The standard package for data-centric AI, machine learning with label errors, and automatically finding and fixing dataset issues in Python.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers






Project description






Documentation | Examples | Blog | Research
Cleanlab’s open-source library helps you clean data and labels by automatically detecting issues in a ML dataset. To facilitate machine learning with messy, real-world data, this data-centric AI package uses your existing models to estimate dataset problems that can be fixed to train even better models.
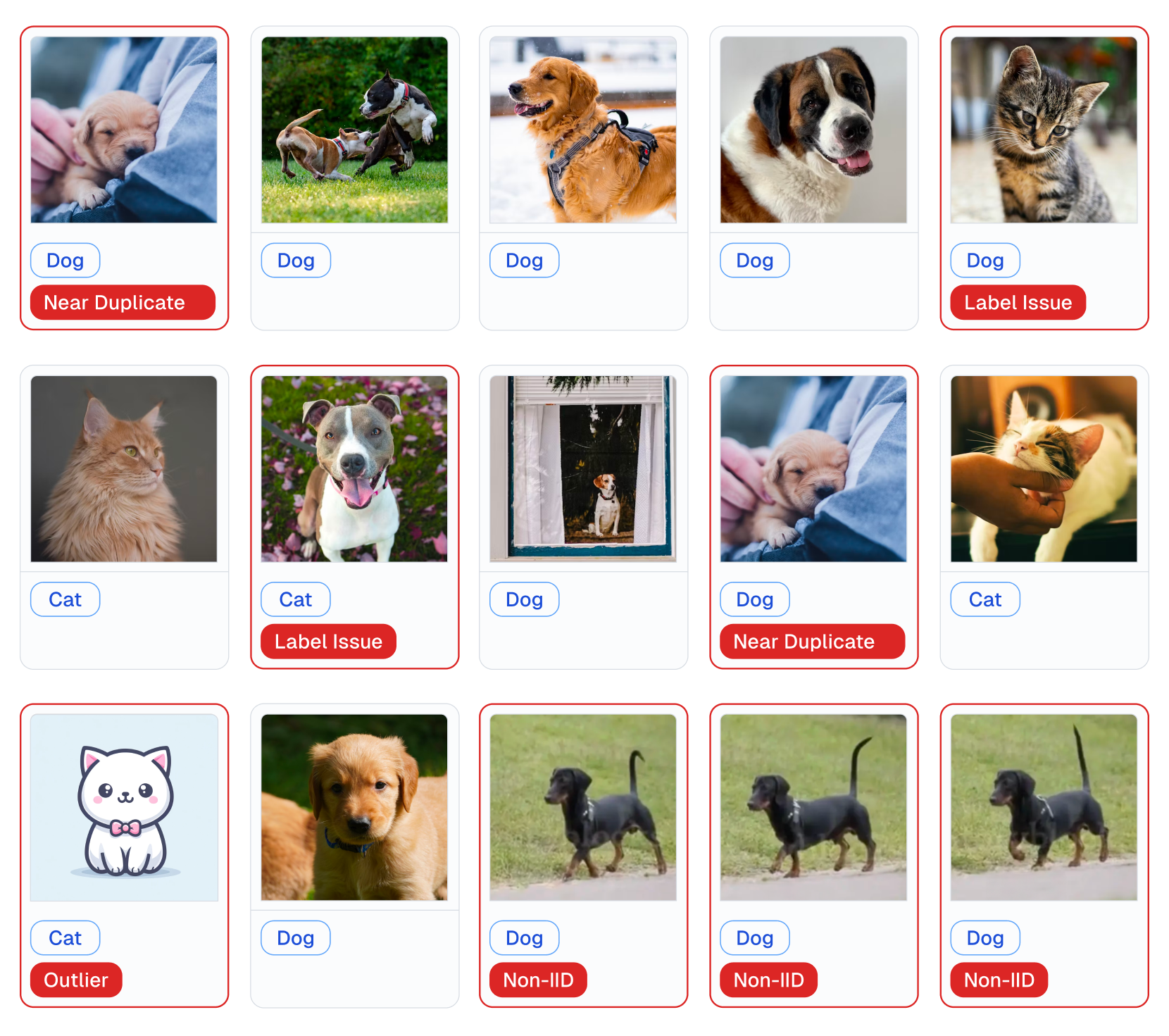
Examples of various issues in Cat/Dog dataset automatically detected by cleanlab via this code:
lab = cleanlab.Datalab(data=dataset, label="column_name_for_labels")
# Fit any ML model, get its feature_embeddings & pred_probs for your data
lab.find_issues(features=feature_embeddings, pred_probs=pred_probs)
lab.report()
- Use cleanlab to automatically check every: text, audio, image, or tabular dataset.
- Use cleanlab to automatically: detect data issues (outliers, duplicates, label errors, etc), train robust models, infer consensus + annotator-quality for multi-annotator data, suggest data to (re)label next (active learning).
Run cleanlab open-source
This cleanlab package runs on Python 3.10+ and supports Linux, macOS, as well as Windows.
- Get started here! Install via
uv,pip, orconda. - Developers who install the bleeding-edge from source should refer to this master branch documentation.
Practicing data-centric AI can look like this:
- Train initial ML model on original dataset.
- Utilize this model to diagnose data issues (via cleanlab methods) and improve the dataset.
- Train the same model on the improved dataset.
- Try various modeling techniques to further improve performance.
Most folks jump from Step 1 → 4, but you may achieve big gains without any change to your modeling code by using cleanlab! Continuously boost performance by iterating Steps 2 → 4 (and try to evaluate with cleaned data).
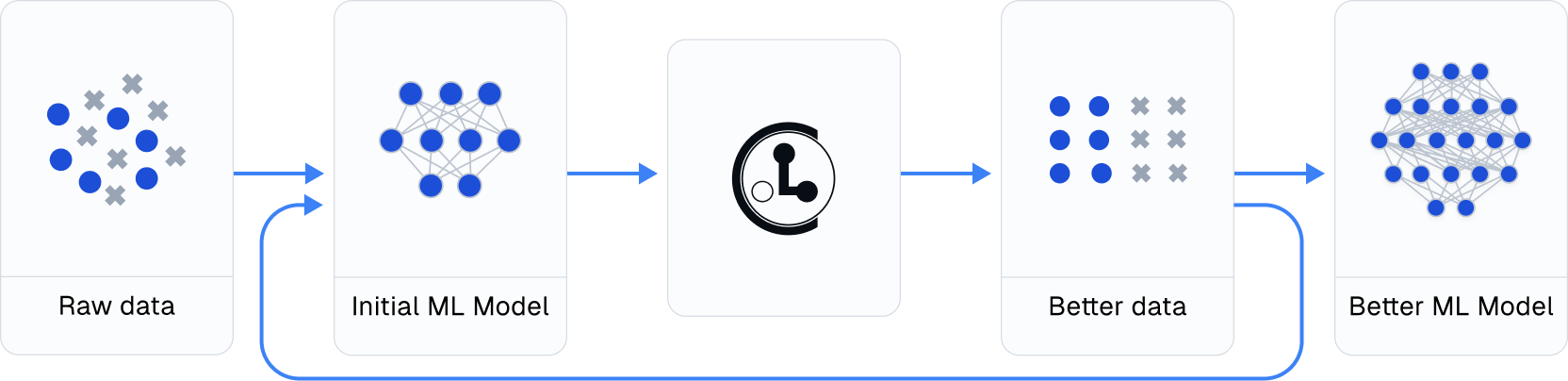
Use cleanlab with any model and in most ML tasks
All features of cleanlab work with any dataset and any model. Yes, any model: PyTorch, Tensorflow, Keras, JAX, HuggingFace, OpenAI, XGBoost, scikit-learn, etc.
cleanlab is useful across a wide variety of Machine Learning tasks. Specific tasks this data-centric AI package offers dedicated functionality for include:
- Binary and multi-class classification
- Multi-label classification (e.g. image/document tagging)
- Token classification (e.g. entity recognition in text)
- Regression (predicting numerical column in a dataset)
- Image segmentation (images with per-pixel annotations)
- Object detection (images with bounding box annotations)
- Classification with data labeled by multiple annotators
- Active learning with multiple annotators (suggest which data to label or re-label to improve model most)
- Outlier detection (identify atypical data that appears out of distribution)
For other ML tasks, cleanlab can still help you improve your dataset if appropriately applied. See our Example Notebooks and Blog.
So fresh, so cleanlab
Beyond automatically catching all sorts of issues lurking in your data, this data-centric AI package helps you deal with noisy labels and train more robust ML models. Here's an example:
# cleanlab works with **any classifier**. Yup, you can use PyTorch/TensorFlow/OpenAI/XGBoost/etc.
cl = cleanlab.classification.CleanLearning(sklearn.YourFavoriteClassifier())
# cleanlab finds data and label issues in **any dataset**... in ONE line of code!
label_issues = cl.find_label_issues(data, labels)
# cleanlab trains a robust version of your model that works more reliably with noisy data.
cl.fit(data, labels)
# cleanlab estimates the predictions you would have gotten if you had trained with *no* label issues.
cl.predict(test_data)
# A universal data-centric AI tool, cleanlab quantifies class-level issues and overall data quality, for any dataset.
cleanlab.dataset.health_summary(labels, confident_joint=cl.confident_joint)
cleanlab cleans your data's labels via state-of-the-art confident learning algorithms, published in this paper and blog. See some of the datasets cleaned with cleanlab at labelerrors.com.
cleanlab is:
- backed by theory -- with provable guarantees of exact label noise estimation, even with imperfect models.
- fast -- code is parallelized and scalable.
- easy to use -- one line of code to find mislabeled data, bad annotators, outliers, or train noise-robust models.
- general -- works with any dataset (text, image, tabular, audio,...) + any model (PyTorch, OpenAI, XGBoost,...)

Examples of incorrect given labels in various image datasets found and corrected using cleanlab. While these examples are from image datasets, this also works for text, audio, tabular data.
Citation and related publications
cleanlab is based on peer-reviewed research. Here are relevant papers to cite if you use this package:
Confident Learning (JAIR '21) (click to show bibtex)
@article{northcutt2021confidentlearning,
title={Confident Learning: Estimating Uncertainty in Dataset Labels},
author={Curtis G. Northcutt and Lu Jiang and Isaac L. Chuang},
journal={Journal of Artificial Intelligence Research (JAIR)},
volume={70},
pages={1373--1411},
year={2021}
}
Rank Pruning (UAI '17) (click to show bibtex)
@inproceedings{northcutt2017rankpruning,
author={Northcutt, Curtis G. and Wu, Tailin and Chuang, Isaac L.},
title={Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels},
booktitle = {Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence},
series = {UAI'17},
year = {2017},
location = {Sydney, Australia},
numpages = {10},
url = {http://auai.org/uai2017/proceedings/papers/35.pdf},
publisher = {AUAI Press},
}
Label Quality Scoring (ICML '22) (click to show bibtex)
@inproceedings{kuan2022labelquality,
title={Model-agnostic label quality scoring to detect real-world label errors},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML DataPerf Workshop},
year={2022}
}
Label Errors in Token Classification / Entity Recognition (NeurIPS '22) (click to show bibtex)
@inproceedings{wang2022tokenerrors,
title={Detecting label errors in token classification data},
author={Wang, Wei-Chen and Mueller, Jonas},
booktitle={NeurIPS Workshop on Interactive Learning for Natural Language Processing (InterNLP)},
year={2022}
}
Label Errors in Multi-Label Classification (ICLR '23) (click to show bibtex)
@inproceedings{thyagarajan2023multilabel,
title={Identifying Incorrect Annotations in Multi-Label Classification Data},
author={Thyagarajan, Aditya and Snorrason, Elías and Northcutt, Curtis and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
Label Errors in Object Detection (ICML '23) (click to show bibtex)
@inproceedings{tkachenko2023objectlab,
title={ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data},
author={Tkachenko, Ulyana and Thyagarajan, Aditya and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
Label Errors in Image Segmentation (ICML '23) (click to show bibtex)
@inproceedings{lad2023segmentation,
title={Estimating label quality and errors in semantic segmentation data via any model},
author={Lad, Vedang and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
Detecting Errors in Numerical Data (DMLR '24) (click to show bibtex)
@inproceedings{zhou2023errors,
title={Detecting Errors in a Numerical Response via any Regression Model},
author={Zhou, Hang and Mueller, Jonas and Kumar, Mayank and Wang, Jane-Ling and Lei, Jing},
booktitle={Journal of Data-centric Machine Learning Research},
year={2024}
}
Out-of-Distribution Detection (ICML '22) (click to show bibtex)
@inproceedings{kuan2022ood,
title={Back to the Basics: Revisiting Out-of-Distribution Detection Baselines},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML Workshop on Principles of Distribution Shift},
year={2022}
}
CROWDLAB for Data with Multiple Annotators (NeurIPS '22) (click to show bibtex)
@inproceedings{goh2022crowdlab,
title={CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators},
author={Goh, Hui Wen and Tkachenko, Ulyana and Mueller, Jonas},
booktitle={NeurIPS Human in the Loop Learning Workshop},
year={2022}
}
ActiveLab: Active learning with data re-labeling (ICLR '23) (click to show bibtex)
@inproceedings{goh2023activelab,
title={ActiveLab: Active Learning with Re-Labeling by Multiple Annotators},
author={Goh, Hui Wen and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
Detecting Dataset Drift and Non-IID Sampling (ICML '23) (click to show bibtex)
@inproceedings{cummings2023drift,
title={Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors},
author={Cummings, Jesse and Snorrason, Elías and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
To understand/cite other cleanlab functionality not described above, check out our Blog.
Other resources
-
Example Notebooks demonstrating practical applications of this package
-
NeurIPS 2021 paper: Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
Interested in contributing? See the contributing guide, development guide, and ideas on useful contributions.
Have questions? Check out our FAQ and Github Issues.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file cleanlab-2.9.0.tar.gz.
File metadata
- Download URL: cleanlab-2.9.0.tar.gz
- Upload date:
- Size: 273.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/4.0.2 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
abe25fe0c772ced8c4b36a94e0de71726db00802224b7fb7bee06db6ff95eb4e
|
|
| MD5 |
8650647c88869e5b94bd16aba6a40645
|
|
| BLAKE2b-256 |
82ab80cbcd832bda6e18ef22f0f9120675f70b7d532a164f762fb660f73fc346
|
File details
Details for the file cleanlab-2.9.0-py3-none-any.whl.
File metadata
- Download URL: cleanlab-2.9.0-py3-none-any.whl
- Upload date:
- Size: 306.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/4.0.2 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9a317d9ba547c388dd15fffec71fcf838cda1404ef4034b6865da78be6603f4e
|
|
| MD5 |
15ab0ca1ac94cee64b331ee10baf2332
|
|
| BLAKE2b-256 |
878a612ba4408b0b21c7ca8cf5671d61ddb5499e675bcec3058e6f48839672cb
|







