An image crawler, including multiple modules and GUI.

Project description

Comic Crawler 是用來扒圖的一支 Python Script。擁有簡易的下載管理員、圖書館功能、 與方便的擴充能力。
下載和安裝(Windows)
Comic Crawler is on PyPI. 安裝完 python 後,可以直接用 pip 指令自動安裝。
Install Python
你需要 Python 3.11 以上。安裝檔可以從它的 官方網站 下載。
安裝時記得要選「Add python.exe to path」,才能使用 pip 指令。
Install Deno
Comic Crawler 使用 Deno 來分析需要執行 JavaScript 的網站︰ https://docs.deno.com/runtime/manual/getting_started/installation
Windows 10 (1709) 以上的版本,可以直接在 cmd 底下輸入以下指令安裝︰
winget install deno
Install Comic Crawler
在 cmd 底下輸入以下指令︰
pip install comiccrawler
更新時︰
pip install comiccrawler --upgrade --upgrade-strategy eager
最後在 cmd 底下輸入以下指令執行 Comic Crawler︰
comiccrawler gui
Supported domains
163.bilibili.com 8comic.com 99.hhxxee.com ac.qq.com beta.sankakucomplex.com chan.sankakucomplex.com comic.acgn.cc comic.sfacg.com comicbus.com coomer.su copymanga.com danbooru.donmai.us deviantart.com e-hentai.org exhentai.org fanbox.cc fantia.jp gelbooru.com hk.dm5.com ikanman.com imgbox.com jpg4.su kemono.party kemono.su konachan.com linevoom.line.me m.dmzj.com m.manhuabei.com m.wuyouhui.net manga.bilibili.com manhua.dmzj.com manhuagui.com nijie.info pixabay.com raw.senmanga.com seemh.com seiga.nicovideo.jp smp.yoedge.com tel.dm5.com tsundora.com tuchong.com tumblr.com tw.weibo.com twitter.com wix.com www.177pic.info www.1manhua.net www.33am.cn www.36rm.cn www.99comic.com www.aacomic.com www.artstation.com www.buka.cn www.cartoonmad.com www.chuixue.com www.chuixue.net www.cocomanhua.com www.colamanga.com www.comicabc.com www.comicvip.com www.dm5.com www.dmzj.com www.facebook.com www.flickr.com www.gufengmh.com www.gufengmh8.com www.hhcomic.cc www.hheess.com www.hhmmoo.com www.hhssee.com www.hhxiee.com www.iibq.com www.instagram.com www.mangacopy.com www.manhuadui.com www.manhuaren.com www.mh160.com www.mhgui.com www.ohmanhua.com www.pixiv.net www.sankakucomplex.com www.setnmh.com www.tohomh.com www.tohomh123.com www.xznj120.com x.com yande.re
使用說明
As a CLI tool:
Usage:
comiccrawler [--profile=<profile>] (
domains |
download <url> [--dest=<save_path>] |
gui
)
comiccrawler (--help | --version)
Commands:
domains 列出支援的網址
download 下載指定的 url
gui 啟動主視窗
Options:
--profile 指定設定檔存放的資料夾(預設為 "~/comiccrawler")
--dest 設定下載目錄(預設為 ".")
--help 顯示幫助訊息
--version 顯示版本
or you can use it in your python script:
from comiccrawler.mission import Mission
from comiccrawler.analyzer import Analyzer
from comiccrawler.crawler import download
# create a mission
m = Mission(url="http://example.com")
Analyzer(m).analyze()
# select the episodes you want
for ep in m.episodes:
if ep.title != "chapter 123":
ep.skip = True
# download to savepath
download(m, "path/to/save")圖形介面
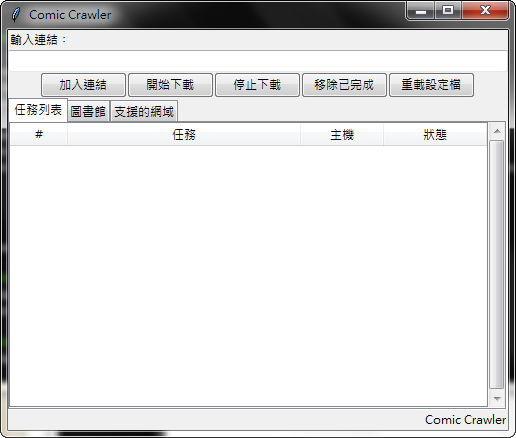
在文字欄貼上網址後點「加入連結」或是按 Enter
若是剪貼簿裡有支援的網址,且文字欄同時是空的,程式會自動貼上
對著任務右鍵,可以選擇把任務加入圖書館。圖書館內的任務,在每次程式啟動時,都會檢查是否有更新。
設定檔
[DEFAULT]
; 設定下載完成後要執行的程式,{target} 會被替換成任務資料夾的絕對路徑
runafterdownload = 7z a "{target}.zip" "{target}"
; 啟動時自動檢查圖書館更新
libraryautocheck = true
; 檢查更新間隔(單位︰小時)
autocheck_interval = 24
; 下載目的資料夾。相對路徑會根據設定檔資料夾的位置。
savepath = download
; 開啟 grabber 偵錯
errorlog = false
; 每隔 5 分鐘自動存檔
autosave = 5
; 存檔時使用下載時的原始檔名而不用頁碼
; 強列建議不要使用這個選項,見 https://github.com/eight04/ComicCrawler/issues/90
