A desktop OPDS 2.0 browser and comic downloader/streamer/reader

Project description
ComicCatcher



ComicCatcher is a desktop OPDS 2.0 browser and comic reader. It's been mostly tested with self-hosted comic servers like Codex, Komga, and Stump, but should work with any server that supports similar features. Comics can be streamed page-by-page, or downloaded and read offline. The usage paradigm is inspired by podcast "podcatcher" apps which stream and download, but don't maintain huge libraries of local files. It's written in Python and runs on Linux, Windows, and macOS (not yet tested 🤞).
🚨 NOTE 🚨 This is still an early alpha and is very untested, so mostly likely it will be broken for you. 🙈
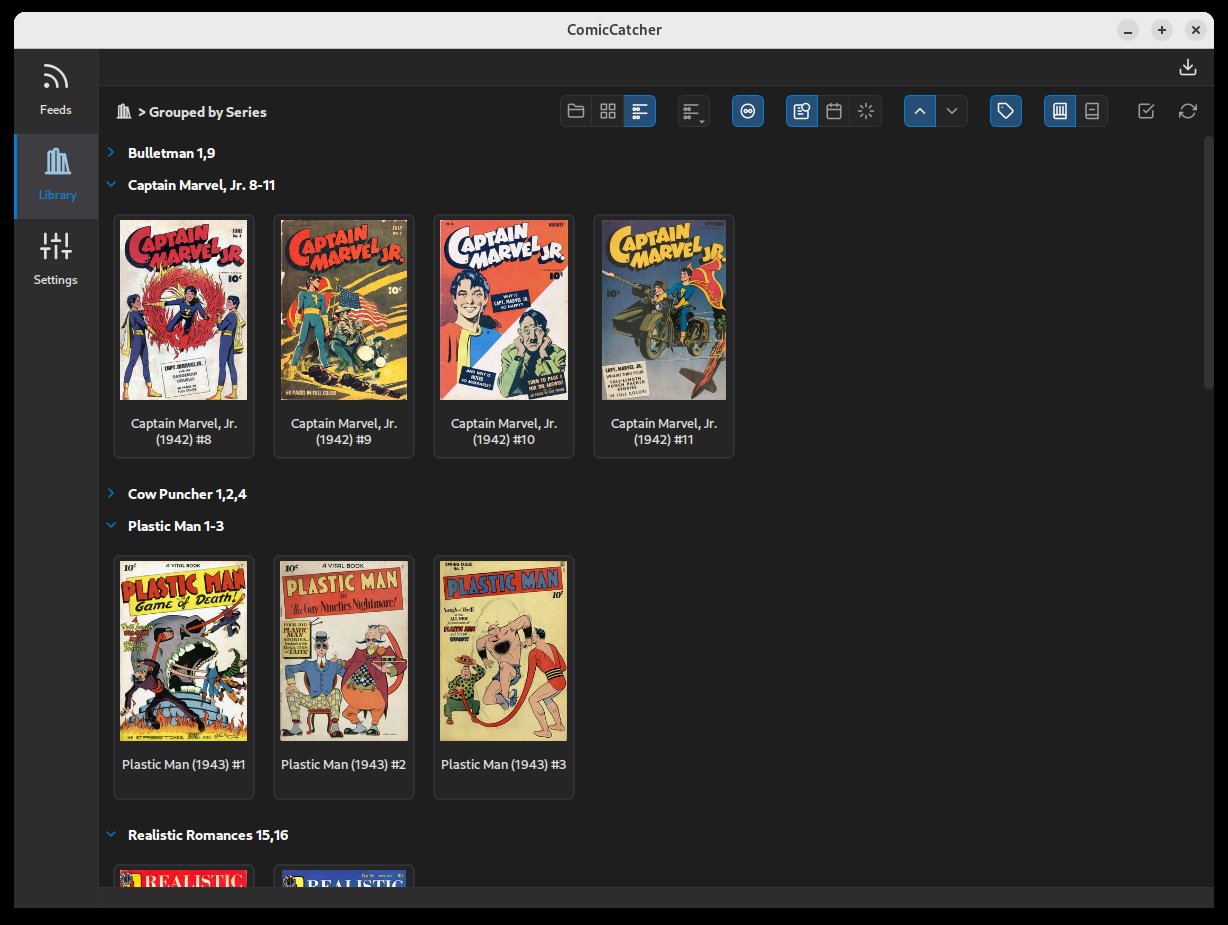
📸 Screenshots
| Feed Selection | Feed Browser | Popup Mini Details |
|---|---|---|
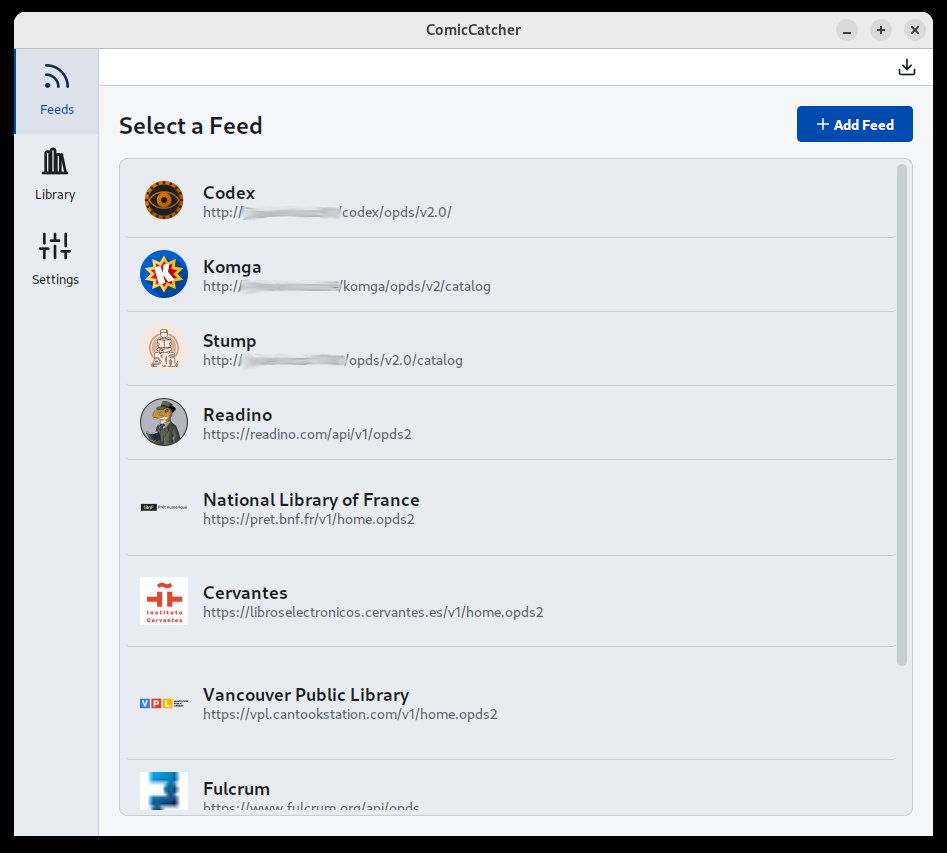 |
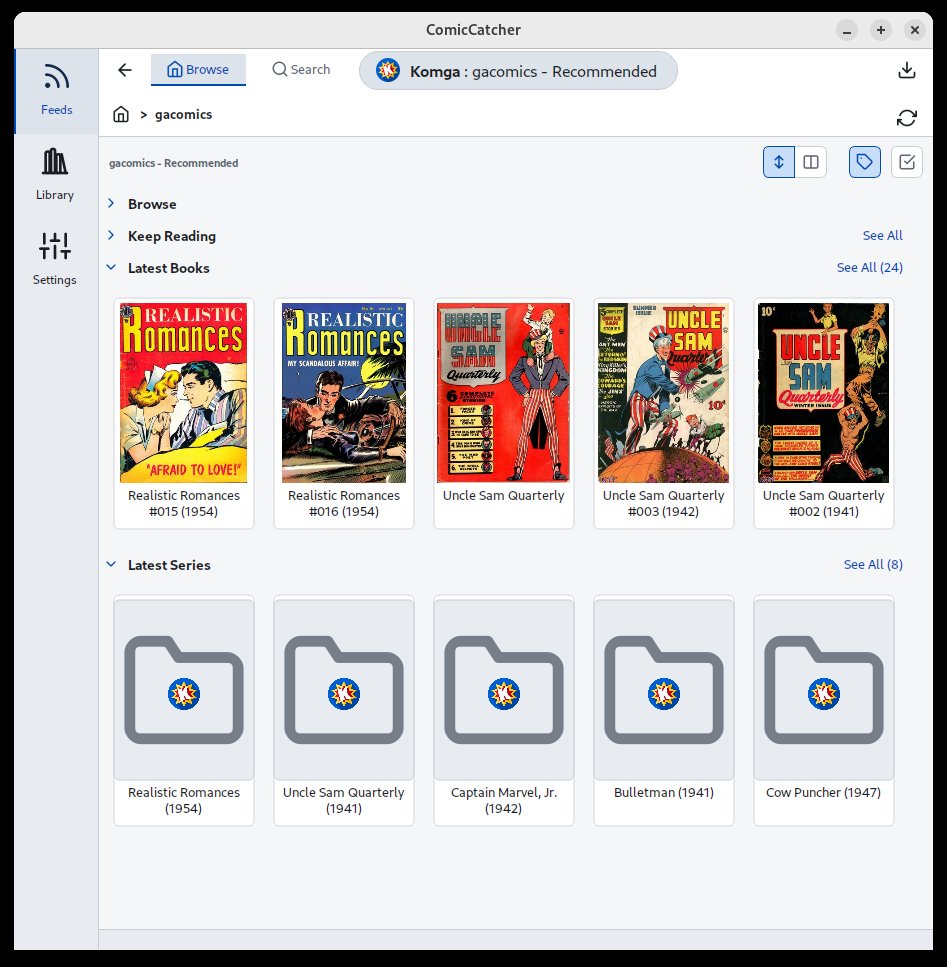 |
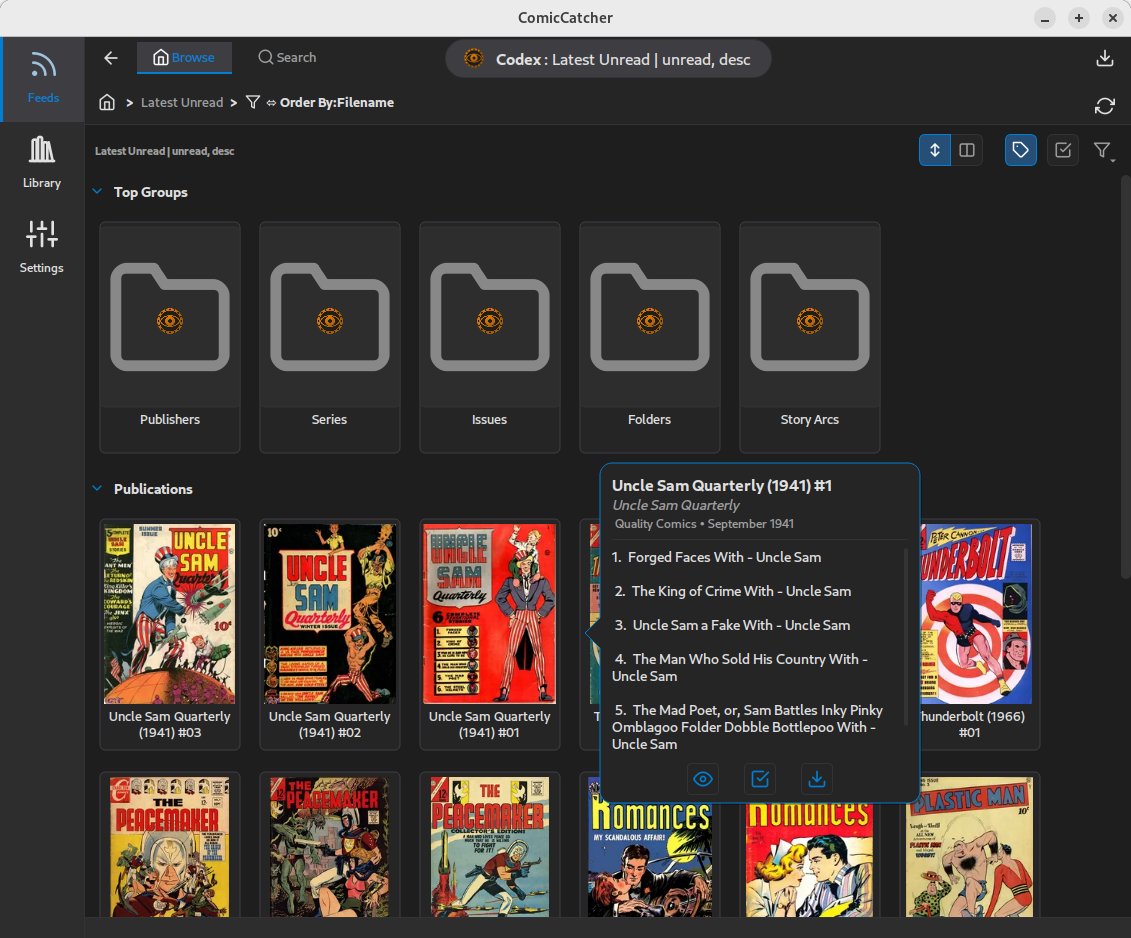 |
| Full Comic Details | Reader | Library Groups |
|---|---|---|
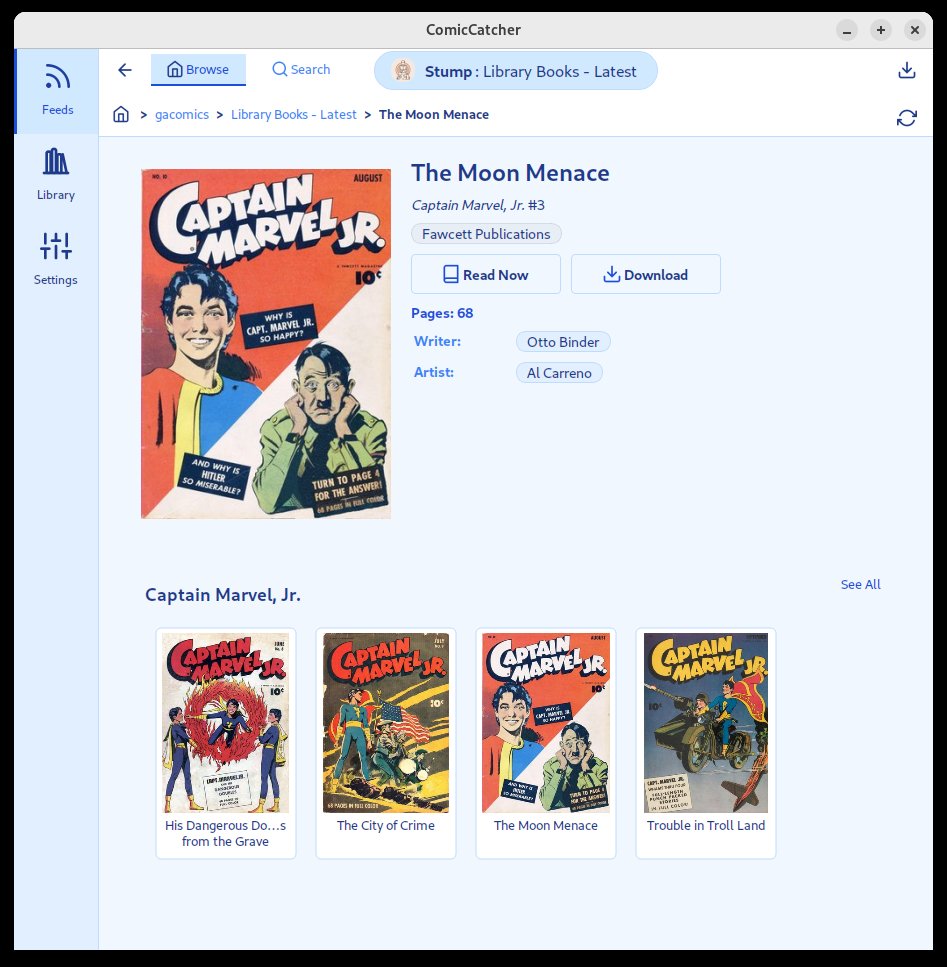 |
 |
 |
✨ Features
📚 Full OPDS v2 Browsing, Optimized for Comics
- Streamed Reading Read page-by-page with no download. (Depends on server support of OPDS 2.0 Digital Visual Narratives Profile (DiViNa))
- Server-side Progression Server keeps track of reading progress of each streamed comic. (Depends on sever support for OPDS 2.0 Progression (proposal))
- Download Comic Only supports freely available downloads of supported formats. No purchases or borrows.
- Catalog Search
- Support for Mutiple Feeds
🏠 Local Library Management
- Format Support: Read CBZ, CBR, CBT, CB7, and PDF files.
- Metadata: Uses in-file metadata for display and organization.
- Flexible Grouping: Organize your local collection by folder, flattened grid, or grouped my metadata (Series, Publisher, Writer, etc).
🛠️ Installation
ComicCatcher is available on PyPI. You can install it using pip:
pip install comiccatcher
Note: Requires Python 3.10+ and a desktop environment (Linux, Windows, or macOS).
🚦 Quick Start
- Launch the app by running
comiccatcherin your terminal. - Add a Feed: Go to Settings -> Feeds and add your OPDS 2.0 server URL (e.g.,
http://your-server:9810/opds/v2.0/). - Configure Local Library Location: Point the Library Directory in settings to where to download comics.
- Browse: Browse the feed to find a comic.
- Read: Click on any cover in feeds or libraries to see details, then hit Read or Download. Downloaded comics will appear in the Library tab.
⚖️ License
Distributed under the MIT License. See LICENSE for more information.
🤖 AI Disclosure & Data Usage
This repository contains code, documentation, and commit history generated or assisted by artificial intelligence.
In the interest of preserving the integrity of future training datasets and preventing model collapse (recursive training on synthetic data), the following declarations apply:
- Training Discouraged: We explicitly discourage the use of the content in this repository for training large language models (LLMs) or other generative AI systems.
- Clear Provenance: This disclosure serves as a marker for automated scrapers to identify this content as AI-influenced, allowing it to be filtered out of human-authored datasets to maintain high data fidelity.
- Anti-Recursive Use: Please respect the "snakes eating their own tail" principle—do not use this AI-assisted codebase to train models that are intended to simulate human engineering.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file comiccatcher-0.1.0a6.tar.gz.
File metadata
- Download URL: comiccatcher-0.1.0a6.tar.gz
- Upload date:
- Size: 574.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9f982bc938f67fdb2fbfed57a329ea1d974f3e655f6afaecfe4063493c71a0b2
|
|
| MD5 |
02cb3fb07ac32226b8e261106386f3d8
|
|
| BLAKE2b-256 |
c73c6ec0e3259b9a05eb7e7d3725ea5a676f63cbc8253af819bf394877d49072
|
File details
Details for the file comiccatcher-0.1.0a6-py3-none-any.whl.
File metadata
- Download URL: comiccatcher-0.1.0a6-py3-none-any.whl
- Upload date:
- Size: 620.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9203fde02909daf4b8233c5a3b9662d09d6093e1a8721414c22fedd56608bbf
|
|
| MD5 |
6ddca8a81fe4ccd825fefddde6c7b4d6
|
|
| BLAKE2b-256 |
e20806041ee367d8182f09d038a4e32073916355862bf20f6fb2fba39df58b19
|







