Index your codebase. AI searches instead of re-reading files. Save 70%+ on tokens. Works with Claude Code, Cursor, VS Code, Gemini CLI, and Codex.

Project description

Code Context Engine
Index your codebase. AI searches instead of re-reading files. 93% token savings, benchmarked.





Works with your editor
One command. Index your codebase. Your AI coding agent searches instead of reading entire files.
Zero-cloud, zero-config. cce init auto-detects your editor.

Install and see savings in 60 seconds
uv tool install code-context-engine # or: pipx install code-context-engine
cd /path/to/your/project
cce init # index, install hooks, register MCP server
Restart your editor. Done. Every question now hits the index instead of re-reading files.
cce init auto-detects your editor and writes the right config:
| Editor | Config written | Instructions |
|---|---|---|
| Claude Code | .mcp.json |
CLAUDE.md |
| VS Code / Copilot | .vscode/mcp.json |
|
| Cursor | .cursor/mcp.json |
.cursorrules |
| Gemini CLI | .gemini/settings.json |
GEMINI.md |
| OpenAI Codex | .codex/config.toml |
Multiple editors in the same project? All get configured in one command.
my-project · 38 queries
⛁ ⛁ ⛁ ⛶ ⛶ ⛶ ⛶ ⛶ ⛶ ⛶ 93% tokens saved
Without CCE 48.0k tokens $0.24
With CCE 3.4k tokens $0.02
──────────────────────────────────────────
Saved 44.6k tokens $0.22
Cost estimate based on Opus input pricing ($5/1M tokens)
Why this matters
Input tokens are 85-95% of your Claude Code bill. CCE cuts them by 93% (benchmarked on FastAPI).
Without CCE: Claude reads payments.py + shipping.py = 45,000 tokens
With CCE: context_search "payment flow" = 800 tokens
| Without CCE | With CCE | |
|---|---|---|
| Session startup | Re-reads files every time | Queries the index |
| Finding a function | Read entire 800-line file | Get the 40-line function |
| Cross-session memory | None | Decisions + code areas persisted |
| Token cost (Opus, medium project) | ~$0.48/session | ~$0.14/session |
Benchmark: FastAPI (independently verified)
We benchmarked CCE against FastAPI (48 source files, 19K lines of Python) with 20 real coding questions. No cherry-picking, no synthetic queries.
Methodology: For each query, "without CCE" means reading the full content of every file the query touches. "With CCE" means the relevant chunks after compression. This is conservative (agents often read more files than needed).
| Metric | Result |
|---|---|
| Retrieval | 93% savings (75,355 → 5,381 tokens/query) |
| + Compression | 90% additional (5,381 → 541 tokens/query) |
| Combined | 99.3% (75,355 → 541 tokens/query) |
| Recall@10 (found the right files) | 0.80 |
| Precision@10 | 0.30 |
| Latency p50 | 0.4ms |
| Queries tested | 20 |
Per-Layer Savings (each measured independently)
| Layer | What it does | Savings | Method |
|---|---|---|---|
| Retrieval | Full files → relevant code chunks | 93% | measured |
| Chunk Compression | Raw chunks → signatures + docstrings | 90% | measured |
| Output Compression | Reduces Claude's reply length | 65% | estimated |
| Grammar | Drops articles/fillers from memory text | 13% | measured |
Reproduce it yourself:
pip install code-context-engine
python benchmarks/run_benchmark.py --repo https://github.com/fastapi/fastapi.git --source-dir fastapi
Full results in benchmarks/results/fastapi.md. Queries and methodology in benchmarks/.