originalfilename = false
; 自動轉換集數名稱中數字的格式,可以用於補0
; 例︰第1集 -> 第001集
; 詳細的格式指定方式請參考 https://docs.python.org/3/library/string.html#format-specification-mini-language
; 注意︰這個設定會影響檔名中的所有數字,包括檔名中英數混合的ID如instagram
titlenumberformat = {:03d}
; 連線時使用 http/https proxy
proxy = 127.0.0.1:1080
; 加入新任務時,預設選擇所有集數
selectall = true
; 不要根據各集名稱建立子資料夾,將所有圖片放在任務資料夾內
noepfolder = true
; 遇到重複任務時的動作
; update: 檢查更新
; reselect_episodes: 重新選取集數
mission_conflict_action = update
; 是否驗證加密連線(SSL),預設是 true
verify = false
; 從瀏覽器中讀取 cookies,使用 yt-dlp 的 cookies-from-browser
; https://github.com/yt-dlp/yt-dlp/blob/e5d4f11104ce7ea1717a90eea82c0f7d230ea5d5/yt_dlp/cookies.py#L109
browser = firefox
; 瀏覽器 profile 的名稱
browser_profile = act3nn7e.default
; 並行下載的任務數量。注意︰你無法並行下載單一網站的多個任務,所以這個數字只對多個不同網站的任務有效
max_threads = 3設定檔位於 ~\comiccrawler\setting.ini。可以在執行時指定 --profile 選項以變更預設的位置。(在 Windows 中 ~ 會被展開為 %HOME% 或 %USERPROFILE%)
執行一次 comiccrawler gui 後關閉,設定檔會自動產生。若 Comic Crawler 更新後有新增的設定,在關閉後會自動將新設定加入設定檔。
各別的網站會有自己的設定,通常是要填入一些登入相關資訊
以 curl 開頭的設定,要填入對應網址的 curl 指令。以 twitter 為例︰https://github.com/eight04/ComicCrawler/issues/241#issuecomment-904411605
以 cookie 開頭的設定,要填入對應的 cookie。
設定檔會在重新啟動後生效。若 ComicCrawler 正在執行中,可以點「重載設定檔」來載入新設定
各別網站的設定不會互相影響。假如在 [DEFAULT] 設 savepath = a;在 [Pixiv] 設 savepath = b,那麼從 pixiv 下載的都會存到 b 資料夾,其它的就用預設值,存到 a 資料夾。
關於需要登入的網站
只要在設定檔裡指定 browser 和 browser_profile ,Comic Crawler 就可以自動從瀏覽器讀取 cookies 並登入。然而最新版的 Chrome 加強了對 Cookie 的保護︰
所以目前只有 Firefox 可以正常運作。
有些網站可以在設定檔裡指定 cookie 或 curl,但這些設定在未來會逐步淘汰,改用瀏覽器 cookie 自動登入。
Module example
Starting from version 2016.4.21, you can add your own module to ~/comiccrawler/mods/module_name.py.
#! python3
"""
This is an example to show how to write a comiccrawler module.
"""
import re
from urllib.parse import urljoin
from comiccrawler.episode import Episode
# The header used in grabber method. Optional.
header = {}
# The cookies. Optional.
cookie = {}
# Match domain. Support sub-domain, which means "example.com" will match
# "*.example.com"
domain = ["www.example.com", "comic.example.com"]
# Module name
name = "Example"
# With noepfolder = True, Comic Crawler won't generate subfolder for each
# episode. Optional, default to False.
noepfolder = False
# If False then setup the referer header automatically to mimic browser behavior.
# If True then disable this behavior.
# Default: False
no_referer = True
# Wait 5 seconds before downloading another image. Optional, default to 0.
rest = 5
# Wait 5 seconds before analyzing the next page in the analyzer. Optional,
# default to 0.
rest_analyze = 5
# User settings which could be modified from setting.ini. The keys are
# case-sensitive.
#
# After loading the module, the config dictionary would be converted into
# a ConfigParser section data object so you can e.g. call
# config.getboolean("use_large_image") directly.
#
# Optional.
config = {
# The config value can only be str
"use_largest_image": "true",
# These special config starting with `cookie__` will be automatically
# used when grabbing html or image.
"cookie_user": "user-default-value",
"cookie_hash": "hash-default-value"
}
def load_config():
"""This function will be called each time the config reloads. Optional.
