compressio


Project description

Compressio
Compressio provides lossless in-memory compression of pandas DataFrames and Series powered by the visions type system. Use up to 10x less RAM with the same data!
Getting started is as easy as
from compressio import Compress
compress = Compress()
compressed_data = compress.it(data)
The Framework
Compressio is a general framework for automated data compression and representation management not limited to any specific compression algorithm or implementation. You have complete control, define your own types, write your own compression algorithms, or get started with the large library of types provided by visions and the suite of powerful algorithms included in compressio by default.
These algorithms can be subdivided around three basic optimization strategies:
- Prefer smaller dtypes where possible without loss of information
- Consider (more efficient) data representations*
- Compress data using more efficient data structures
* this is where things get messy without visions
1. Smaller dtypes
Under the hood, pandas leverages numpy arrays to store data.
Each numpy array has an associated dtype specifying a physical, on disk, representation of the data.
For instance, a sequence of integers might be stored as 64-bit integers (int64), 8-bit unsigned integers (uint8) or even 32-bit floating point number (float32).
An overview of the numpy type system can be found here.
These type differences have numerous computational implications, for example, where an 8 bit integer can represent numbers between 0 and 255, the range of a 64 bit integer is between -9,223,372,036,854,775,808 and 9,223,372,036,854,775,807 at the cost of an 8x larger memory footprint. There can also be computational performance implications for different sizes.
import numpy as np
array_int_64 = np.ones((1000, 1000), dtype=np.int64)
print(array_int_64.nbytes)
8000000
array_int_8 = np.ones((1000, 1000), dtype=np.int8)
print(array_int_8.nbytes)
1000000
As you can see, the 8-bit integer array decreases the memory usage by 87.5%.
2. Appropriate machine representation
Compressio uses visions to infer the semantic type of data and coerce it into alternative computational representations which minimize memory impact while maintaining it's semantic meaning.
For instance, although pandas can use the generic object dtype to store boolean sequences, it comes at the cost of a 4x memory footprint. Visions can automatically handle these circumstances to find an appropriate representation for your data.
>>>> import pandas as pd
>>>> # dtype: object
>>>> series = pd.Series([True, False, None, None, None, None, True, False] * 1000)
>>>> print(series.nbytes)
64000
>>>> # dtype: boolean (pandas' nullable boolean)
>>>> new_series = series.astype("boolean")
>>>> print(new_series.nbytes)
16000
Further background information is available in the visions documentation, github repository and JOSS publication.
3. Efficient data structures
Without additional instructions, pandas represents your data as dense arrays. This is a good all-round choice.
When your data is not randomly distributed, it can be compressed (Theory).
