A simple, yet elegant, LLM API routing library
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description





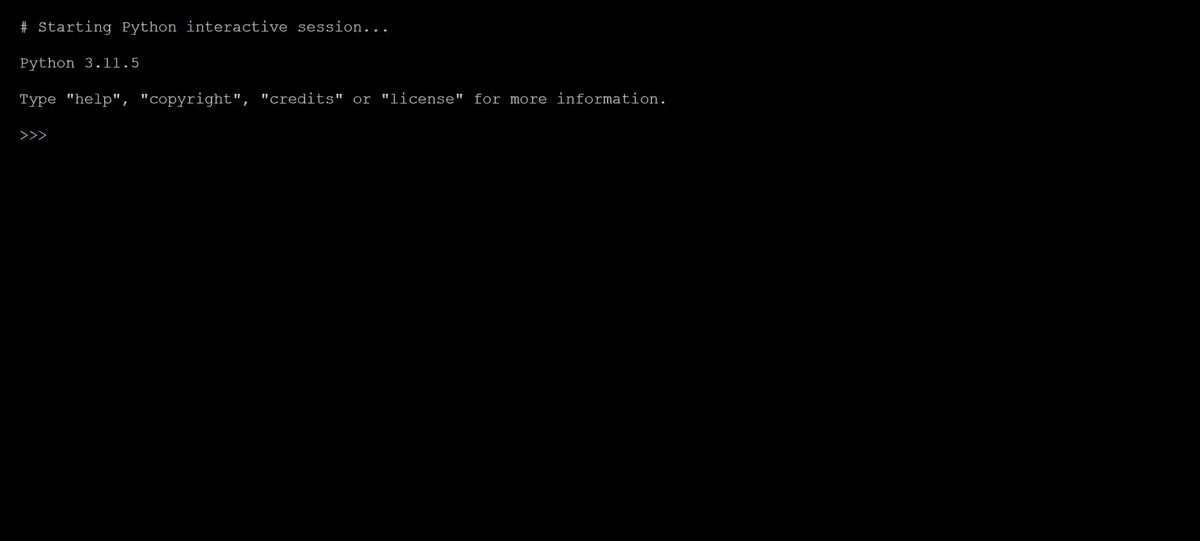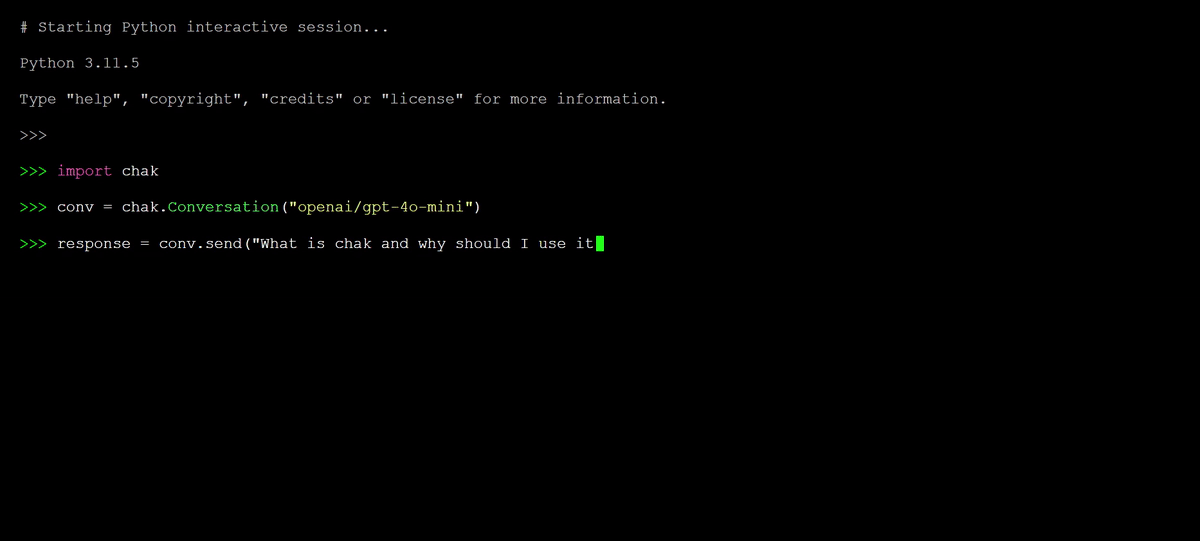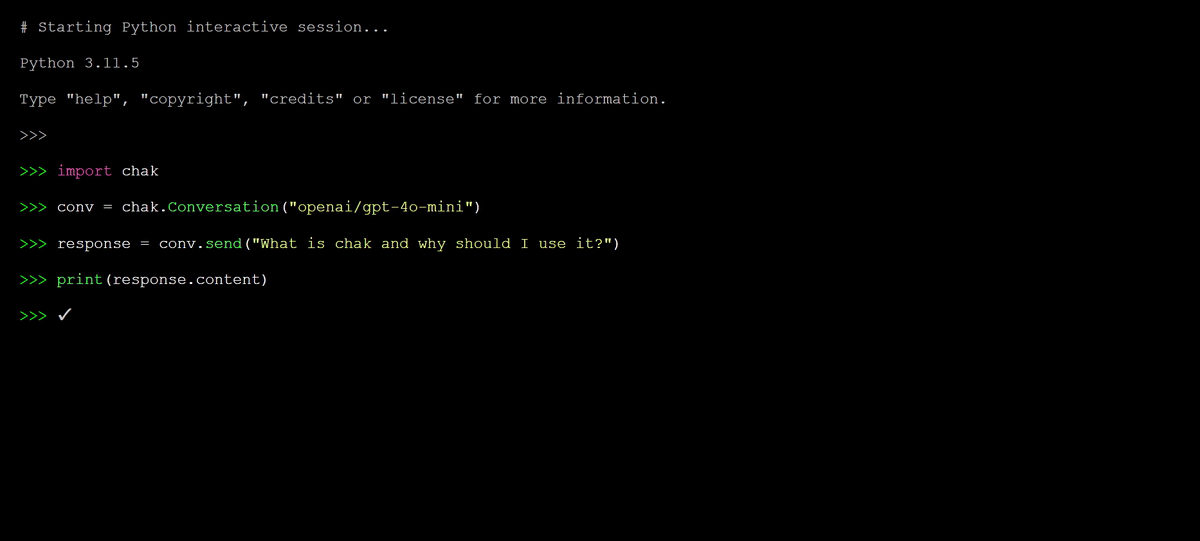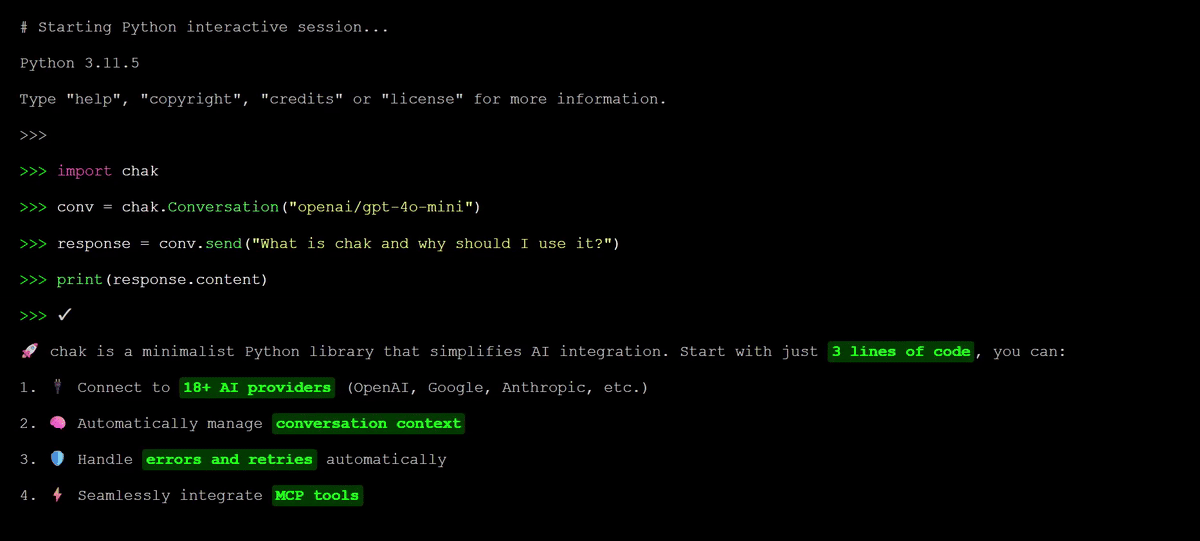
A multi-model LLM client with built-in context management and flexible tool calling.
chak is not another liteLLM, one-api, or OpenRouter, but a client library that actively manages conversation context and tool calls for you. Just focus on building your application, let chak handle the complexity.
🌵 What's New
- 2026-02-02 | v0.3.0 - Major update:
- Skill-based progressive disclosure for tool calling - prevent overwhelming LLMs with too many tools. See Skill-based Tools.
- Turn ID tracking & message filtering - fine-grained conversation history management. See examples examples/turn_id_tracking.py and examples/message_filtering_demo.py.
- Reasoning support - compatible with OpenAI gpt-5/o1/o3 and Bailian QwQ models. See examples examples/chat_reasoning.py.
- Context handler refactoring - replaced strategies with handlers for better clarity (⚠️ Breaking change). See Pluggable Context Management.
- 2026-01-29 | v0.2.7 - Added human-in-the-loop tool approval via
tool_approval_handler, with CLI and browser/WebSocket support. See Human-in-the-loop Approval in Tool Calling. - 2026-01-12 | v0.2.6 - Added event stream support for real-time tool call observability. Use
event=Trueto observe tool execution in your UI. See Tool Call Observability - 2026-01-09 | v0.2.5 - Added configurable tool executor for CPU-intensive tasks. Use
tool_executorparameter to control execution mode. See Tool Calling - 2026-01-07 | v0.2.3 - Conversation now supports structured outputs via
returnsparameter. See Structured Output - 2025-12-02 | v0.2.2 - Conversation now supports multimodal inputs. See Multimodal Support
Core Features
🌱 Minimalist API Design
No complex configurations, no learning curve. chak is designed to be intuitive:
# Use as SDK - connect to any LLM with a simple URI
conv = chak.Conversation(
"openai/gpt-4o-mini",
api_key="YOUR_KEY",
event=True, # Enable event streaming for real-time tool call observability
reasoning=True # Enable reasoning mode for compatible models
)
response = conv.send("Hello!")
# Or run as a local gateway - start in 2 lines
import chak
chak.serve('chak-config.yaml')
Whether you're building an application or running a gateway, chak keeps things simple.
🌳 Multimodal Conversations
Conversations support multimodal inputs - images, audio, video, and documents. Just pass attachments:
from chak import Image, PDF, Audio
# Send image with question
response = await conv.asend(
"What's in this image?",
attachments=[Image("photo.jpg")] # local path, URL, or base64
)
# Analyze documents
response = await conv.asend(
"Summarize this document",
attachments=[PDF("report.pdf")]
)
# Multiple attachments at once
response = await conv.asend(
"Compare these images",
attachments=[
Image("https://example.com/img1.jpg"),
Image("./local/img2.png")
]
)
Supports images, audio, video, PDF, Word, Excel, CSV, TXT, and web links. See Multimodal Support for details.
🪴 Pluggable Context Management
Chak handles context automatically with multiple handlers:
# Context is managed automatically
conv = chak.Conversation(
"openai/gpt-4o",
context_handler=chak.FIFOContextHandler(max_messages=10)
)
chak's handler pattern makes it fully pluggable and extensible. Want custom logic? Just inherit from BaseContextHandler:
from chak import BaseContextHandler
class MyCustomHandler(BaseContextHandler):
def handle(self, messages, *, conversation_id):
# Your custom logic here
# messages: complete conversation history (read-only)
# Return: messages to send to LLM in this round
return messages # or your filtered/modified messages
🌻 Simple Tool Calling
Write tools your way - functions, objects (regular or skill-based), or MCP servers, chak handles the rest:
# Functions
def get_weather(city: str) -> str:
...
