ClinicalPLAN is a Python package for predicting postoperative risks from clinical notes using language models. It provides training and inference workflows for fine-tuned models, semi-supervised methods, and multi-task prediction of multiple clinical outcomes. The package is intended for clinical research and educational use, notably for the American College of Surgeons.

This project has been archived.
The maintainers of this project have marked this project as archived. No new releases are expected.
Project description
Overview
ClinicalPLAN (Clinical Postoperative Risk Prediction with Language Models Adapting to Clinical Notes) is a Python package for predicting postoperative risks from clinical notes using language models. It provides flexible and clinically oriented workflows that support a range of perioperative use cases, enabling clinicians, researchers, and healthcare institutions to train and fine-tune models using preoperative or intraoperative clinical text.
The package is designed to be accessible to a broad range of users, including clinicians, surgeons, and researchers with limited programming experience. It minimizes the need to interact with lower-level machine learning frameworks such as PyTorch. With just a few lines of high-level functions, users can begin training and fine-tuning their own models.
ClinicalPLAN supports multiple modeling strategies, including:
- Direct inference with fine-tuned language models
- (Joint) Semi-supervised learning approaches for leveraging partially labeled data
- A multi-task learning framework that enables simultaneous prediction of multiple postoperative outcomes
The package was developed for the American College of Surgeons (ACS) workshop, AI for Clinicians and Surgeons: A Hands-On Introduction Across the Care Continuum.
The accompanying work is:
The foundational capabilities of large language models in predicting postoperative risks using clinical notes
Alba, Xue, Abraham, Kannampallil, and Lu (2025), npj Digital Medicine
Installation
pip install clinicalplan
Because torch CUDA wheels aren't hosted on PyPI, install PyTorch first matching your GPU's CUDA version, then install this package. For example, on a machine with CUDA 11.8 drivers:
pip install torch==2.1.2 --index-url https://download.pytorch.org/whl/cu118
pip install clinicalplan
Python version: 3.9–3.12 (tested on 3.12).
Quick example
import pandas as pd
from MultiTaskLearningPrediction import mtl_finetune, get_postoperative_outcome_scores
df = pd.read_csv("my_clinical_data.csv")
# df columns: "text", "Outcome_1", "Outcome_2", "Outcome_3", "Outcome_4"
# 1. Fine-tune
mtl_finetune(
df,
text_col="text",
outcome_cols=["Outcome_1", "Outcome_2", "Outcome_3", "Outcome_4"],
output_dir="my_finetuned_model",
)
# 2. Score a new scenario
note_1 = (
"83-year-old male, ASA 4, scheduled for coronary artery bypass graft (emergent three-vessel). "
"Indication: severe CAD with LAD stenosis, presenting with unstable angina. "
"PMH: COPD, type 2 diabetes mellitus, coronary artery disease, prior MI, chronic kidney disease stage 3. "
"Social: current smoker, 1 pack per day. "
"BMI 34 (obese). "
"Home medications: metoprolol, aspirin 81 mg, atorvastatin, insulin glargine, furosemide. "
"Allergies: NKDA. "
"Preop labs within acceptable limits. Consent obtained, plan to proceed."
)
scores = get_postoperative_outcome_scores(
"my_finetuned_model",
note_1
)
# {'Outcome_1': 0.12, 'Outcome_2': 0.28, 'Outcome_3': 0.04, 'Outcome_4': 0.39}
API reference
Direct inference
Allows users to use out-of-the-box models that have already been trained on clinical data and its associated post-operative outcomes. Unlike the later ones, this is a direct inference function that loads a pre-trained, ready-to-use model from HuggingFace Hub and therefore requires no model training.
The default model is cja5553/BJH-perioperative-notes-bioClinicalBERT, which is our a Bio+ClinicalBERT model variant that was multi-task fine-tuned across 6 postoperative outcomes: (1) death in 30, (2) DVT, (3) PE, (4) AKI, (5) delirium and (6) Pneumonoia. This model was used in our accompanying npj Digital Medicine paper.
direct_inference_from_trained_model
Score clinical text against a pre-trained multi-task model without any fine-tuning step. The model is downloaded from HuggingFace Hub on first use and cached locally thereafter.
Example
from clinicalplan import direct_inference_from_trained_model
note = (
"Redo coronary artery bypass graft with aortic valve replacement "
"bioprosthetic. Indication: severe ischemic cardiomyopathy, "
"ejection fraction 25 percent, prior MI, ventricular arrhythmia "
"status post AICD placement, stage 3 chronic kidney disease, COPD."
