CompSil: Composite Silhouette for Cluster-Count Selection
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
CompSil





|
📄 Accepted at ECML PKDD 2026 Composite Silhouette |
CompSil is an open-source Python package for selecting the number of clusters in unlabeled data using Composite Silhouette, an internal validation criterion that adaptively combines micro- and macro-averaged Silhouette scores across repeated subsampled clusterings.
Composite Silhouette: A Subsampling-based Aggregation Strategy
Selecting the number of clusters is a central challenge in unsupervised learning, where ground-truth labels are usually unavailable.
The standard Silhouette coefficient is one of the most widely used internal validation metrics for this task. However, its usual micro-averaged form aggregates Silhouette values over all data points, which can make the score strongly influenced by large clusters. In imbalanced datasets, this may mask poor separation or instability in smaller but meaningful groups.
A natural alternative is macro-averaging, where Silhouette values are first averaged within each cluster and then averaged across clusters. This gives every cluster equal influence, reducing the dominance of majority groups. However, macro-averaging can also overemphasize small, noisy, or under-represented clusters.
The distinction between micro- and macro-averaged Silhouette aggregation is discussed in detail in Revisiting Silhouette Aggregation by Pavlopoulos, Vardakas, and Likas. The corresponding repository is available here: https://github.com/ipavlopoulos/revisiting-silhouette-aggregation.
For users who only need direct Silhouette computation, including sample-level, micro-averaged, and macro-averaged Silhouette scores with or without approximation, see the companion Silhouette package: https://github.com/semoglou/sil_score.
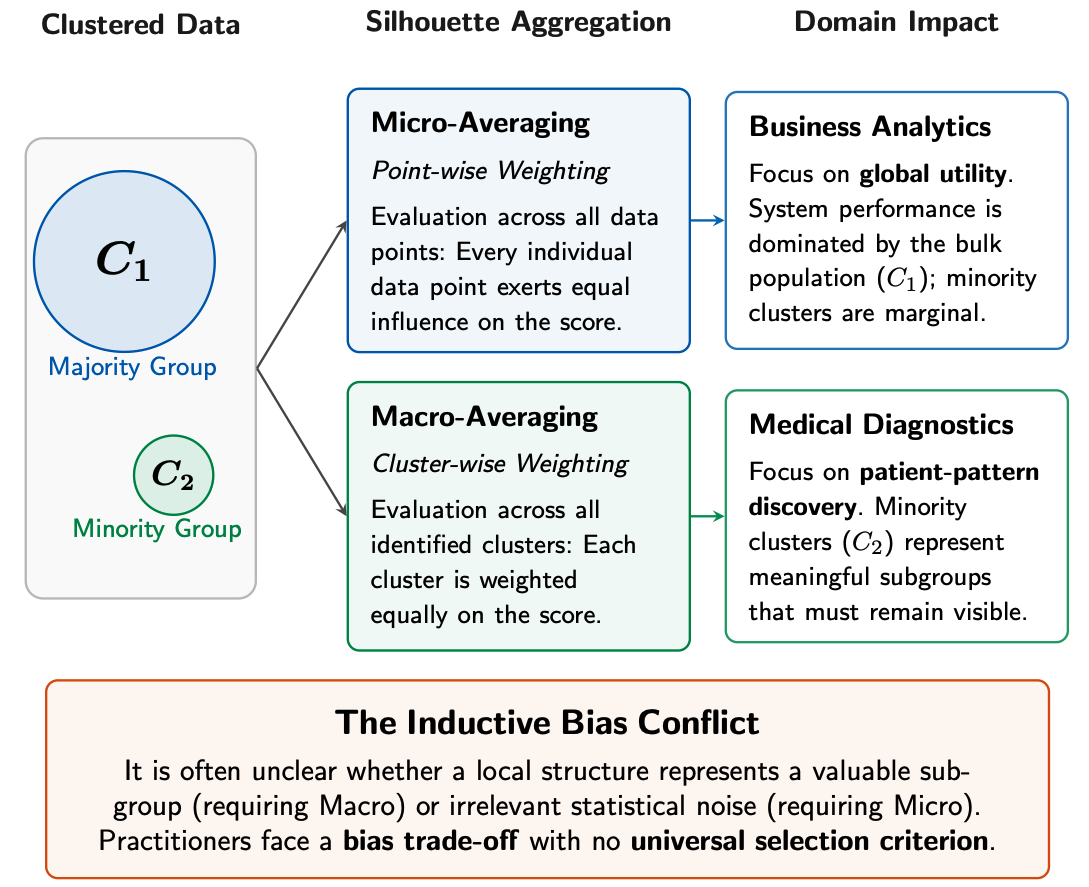
These complementary failure modes create a practical dilemma:
-
Micro-averaging reflects global, point-wise clustering quality but can favor majority clusters.
