chDB is an in-process OLAP SQL Engine powered by ClickHouse

Project description






chDB
chDB is an in-process SQL OLAP Engine powered by ClickHouse [^1] For more details: The birth of chDB
Features
- 🐼 Pandas-compatible DataStore API - Use familiar pandas syntax with ClickHouse performance
- In-process SQL OLAP Engine, powered by ClickHouse
- No need to install ClickHouse
- Minimized data copy from C++ to Python with python memoryview
- Input&Output support Parquet, CSV, JSON, Arrow, ORC and 60+more formats
- Support Python DB API 2.0
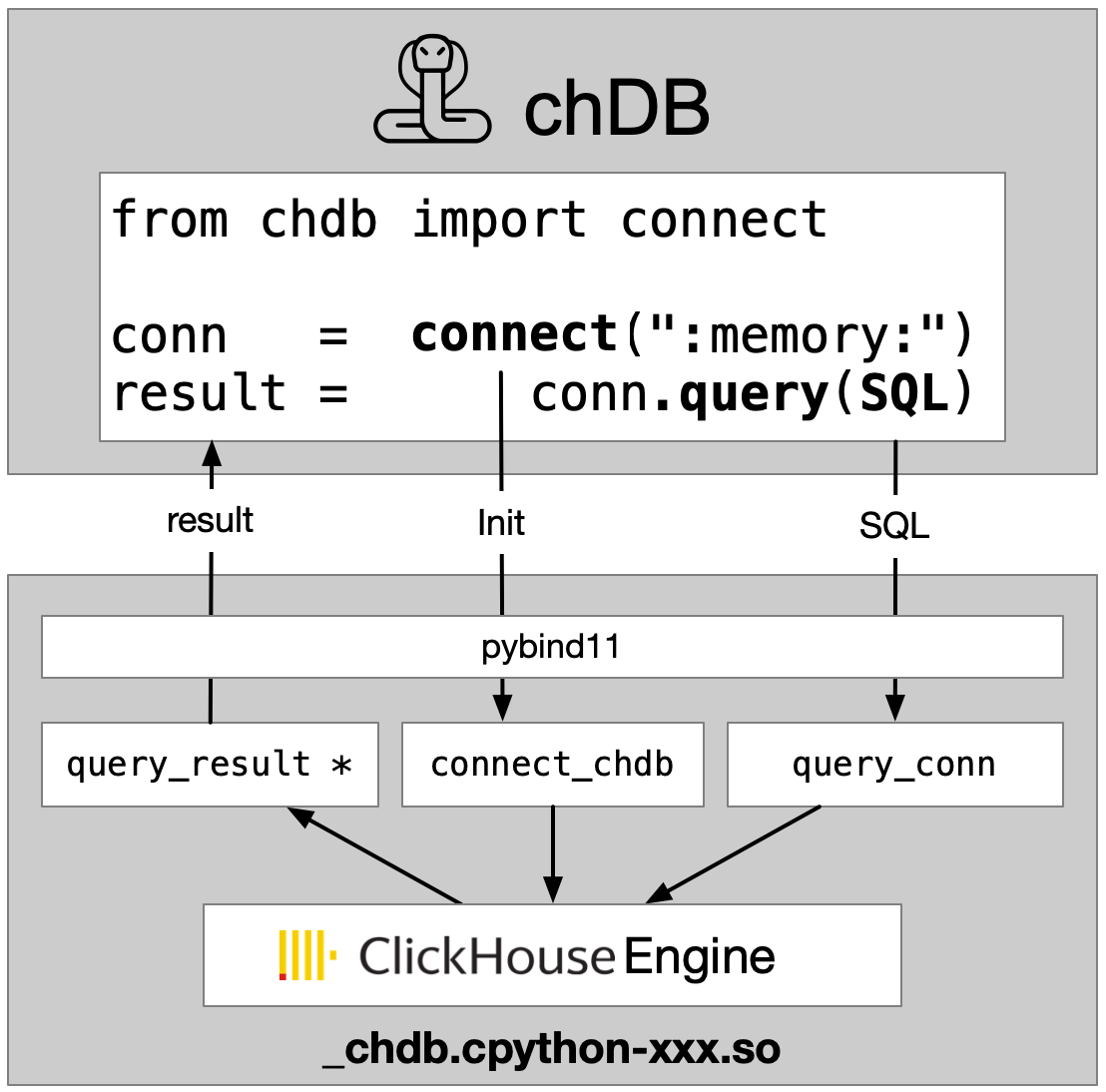
Arch
Installation
Currently, chDB supports Python 3.9+ on macOS and Linux (x86_64 and ARM64).