"""
pass
def get_title(html, url):
"""Return mission title.
The title would be used in saving filepath, so be sure to avoid
duplicated title.
"""
return re.search("<h1 id='title'>(.+?)</h1>", html).group(1)
def get_episodes(html, url):
"""Return episode list.
The episode list should be sorted by date, oldest first.
If is a multi-page list, specify the URL of the next page in
get_next_page. Comic Crawler would grab the next page and call this
function again.
The `Episode` object accepts an `image` property which can be a list of `Image`.
However, unlike `get_images`, the `Episode` object is JSON-stringified and saved
to the disk, therefore you must only use JSON-compatible types i.e. no `Image.get_url`.
"""
match_list = re.findall("<a href='(.+?)'>(.+?)</a>", html)
return [Episode(title, urljoin(url, ep_url))
for ep_url, title in match_list]
def get_images(html, url):
"""Get the URL of all images.
The return value could be:
- A list of image.
- A generator yielding image.
- An image, when there is only one image on the current page.
Comic Crawler treats following types as an image:
- str - the URL of the image
- callable - return a URL when called
- comiccrawler.core.Image - use it to provide customized filename.
While receiving the value, it is converted to an Image instance. See ``comiccrawler.core.Image.create()``.
If the episode has multi-pages, uses get_next_page to change page.
Use generator in caution! If the generator raises any error between
two images, next call to the generator will always result in
StopIteration, which means that Comic Crawler will think it had crawled
all images and navigate to next page. If you have to call grabhtml()
for each image (i.e. it may raise HTTPError), use a list of
callback instead!
"""
return re.findall("<img src='(.+?)'>", html)
def get_next_page(html, url):
"""Return the URL of the next page."""
match = re.search("<a id='nextpage' href='(.+?)'>next</a>", html)
if match:
return match.group(1)
def get_next_image_page(html, url):
"""Return the URL of the next page.
If this method is defined, it will be used by the crawler and ``get_next_page`` would be ignored.
Therefore ``get_next_page`` will only be used by the analyzer.
"""
pass
def redirecthandler(response, crawler):
"""Downloader will call this hook if redirect happens during downloading
an image. Sometimes services redirects users to an unexpected URL. You
can check it here.
"""
if response.url.endswith("404.jpg"):
raise Exception("Something went wrong")
def errorhandler(error, crawler):
"""Downloader will call errorhandler if there is an error happened when
downloading image. Normally you can just ignore this function.
"""
pass
def imagehandler(ext, b):
"""If this function exists, Comic Crawler will call it before writing
the image to disk. This allow the module to modify the image after
the download.
@ext str, file extension, including ".". (e.g. ".jpg")
@b The bytes object of the image.
It should return a (modified_ext, modified_b) tuple.
"""
return (ext, b)
def grabhandler(grab_method, url, **kwargs):
"""Called when the crawler is going to make a web request. Use this hook
to override the default grabber behavior.
@grab_method function, could be ``grabhtml`` or ``grabimg``.
@url str, request URL.
@kwargs other arguments that will be passed to grabber.
By returning ``None``
"""
if "/api/" in URL:
kwargs["headers"] = {"some-api-header": "some-value"}
return grab_method(url, **kwargs)
def after_request(crawler, response):
"""Called after the request is made."""
if response.url.endswith("404.jpg"):
raise Exception("Something went wrong")
def session_key(url):
"""Return a key to identify the session. If the key is the same, the
session would be shared. Otherwise, a new session would be created.
For example, you may want to separate the session between the main site
and the API endpoint.
Return None to pass the URL to next key function.
"""
r = urlparse(url)
if r.path.startswith("/api/"):
return (r.scheme, r.netloc, "api")Todos
Need a better error log system.
Support pool in Sankaku.
Add module.get_episode_id to make the module decide how to compare episodes.
Use HEAD to grab final URL before requesting the image?
Changelog
2025.3.24
Add: max_threads setting.
Add: loop detection in analyzer. Twitter doesn’t work anymore.
Add: support colamanga by @Silverbullet069.