What you get
9 MCP tools that Claude uses automatically:
| Tool | What it does |
|---|---|
context_search |
Hybrid vector + BM25 search with graph expansion |
expand_chunk |
Full source for a compressed result |
related_context |
Find code via graph edges (calls, imports) |
session_recall |
Recall decisions from past sessions |
record_decision |
Save a decision for future sessions |
record_code_area |
Record which files were worked in |
index_status |
Check index freshness |
reindex |
Re-index a file or the full project |
set_output_compression |
Adjust response verbosity (off / lite / standard / max) |
Live dashboard with donut charts, file health, and session history:
cce dashboard
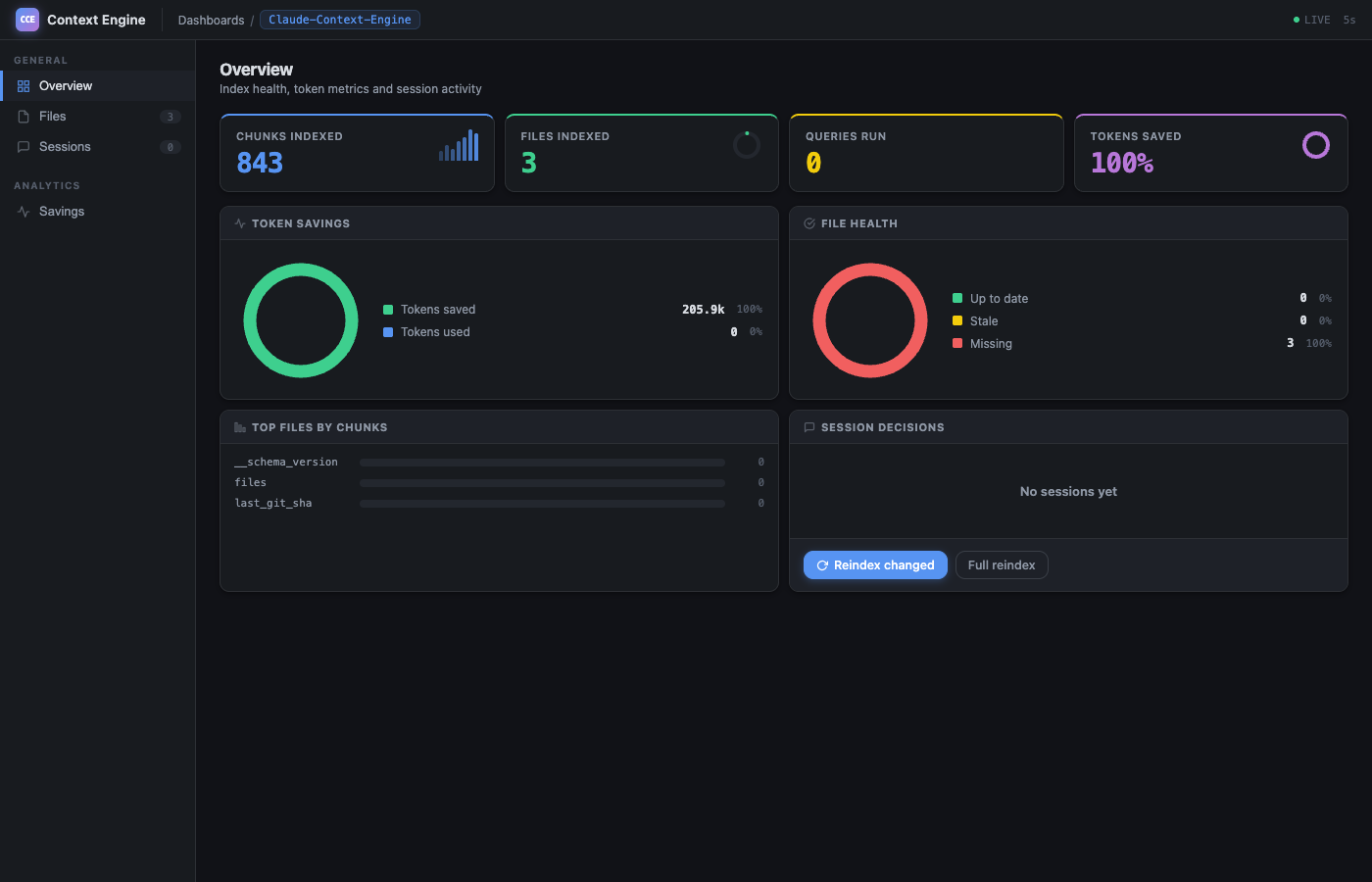
Dollar estimates fetched from live Anthropic pricing:
cce savings --all # see savings across all projects
How it works (the short version)
- Index: Tree-sitter parses your code into semantic chunks (functions, classes, modules). Stored as vector embeddings locally.