pip install chdb
🐼 DataStore: Pandas-Compatible API (Recommended)
DataStore provides a familiar pandas-like API with automatic SQL generation and ClickHouse performance. Write pandas code, get SQL performance - no learning curve required.
Quick Start (30 seconds)
Just change your import - use the pandas API you already know:
import datastore as pd # That's it! Use pandas API as usual
# Create a DataFrame - works exactly like pandas
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'Diana'],
'age': [25, 30, 35, 28],
'city': ['NYC', 'LA', 'NYC', 'LA']
})
# Filter with familiar pandas syntax
result = df[df['age'] > 26]
print(result)
# name age city
# 1 Bob 30 LA
# 2 Charlie 35 NYC
# 3 Diana 28 LA
# GroupBy works too
print(df.groupby('city')['age'].mean())
# city
# LA 29.0
# NYC 30.0
✨ Zero code changes required. All operations are lazy - they're recorded and compiled into optimized SQL, executed only when results are needed.
Why DataStore?
| Feature | pandas | DataStore |
|---|---|---|
| API | ✅ Familiar | ✅ Same pandas API |
| Large datasets | ❌ Memory limited | ✅ SQL-optimized |
| Learning curve | ✅ Easy | ✅ None - same syntax |
| Performance | ❌ Single-threaded | ✅ ClickHouse engine |
Working with Files
from datastore import DataStore
# Load any file format
ds = DataStore.from_file("data.parquet") # or CSV, JSON, ORC...
# Explore your data
print(ds.head()) # Preview first 5 rows
print(ds.shape) # (rows, columns)
print(ds.columns) # Column names
# Build queries with method chaining
result = (ds
.select("product", "revenue", "date")
.filter(ds.revenue > 1000)
.sort("revenue", ascending=False)
.head(10))
print(result)
Query Any Data Source
from datastore import DataStore
# S3 (with anonymous access)
ds = DataStore.uri("s3://bucket/data.parquet?nosign=true")
# MySQL
ds = DataStore.uri("mysql://user:pass@localhost:3306/mydb/users")
# PostgreSQL
ds = DataStore.uri("postgresql://user:pass@localhost:5432/mydb/products")
# And more: SQLite, MongoDB, ClickHouse, HDFS, Azure, GCS...
Pandas API Coverage
DataStore implements comprehensive pandas compatibility:
| Category | Coverage |
|---|---|
| DataFrame methods | 209 methods |
| Series.str accessor | 56 methods |
| Series.dt accessor | 42+ methods |
| ClickHouse SQL functions | 334 functions |
# All these pandas methods work:
df.drop(columns=['unused'])
df.fillna(0)
df.assign(revenue=lambda x: x['price'] * x['quantity'])
df.sort_values('revenue', ascending=False)
df.groupby('category').agg({'revenue': 'sum', 'quantity': 'mean'})
df.merge(other_df, on='id')
df.pivot_table(values='sales', index='date', columns='product')
# ... and 200+ more
String and DateTime Operations
# String operations via .str accessor
ds['name'].str.upper()
ds['email'].str.contains('@gmail')
ds['text'].str.replace('old', 'new')
# DateTime operations via .dt accessor
ds['date'].dt.year
ds['date'].dt.month
ds['timestamp'].dt.hour
Documentation
- Pandas Compatibility Guide - Full list of supported methods
- Function Reference - 334 ClickHouse SQL functions
- Migration Guide - Step-by-step guide for pandas users
SQL API
For users who prefer SQL or need advanced ClickHouse features:
Run in command line
python3 -m chdb SQL [OutputFormat]
python3 -m chdb "SELECT 1,'abc'" Pretty
Data Input
The following methods are available to access on-disk and in-memory data formats:
🗂️ Connection based API
import chdb
# Create a connection (in-memory by default)
conn = chdb.connect(":memory:")
# Or use file-based: conn = chdb.connect("test.db")
# Create a cursor
cur = conn.cursor()
# Execute queries
cur.execute("SELECT number, toString(number) as str FROM system.numbers LIMIT 3")
# Fetch data in different ways
print(cur.fetchone()) # Single row: (0, '0')
print(cur.fetchmany(2)) # Multiple rows: ((1, '1'), (2, '2'))
# Get column information
print(cur.column_names()) # ['number', 'str']
print(cur.column_types()) # ['UInt64', 'String']
# Use the cursor as an iterator
cur.execute("SELECT number FROM system.numbers LIMIT 3")
for row in cur:
print(row)
# Always close resources when done
cur.close()
conn.close()
For more details, see examples/connect.py.
🗂️ Query On File
(Parquet, CSV, JSON, Arrow, ORC and 60+)
You can execute SQL and return desired format data.
import chdb
res = chdb.query('select version()', 'Pretty'); print(res)
Work with Parquet or CSV
# See more data type format in tests/format_output.py
res = chdb.query('select * from file("data.parquet", Parquet)', 'JSON'); print(res)
res = chdb.query('select * from file("data.csv", CSV)', 'CSV'); print(res)
print(f"SQL read {res.rows_read()} rows, {res.bytes_read()} bytes, storage read {res.storage_rows_read()} rows, {res.storage_bytes_read()} bytes, elapsed {res.elapsed()} seconds")
Parameterized queries
import chdb
df = chdb.query(
"SELECT toDate({base_date:String}) + number AS date "
"FROM numbers({total_days:UInt64}) "
"LIMIT {items_per_page:UInt64}",
"DataFrame",
params={"base_date": "2025-01-01", "total_days": 10, "items_per_page": 2},
)
print(df)
# date
# 0 2025-01-01
# 1 2025-01-02
Pandas dataframe output
# See more in https://clickhouse.com/docs/en/interfaces/formats
chdb.query('select * from file("data.parquet", Parquet)', 'Dataframe')
🗂️ Query On Table
(Pandas DataFrame, Parquet file/bytes, Arrow bytes)
Query On Pandas DataFrame
import chdb.dataframe as cdf
import pandas as pd
# Join 2 DataFrames
df1 = pd.DataFrame({'a': [1, 2, 3], 'b': ["one", "two", "three"]})
df2 = pd.DataFrame({'c': [1, 2, 3], 'd': ["①", "②", "③"]})
ret_tbl = cdf.query(sql="select * from __tbl1__ t1 join __tbl2__ t2 on t1.a = t2.c",
tbl1=df1, tbl2=df2)
print(ret_tbl)
# Query on the DataFrame Table
print(ret_tbl.query('select b, sum(a) from __table__ group by b'))
# Pandas DataFrames are automatically registered as temporary tables in ClickHouse
chdb.query("SELECT * FROM Python(df1) t1 JOIN Python(df2) t2 ON t1.a = t2.c").show()
🗂️ Query with Stateful Session
from chdb import session as chs
## Create DB, Table, View in temp session, auto cleanup when session is deleted.
sess = chs.Session()
sess.query("CREATE DATABASE IF NOT EXISTS db_xxx ENGINE = Atomic")
sess.query("CREATE TABLE IF NOT EXISTS db_xxx.log_table_xxx (x String, y Int) ENGINE = Log;")
sess.query("INSERT INTO db_xxx.log_table_xxx VALUES ('a', 1), ('b', 3), ('c', 2), ('d', 5);")
sess.query(
"CREATE VIEW db_xxx.view_xxx AS SELECT * FROM db_xxx.log_table_xxx LIMIT 4;"
)
print("Select from view:\n")
print(sess.query("SELECT * FROM db_xxx.view_xxx", "Pretty"))
see also: test_stateful.py.
🗂️ Query with Python DB-API 2.0
import chdb.dbapi as dbapi
print("chdb driver version: {0}".format(dbapi.get_client_info()))
conn1 = dbapi.connect()
cur1 = conn1.cursor()
cur1.execute('select version()')
print("description: ", cur1.description)
print("data: ", cur1.fetchone())
cur1.close()
conn1.close()
🗂️ Query with UDF (User Defined Functions)
from chdb.udf import chdb_udf
from chdb import query
@chdb_udf()
def sum_udf(lhs, rhs):
return int(lhs) + int(rhs)
print(query("select sum_udf(12,22)"))
Some notes on chDB Python UDF(User Defined Function) decorator.
- The function should be stateless. So, only UDFs are supported, not UDAFs(User Defined Aggregation Function).
- Default return type is String. If you want to change the return type, you can pass in the return type as an argument. The return type should be one of the following: https://clickhouse.com/docs/en/sql-reference/data-types
- The function should take in arguments of type String. As the input is TabSeparated, all arguments are strings.
- The function will be called for each line of input. Something like this:
def sum_udf(lhs, rhs): return int(lhs) + int(rhs) for line in sys.stdin: args = line.strip().split('\t') lhs = args[0] rhs = args[1] print(sum_udf(lhs, rhs)) sys.stdout.flush() - The function should be pure python function. You SHOULD import all python modules used IN THE FUNCTION.
def func_use_json(arg): import json ... - Python interpertor used is the same as the one used to run the script. Get from
sys.executable
see also: test_udf.py.
🗂️ Streaming Query
Process large datasets with constant memory usage through chunked streaming.
from chdb import session as chs
sess = chs.Session()
# Example 1: Basic example of using streaming query
rows_cnt = 0
with sess.send_query("SELECT * FROM numbers(200000)", "CSV") as stream_result:
for chunk in stream_result:
rows_cnt += chunk.rows_read()
print(rows_cnt) # 200000
# Example 2: Manual iteration with fetch()
rows_cnt = 0
stream_result = sess.send_query("SELECT * FROM numbers(200000)", "CSV")
while True:
chunk = stream_result.fetch()
if chunk is None:
break
rows_cnt += chunk.rows_read()
print(rows_cnt) # 200000
For more details, see test_streaming_query.py.
🗂️ Python Table Engine
Query on Pandas DataFrame
import chdb
import pandas as pd
df = pd.DataFrame(
{
"a": [1, 2, 3, 4, 5, 6],
"b": ["tom", "jerry", "auxten", "tom", "jerry", "auxten"],
}
)
chdb.query("SELECT b, sum(a) FROM Python(df) GROUP BY b ORDER BY b").show()
Query on Arrow Table
import chdb
import pyarrow as pa
arrow_table = pa.table(
{
"a": [1, 2, 3, 4, 5, 6],
"b": ["tom", "jerry", "auxten", "tom", "jerry", "auxten"],
}
)
chdb.query("SELECT b, sum(a) FROM Python(arrow_table) GROUP BY b ORDER BY b").show()
see also: test_query_py.py.
🧠 AI-assisted SQL generation
chDB can translate natural language prompts into SQL. Configure the AI client through the connection (or session) string parameters:
ai_provider:openaioranthropic. Defaults to OpenAI-compatible whenai_base_urlis set, otherwise auto-detected.ai_api_key: API key; falls back toAI_API_KEY,OPENAI_API_KEY, orANTHROPIC_API_KEYenv vars.ai_base_url: Custom base URL for OpenAI-compatible endpoints.ai_model: Model name (e.g.,gpt-4o-mini,claude-3-opus-20240229).
import chdb
# Use env OPENAI_API_KEY/AI_API_KEY/ANTHROPIC_API_KEY for credentials
conn = chdb.connect("file::memory:?ai_provider=openai&ai_model=gpt-4o-mini")
conn.query("CREATE TABLE nums (n UInt32) ENGINE = Memory")
conn.query("INSERT INTO nums VALUES (1), (2), (3)")
sql = conn.generate_sql("Select all rows from nums ordered by n desc")
print(sql) # e.g., SELECT * FROM nums ORDER BY n DESC
# ask(): one-call generate + execute
print(conn.ask("List the numbers table", format="Pretty"))
For more examples, see examples and tests.
Demos and Examples
- Project Documentation and Usage Examples
- Colab Notebooks and other Script Examples
Benchmark

Documentation
- For chdb specific examples and documentation refer to chDB docs
- For SQL syntax, please refer to ClickHouse SQL Reference
- For DataStore API, see Pandas Compatibility Guide
Events
- Demo chDB at ClickHouse v23.7 livehouse! and Slides
Contributing
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated. There are something you can help:
- Help test and report bugs
- Help improve documentation
- Help improve code quality and performance
Bindings
We welcome bindings for other languages, please refer to bindings for more details.
Version Guide
Please refer to VERSION-GUIDE.md for more details.
Paper
License
Apache 2.0, see LICENSE for more information.
Acknowledgments
chDB is mainly based on ClickHouse [^1] for trade mark and other reasons, I named it chDB.
Contact
- Discord: https://discord.gg/D2Daa2fM5K
- Email: auxten@clickhouse.com
- Twitter: @chdb
[^1]: ClickHouse® is a trademark of ClickHouse Inc. All trademarks, service marks, and logos mentioned or depicted are the property of their respective owners. The use of any third-party trademarks, brand names, product names, and company names does not imply endorsement, affiliation, or association with the respective owners.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file chdb-4.0.1-cp39-abi3-manylinux2014_x86_64.manylinux_2_17_x86_64.whl.
File metadata
- Download URL: chdb-4.0.1-cp39-abi3-manylinux2014_x86_64.manylinux_2_17_x86_64.whl
- Upload date:
- Size: 149.4 MB
- Tags: CPython 3.9+, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3d78fb82e29fe9d61ab70c452a7b818c84326ad8ac7eb7e9efd3cb0b2e7c6dee
|
|
| MD5 |
288f4b00d151f004d548b03d5e9b16fe
|
|
| BLAKE2b-256 |
2328f3aa551b4af78b8ac967c191407301eff5906dc7239ddb232d4d34bf8ad4
|
File details
Details for the file chdb-4.0.1-cp39-abi3-manylinux2014_aarch64.manylinux_2_17_aarch64.whl.
File metadata
- Download URL: chdb-4.0.1-cp39-abi3-manylinux2014_aarch64.manylinux_2_17_aarch64.whl
- Upload date:
- Size: 116.4 MB
- Tags: CPython 3.9+, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3cad5ed83e113304a04080d506b37c8370cdf5f6c2db4600de2a2ea850278aee
|
|
| MD5 |
5833ce633f4c11d749a73f08453f35fd
|
|
| BLAKE2b-256 |
f213463700d05ca19d71366255dfdffc57c7622a03000d3ace6ecbe04bed7537
|
File details
Details for the file chdb-4.0.1-cp39-abi3-macosx_11_0_arm64.whl.
File metadata
- Download URL: chdb-4.0.1-cp39-abi3-macosx_11_0_arm64.whl
- Upload date:
- Size: 84.2 MB
- Tags: CPython 3.9+, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
379434271621be972e18cd55cfd441317ced4c6a567f26c789f65df7bbec39ff
|
|
| MD5 |
f517bce7d03e5a2c893c56ec2b6f44ab
|
|
| BLAKE2b-256 |
150d7132912bd996bbc41c0f472218a4d14501b0ccc802a0ab46d40b5e6fee43
|
File details
Details for the file chdb-4.0.1-cp39-abi3-macosx_10_15_x86_64.whl.
File metadata
- Download URL: chdb-4.0.1-cp39-abi3-macosx_10_15_x86_64.whl
- Upload date:
- Size: 96.9 MB
- Tags: CPython 3.9+, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e58d80ba26338a400d6815f93868df420ddc50a6f573dacdb063531e7beeb567
|
|
| MD5 |
80236cd0a5945d9871fc6934c0fe7f5c
|
|
| BLAKE2b-256 |
beb1134c7ad7a50c574c255c6fa09fa59cee7710cf06ae90e09a866c0e7b1854
|