Low cardinality data can often be more efficiently stored using sparse data structures, which are provided by pandas by default. These structures offer efficiency by storing the predominant values only once and instead keeping indices for all other values.
This notebook shows how to use compressio with sparse data structures.
Data structure optimization is not limited to sparse arrays but instead include numerous domain specific opportunities such as run-length encoding (RLE) which can be applied to compress sequential data. We note that a pandas-specific third-party implementation is currently under development: RLEArray.
Usage
Installation
You can easily install compressio with pip:
pip install compressio
Or, alternatively, install from source.
git clone https://github.com/dylan-profiler/compressio.git
Examples
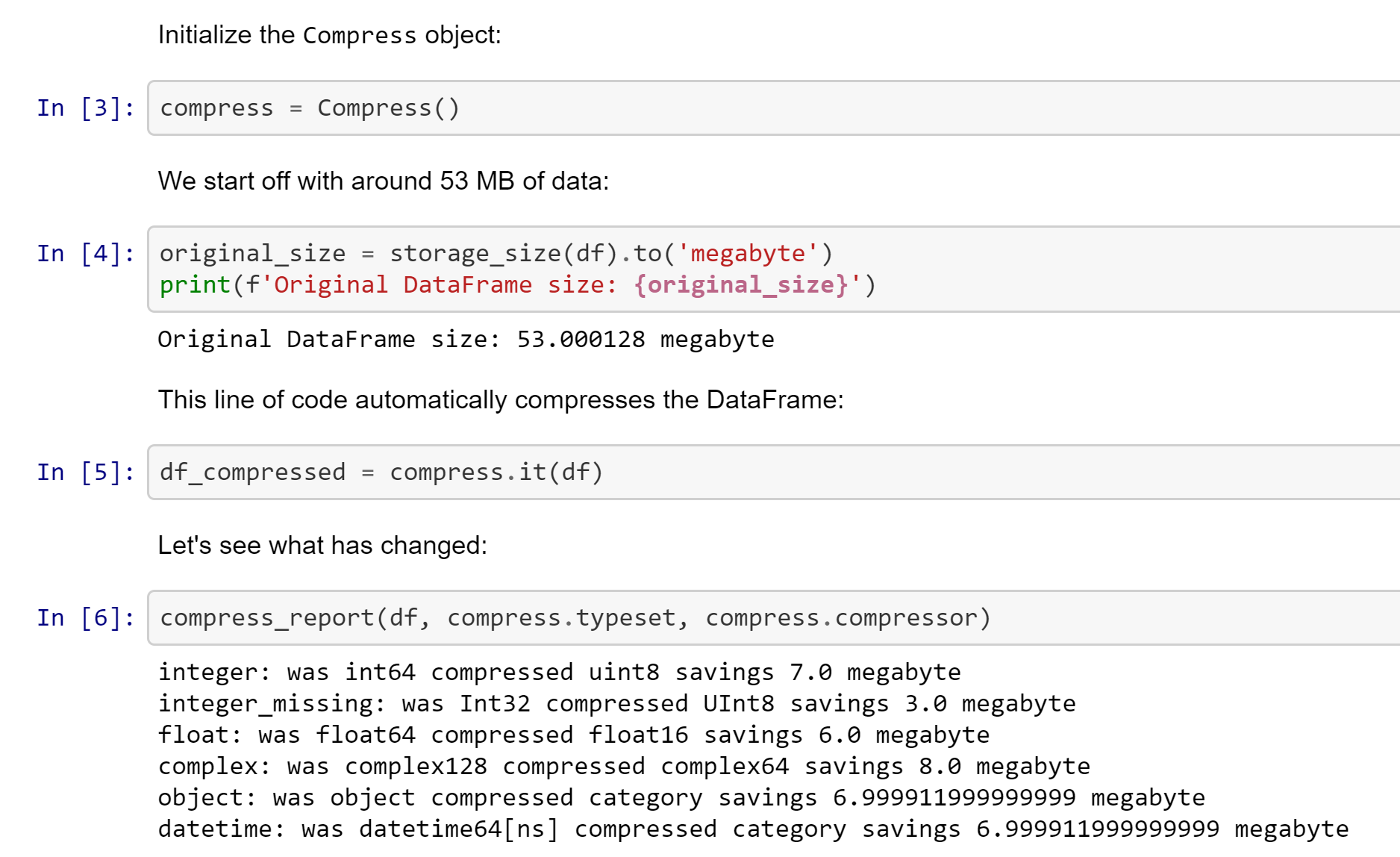
There is a collection of example notebooks to play with in the examples directory with a quick start notebook available here.
Optimizing strings in pandas
Pandas allows for multiple ways of storing strings: as string objects or as pandas.Category. Recent version of pandas have a pandas.String type.
How you store strings in pandas can significantly impact the RAM required.
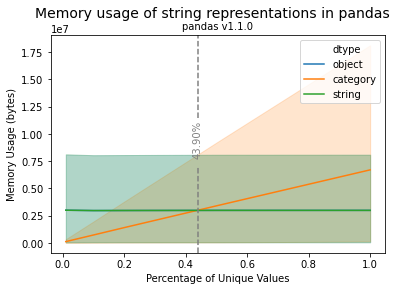
The key insights from this analysis are:
- The Category is more memory efficient when values are recurring and the String representation the percentage of distinct values.
- The size of the Series is not decisive for the string representation choice.
You can find the full analysis here.
Gotcha's
Compressing DataFrames can be helpful in many situations, but not all. Be mindful of how to apply it in the following cases:
-
Overflow: compression by dropping precision can lead to overflows if the array is manipulated afterwards. This can be an issue for instance for numpy integers. In case this is a problem for your application, you can explicitly choose a precision.
-
Compatibility: other libraries may make different decisions to how to handle your compressed data. One example where code needs to be adjusted to the compressed data is when the sparse data structure is used in combination with
.groupby. (observedmust be set toTrue). This article provides another example of scikit-image, which for some functions immediately converts a given array to a float64 dtype.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file compressio-0.1.4.tar.gz.
File metadata
- Download URL: compressio-0.1.4.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.50.2 CPython/3.8.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f174e2b40ccf7c5681de37532d9535e04d296f3ce8a9f836d02d0957490421e
|
|
| MD5 |
72415763e3ba5fb398bedec5f44f3444
|
|
| BLAKE2b-256 |
412be6991b1bb9be16d077459ae73d457701ac1c234542b7cfabadba022f2d43
|
File details
Details for the file compressio-0.1.4-py3-none-any.whl.
File metadata
- Download URL: compressio-0.1.4-py3-none-any.whl
- Upload date:
- Size: 11.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.50.2 CPython/3.8.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c8b5a0b548c21f257e21f5e9a23b04247b7873e15a8dce83177ae157fc79b862
|
|
| MD5 |
fe73f290f75bf3a3071d77d546539b71
|
|
| BLAKE2b-256 |
b70f55ee14a82d2e37c6cebaae1ac1d480949791264b4e9fb9609eb899197b29
|