-
Macro-averaging reflects cluster-wise balance but can overemphasize small or noisy groups.
In many applications, it is unclear in advance which view should be trusted.
CompSil addresses this issue by using the disagreement between micro- and macro-averaged Silhouette scores as a local signal for adaptive aggregation.
Composite Silhouette evaluates candidate numbers of clusters through repeated subsampled clusterings. For each candidate value of k, the method:
-
Draws multiple subsamples of the dataset.
-
Clusters each subsample.
-
Computes both micro- and macro-averaged Silhouette scores.
-
Measures their discrepancy.
-
Converts this discrepancy into a smooth convex weight.
-
Combines the two Silhouette views into a subsample-level composite score.
-
Averages the composite scores across subsamples.
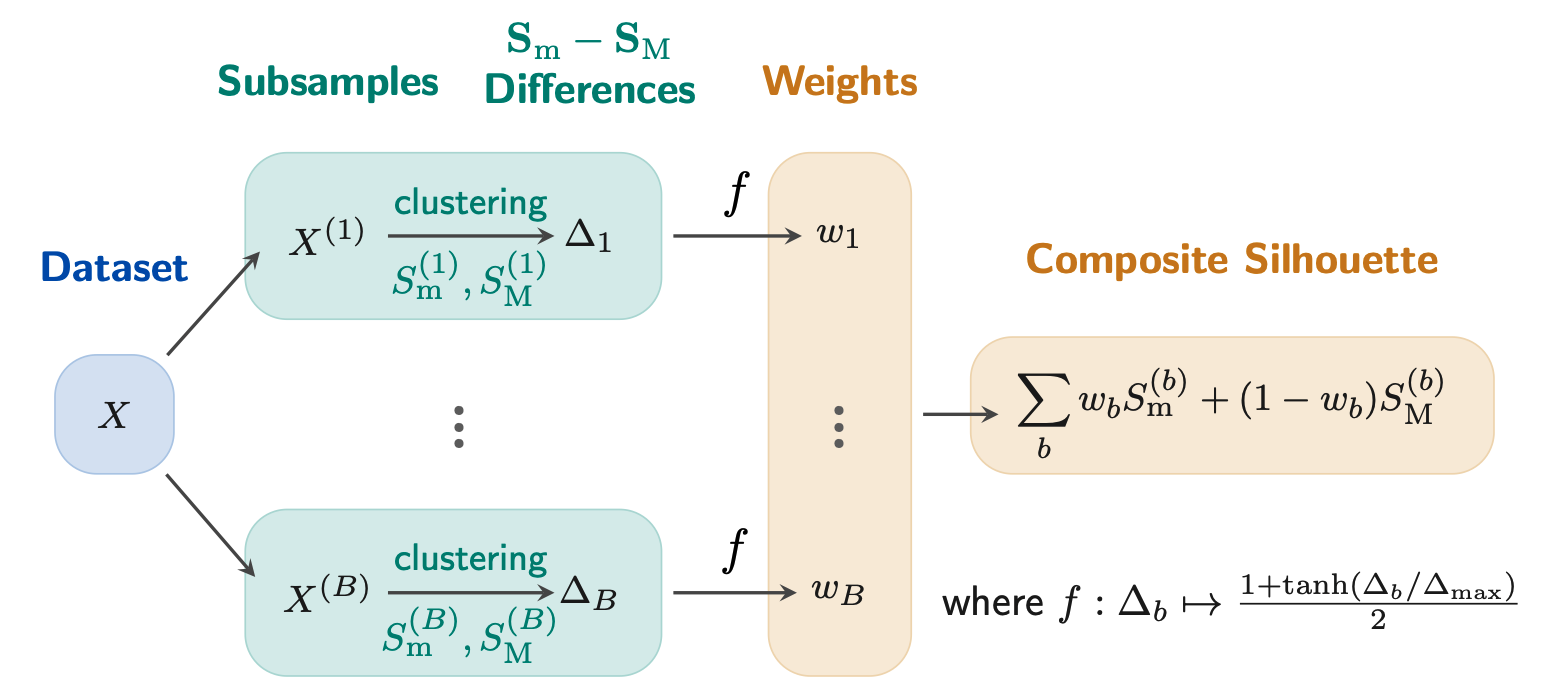
For each subsample, Composite Silhouette combines the two views as:
S_mM = w * S_micro + (1 - w) * S_macro
where the weight w is determined adaptively from the normalized discrepancy between S_micro and S_macro.