# Regular objects
class ShoppingCart:
def add_item(self, name: str, price: float): ...
def get_total(self) -> float: ...
# Skill-based objects (group related tools)
class FileSkill(SkillBase):
def read_file(self, path: str): ...
def analyze_size(self, path: str): ...
cart = ShoppingCart()
file_skill = FileSkill()
# MCP servers
from chak.tools.mcp import Server
mcp_tools = await Server(url="...").tools()
# Use them, that's all
conv = Conversation(
"openai/gpt-4o",
tools=[get_weather, cart, *mcp_tools]
)
Real-time Observability: Get instant visibility into tool execution with event streams:
from chak.message import MessageChunk, ToolCallStartEvent, ToolCallSuccessEvent, ToolCallErrorEvent
# Use event=True to observe tool calls in real-time
tool_start_times = {}
async for event in await conv.asend("Calculate 15 + 27", event=True):
match event:
case ToolCallStartEvent(tool_name=name, arguments=args, call_id=cid, timestamp=ts):
tool_start_times[cid] = ts
print(f"🔧 Calling: {name} with {args}")
case ToolCallSuccessEvent(tool_name=name, call_id=cid, result=res, timestamp=ts):
duration = ts - tool_start_times.get(cid, ts)
print(f"✅ Result: {name} -> {res}")
print(f" ⏱️ Duration: {duration:.3f}s")
case ToolCallErrorEvent(tool_name=name, call_id=cid, error=err, timestamp=ts):
duration = ts - tool_start_times.get(cid, ts)
print(f"❌ Failed: {name} - {err}")
print(f" ⏱️ Duration: {duration:.3f}s")
case MessageChunk(content=text, is_final=final):
print(text, end="", flush=True)
Perfect for building UIs that show live tool execution progress. See examples/event_stream_chat_demo.py
Configurable Execution: For CPU-intensive tools, use tool_executor to control how tools run:
import chak
# Default: best for IO-bound tasks (API calls, DB queries)
conv = chak.Conversation(
"openai/gpt-4o",
tools=[...],
tool_executor=chak.ToolExecutor.ASYNCIO # default
)
# For CPU-intensive tasks: use process pool for true parallelism
conv = chak.Conversation(
"openai/gpt-4o",
tools=[heavy_compute, ...],
tool_executor=chak.ToolExecutor.PROCESS # bypasses GIL
)
# Can switch anytime
conv.set_tool_executor(chak.ToolExecutor.PROCESS)
# Or override for a single call
await conv.asend("Run heavy task", tool_executor=chak.ToolExecutor.PROCESS)
Choose the right executor:
| Scenario | ASYNCIO | THREAD | PROCESS | Recommended |
|---|---|---|---|---|
| CPU-intensive (sync) | ❌ GIL limited | ❌ GIL limited | ✅ True parallel | PROCESS |
| IO-intensive (async) | ✅ Native concurrency | - | - | Default |
| IO-intensive (sync) | ✅ Works well | ✅ Works well | ⚠️ Overkill | ASYNCIO |
See full example: examples/tool_calling_parallel_demo.py
- Now: Functions, objects, and MCP tools all work the same way
- Now: Configurable executor for optimal performance
- Now: Skill-based progressive disclosure prevents overwhelming LLMs
🌺 Structured Output
Get structured data directly from LLM responses using Pydantic models:
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(description="User's full name")
email: str = Field(description="User's email address")
age: int = Field(description="User's age")
# Get structured output automatically
user = await conv.asend(
"Create a user: John Doe, john@example.com, 30 years old",
returns=User
)
print(user.name) # "John Doe"
print(user.email) # "john@example.com"
print(user.age) # 30
Works with multimodal inputs too - extract structured data from images, documents, and more.
Integrated Providers (18+)
OpenAI, Google Gemini, Azure OpenAI, Anthropic Claude, Alibaba Bailian, Baidu Wenxin, Tencent Hunyuan, ByteDance Doubao, Zhipu GLM, Moonshot, DeepSeek, iFlytek Spark, MiniMax, Mistral, SiliconFlow, xAI Grok, Ollama, vLLM, and more.
🌖 Quick Start
Installation
# Basic installation (SDK only)
pip install chakpy
# With server support
pip install chakpy[server]
# Install all optional dependencies
pip install chakpy[all]
Chat with global models in a few lines
import chak
conv = chak.Conversation(
"openai/gpt-4o-mini",
api_key="YOUR_KEY"
)
resp = conv.send("Explain context management in one sentence")
print(resp.content)
Key parameters:
Constructor (Conversation):
| Parameter | Type | Description |
|---|---|---|
model_uri |
str |
Model URI (e.g., "openai/gpt-4o-mini") |
api_key |
str |
API key for authentication |
system_prompt |
str |
System instructions for the LLM |
context_handler |
BaseContextHandler |
Context management handler (FIFO, LRU, Summarization) |
tools |
List |
Tools for function calling (functions, objects, skills, MCP) |
tool_executor |
ToolExecutor |
Execution mode: ASYNCIO (IO-bound), THREAD (sync), PROCESS (CPU-bound) |
tool_approval_handler |
Callable |
Human-in-the-loop approval for tool calls |
Send methods (send / asend):
| Parameter | Type | Description |
|---|---|---|
message |
str |
Message content to send |
attachments |
List[Attachment] |
Multimodal attachments (images, audio, PDFs) |
stream |
bool |
Enable streaming response |
event |
bool |
Enable event streaming for real-time tool call observability |
reasoning |
dict |
Enable reasoning mode (e.g., {"effort": "medium"}) for compatible models |
timeout |
int |
Request timeout in seconds |
returns |
type |
Pydantic model for structured output |
chak handles: connection initialization, message alignment, retry logic, context management, model format conversion... You just need to send messages.
🌒 Enable Automatic Context Management
Three built-in handlers:
- FIFO: Keep the last N messages, automatically drops older ones.
- Summarization: When context reaches a threshold, early history is summarized; recent messages stay in full.
- LRU: Built on Summarization, keeps hot topics and prunes cold ones.