Fix: HTTP 416 results in invalid data.
Fix: error object has no response property.
Fix: imagehandler doesn’t work with temp files @Silverbullet069.
Fix: improve bandwidth limit detection in eh.
Fix: kemono.
Fix: progress bar crashing the application.
2024.12.9
Fix: login check in exh.
2024.12.6
Fix: better login check in exh.
Fix: fullimg in exh.
Change: switch to curl_cffi, fix pixiv and oh.
2024.11.14
Fix: add language tag to seemh.
Fix: eight module.
Fix: sankaku.
Fix: handler 416 content range.
Add: new domain in kemono.
Add: try smaller images when 404 on twitter.
2024.8.14
Add: extract file extension from URL.
Fix: 404 error in dm5.
2024.8.9
Add: jpg4 module.
Fix: domain changed to x.com in twitter.
Fix: failed locating popular posts in sankaku.
Fix: handle empty thumbnail in fantia.
Fix: skip posts without files in fanbox.
Fix: stop detecting zip as docx.
Fix: wrong image URL in bilibili manga.
2024.4.11
Fix: redirect error in sankaku.
2024.4.10
Fix: limit retry delay to 10 minutes at most.
Fix: failed handling http 206 response.
Fix: username may conatain dash in fanbox.
Add: max_errors setting.
Add: ability to run multiple crawlers. One for each host.
2024.4.2
Fix: wrong protocol in seemh.
Fix: failed downloading webp images.
2024.3.25
Fix: skip episodes without images in kemono.
Fix: sankaku.
Fix: some posts are missing in twitter.
Add: new domain kemono.su.
Add: .clip to valid file extensions.
Add: ability to write partial data to disk.
Add: browser and browser_profile settings which are used to extract cookies.
Add: after_request, session_key hooks.
Add: session_manager for better control of api sessions.
Change: set referer and origin header in analyzer.
Change: wait 3 seconds after analyze error.
2024.1.4
Fix: vm error in seemh.
Change: drop imghdr.
2023.12.24
Fix: bili, cartoonmad, seemh module.
Fix: support python 3.12.
2023.12.11
Fix: seemh, twitter modules.
Add: fanbox module.
2023.10.11
Fix: instagram, fantia, seemh, sanka modules.
Add: progress bar.
Change: switch to deno_vm.
2023.10.8
Fix: unable to download bili free chapters.
Fix: facebook module.
Add: copymanga new domain.
Add: kemono module.
Add: linevoom module.
Add: support more audio formats.
Add: new plugin hook get_next_image_page.
2022.11.21
Fix: switching pages error in 8comic.
Fix: use url path to guess extension.
Add: allow to download txt file.
2022.11.11
Fix: now danbooru requires curl.
Fix: 8comic doesn’t use ajax anymore.
Fix: download error in instagram.
Change: download thumbnail in fantia.
Change: require python 3.10.
2022.2.6
Fix: magic import error.
Add: support replacing argument in runafterdownload.
2022.2.3
Fix: analyze error in seemh.
Add: support fantia.jp
Add: support br encoding.
Add: open episode URL on right-click when selecting episodes.
Add: display completed episodes as green.
Add: exponential backoff.
Change: use curl in sankaku.
Change: skip 404 ep on twitter.
Change: use python-magic to detect file type.
2021.12.2
Fix: empty episodes error.
2021.11.15
Fix: copymanga.
2021.9.15
Fix: ep order is wrong in twitter.
Fix: copymanga.
2021.8.31
Fix: hidden manga in dmzj.
Fix: skip 404 episode in instagram.
Fix: support multiple videos in instagram.
Fix: failed analyzing search page in pixiv.
Fix: empty episode error in gelbooru.
Add: copymanga module.
Add: twitter module.
Add: grabhandler hook.
Change: stop downloading if all available missions fail.
2020.10.29
Fix: cartoonmad error.
Fix: seemh error.
Fix: show all content in gelbooru.
Fix: qq error.
Fix: paging issue in oh.
Fix: deviantart error.
Add: new domain for hhxiee.
Add: new domain for oh.
Change: send referer when fetching html.
2020.9.2
Fix: api is changed in sankaku beta.
Fix: avoid page limit in sankaku.
Fix: cannot get title in weibo.
Fix: cannot fetch nico image.
Fix: duplicated pic in nijie.
Fix: cannot fetch image in seemh.
Add: oh module.
Add: setnmh module.
Add: manhuabei module.
Add: module constant no_referer.
Breaking: require Python@3.6+
2020.6.3
Fix: don’t navigate to next page in danbooru.
Fix: analyzation error in eight.
Fix: instagram now requires login.