- Search: Claude calls
context_search. Hybrid vector + BM25 retrieval finds the right chunks. Code graph adds related files automatically. - Compress: Chunks are truncated to signatures + docstrings (or LLM-summarized if Ollama is running).
- Remember: Decisions and code areas persist across sessions via
session_recall. - Track: Every query is logged.
cce savingsshows exactly how much you saved.
Re-indexing after edits takes under 1 second (96% embedding cache hit rate). Git hooks keep the index current automatically.
What makes CCE different
It saves where the money is
Output compression tools (like Caveman) save 20-75% on output tokens. Output is 5-15% of your bill. Net savings: ~11%.
CCE saves on input tokens (93% retrieval + 90% compression on FastAPI, independently benchmarked). Input is 85-95% of your bill.
It actually understands your code
Not a text search. Tree-sitter AST parsing creates semantic chunks. Hybrid retrieval merges vector similarity with BM25 keyword matching via Reciprocal Rank Fusion. A confidence scorer blends similarity (50%), keyword match (30%), and recency (20%). Graph expansion walks CALLS/IMPORTS edges to pull in related code.
It remembers
record_decision("use JWT for auth", reason="session tokens flagged by legal") is stored in SQLite and surfaces via session_recall in the next session. No re-explaining your architecture.
It tracks real savings
Not estimates. Actual tokens served vs full-file baseline, broken down by buckets (retrieval, compression, output, memory, grammar). Dollar costs fetched from Anthropic's pricing page. Savings summary shown at every session start.
It is secure by default
Secret files (.env, *.pem, credentials.json) are never indexed. Content is scanned for AWS keys, GitHub tokens, Slack tokens, Stripe keys, JWTs, and generic credentials. PII (emails, IPs, SSNs, credit cards) is scrubbed from memory writes. All MCP file paths are validated against path traversal.
Under the hood
Content-Hash Embedding Cache
SHA-256 fingerprint per chunk, salted with model name. Re-index skips unchanged code. Binary float32 storage (10x smaller than JSON). Typical re-index: 96% cache hit, under 1 second.
sqlite-vec: 2 MB instead of 217 MB
Replaced LanceDB with sqlite-vec. Same cosine-distance quality, 99% smaller install. WAL mode + PRAGMA NORMAL for 80% write speedup. Vectors, FTS5, code graph, and compression cache all in three SQLite files.
Deterministic Grammar Compression
Memory entries compressed without LLM calls. Drops articles, fillers, pronouns. Three levels (lite/full/ultra, 20-60% savings). Code, paths, URLs preserved byte-for-byte. Same input always yields same output.
Fail-Closed Hook Design
5 Claude Code lifecycle hooks capture session context. Every hook runs curl ... || true, so a crashed server never blocks the user. SessionStart injects bootstrap context; others capture silently.
Dynamic Pricing
Dollar estimates in cce savings come from live Anthropic pricing (HTML table parsed, cached 7 days, offline fallback). No manual updates when rates change.
Append-Only Savings Ledger
7 buckets track every token saved: retrieval, chunk compression, output compression, memory recall, grammar, turn summarization, progressive disclosure. Survives restarts. Powers CLI and dashboard analytics.
CLI at a glance
cce init # Index + install hooks + register MCP
cce # Status banner
cce savings # Token savings with dollar estimates
cce savings --all # All projects
cce dashboard # Web dashboard with live charts
cce search "auth flow" # Test a query
cce status # Index health + config
cce services # Ollama + dashboard + MCP status
cce commands add-rule '...' # Project rules for Claude
cce uninstall # Clean removal of all CCE artifacts
Run cce list for the full command reference.