Quick start:
from chak import Conversation, FIFOContextHandler
conv = Conversation(
"bailian/qwen-flash",
api_key="YOUR_KEY",
context_handler=FIFOContextHandler(max_messages=10)
)
See full examples (parameters, how it works, tips):
- FIFO: examples/context_handler_fifo.py
- Summarization: examples/context_handler_summarization.py
- LRU: examples/context_handler_lru.py
Create Custom Handler
Implement your own context strategy by subclassing BaseContextHandler.
To create a custom handler you only need to:
- Inherit
BaseContextHandler - Implement
handle(messages, *, conversation_id) -> List[Message]
from typing import List
from chak.context.handlers import BaseContextHandler
class MyCustomHandler(BaseContextHandler):
"""Minimal example: decide which messages should be sent to the LLM."""
def handle(self, messages: List[Message], *, conversation_id: str) -> List[Message]:
"""Receive full conversation history and return messages to send for this call."""
# Your logic here: filter, summarize, reorder, etc.
return messages
# Use your custom handler
conv = Conversation(
"openai/gpt-4o",
api_key="YOUR_KEY",
context_handler=MyCustomHandler(),
)
Key points:
- Input: complete message history (read-only snapshot)
- Output: messages to send to LLM in this round
- You can add/delete/modify messages freely
🌓 Tool Calling
Write tools the way you like - functions, objects, skills, or MCP servers. chak handles the rest.
Just pass what you have, and it works.
Skill-based Tools (New in 0.3.0)
Write 50+ methods without worrying about overwhelming the LLM. Skills use 3-stage progressive disclosure to handle large tool sets intelligently.
Why skills?
- ✅ Scale effortlessly: Write 50, 100, or more methods - the framework handles it
- ✅ Zero overhead: Just inherit
SkillBase, public methods auto-expose as tools - ✅ Smart disclosure: LLM discovers skills → reads summary → calls specific methods
- ✅ No token waste: Only 1 skill entry in tool list, not 50 detailed schemas
How to create a custom skill?
Simply inherit from SkillBase - that's it! Write your class like any normal Python class, and all public methods will automatically become callable tools.
from chak import Conversation
from chak.tools import SkillBase
class MegaSkill(SkillBase):
"""Inherit SkillBase and write methods - framework does the rest."""
name = "mega_operations" # Skill name LLM will see
description = "Comprehensive operations toolkit" # Skill description
# File operations (10 methods)
def file_read(self, path: str) -> str:
"""Read content from a file."""
with open(path, 'r') as f:
return f.read()
def file_write(self, path: str, content: str) -> str:
"""Write content to a file."""
with open(path, 'w') as f:
f.write(content)
return f"Wrote {len(content)} bytes to {path}"
def file_delete(self, path: str) -> str:
"""Delete a file."""
import os
os.remove(path)
return f"Deleted {path}"
# ... 7 more file methods
# Database operations (10 methods)
def db_connect(self, host: str, port: int) -> str:
"""Connect to database."""
return f"Connected to {host}:{port}"
def db_query(self, sql: str) -> str:
"""Execute SQL query."""
# Your implementation
return "Query executed"
# ... 8 more db methods
# Network operations (10 methods)
def net_get(self, url: str) -> str:
"""HTTP GET request."""
import requests
return requests.get(url).text
def net_post(self, url: str, data: dict) -> str:
"""HTTP POST request."""
import requests
return requests.post(url, json=data).text
# ... 8 more net methods
# Data processing (10 methods)
def data_parse_json(self, text: str) -> dict:
"""Parse JSON string."""
import json
return json.loads(text)
# ... 9 more data methods
# String operations (10 methods)
def str_upper(self, text: str) -> str:
"""Convert to uppercase."""
return text.upper()
def str_lower(self, text: str) -> str:
"""Convert to lowercase."""
return text.lower()
# ... 8 more string methods
# Usage - exactly like regular tools
tools = [MegaSkill()]
conv = Conversation("bailian/qwen-plus", tools=tools)
# The LLM only sees 1 skill entry, not 50 individual tools!
response = await conv.asend("Read /tmp/test.txt and convert to uppercase")
How it works - 3-stage progressive disclosure:
- Step 1 – Skill listing: ToolManager turns your
SkillBasesubclasses into one skill entry per class. The LLM only sees the skill name + description + class docstring (e.g.mega_operations) – it does not see every method yet. - Step 2 – Capability summary: When the LLM first calls the skill without a
methodparameter, Chak inspects all public methods and returns a natural-language summary of their names, docstrings and signatures as normal assistant text (not tool schemas). - Step 3 – Method planning & execution: Based on that summary, the LLM decides which concrete methods to use and calls the same skill again with
method='...'and the actual arguments. Chak then routes the call to your real Python method(s) and returns their results.
Real execution flow:
User: "Read /tmp/test.txt and convert to uppercase"
1. LLM sees: [mega_operations] (1 entry in tool list)
2. LLM calls: mega_operations()
3. Framework returns: "Available methods: file_read(), file_write(), ..., str_upper(), str_lower(), ..."
4. LLM calls: mega_operations(method='file_read', path='/tmp/test.txt')
5. LLM calls: mega_operations(method='str_upper', text='file content here')
6. Done!
Key benefit: The LLM never sees 50 detailed tool schemas at once - it discovers them progressively as needed. This prevents token waste and keeps the LLM focused.