)
scores = direct_inference_from_trained_model(text=note)
# {'DVT': 0.17, 'PE': 0.06, 'PNA': 0.28, 'postop_del': 0.81,
# 'death_in_30': 0.46, 'post_aki_status': 0.93}
Parameters
text(str | list[str], required): One clinical scenario, or a list of them. Determines the shape of the return value.outcomes(list[str] | None, default:None): Which outcomes to score. Defaults to all outcomes the default model was trained on (DVT,PE,PNA,postop_del,death_in_30,post_aki_status), recovered from the model'smtl_metadata.json. Pass a subset to score only some.model_name(str, default:"cja5553/BJH-perioperative-notes-bioClinicalBERT"): HuggingFace repo ID or local path. Override to use your own fine-tuned model.max_length(int | None, default:None): Token sequence length. Defaults to the value used during fine-tuning, recovered from metadata.device(str | None, default:None):"cuda","cpu", orNoneto auto-detect.hf_token(str | None, default:None): Optional HuggingFace token, required only if the model repo is gated/private.
Returns
dict[str, float]whentextis a string — maps each outcome name to a probability in[0, 1].list[dict[str, float]]whentextis a list — one dict per input, in the same order.
Notes
- First call downloads the model (~440 MB) from HuggingFace and caches it locally; subsequent calls use the cache.
- Inference runs on CPU in ~5 seconds per note, or ~0.5 seconds with a GPU.
- For users who want to fine-tune their own model, see
mtl_finetune(multi-outcome) orjoint_finetune(single-outcome).
Joint or semi-supervised finetuning
Joint Single-Outcome Finetuning trains a separate model for each postoperative outcome of interest. The jointly learns the structure of your clinical notes whilst learns to predict the outcome, ensuring the model captures both the linguistic patterns of your institution's documentation style and the clinical features that drive your specific outcomes. Unlike the below MultiTaskLearningPrediction, this is catered to a single specific outcome as opposed to multiple outcomes.
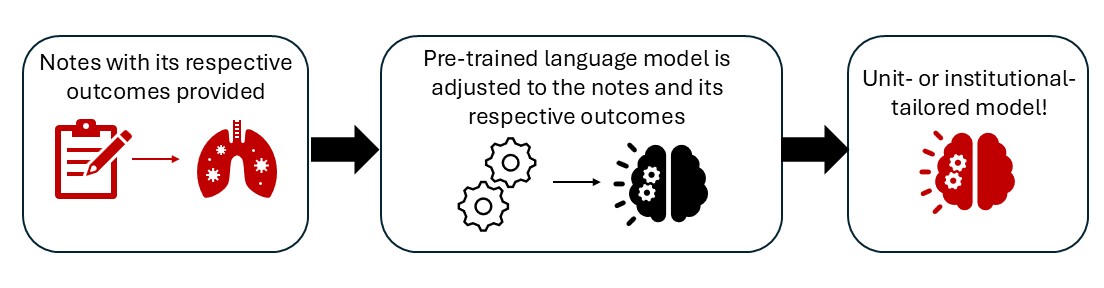
JointFinetuning
Perform Joint (or semi-supervised) finetuning.
Example
joint_finetune(
df,
text_col="clinical_notes",
outcome_col="DVT",
output_dir="DVT_model",
training_configs={
"num_train_epochs": 3,
"per_device_train_batch_size": 16,
"evaluation_strategy": "steps",
"eval_steps": 100,
"logging_steps": 100,
"learning_rate": 2e-5,
},
)
Fine-tune Bio+ClinicalBERT on MLM jointly with a single binary classification head for one outcome.
Parameters
df(pandas.DataFrame, required): Must containtext_colandoutcome_col.text_col(str, required): Name of the free-text column.outcome_col(str, required): Name of a single binary (0/1) outcome column. Rows with NaN in this column are dropped before training.output_dir(str, default"joint_finetuned"): Directory to save the fine-tuned model, tokenizer, and metadata. Also used as the HuggingFace Traineroutput_dirfor checkpoints and logs.base_model(str, default"emilyalsentzer/Bio_ClinicalBERT"): HuggingFace model id to start from. Any BERT-architecture model should work.hf_token(str | None, defaultNone): Optional HuggingFace token for gated/private base models. IfNone, uses the cached CLI login when present.max_length(int, default512): Token sequence length for tokenization.lambda_constant(float, default2): Weight on the auxiliary (BCE) loss relative to MLM loss. Total loss = MLM + λ · BCE.mlm_probability(float, default0.15): Token masking probability for MLM.val_fraction(float, default1/8): Fraction ofdfheld out for validation during training.weight(torch.Tensor | None, defaultNone): Optionalpos_weightforBCEWithLogitsLossto handle class imbalance. Useful for rare outcomes (e.g.,torch.tensor([20.0])for ~5% positive prevalence).training_configs(dict | None, defaultNone): Any keyword arguments accepted bytransformers.TrainingArguments. User-provided values override the defaults below. Defaulttraining_configsis{"num_train_epochs": 5, "per_device_train_batch_size": 24, "per_device_eval_batch_size": 24, "learning_rate": 1e-5, "warmup_ratio": 0.06, "weight_decay": 1e-3, "logging_steps": 1000, "save_strategy": "epoch", "seed": 42, "report_to": "none"}.