This produces a single internal validation score that can be maximized over candidate values of k.
CompSil enables:
-
Selection of the number of clusters without labels.
-
Adaptive balancing of micro- and macro-averaged Silhouette.
-
More robust cluster-count selection under size imbalance.
-
Repeated subsampling for stable internal validation.
-
Optional lower-confidence-bound selection using subsampling variability.
Citation
If you find this work useful, please consider citing:
Semoglou, A., Likas, A., & Pavlopoulos, J. (2026). Composite Silhouette.
Accepted at ECML PKDD 2026.
@inproceedings{semoglou2026composite,
title = {Composite Silhouette},
author = {Semoglou, Aggelos and Likas, Aristidis and Pavlopoulos, John},
booktitle = {Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases},
year = {2026}
}
The preprint is also available on arXiv: https://arxiv.org/abs/2604.13816
Installation
Install CompSil from PyPI:
pip install compsil
Import the main class in Python as:
from compsil import CompSil
API Reference
CompSil provides a simple class-based interface for evaluating Composite Silhouette over one or more candidate numbers of clusters.
CompSil
Computes Composite Silhouette for candidate cluster counts using repeated subsampled clusterings.
CompSil(
data,
ground_truth=None,
k_values=range(2, 11),
num_samples=10,
sample_size="auto",
random_state=42,
n_jobs=-1,
eps=1e-12,
)
Inputs
-
data: array-like of shape(n_samples, n_features)
Input data matrix. -
ground_truth: int or None, defaultNone
Optional reference number of clusters.
Used only for visualization. -
k_values: iterable of int or int, defaultrange(2, 11)
Candidate number or candidate numbers of clusters to evaluate. -
num_samples: int, default10
Number of subsamples used for each candidate value ofk. -
sample_size: int, float, None, or"auto", default"auto"
Subsample size used in each repeated clustering.- If
int, it is interpreted as the absolute subsample size. - If
floatin(0, 1], it is interpreted as a fraction of the dataset size. - If
Noneor"auto", the subsample size is selected automatically from the dataset size and the largest candidate value ofk.
- If
-
random_state: int, default42
Base random seed used for reproducible subsampling and clustering. -
n_jobs: int, default-1
Number of parallel jobs used during evaluation. -
eps: float, default1e-12
Numerical stability constant used when normalizing micro–macro discrepancies.
evaluate
Evaluates Composite Silhouette over all candidate values of k.
model.evaluate()
After calling evaluate, the results are stored in:
model.results_df
The results table contains:
k: candidate number of clusters.avg S_micro: average micro-averaged Silhouette across subsamples.avg S_macro: average macro-averaged Silhouette across subsamples.w_micro: average adaptive weight assigned to the micro view.S_mM: Composite Silhouette score.std S_mM: standard deviation of subsample-level composite scores.se S_mM: standard error of the Composite Silhouette estimate.LCB S_mM: lower-confidence-bound score, computed asS_mM - se S_mM.B_eff: number of valid subsampling trials.sample_size: resolved subsample size.sample_fraction: resolved subsample fraction.
get_optimal_k
Returns the selected number of clusters.
model.get_optimal_k(use_lcb=False)
Inputs
use_lcb: bool, defaultFalse
IfFalse, selects thekthat maximizesS_mM.
IfTrue, selects thekthat maximizesLCB S_mM.
Returns
optimal_k: int
Selected number of clusters.
get_results_dataframe
Returns the results as a pandas DataFrame indexed by k.
results = model.get_results_dataframe()
Returns
results: pandas DataFrame
Table containing the Composite Silhouette results for all candidate values ofk.
plot_results
Plots the Composite Silhouette curve together with the subsample-averaged micro- and macro-averaged Silhouette curves.
model.plot_results()
If ground_truth was provided, it is shown as a vertical reference line.