See examples:
- Simple skill: examples/tool_calling_skills_simple.py
- Large-scale skill (50 methods): examples/tool_calling_skills_large_scale.py
Pass Functions
Just pass regular Python functions:
from datetime import datetime
def get_current_time() -> str:
"""Get current date and time"""
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def calculate(a: int, b: int, operation: str = "add") -> int:
"""Perform calculation on two numbers"""
if operation == "add":
return a + b
elif operation == "multiply":
return a * b
# ...
conv = chak.Conversation(
"openai/gpt-4o",
tools=[get_current_time, calculate]
)
response = await conv.asend("What time is it? Then calculate 50 times 20")
Type Safety with Pydantic: Functions support Pydantic models for parameters and return values. Automatic validation and serialization included:
from pydantic import BaseModel, Field
class UserInput(BaseModel):
name: str = Field(description="User's full name")
email: str = Field(description="User's email address")
age: int = Field(description="User's age")
class UserOutput(BaseModel):
id: int
name: str
status: str = "active"
def create_user(user: UserInput) -> UserOutput:
"""Create a new user"""
return UserOutput(id=123, name=user.name, status="active")
conv = chak.Conversation(
"openai/gpt-4o",
tools=[create_user]
)
response = await conv.asend("Create a user: John Doe, john@example.com, 30 years old")
See full example: tool_calling_chat_functions_pydantic.py
Pass Objects
Pass Python objects, their methods become tools. Object state persists across calls:
class ShoppingCart:
def __init__(self):
self.items = []
self.discount = 0
def add_item(self, name: str, price: float, quantity: int = 1):
"""Add item to cart"""
self.items.append({"name": name, "price": price, "quantity": quantity})
def apply_discount(self, percent: float):
"""Apply discount percentage"""
self.discount = percent
def get_total(self) -> float:
"""Calculate total price"""
subtotal = sum(item["price"] * item["quantity"] for item in self.items)
return subtotal * (1 - self.discount / 100)
cart = ShoppingCart()
conv = chak.Conversation(
"openai/gpt-4o",
tools=[cart] # Pass object directly!
)
# LLM modifies cart state through natural language!
response = await conv.asend(
"Add 2 iPhones at $999 each, then apply 10% discount and tell me the total"
)
print(cart.items) # [{'name': 'iPhone', 'price': 999, 'quantity': 2}]
print(cart.discount) # 10
print(cart.get_total()) # 1798.2
The LLM modifies object state through method calls.
Pydantic + Stateful Objects: Combine type safety with state persistence:
from pydantic import BaseModel
class Product(BaseModel):
name: str
price: float
quantity: int = 1
class Order(BaseModel):
order_id: int
products: list[Product]
total: float
class OrderManager:
def __init__(self):
self.orders = [] # State persists!
def create_order(self, product: Product) -> Order:
"""Create order with type-safe Product"""
order = Order(
order_id=len(self.orders) + 1,
products=[product],
total=product.price * product.quantity
)
self.orders.append(order)
return order
def get_stats(self) -> dict:
"""Get statistics from accumulated state"""
return {"total_orders": len(self.orders)}
manager = OrderManager()
conv = chak.Conversation(
"openai/gpt-4o",
tools=[manager] # Type-safe + stateful!
)
await conv.asend("Create an order: Laptop, $1200, quantity 1")
await conv.asend("Create another order: Mouse, $25, quantity 2")
response = await conv.asend("Show me the order statistics")
print(len(manager.orders)) # 2 - state persisted!
See full example: tool_calling_chat_objects_pydantic.py
Pass MCP Tools
chak integrates the Model Context Protocol (MCP):
import asyncio
from chak import Conversation
from chak.tools.mcp import Server
async def main():
# Connect to MCP server and load tools
tools = await Server(
url="https://your-mcp-server.com/sse",
headers={"Authorization": "Bearer YOUR_TOKEN"}
).tools()
# Create conversation with tools
conv = Conversation(
"openai/gpt-4o",
api_key="YOUR_KEY",
tools=tools
)
# Model automatically calls tools when needed
response = await conv.asend("What's the weather in San Francisco?")
print(response.content)
asyncio.run(main())
Supports three transport types:
- SSE (Server-Sent Events): Cloud-hosted MCP services
- stdio: Local MCP servers
- HTTP: HTTP-based MCP services
Mix Everything
Functions, objects, and MCP tools work together:
def send_email(to: str, subject: str): ...
class OrderWorkflow:
def add_items(self, items): ...
def submit_order(self): ...
mcp_tools = await Server(url="...").tools() # External tools
conv = Conversation(
"openai/gpt-4o",
tools=[
send_email, # Native function
OrderWorkflow(), # Native object (stateful!)
*mcp_tools # MCP tools
]
)
Human-in-the-loop Approval
Require manual approval before executing tools, and optionally auto-approve safe read-only tools via tool_approval_handler:
from chak.tools.manager import ToolCallApproval
async def my_approval_handler(approval: ToolCallApproval) -> bool:
"""Auto-approve safe tools, prompt for others."""
# Whitelist: auto-approve read-only tools without prompting
SAFE_TOOLS = {"search_web", "get_current_time", "read_file"}
if approval.tool_name in SAFE_TOOLS:
print(f"✓ Auto-approved safe tool: {approval.tool_name}")
return True
# For other tools, require manual approval
print(f"⚠️ Tool '{approval.tool_name}' requires approval")
print(f" Arguments: {approval.arguments}")
answer = input(" Allow? (y/n): ").strip().lower()
return answer == "y"
# Assume search_web, get_current_time, delete_file are tools you provided
conv = chak.Conversation(
model_uri="openai/gpt-4o",
model_uri="openai/gpt-4o",
api_key="YOUR_KEY",
tools=[search_web, get_current_time, delete_file], # Mix safe and dangerous tools
tool_approval_handler=my_approval_handler,
)
response = await conv.asend("What time is it now?")
🌙 Structured Output
chak's Conversation supports structured outputs through the returns parameter. Instead of parsing LLM text responses manually, you can specify a Pydantic model and get validated, type-safe data directly.
Supported types:
- ✅
BaseModel- Single Pydantic model - ✅
List[BaseModel]- List of models (NEW!) - ✅
Dict[str, BaseModel]- Dictionary of models (NEW!)