Returns
str — the output_dir path. After training, this directory contains:
pytorch_model.bin(ormodel.safetensors) — model weightsconfig.json— model architecture configtokenizer.json,vocab.txt,tokenizer_config.json,special_tokens_map.json— tokenizerjoint_metadata.json— recordsoutcome_col,text_col,max_length,base_model,lambda_constant,num_tasks(always 1), andworkflowso inference can recover them automaticallycheckpoint-*— per-epoch training checkpoints (can be deleted after training)logs/— TensorBoard-compatible training logs
get_outcome_score
Score a text scenario (or list of scenarios) against the single auxiliary head of a joint-finetuned model.
Example
get_outcome_score(
model_name="DVT_model",
text="83-year-old male, ASA 4, scheduled for CABG. PMH: COPD, diabetes.",
)
Parameters
model_name(str, required): Path to a directory saved byjoint_finetune.text(str | list[str], required): One scenario string, or a list of them. Determines the shape of the return value.max_length(int | None, default:None): Token sequence length. Defaults to the value used during fine-tuning, recovered fromjoint_metadata.json, otherwise512.device(str | None, default:None):"cuda","cpu", orNoneto auto-detect.hf_token(str | None, default:None): Optional HuggingFace token for gated/private models.
Returns
floatwhentextis a string — the predicted probability for the trained outcome, in[0, 1].list[float]whentextis a list — one probability per input, in the same order.
Multi-task finetuning
Multi-Task Learning (MTL) allows you to train a single versatile model capable of predicting multiple postoperative outcomes from the same clinical notes. Unlike traditional finetuning strategies — where you'd need to train a single model for each outcome — MTL allows you to create a model capable of simultaneously predicting multiple risks — analogous to foundation models.
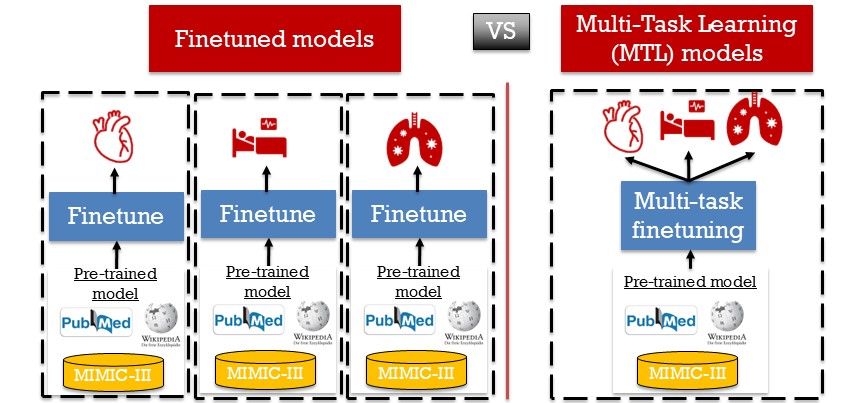
MultiTaskLearningPrediction
Performs MTL finetuning.
Example
mtl_finetune(
df,
text_col="clincal_notes",
outcome_cols=["death_30d", "dvt", "pneumonia", "aki", "AUR", "PE"],
output_dir="my_run",
training_configs={
"num_train_epochs": 3,
"per_device_train_batch_size": 16,
"evaluation_strategy": "steps",
"eval_steps": 100,
"logging_steps": 100,
"learning_rate": 2e-5
}
)
Fine-tune Bio+ClinicalBERT on MLM jointly with one binary classification head per outcome.
Parameters
df(pandas.DataFrame, required): Must containtext_coland alloutcome_cols.text_col(str, required): Name of the free-text column.outcome_cols(list[str], required): Names of binary (0/1) outcome columns. One auxiliary head is trained per outcome. Rows with NaN in a given outcome are dropped for that outcome's task but used for the others.output_dir(str, default"mtl_finetuned"): Directory to save the fine-tuned model, tokenizer, and metadata. Also used as the HuggingFace Traineroutput_dirfor checkpoints and logs.base_model(str, default"emilyalsentzer/Bio_ClinicalBERT"): HuggingFace model id to start from. Any BERT-architecture model should work.max_length(int, default512): Token sequence length for tokenization.lambda_constant(float, default2): Weight on the auxiliary (per-outcome BCE) loss relative to MLM loss. Total loss = MLM + λ · mean(per-task BCE).val_fraction(float, default1/8): Fraction ofdfheld out for validation during training.training_configs(dict | None, defaultNone): Any keyword arguments accepted bytransformers.TrainingArguments. User-provided values override the defaults below. Defaulttraining_configsis{"num_train_epochs": 5, "per_device_train_batch_size": 24, "per_device_eval_batch_size": 24, "learning_rate": 1e-5, "warmup_ratio": 0.06, "weight_decay": 1e-3, "logging_steps": 1000 "save_strategy": "epoch", "seed": 42,}
Returns
str — the output_dir path. After training, this directory contains:
pytorch_model.bin(ormodel.safetensors) — model weightsconfig.json— model architecture configtokenizer.json,vocab.txt,tokenizer_config.json,special_tokens_map.json— tokenizermtl_metadata.json— recordsoutcome_cols,text_col,max_length,base_model,lambda_constant,num_tasksso inference can recover them automaticallycheckpoint-*— per-epoch training checkpoints (can be deleted after training)logs/— TensorBoard-compatible training logs
get_postoperative_outcome_scores
Score a text scenario (or list of scenarios) against each auxiliary head of a fine-tuned MTL model.
Example
get_postoperative_outcome_scores(
model_name,
text,
outcomes=["death_30d", "dvt", "pneumonia", "aki", "AUR", "PE"],
)
Parameters
model_name(str, required): Path to a directory saved bymtl_finetune.text(str | list[str], required): One scenario string, or a list of them. Determines the shape of the return value.outcomes(list[str] | None, default:None): Which outcomes to score. Defaults to all outcomes the model was trained on, recovered frommtl_metadata.json. Pass a subset to score only some. Names must match those used inmtl_finetune.max_length(int | None, default:None): Token sequence length. Defaults to the value used during fine-tuning, recovered from metadata, otherwise512.device(str | None, default:None):"cuda","cpu", orNoneto auto-detect.
Returns
dict[str, float]whentextis a string — maps each outcome name to a probability in[0, 1].list[dict[str, float]]whentextis a list — one dict per input, in the same order.
get_pseudo_data
Generate a small synthetic dataset of preoperative clinical notes with binary outcomes for testing and demonstration. Outcomes are not random — each is driven by realistic feature combinations in the note (procedure type, age, ASA class, comorbidities), so a fine-tuned model is expected to learn meaningful associations.
Example
df = get_pseudo_data()
print(df.shape) # (1000, 5)
print(df.columns.tolist()) # ['text', 'Outcome_1', 'Outcome_2', 'Outcome_3', 'Outcome_4']
Parameters
None.
Returns
pandas.DataFrame with 1000 rows and 5 columns:
text(str) — synthetic preoperative note.Outcome_1toOutcome_4(int, 0/1) — binary outcomes driven by clinical features in the note.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file clinicalplan-0.1.6.tar.gz.
File metadata
- Download URL: clinicalplan-0.1.6.tar.gz
- Upload date:
- Size: 28.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8458985f11394d4ef6b1b522a96718fbac939f6cb6bbdf478c735c5345824f88
|
|
| MD5 |
6dbf63f6cfe00e2d858626239fa1bf17
|
|
| BLAKE2b-256 |
20e30612869aa93a1fcd3c43ab6b4ed00e3678e9d0c2a3fbfedba6f5282ffeb5
|
File details
Details for the file clinicalplan-0.1.6-py3-none-any.whl.
File metadata
- Download URL: clinicalplan-0.1.6-py3-none-any.whl
- Upload date:
- Size: 28.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
49f95b73aec5837e1ce3c28b0fd99a25c939a9b14f8ca0952cfb4b4c588e0d81
|
|
| MD5 |
ebedfd7bb4fcb7d7594701f0da1054a2
|
|
| BLAKE2b-256 |
cbbbf8b7a5da4085de0a9e604240a0eaf2625e5f540ab5ec65cf478b63c3a1f5
|