Quick Start
This example creates a simple synthetic dataset with five Gaussian clusters, evaluates candidate values of k, and selects the number of clusters using Composite Silhouette.
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
from compsil import CompSil
# Create a simple synthetic dataset
X, y = make_blobs(
n_samples=1000,
centers=5,
n_features=10,
cluster_std=1.5,
random_state=42,
)
# Standardize the data
X = StandardScaler().fit_transform(X)
# Initialize Composite Silhouette
model = CompSil(
data=X,
ground_truth=5,
k_values=range(2, 11),
num_samples=10,
sample_size="auto",
random_state=0,
n_jobs=-1,
)
# Evaluate all candidate k values
model.evaluate()
# Select the number of clusters
best_k = model.get_optimal_k()
print("Selected k:", best_k)
# Inspect the full results table
results = model.get_results_dataframe()
print(results)
# Plot the Composite Silhouette curve
model.plot_results()
The S_mM column in the results table contains the Composite Silhouette score for each candidate number of clusters. The selected number of clusters is the value of k that maximizes S_mM.
CompSil can also be used to evaluate a single candidate number of clusters. In this case, pass an integer to k_values.
# Evaluate a single candidate k
model = CompSil(
data=X,
k_values=5
)
model.evaluate()
# Composite Silhouette score for k=5
print("Composite Silhouette score:", model.score_)
# Full results table
results = model.get_results_dataframe()
print(results)
When a single value of k is evaluated, model.score_ stores the corresponding Composite Silhouette score.
Acknowledgments
This work was supported by Archimedes Research Unit, Athena Research Center.
License
This project is licensed under the MIT License.
Links
- Package: PyPI
- Paper: Accepted at ECML PKDD 2026
- DOI: Coming soon
- Preprint: arXiv:2604.13816
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file compsil-0.1.0.tar.gz.
File metadata
- Download URL: compsil-0.1.0.tar.gz
- Upload date:
- Size: 13.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc70e1b4daae6a0707ce30fcfa3bb7ee0db68ca22b6362b9d0d54405f762854f
|
|
| MD5 |
5c9b9219d3ff72b399957fc0b4ff5f5d
|
|
| BLAKE2b-256 |
62921ab88a8c2f67843ec85ce5ff7fbde2207d087a670c19fc504f5a8d62160b
|
Provenance
The following attestation bundles were made for compsil-0.1.0.tar.gz:
Publisher:
python-publish.yml on semoglou/compsil
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
compsil-0.1.0.tar.gz -
Subject digest:
cc70e1b4daae6a0707ce30fcfa3bb7ee0db68ca22b6362b9d0d54405f762854f - Sigstore transparency entry: 1675256547
- Sigstore integration time:
-
Permalink:
semoglou/compsil@50b981843cd27b53455ea64e5f35d339e903c305 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/semoglou
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@50b981843cd27b53455ea64e5f35d339e903c305 -
Trigger Event:
release
-
Statement type:
File details
Details for the file compsil-0.1.0-py3-none-any.whl.
File metadata
- Download URL: compsil-0.1.0-py3-none-any.whl
- Upload date:
- Size: 10.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58003b6b8681dbc2201d3edc996e089e35e1e29212c9082f995254be21d8d51f
|
|
| MD5 |
69ed85ffbc18b1d8100b9e1df6c869b3
|
|
| BLAKE2b-256 |
316ba24ad4a2c646cb39507151a1c0ccebe1806f28b4e4d169c00062b3b0a68d
|
Provenance
The following attestation bundles were made for compsil-0.1.0-py3-none-any.whl:
Publisher:
python-publish.yml on semoglou/compsil
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
compsil-0.1.0-py3-none-any.whl -
Subject digest:
58003b6b8681dbc2201d3edc996e089e35e1e29212c9082f995254be21d8d51f - Sigstore transparency entry: 1675256684
- Sigstore integration time:
-
Permalink:
semoglou/compsil@50b981843cd27b53455ea64e5f35d339e903c305 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/semoglou
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@50b981843cd27b53455ea64e5f35d339e903c305 -
Trigger Event:
release
-
Statement type:







