g., r16, r32, r64, r128, etc.
... svdq_kwargs={"smooth_strategy": "few_shot"}))
>>> output = pipe(...) # Then, just call the pipe as normal.
For more advanced features, please refer to our online documentation at 📘cache-dit.io.
🌐Community Integration
- 🎉ComfyUI x Cache-DiT
- 🎉(Intel) llm-scaler x Cache-DiT
- 🎉Diffusers x Cache-DiT
- 🎉TensorRT-LLM x Cache-DiT
- 🎉SGLang Diffusion x Cache-DiT
- 🎉vLLM-Omni x Cache-DiT
- 🎉Nunchaku x Cache-DiT
- 🎉SD.Next x Cache-DiT
- 🎉stable-diffusion.cpp x Cache-DiT
- 🎉jetson-containers x Cache-DiT
©️Acknowledgements
Special thanks to vipshop's Computer Vision AI Team for supporting testing and deployment of this project. We learned and reused codes from: Diffusers, SGLang, vLLM-Omni, Nunchaku, xDiT and TaylorSeer.
©️Citations
@misc{cache-dit@2025,
title={Cache-DiT: A PyTorch-native Inference Engine with Cache, Parallelism and Quantization for Diffusion Transformers.},
url={https://github.com/vipshop/cache-dit.git},
note={Open-source software available at https://github.com/vipshop/cache-dit.git},
author={DefTruth, vipshop.com, etc.},
year={2025}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file cache_dit-1.3.11-py3-none-any.whl.
File metadata
- Download URL: cache_dit-1.3.11-py3-none-any.whl
- Upload date:
- Size: 468.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6f2361acf14c78f8578b86aff57dfccadd6c8c5c7b4907d17a885344775a6431
|
|
| MD5 |
9ccd763ac7f682ca0d5820c6353b7570
|
|
| BLAKE2b-256 |
a207850ead88080407899b1df1fe7df3d7ca461053ae0b7f52723b452fb6d283
|