Basic Usage
Simple Data Extraction
from pydantic import BaseModel, Field
from chak import Conversation
class User(BaseModel):
"""User information"""
name: str = Field(description="User's full name")
email: str = Field(description="User's email address")
age: int = Field(description="User's age")
conv = Conversation("openai/gpt-4o", api_key="YOUR_KEY")
# Extract structured data from natural language
user = await conv.asend(
"Create a user profile for John Doe, email john@example.com, 30 years old",
returns=User
)
print(user.name) # "John Doe"
print(user.email) # "john@example.com"
print(user.age) # 30
Complex Nested Models
from typing import List, Dict
from typing import List, Dict
from pydantic import BaseModel, Field
class Address(BaseModel):
street: str
city: str
country: str
class Company(BaseModel):
name: str
industry: str
address: Address
employee_count: int
# Works with nested structures
company = await conv.asend(
"Apple Inc is a technology company with 150,000 employees, located at One Apple Park Way, Cupertino, USA",
returns=Company
)
print(company.name) # "Apple Inc"
print(company.address.city) # "Cupertino"
print(company.employee_count) # 150000
Extract Lists and Dictionaries
from typing import List, Dict
from pydantic import BaseModel
class Product(BaseModel):
name: str
price: float
category: str
# Extract list of models
products = await conv.asend(
"List 3 popular tech products: iPhone 15 Pro ($999), MacBook Air ($1199), AirPods Pro ($249)",
returns=List[Product]
)
# Returns: [Product(...), Product(...), Product(...)]
# Extract dictionary of models
products_dict = await conv.asend(
"Create product catalog keyed by name",
returns=Dict[str, Product]
)
# Returns: {"iPhone 15 Pro": Product(...), "MacBook Air": Product(...), ...}
Note: Supports BaseModel, List[BaseModel], and Dict[str, BaseModel]. Other generic types (e.g., Tuple, Set, Dict[int, T]) are not supported.
Extract Lists and Dictionaries
from typing import List, Dict
from pydantic import BaseModel
class Product(BaseModel):
name: str
price: float
category: str
# Extract list of models
products = await conv.asend(
"List 3 popular tech products: iPhone 15 Pro ($999), MacBook Air ($1199), AirPods Pro ($249)",
returns=List[Product]
)
# Returns: [Product(...), Product(...), Product(...)]
# Extract dictionary of models
products_dict = await conv.asend(
"Create product catalog keyed by name",
returns=Dict[str, Product]
)
# Returns: {"iPhone 15 Pro": Product(...), "MacBook Air": Product(...), ...}
Note: Supports BaseModel, List[BaseModel], and Dict[str, BaseModel]. Other generic types (e.g., Tuple, Set, Dict[int, T]) are not supported.
Multimodal Structured Output
Combine structured outputs with images, documents, and other attachments:
Extract Data from Images
from chak import Image
class SceneDescription(BaseModel):
"""Scene description extracted from image"""
main_subject: str = Field(description="The main subject or focal point")
setting: str = Field(description="The location or setting")
colors: List[str] = Field(description="Dominant colors in the image")
mood: str = Field(description="Overall mood or atmosphere")
# Analyze image and get structured output
scene = await conv.asend(
"Analyze this image and describe the scene",
attachments=[Image("photo.jpg")],
returns=SceneDescription
)
print(scene.main_subject) # "Mount Fuji"
print(scene.colors) # ["blue", "white", "pink"]
print(scene.mood) # "peaceful and serene"
Extract Data from Documents
from chak import PDF
class Invoice(BaseModel):
"""Invoice information extracted from document"""
invoice_number: str
date: str
total_amount: float
vendor_name: str
items: List[str]
# Extract structured data from PDF
invoice = await conv.asend(
"Extract invoice information from this document",
attachments=[PDF("invoice.pdf")],
returns=Invoice
)
print(invoice.invoice_number) # "INV-2024-001"
print(invoice.total_amount) # 1250.00
print(invoice.vendor_name) # "Acme Corp"
Complete Example
See full working examples:
- Basic Structured Output: examples/structured_output_simple.py
- Multimodal Structured Output: examples/structured_output_multimodal.py
Notes
- Pydantic Required: The
returnsparameter must be a PydanticBaseModelsubclass - Function Calling Support: Your LLM must support function calling (most modern models do)
- Async Only: Structured output currently works with
asend()only, notsend() - Validation: All data is automatically validated against your Pydantic model schema
- Provider Compatibility:
- ✅ Supported: OpenAI, Anthropic, Google Gemini, most text models
- ⚠️ Limited: Some vision models may not support function calling
- Use text models with multimodal support (e.g., OpenAI gpt-4o, gpt-4-vision) for best results
🌔 Multimodal Support
chak's Conversation supports multimodal inputs through the attachments parameter. You can send images, audio, video, documents (PDF, Word, Excel, CSV, TXT), and web links alongside your text messages.
Supported File Types
| Type | Class | Supported Formats | Use Cases |
|---|---|---|---|
| Image | Image |
JPEG, PNG, GIF, WEBP | Image analysis, visual Q&A, OCR |
| Audio | Audio |
WAV, MP3, OGG | Speech recognition, audio analysis |
| Video | Video |
MP4, WEBM | Video understanding, frame extraction |
PDF |
Document analysis, extraction | ||
| Word | DOC |
DOC, DOCX | Document reading, content extraction |
| Excel | Excel |
XLS, XLSX | Data analysis, spreadsheet processing |
| CSV | CSV |
CSV | Structured data analysis |
| Text | TXT |
TXT, MD, etc. | Plain text/markdown analysis |
| Link | Link |
HTTP/HTTPS URLs | Web content analysis |
Input Format Flexibility
All attachment types support three input formats:
- Local file path:
Image("./photo.jpg") - Remote URL:
Image("https://example.com/photo.jpg") - Base64 data URI:
Image("data:image/jpeg;base64,/9j/4AAQ...")
Basic Usage
Single Image
from chak import Conversation, Image
conv = Conversation("openai/gpt-4o", api_key="YOUR_KEY")
# Using URL
response = await conv.asend(
"What's in this image?",
attachments=[Image("https://example.com/photo.jpg")]
)
# Using local path
response = await conv.asend(
"Describe this image",
attachments=[Image("./local/photo.png")]
)
# Using base64
response = await conv.asend(
"Analyze this",
attachments=[Image("data:image/jpeg;base64,/9j/4AAQSkZJRg...")]