Add: a verify option to disable security check.
2019.12.25
Add: support search page in pixiv.
2019.11.19
Fix: handle LastPageError in get_episodes.
Fix: download error in nijie.
Fix: refetch size info if the size is unavailable in flickr.
Fix: skip unavailable episodes in pixiv.
Fix: handle filename with broken extension (jpg@YYYY-mm-dd).
Add: instagram.
Add: sankaku_beta.
Add: redirecthandler hook.
Add: contextmenu to delete missions from both managers.
Change: decrease max retry from 10 to 3 so a broken mission will fail faster.
2019.11.12
Fix: pixiv.
Add: allow get_images to raise SkipPageError.
2019.10.28
Fix: download too many images in danbooru.
2019.10.19
Add: manga.bilibili module.
2019.9.2
Add: bilibili module.
Add: 177pic module.
2019.8.19
Fix: can’t change page in danbooru.
Fix: failed to analyze episodes in pixiv.
Fix: download error in qq.
Bump dependencies.
2019.7.1
Add: autocheck_interval option.
Add: manhuadui module.
Fix: chuixue module.
Fix: handle 404 errors in pixiv.
2019.5.20
Fix: ignore empty episodes in youhui.
2019.5.3
Fix: can’t analyze profile URL with tags in pixiv.
Add: pixabay module.
2019.3.27
Fix: getcookie is not defined in eight.
2019.3.26
Add: manhuaren module.
Fix: failed to switch page in fb.
2019.3.18
Fix: handle 403 error in artstation.
2019.3.13
Add: new domain gufengmh8.com for gufeng module.
Add: new domain tohomh123.com for toho module
Add: new cookie igneous for exh module.
Fix: download images in cartoonmad.
Change: drop ck101 module.
2018.12.25
Add: new domain hheess.com for hhcomic module.
Add: new domain 36rm.cn for xznj module.
Add: toho module.
Fix: support new layout in dm5.
2018.11.18
Add: mission_conflict_action option.
Fix: failed to download images in qq.
Fix: failed to download images in youhui.
2018.10.24
Fix: new domain hhmmoo.com for hhxiee.
Fix: ignore comments when analyzing episodes.
2018.9.30
Change: prefix ep title with group name in seemh.
2018.9.24
Add: support user’s tag in pixiv.
2018.9.23
Fix: failed to get episodes in pixiv.
Fix: on_success is executed when analyzation failed.
Fix: make 503 error retryable.
2018.9.11
Fix: failed to get next page in gelbooru.
Add: gufeng module.
2018.9.7
Fix: domains of eight module.
Fix: batch analyze error is not shown.
Fix: connection error would crash the entire application.
2018.8.20
Add: new option “noepfolder”.
2018.8.11
Fix: title and image URLs in eight.
2018.8.10
Add: mh160 module.
Add: youhui module.
Add: grabber_cooldown module constant.
Add: domain hk.dm5.com in dm5.
Add: travis.
Fix: skip 404 pages in weibo.
Fix: guess the file extension from the content then from the header.
Change: use a newer user agent.
2018.7.18
Add: new domain in xznj120.
Fix: get_episodes returns empty list in deviantart.
2018.6.21
Add: make table sortable.
Add: last_update attribute.
Fix: analyze error in senmanga.
2018.6.14
Revert: do not normalize whitespaces.
Fix: escape more characters in safefilepath.
2018.6.8
Refactor: comiccrawler.core is exploded.
Fix: new interface in pixiv.
Add: “Check update” command in the library contextmenu.
Add: rest_analyze constant in modules.
Drop: migrate command.
2018.5.24
Fix: fail to get images from xznj.
Refactor: split out select_episodes.
2018.5.13
Add: selectall option.
Fix: the column check button operates on a wrong range.
Fix: the column check button appearance.
Fix: download error in tumblr.
2018.5.5
Add: range reverse.
Add: xznj120 module.
Add: gelbooru module.
Fix: cannot analyze episode list in md5.
2018.4.16
Add: support user page. (weibo)
Change: remove raise_429 arg in grabhtml. Add retry.
2018.4.8
Add: allow users to login. (tumblr)
Add: support videos. (tumblr)
2018.3.18
Fix: SMH is not defined error. (seemh) (#106)
2018.3.15
Change: use chapter id in the title of the episode. (qq) (#104)
2018.3.9
Fix: seemh start using https. (#103)
Add: qq module. (#102)
2018.3.7
Fix: get_episodes error in buka. Note that buka currently only shows images to its own reader app.
Fix: can’t download image in seemh (manhuagui).
Add: SkipPageError for get_episodes.
Add: artstation module.
Update pylint to 1.8.2.
2018.1.30.2
Fix: update seemh.
2018.1.30.1
Fix: get Content-Length error.
2018.1.30
Fix: verify Content-Length.
Fix: dm5 update.
2017.12.15
Fix: incorrect title in pixiv.
2017.12.14
Fix: insecure_http option in tumblr doesn’t work properly.
2017.12.9
Add: full_size, insecure_http options to tumblr.
Add: Support .ugoira file in pixiv.
2017.12.4
2017.11.29
2017.9.9
Fix: image match pattern in cartoonmad.
2017.9.5
Fix: url is not unescaped correctly in sankaku.
2017.8.31
Fix: match nview.js in comicbus.
Fix: ikanman.com -> manhuagui.com.
Fix: require login in facebook.
2017.8.26
Fix: html changed in pixiv.
2017.8.20.1
Fix: can’t download in comicbus.
2017.8.20
Fix: can’t match http in deviantart.
Fix: can’t get images in eight.
Add setting proxy.
2017.8.16
Fix: deviantart login issue.
2017.8.13
Fix: sankaku login issue. #66
2017.6.14
Fix: comicbus analzye issue.
2017.5.29
Fix: 99 module. #63
2017.5.26
Fix: ikanman analyze issue.
2017.5.22
Fix: comicbus analyze issue. #62
2017.5.19
2017.5.5
Fix: use raw <title> as title in search result (pixiv).
Add .wmv, .mov, and .psd into valid file extensions.
2017.4.26
Change: use table view in dm5. #54
Fix: runafterdownload is parsed incorrectly on windows.
2017.4.24
Fix: starred expression inside list.
2017.4.23
Fix: compat with python 3.4, starred expression can only occur inside function call.
Update node_vm2 to 0.3.0.
2017.4.22
Add .bmp to valid file extensions.
Fix: unable to check update for multi-page sites.
2017.4.18
Add senmanga. #49
Add yoedge. #47
Fix: header parser issue. See https://www.ptt.cc/bbs/Python/M.1492438624.A.BBC.html
Fix: escape trailing dots in file path. #46
Add: double-click to launch explorer.
Add: batch analyze panel. #45
2017.4.6
Fix: run after download doesn’t work properly if path contains spaces.
Fix: VMError with ugoku in pixiv.
Fix: automatic update check doesn’t record update time when failing.
2017.4.3
Fix: analyze error in dA.
Fix: subdomain changed in exh.
Fix: vm error in hh.
Add .url utils, .core.CycleList, .error.HTTPError.
Add aacomic.
Update pyxcute to 0.4.1.
2017.3.26
Fix: cleanup the old files.
Update pythreadworker to 0.8.0.
2017.3.25
Switch to node_vm2, drop pyexecjs.
Add login check in exh.
Switch to pylint, drop pyflakes.
Drop module manhuadao.
Update pyxcute.
Refactor.
2017.3.9
Add –profile option. #36
2017.3.6
Update seemh. #35
Escape title in pixiv.
Strip non-printable characters in safefilepath.
2017.2.5
2017.1.10
Add: nowebp option in ikanman. #31
Add weibo module.
Add tuchong module.
Fix: update table safe_tk error.
Change: existence check will only check original filename when originalfilename option is true.
2017.1.6
2017.1.3.1
Fix: schema error (konachan).
Fix: original filename should be extracted from final url instead of request url.
Add: now the module can specify image filename with comiccrawler.core.Image.
2017.1.3
Fix: original option doesn’t work (exh).
2016.12.20
Change how config works. This will affect the sites requiring cookie information.
Comic Crawler can save cookie back to config now!
Change how safefilepath works. Use escape table.
Make io.move support folders.
Add io.exists.
Add migrate command.
Add originalfilename option.
2016.12.6
Fix: imghdr can’t reconize .webp in Python 3.4.
2016.12.1
Fix: analyze error in wix.
Fix: mimetypes.guess_extension is not reliable with application/octet-stream
Add .webp to valid file type.
2016.11.27
Fix hhxiee module. Use new domain www.hhssee.com.
2016.11.25
Support cartoonmad.
2016.11.2
Fix: scaling issue on Windows XP.
Fix: login-check in deviantart.
Use desktop3 to open folder. #16
Fix: GUI crahsed if scaling < 1.
2016.10.8
Fix: math.inf is only available in python 3.5.
2016.10.4
Fix: can not download video in flickr.
Fix: use cookie in grabimg.
2016.9.30
Add params option to grabber.
Add flickr module.
2016.9.27
Fix: image pattern in buka.
Fix: add hhcomic domain.
2016.9.11
Fix: failed to read file encoded with utf-8-sig.
Fix: ignore empty posts in tumblr.
2016.8.24.1
Use better method to find next page in tumblr.
Fix unicode referer bug in grabber.
Update match pattern to avoid redirect in tumblr. See https://github.com/kennethreitz/requests/issues/3078.
Fix get_title error in tumblr that the title might be empty.
2016.8.24
Fix 429 error still raised by analyze_info.
Fix next page pattern in tumblr.
2016.8.22
Support hhxiee.
Fix get_episodes error in ck101.
Suppress 429 error when analyzing.
Change title format in yendere. Support pools.
2016.8.19
Fix title not found error in dm5.
2016.8.8
Use a safer method in write_file.
Add mission_lock for thread safe.
Use str as runafterdownload.
Use float as autosave.
Add debug log.
Rewrite analyzer. Episodes shouldn’t have same title.
2016.7.2
Fix context menu popup bug on linux.
Fix update checking stops after finished mission.
2016.7.1
Use cross-platform startfile (incomplete).
Use clam theme for GUI under linux.
Fix the error message of update checking failure.
Update checking won’t block GUI thread anymore.
Update pythreadworker to 0.6.
Fix import syntax in gui.get_scale.
2016.6.30
Support high dpi displays.
Don’t show error in library thread. Only warn the user when update checking fails.
2016.6.25
API changed. Now the errorhandler will recieve (error, crawler) instead of (error, episode).
Add errorhandler in seemh. It will try to use different host if downloading failed.
Drop mission to the bottom when update checking failed. Update checking process will stop if it had retried 10 times.
2016.6.14.1
Pass pyflakes and fix a bunch of typo.
2016.6.14
Fix: always re-init in crawlpage loop!
2016.6.12
Use GBK instead of GB2312 in grabber.
Add the ability to get title from non-user page in nico.
Fix: unable to add mission in chuixue.
Fix: unable to download image in nico.
Fix: episode is lost after changing the name of the mission.
Fix: unable to recheck update after login error.
2016.6.10
Change how to handle HTTP 429 error. Let the mission drop.
Add login check in sankaku.
Support .jpe(.jpg), .webm file types.
2016.6.4
Change how saved data works. Comic Crawler will write inactive mission data into ~/comiccrawler/pool/ folder to save the memory.
Fix regex in dA.
Fix sankaku’s hang. Do not suppress 429 error in grabber.
2016.6.3
Minor change to save/load file function to avoid unnecessary copy.
Comic Crawler will now execute runafterdownload command both from the default section and the module section.
2016.5.30
Add module.imagehandler, which can edit the image file before saving to disk.
Write frame info into ugoku zip in pixiv.
2016.5.28
Change how config work. Now you can specify different setting in each sections. (e.g. use different savepath with different module)
Save frame info about ugoku in pixiv.
Drop config.update in module.load_config.
Try to support additional info in get_images.
2016.5.24
Support buka.
2016.5.20
Find server by executing js in seemh.
2016.5.15
Fix dependency scheme.
2016.5.2
Use Conten-Type header to guess file extension.
Fix a bug that the thread is not removed when recived DOWNLOAD_INVALID.
Pause download when meeting 509 error in exh.
Add .mp4 to valid file types.
2016.5.1.1
Fix a bug that Comic Crawler doesn’t retry when the first connection failed.
Add Episode.image, so the module can supply image list during constructing Episode.
2016.5.1
Support wix.com.
2016.4.27
Domain changed in seemh.
2016.4.26.1
Fix charset encoding bug.
2016.4.26
Fix config bug with upper-case key.
Check urls of old episodes to avoid unnecessary analyzing.
Add option to get original image in exh. It will cost 5x of viewing limit.
2016.4.22.3
Fix retry-after hanged bug.
Fix cnfig override bug. Use ComicCrawler section to replace DEFAULT section.
Support account login in sankaku.
Support HTTP error log before raising.
Show next page url while analyzing.
2016.4.22.2
Move to pythreadworker 0.5.0
2016.4.22.1
Support loading module in python3.4.
2016.4.22
Fix setup.py. Use find_packages.
2016.4.21
Big rewrite.
Move to requests.
Move to pythreadworker 0.4.0.
Add the ability to load module from ~/comiccrawler/mods
Drop migrate command.
2016.4.20
Update install_requires.
2016.4.13
Fix facebook bug.
Move to doit.
2016.4.8
Fix get_next_page error.
Fix key error in CLI.
2016.4.4
Use new API!
Analyzer will check the last episode to decide whether to analyze all pages.
Support multiple images in one page.
Change how getimgurl and getimgurls work.
2016.4.2
Add tumblr module.
Enhance: support sub-domain in mods.get_module.
2016.3.27
Fix: handle deleted post (konachan).
Fix: enhance dialog. try to fix #8.
2016.2.29
Fix: use latest comicview.js (8comic).
2016.2.27
Fix: lastcheckupdate doesn’t work.
Add: comicbus domain (8comic).
2016.2.15.1
Fix: can not add mission.
2016.2.15
Add lastcheckupdate setting. Now the library will only automatically check updates once a day.
Refactor. Use MissionProxy, Mission doesn’t inherit UserWorker anymore.
2016.1.26
Change: checking updates won’t affect mission which is downloading.
Fix: page won’t skip if the savepath contains “~”.
Add: a new url pattern in facebook.
2016.1.17
Fix: an url matching issue in Facebook.
Enhance: downloader will loop through other episodes rather than stop current mission on crawlpage error.
2016.1.15
Fix: ComicCrawler doesn’t save session during downloading.
2016.1.13
Handle HTTPError 429.
2016.1.12
Add facebook module.
Add circular option in module. Which should be set to True if downloader doesn’t know which is the last page of the album. (e.g. Facebook)
2016.1.3
Fix downloading failed in seemh.
2015.12.9
Fix build-time dependencies.
2015.11.8
Fix next page issue in danbooru.
2015.10.25
Support nico seiga.
Try to fix MemoryError when writing files.
2015.10.9
Fix unicode range error in gui. See http://is.gd/F6JfjD
2015.10.8
Fix an error that unable to skip episode in pixiv module.
2015.10.7
Fix errors that unable to create folder if title contains “{}” characters.
2015.10.6
Support search page in pixiv module.
2015.9.29
Support http://www.chuixue.com.
2015.8.7
Fixed sfacg bug.
2015.7.31
Fixed: libraryautocheck option does not work.
2015.7.23
Add module dmzj_m. Some expunged manga may be accessed from mobile page. http://manhua.dmzj.com/name => http://m.dmzj.com/info/name.html
2015.7.22
Fix bug in module eight.
2015.7.17
Fix episode selecting bug.
2015.7.16
Added:
Cleanup unused missions after session loads.
Handle ajax episode list in seemh.
Show an error if no update to download when clicking “download updates”.
Show an error if failing to load session.
Changed:
Always use “UPDATE” state if the mission is not complete after re-analyzing.
Create backup if failing to load session instead of moving them to “invalid-save” folder.
Check edit flag in MissionManager.save().
Fixed:
Can not download “updated” mission.
Update checking will stop on error.
Sankaku module is still using old method to create Episode.
2015.7.15
Add module seemh.
2015.7.14
Refactor: pull out download_manager, mission_manager.
Enhance content_write: use os.replace.
Fix mission_manager save loop interval.
2015.7.7
Fix danbooru bug.
Fix dmzj bug.
2015.7.6
Fix getepisodes regex in exh.
2015.7.5
Add error handler to dm5.
Add error handler to acgn.
2015.7.4
Support imgbox.
2015.6.22
Support tsundora.
2015.6.18
Fix url quoting issue.
2015.6.14
Enhance safeprint. Use echo command.
Enhance content_write. Add append=False option.
Enhance Crawler. Cache imgurl.
Enhance grabber. Add cookie=None option. Change errorlog behavior.
Fix grabber unicode encoding issue.
Some module update.
2015.6.13
Fix clean_finished
Fix console_download
Enhance get_by_state
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file comiccrawler-2025.3.24.tar.gz.
File metadata
- Download URL: comiccrawler-2025.3.24.tar.gz
- Upload date:
- Size: 114.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
66af40324c082c3f8a845ff89878c06fe8daea1299f6d7fe5c63d34652565263
|
|
| MD5 |
63074c7f1e60a05472c4fc435e5715b4
|
|
| BLAKE2b-256 |
6912681ebf6239a9a90284672a76ca70e1aca8d85fbfcf3ace98cbf5bb83195d
|
File details
Details for the file comiccrawler-2025.3.24-py3-none-any.whl.
File metadata
- Download URL: comiccrawler-2025.3.24-py3-none-any.whl
- Upload date:
- Size: 122.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25fdb81e8e1ac5d56df2d3827ddb92072477a82586c88669b0cef85fb96e1140
|
|
| MD5 |
4e334000ee405b1d4f78ec9915575383
|
|
| BLAKE2b-256 |
a843dfefad5838c428148ffe3dc1d890f2d847336cc62fbc5dc290529fb41d79
|