Configuration
Zero-config by default. Override what you need in ~/.cce/config.yaml or .context-engine.yaml:
compression:
level: standard # minimal | standard | full
output: standard # off | lite | standard | max
retrieval:
top_k: 20
confidence_threshold: 0.5
pricing:
model: opus # opus | sonnet | haiku
Output Compression
CCE also compresses Claude's responses (same concept as Caveman):
| Level | Style | Savings |
|---|---|---|
off |
Full output | 0% |
lite |
No filler or hedging | ~30% |
standard |
Fragments, drop articles | ~65% |
max |
Telegraphic | ~75% |
Tell Claude: "switch to max compression" or "turn off compression". Code blocks and commands are never compressed.
Disk Footprint
| Component | Size |
|---|---|
| Installed package | ~189 MB (ONNX Runtime is 66 MB of that) |
| Embedding model (one-time download) | ~60 MB |
| Index per project (small/medium/large) | 5-60 MB |
No GPU required. Embedding model runs on CPU via ONNX Runtime.
Supported Languages
AST-aware chunking (10 extensions):
| Language | Extensions |
|---|---|
| Python | .py |
| JavaScript | .js, .jsx |
| TypeScript | .ts, .tsx |
| PHP | .php |
| Go | .go |
| Rust | .rs |
| Java | .java |
Fallback chunking: All other text files (Markdown, YAML, config, etc.) chunked by line range.
Documentation
| Page | Content |
|---|---|
| Examples | Real conversations with Claude |
| How It Works | Full 9-stage pipeline |
| CLI Reference | Every command with output |
| Configuration | All config options |
| Project Commands | Rules and preferences for Claude |
| Tech Stack | Every library and why |
Roadmap
- Semantic indexing + hybrid retrieval + graph expansion
- Cross-session memory (decisions, code areas, session recall)
- Web dashboard with live charts
- Token savings tracking with dollar estimates
- Output compression (off / lite / standard / max)
- Content-hash embedding cache (96% hit rate on re-index)
- sqlite-vec migration (99% smaller install)
- Dynamic pricing from Anthropic docs
- 7-layer security (secrets, PII, path traversal, audit log)
- Clean uninstall (removes all CCE artifacts)
- AST-aware chunking for PHP, Go, Rust, Java (tree-sitter)
- Multi-editor support (Cursor, VS Code/Copilot, Gemini CLI)
- Reproducible benchmark suite (93% savings on FastAPI, per-layer breakdown)
- Session savings visibility (shown at every session start)
- Tree-sitter support for C, C++, Ruby, Swift, Kotlin
- Docker support for remote mode
Contributing
Contributions welcome. See https://github.com/elara-labs/code-context-engine/blob/main/CONTRIBUTING.md for setup.
License
MIT. See LICENSE.
Authors
Acknowledgments
Claude Code · MCP · sqlite-vec · Tree-sitter · fastembed · Ollama
If CCE saves you tokens, give it a star.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file code_context_engine-0.4.3.tar.gz.
File metadata
- Download URL: code_context_engine-0.4.3.tar.gz
- Upload date:
- Size: 196.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ca72be89c9b01431ad43196c0791453478b3e5cbff7bed7e4a8752fd20197cee
|
|
| MD5 |
fcf0d9735b7067d171a06bdcb42477a9
|
|
| BLAKE2b-256 |
618736ee00f4c81770f7389ae8107c7656d34cd496a3cc35c3d4974b96c92df6
|
File details
Details for the file code_context_engine-0.4.3-py3-none-any.whl.
File metadata
- Download URL: code_context_engine-0.4.3-py3-none-any.whl
- Upload date:
- Size: 194.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
414c336490396c16aafc915c47cc6f93bdb8275fe01effb0cfde22d054519451
|
|
| MD5 |
4b0a7a5b7343e850d879dd0e30619862
|
|
| BLAKE2b-256 |
71f8dd25da2a1293b71db2f306f25568a756ccf496e4f2c629cee3599b060e82
|