)
Multiple Images
from chak import Image, MimeType
# Compare multiple images
response = await conv.asend(
"What are the differences between these images?",
attachments=[
Image("https://example.com/image1.jpg"),
Image("./local/image2.png", MimeType.PNG),
Image("data:image/webp;base64,...", MimeType.WEBP)
]
)
Audio Files
from chak import Audio, MimeType
response = await conv.asend(
"What is being said in this audio?",
attachments=[Audio("https://example.com/speech.wav", MimeType.WAV)]
)
Documents
from chak import PDF, DOC, Excel, CSV, TXT
# PDF analysis
response = await conv.asend(
"Summarize this PDF document",
attachments=[PDF("./report.pdf")],
timeout=120 # Longer timeout for large files
)
# Word document
response = await conv.asend(
"Extract key points from this document",
attachments=[DOC("https://example.com/document.docx")]
)
# Excel spreadsheet
response = await conv.asend(
"What's the total revenue in this spreadsheet?",
attachments=[Excel("./sales_data.xlsx")]
)
# CSV data
response = await conv.asend(
"Find all customers from California",
attachments=[CSV("./customers.csv")]
)
# Plain text or markdown
response = await conv.asend(
"Summarize this article",
attachments=[TXT("https://example.com/article.md")]
)
Web Links
from chak import Link
# Analyze web content
response = await conv.asend(
"What are the main points in this article?",
attachments=[Link("https://example.com/article")]
)
Streaming with Attachments
Multimodal inputs work seamlessly with streaming:
from chak import Image
print("Response: ", end="")
async for chunk in await conv.asend(
"Describe this image in detail",
attachments=[Image("photo.jpg")],
stream=True
):
print(chunk.content, end="", flush=True)
Advanced: Direct Multimodal Message
For fine-grained control, construct multimodal messages directly:
from chak import HumanMessage
response = await conv.asend(
HumanMessage(content=[
{"type": "text", "text": "What colors are in this image?"},
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}}
])
)
Complete Examples
See full working examples:
-
Images: examples/multimodal_chat_image.py
- Single image analysis
- Multiple image comparison
- Streaming with images
- Audio input (when supported)
- Advanced multimodal messages
-
Documents: examples/multimodal_chat_documents.py
- PDF document analysis
- Word document processing
- Plain text and markdown files
- CSV data analysis
- Excel spreadsheet processing
- Web link content analysis
- Streaming with documents
Notes
-
Model Support: Not all LLM providers support all modalities. Check your provider's documentation:
- Vision models: OpenAI GPT-4o, Anthropic Claude 3, Google Gemini, Bailian Qwen-VL
- Audio models: Some Qwen variants, Whisper-based models
- Document support varies by provider
-
File Size: Large files may require longer timeouts. Use
timeoutparameter:response = await conv.asend( "Analyze this large PDF", attachments=[PDF("large.pdf")], timeout=180 # 3 minutes )
-
Custom Readers: Built-in readers cover most use cases. For specialized needs, you can provide custom reader functions to document attachment types (PDF, DOC, Excel, etc.).
-
Async Required: Multimodal support works with both
send()andasend(), but async is recommended for better performance with large files.
🌗 Practical Utilities
View Conversation Statistics
stats = conv.stats()
print(stats)
# {
# 'total_messages': 10,
# 'by_type': {'user': 5, 'assistant': 4, 'context': 1},
# 'total_tokens': '12.5K',
# 'input_tokens': '8.2K',
# 'output_tokens': '4.3K'
# }
Logging Configuration
Control log output at runtime:
import chak
chak.set_log_level("DISABLE") # Disable all logs (production)
chak.set_log_level("ERROR") # Only errors
chak.set_log_level("WARNING") # Warnings + errors
chak.set_log_level("INFO") # Default, shows tool execution
chak.set_log_level("DEBUG") # Detailed logs with file:line
Or use environment variables (set before importing):
export CHAK_LOG_LEVEL=ERROR
export CHAK_LOG_TO_FILE=true # Optional: enable file logging
export CHAK_LOG_FILE=logs/chak.log
Debug Mode
Use DEBUG level for detailed logs:
chak.set_log_level("DEBUG")
Shows:
- Context strategies: trigger points, retention intervals, summary previews, token counts
- Tool calls: tool invocation, request/response details, execution results
🌑 Custom Data
All messages in chak have a custom field - a dictionary for storing any application-specific data alongside the message content.
Basic Usage
from chak import Conversation
conv = Conversation("openai/gpt-4o-mini", api_key="YOUR_KEY")
# Get response from LLM
response = await conv.asend("Hello!")
# Store custom data in the message
response.custom = {
"user_id": "12345",
"session_id": "abc-def",
"tags": ["greeting", "new_user"]
}
Use Cases
The custom field is completely flexible - use it however your application needs:
- Frontend rendering: Pass UI instructions (forms, charts, widgets)
- Tracking: Store session IDs, user IDs, request metadata
- Routing: Add routing hints or processing flags
- Analytics: Attach tracking data for logging
- Anything else: It's your data, structure it your way
Example: examples/custom_payload_demo.py - Demo showing custom data used for dynamic form rendering
Local Server Mode (Optional)
⚠️ chak is primarily an SDK. The built-in local server is intended for local development and prototyping only, and is not recommended or hardened for production use.
Start a local gateway service with 2 lines of code:
1. Create Configuration File
# chak-config.yaml
api_keys:
# Simple format - use default base_url
openai: ${OPENAI_API_KEY} # Read from environment variable (recommended)
bailian: "sk-your-api-key-here" # Plain text (for development/testing)
# Custom base_url (requires quotes)
"ollama@http://localhost:11434": "ollama"
"vllm@http://192.168.1.100:8000": "dummy-key"
server:
host: "0.0.0.0"
port: 8000
2. Start Server
import chak
chak.serve('chak-config.yaml')
That's it! The server starts and you'll see:
======================================================================
✨ Chak AI Gateway
A simple, yet handy, LLM gateway
======================================================================
🚀 Server running at: http://localhost:8000
🎮 Playground: http://localhost:8000/playground
📡 WebSocket endpoint: ws://localhost:8000/ws/conversation
⭐ Star on GitHub: https://github.com/zhixiangxue/chak-ai
======================================================================
3. Use Playground for Quick Model Conversations
Open http://localhost:8000/playground, select a provider and model, start chatting immediately. Experience real-time interaction with global LLMs.
4. Call from Any Language
The service provides a WebSocket API, callable from JavaScript, Go, Java, Rust, or any language:
// JavaScript example
const ws = new WebSocket('ws://localhost:8000/ws/conversation');
// Initialize session
ws.send(JSON.stringify({
type: 'init',
model_uri: 'openai/gpt-4o-mini'
}));
// Send message
ws.send(JSON.stringify({
type: 'send',
message: 'Hello!',
stream: true
}));
This way chak becomes your local LLM gateway, centrally managing all provider API keys, callable from any language.
Supported LLM Providers
| Provider | Registration | URI Example |
|---|---|---|
| OpenAI | https://platform.openai.com | openai/gpt-4o |
| Anthropic | https://console.anthropic.com | anthropic/claude-3-5-sonnet |
| Google Gemini | https://ai.google.dev | google/gemini-1.5-pro |
| DeepSeek | https://platform.deepseek.com | deepseek/deepseek-chat |
| Alibaba Bailian | https://bailian.console.aliyun.com | bailian/qwen-max |
| Zhipu GLM | https://open.bigmodel.cn | zhipu/glm-4 |
| Moonshot | https://platform.moonshot.cn | moonshot/moonshot-v1-8k |
| Baidu Wenxin | https://console.bce.baidu.com/qianfan | baidu/ernie-bot-4 |
| Tencent Hunyuan | https://cloud.tencent.com/product/hunyuan | tencent/hunyuan-standard |
| ByteDance Doubao | https://console.volcengine.com/ark | volcengine/doubao-pro |
| iFlytek Spark | https://xinghuo.xfyun.cn | iflytek/spark-v3.5 |
| MiniMax | https://platform.minimaxi.com | minimax/abab-5.5 |
| Mistral | https://console.mistral.ai | mistral/mistral-large |
| xAI Grok | https://console.x.ai | xai/grok-beta |
| SiliconFlow | https://siliconflow.cn | siliconflow/qwen-7b |
| Azure OpenAI | https://azure.microsoft.com/en-us/products/ai-services/openai-service | azure/gpt-4o |
| Ollama | https://ollama.com | ollama/llama3.1 |
| vLLM | https://github.com/vllm-project/vllm | vllm/custom-model |
Notes:
- URI format:
provider/model - Custom base_url: Use complete format
provider@base_url:model - Local deployments (Ollama, vLLM) require custom base_url configuration
MCP Server Resources
Explore thousands of ready-to-use MCP servers:
| Platform | Description | URL |
|---|---|---|
| Mcp.so | 8,000+ servers, supports STDIO & SSE, with API playground | https://mcp.so |
| Smithery | 4,500+ servers, beginner-friendly, one-click config for Cursor | https://smithery.ai |
| Alibaba Bailian | Enterprise-grade MCP marketplace with cloud-hosted services | https://bailian.console.aliyun.com/?tab=mcp#/mcp-market |
| ModelScope | Largest Chinese MCP community by Alibaba Cloud | https://modelscope.cn/mcp |
| Awesome MCP | 200+ curated servers organized by category (GitHub) | https://github.com/punkpeye/awesome-mcp-servers |
| ByteDance Volcengine | Enterprise-level stable and secure MCP services | https://www.volcengine.com/mcp-marketplace |
| iFlytek Spark | MCP servers for Spark AI platform | https://mcp.xfyun.cn |
| Baidu SAI | Explore massive available MCP servers | https://sai.baidu.com/mcp |
| PulseMCP | 3,290+ servers with weekly updates and tutorials | https://www.pulsemcp.com |
| mcp.run | 200+ templates with one-click web deployment | https://www.mcp.run |
🌕 Is chak for You?
If you:
- Need to connect to multiple model platforms
- Want simple, automatic context management
- Want the simplest tool calling experience - just pass functions or objects or mcp tools
- Want to focus on building applications, not wrestling with context and tools
Then chak is made for you.
To get started quickly, explore the examples/ directory for end-to-end demos (tool calling, skills, multimodal, structured output, local server, etc.).

Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file chakpy-0.3.0.tar.gz.
File metadata
- Download URL: chakpy-0.3.0.tar.gz
- Upload date:
- Size: 178.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ee060df37d1a7d07619a6a26ccf40f8f37340a9c66cb817ac82d12ce78a20477
|
|
| MD5 |
c5852157cf406ec779f98a4d0e44e403
|
|
| BLAKE2b-256 |
54f286dd19b7e794a0072ff5cdd777f20630229825b34fba13b96e25ad6825bc
|
Provenance
The following attestation bundles were made for chakpy-0.3.0.tar.gz:
Publisher:
publish.yml on zhixiangxue/chak-ai
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
chakpy-0.3.0.tar.gz -
Subject digest:
ee060df37d1a7d07619a6a26ccf40f8f37340a9c66cb817ac82d12ce78a20477 - Sigstore transparency entry: 1100899624
- Sigstore integration time:
-
Permalink:
zhixiangxue/chak-ai@551d2084b5a515a4adc270c25bfe01fd2b2a29b9 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/zhixiangxue
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@551d2084b5a515a4adc270c25bfe01fd2b2a29b9 -
Trigger Event:
release
-
Statement type:
File details
Details for the file chakpy-0.3.0-py3-none-any.whl.
File metadata
- Download URL: chakpy-0.3.0-py3-none-any.whl
- Upload date:
- Size: 206.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad9cf548d327948f566903b664fefffb20ae695e6765bdd28d0462ed79737caf
|
|
| MD5 |
70038f0eeedf7d0165171d4a3b9a1fa9
|
|
| BLAKE2b-256 |
a23c39d838558b92fca0f3acc40329097bf8eccbfab5af11932862d9bb54b563
|
Provenance
The following attestation bundles were made for chakpy-0.3.0-py3-none-any.whl:
Publisher:
publish.yml on zhixiangxue/chak-ai
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
chakpy-0.3.0-py3-none-any.whl -
Subject digest:
ad9cf548d327948f566903b664fefffb20ae695e6765bdd28d0462ed79737caf - Sigstore transparency entry: 1100899628
- Sigstore integration time:
-
Permalink:
zhixiangxue/chak-ai@551d2084b5a515a4adc270c25bfe01fd2b2a29b9 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/zhixiangxue
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@551d2084b5a515a4adc270c25bfe01fd2b2a29b9 -
Trigger Event:
release
-
Statement type:







