Shared neural memory middleware for multi-agent systems.

Project description
🧠 Context Bridge
Shared neural memory middleware for multi-agent systems
Stop passing giant transcripts between agents. Give them a shared memory and let each one recall only what it needs.






Contents · Problem · Compare · Architecture · Features · Install · Demo · API · Config · Benchmark · Deploy · Roadmap
The problem
Multi-agent frameworks route work by passing ever-larger context blobs from agent to agent. The shared history grows with every hop, so token cost climbs super-linearly and the genuinely relevant facts drown in noise.
❌ Without Context Bridge ✅ With Context Bridge
Agent A ──[full history]──▶ Agent B Agent A ─┐ ┌─ Agent B
│ │ ▼ ▼
└──[bigger history]──▶ Agent C ┌─────────────────────┐
tokens 📈📈📈 cost 💸 │ Shared memory pool │
│ (write • recall) │
every agent re-reads everything └─────────────────────┘
each agent recalls only its
task-scoped, budgeted slice
Context Bridge is a standalone service that turns agent memory into a shared, governed, queryable pool. Agents write their outputs into it and recall just the slice they need for the current task — under a strict token budget.
Why it's different
- Shared, not per-agent. Memory is a first-class service every agent reads from and writes to — with full provenance — not a private scratch buffer.
- Governed writes. Confidence gating, near-duplicate suppression and optional summarize-before-store stop the pool from poisoning itself.
- Token budgets are explicit. Every recall is bounded and reports exactly what it spent — the measurable cost-savings lever.
How it compares
| Transcript passing (AutoGen-style) |
Per-agent memory (mem0 / Letta) |
Context Bridge | |
|---|---|---|---|
| Memory scope | none — re-sent each hop | private per agent | shared across agents |
| Token cost | grows ~quadratically | linear-ish | bounded by budget |
| Retrieval | — | dense only | hybrid + rerank + MMR |
| Provenance | — | partial | full (agent / task / session) |
| Write governance | — | varies | dedup + confidence + TTL |
| Multi-tenant | — | — | namespace RBAC |
Context Bridge is not another agent framework — it's the memory layer any framework can point at.
Architecture
flowchart TB
subgraph Agents
A1[Agent A]
A2[Agent B]
A3[Agent C]
end
subgraph CB["Context Bridge API (/v1)"]
MM[MemoryManager]
end
subgraph Tiers["Memory tiers"]
W[("Working memory<br/>in-process / Redis")]
S[("Semantic memory<br/>Qdrant · dense + sparse")]
E[("Episodic / provenance<br/>SQL · SQLAlchemy")]
end
A1 & A2 & A3 -->|remember / recall| MM
MM --> W
MM --> S
MM --> E
| Tier | Purpose | Backing store |
|---|---|---|
| Working | Recent per-session scratchpad, ephemeral | In-process / Redis |
| Semantic | Long-term embedded knowledge | Qdrant (dense + sparse) |
| Episodic | Task graph & provenance ("who/what/when/why") | SQL (SQLite / Postgres) |
Read & write pipelines
sequenceDiagram
participant Agent
participant API as Context Bridge
participant V as Qdrant
participant DB as SQL
Note over Agent,DB: WRITE (governed)
Agent->>API: remember(content, agent_id, namespace)
API->>API: chunk → embed (dense+sparse)
API->>API: dedup + confidence gate
API->>V: upsert chunks
API->>DB: store parent doc + episode
Note over Agent,DB: RECALL (token-budgeted)
Agent->>API: recall(query, token_budget)
API->>V: hybrid search (RRF fusion)
API->>API: rerank → MMR → assemble ≤ budget
API-->>Agent: context + cited sources + tokens_used
Every provider sits behind a small Protocol — VectorStore, Embedder,
Reranker, WorkingMemory, Summarizer — so backends are swappable without
vendor lock-in.
Features
| 🔀 Hybrid retrieval | Dense + sparse vectors fused with Reciprocal Rank Fusion |
| 🎯 Reranking + MMR | Cross-encoder precision, then diversity to kill redundancy |
| 💰 Token budgeting | Recall is bounded and reports tokens_used |
| 🧬 Small-to-big chunks | Match a small chunk, expand to its parent on demand |
| 🛡️ Write governance | Dedup, confidence gating, summarize-before-store |
| 🧾 Provenance | Every memory is attributable; full session timeline |
| ⏳ TTL & decay | Expiry at query time + background/endpoint sweep |
| 🏢 Multi-tenant RBAC | API keys scoped to namespace globs + read/write permissions |
| 🔑 Auth & rate limit | Constant-time keys; in-memory or Redis limiter |
| 🔌 Embedder choice | Local (FastEmbed), OpenAI, Cohere — all behind one protocol |
| 📡 Streaming recall | Server-Sent Events: render context progressively |
| 📊 Observability | Prometheus metrics, request IDs, structured errors |
| 🐳 Production-ready | Dockerfile, CI, Alembic migrations, typed SDK |
| 🔌 Pluggable | Swap Qdrant/embedder/reranker behind protocols |
🧠 Cognitive layer (opt-in)
Beyond storage — the shared pool consolidates, reconciles and learns:
| 💤 Reflective consolidation | Cluster related memories and synthesize higher-order insights no single agent wrote |
| ⚖️ Truth-maintenance | Detect contradictions between agents, flag and resolve them |
| 🕸️ Knowledge graph | Extract entity/relation triples; multi-hop GET /v1/graph/neighbors |
| 🔁 Learning recall | Outcome feedback re-ranks future retrieval |
| 🔒 PII/secret redaction | Mask sensitive data before it enters the shared pool |
🤝 Collective learning (the team compounds)
The pool doesn't just remember — the team gets better over time:
| 🏅 Agent reputation | Per-namespace profiles learn who is reliable at what (GET /v1/agents) |
| 🎯 Outcome credit | A task's success/failure propagates to the memories and agents behind it (POST /v1/outcomes) |
| 📒 Procedural memory | Reusable playbooks with success tracking, so solved problems aren't re-solved (/v1/procedures) |
| 🧷 Salient distillation | Stream cheap turns; the system keeps only what was dwelled upon and carries it into future chats (/v1/sessions/{id}/distill) |
| 📅 Temporal recall | Memories carry dates; recall with include_dates and since/until — remembers when, human-like |
| 🧭 Ontology alignment | Agents that named the same entity differently converge on one canonical name — auto (POST /v1/graph/align) or by alias (POST /v1/graph/aliases) |
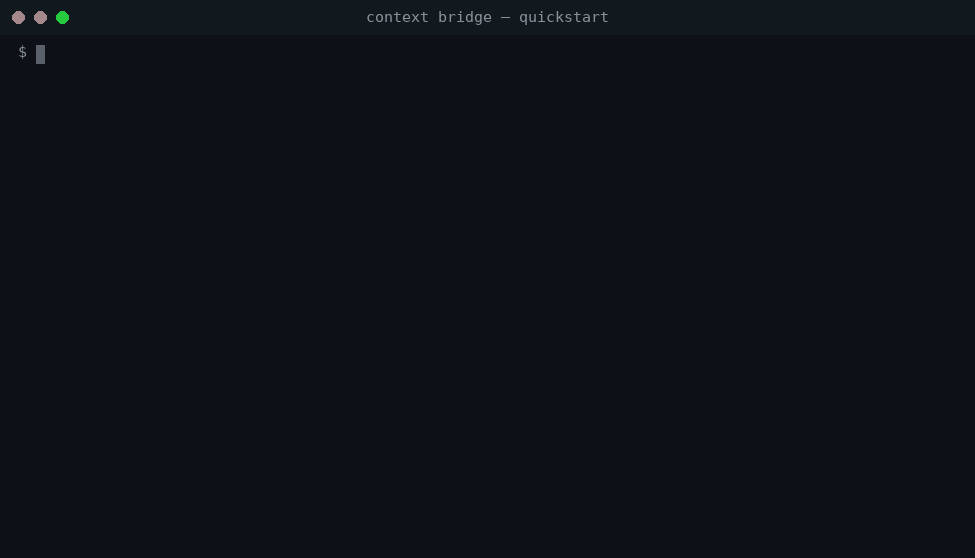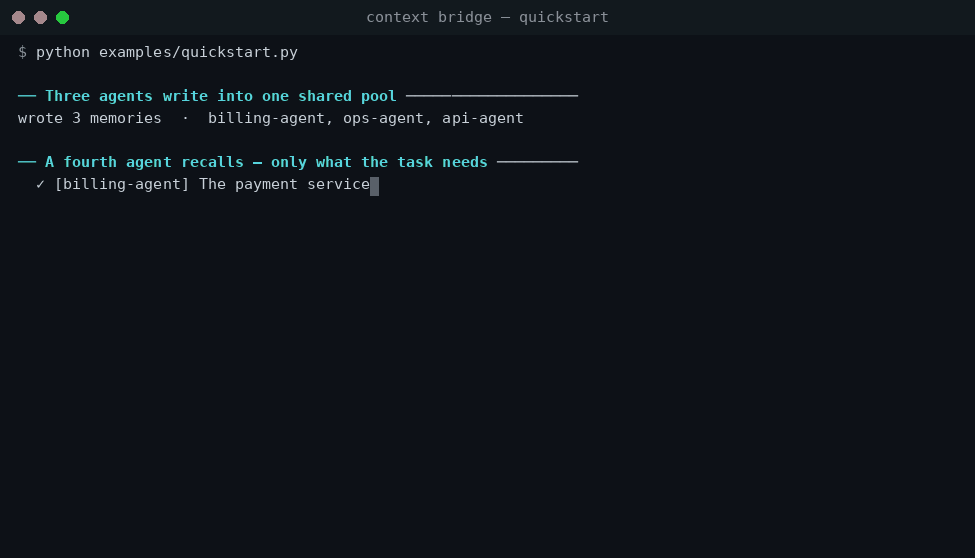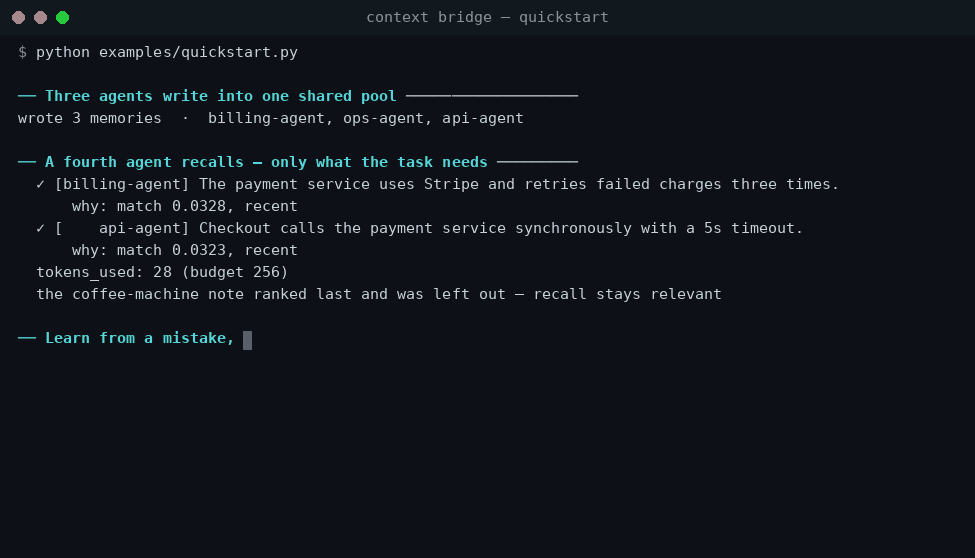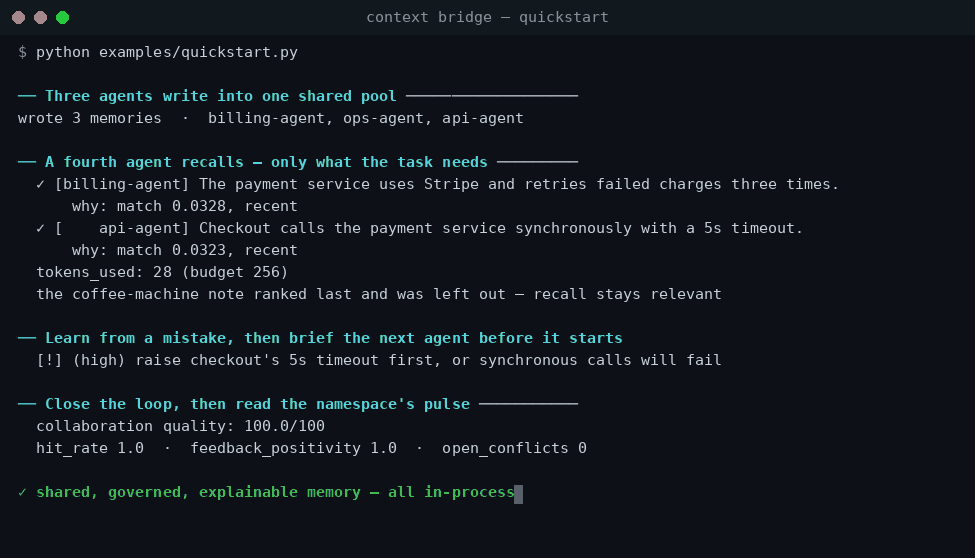
| 📈 Collaboration-quality score | One 0-100 metric (GET /v1/quality) blends recall hit-rate, feedback positivity and conflict health, so a team can watch shared memory pay off |
| 🧯 Failure memory | Capture a lesson from a mistake; the system proactively raises it as a guardrail before similar work, so the team stops repeating errors (/v1/lessons) |
| 🧰 Preflight briefing | Before a task, get the lessons to avoid and the playbooks that worked in one call (POST /v1/preflight) |
| 🔄 Belief revision | Resolving a contradiction decays the loser's trust; confidence-weighted recall sinks discredited memories and retires repeat losers — the pool changes its mind |
| ⚗️ Auto lesson distillation | Cluster memories implicated in failures into auto-drafted lessons, no human in the loop (POST /v1/lessons/distill) |
| 🔎 Recall explainability | Every recalled chunk carries per-signal scores and a plain-language why it was retrieved (match, feedback, confidence, age) |
| 🩺 Memory health panel | One pulse-check per namespace: volume, trust distribution, conflicts, lessons, quality (GET /v1/namespaces/{ns}/health) |
| ⚖️ Auto conflict resolution | Close contradictions automatically when one side decisively leads, leaving ambiguous ones for a human (POST /v1/conflicts/auto-resolve) |
| 🧬 Belief timeline | A memory diff: how belief about a topic changed over time — which claim fell out of favour, and when (GET /v1/namespaces/{ns}/beliefs) |
| ⏱️ Scheduled maintenance | One housekeeping cycle — sweep + auto-resolve + consolidate + distill — on demand or on a timer (POST /v1/maintenance/run) |
| 📡 Event webhooks | Best-effort notifications on conflict.opened / conflict.resolved / lesson.created, never blocking a write (WEBHOOK_URLS) |
| 📦 Namespace portability | Export a namespace to a portable, vector-free document and restore it anywhere — re-embedded on import (/v1/namespaces/{ns}/export · …/import) |
Install
pip install context-bridge-memory # core
pip install "context-bridge-memory[fastembed,redis,postgres]" # full local stack
The distribution is published as
context-bridge-memory; the import package stayscontext_bridge(e.g.from context_bridge.sdk import ...).
From source (for development):
git clone https://github.com/sa-aris/context-bridge && cd context-bridge
uv pip install -e ".[dev]"
Quick start
# 1. (optional) backing services — Qdrant + Postgres + Redis
docker compose up -d
# 2. run the API
context-bridge # if installed from PyPI -> http://localhost:8000
make run # from source (auto-reload) -> http://localhost:8000/docs
Open http://localhost:8000 for the service banner, or /docs for interactive
API docs.
Out of the box the defaults are dependency-light and fully offline: an
in-process Qdrant (QDRANT_URL=:memory:), a deterministic hashing embedder and
SQLite. Flip EMBED_PROVIDER=fastembed for production-quality local embeddings
and point QDRANT_URL / DATABASE_URL at real services. See
.env.example for every option.
Demo
Run the whole tour offline in one command — it uses real local embeddings (a small model is fetched once) and needs no external services:
python examples/quickstart.py
Or drive it over HTTP. Write two memories from two different agents, then recall just the relevant one:
# Agent 1 writes
curl -s localhost:8000/v1/memory/write -H 'content-type: application/json' -d '{
"content": "The payment service uses Stripe and retries failed charges three times.",
"agent_id": "billing-agent", "session_id": "run-42", "namespace": "project-x"
}'
# Agent 2 writes something unrelated
curl -s localhost:8000/v1/memory/write -H 'content-type: application/json' -d '{
"content": "The office coffee machine is broken; a replacement is on order.",
"agent_id": "ops-agent", "session_id": "run-42", "namespace": "project-x"
}'
# Another agent recalls — within a token budget
curl -s localhost:8000/v1/memory/query -H 'content-type: application/json' -d '{
"query": "how does the payment service handle failed charges?",
"namespace": "project-x", "token_budget": 256
}'
{
"context": "The payment service uses Stripe and retries failed charges three times.",
"tokens_used": 14,
"chunks": [{ "id": "…", "agent_id": "billing-agent", "score": 0.83, … }],
"sources": [{ "agent_id": "billing-agent", "session_id": "run-42", … }]
}
The coffee-machine note never shows up — only the budgeted, reranked, deduped slice the query actually needs, with provenance for every line.
From an agent (Python SDK)
from context_bridge.sdk import ContextBridgeClient
with ContextBridgeClient("http://localhost:8000") as cb:
cb.remember(
"The payment service retries failed charges three times.",
agent_id="billing-agent", session_id="run-42", namespace="project-x",
)
result = cb.recall(
"how are failed charges handled?",
namespace="project-x", token_budget=512,
)
print(result["context"]) # budget-bounded, reranked, deduped
print(result["sources"]) # provenance for every included chunk
An AsyncContextBridgeClient with the same surface is available for async agents.
API
| Method | Path | Description |
|---|---|---|
POST |
/v1/memory/write |
Chunk, embed, govern and store content |
POST |
/v1/memory/write_batch |
Write many memories in one request |
POST |
/v1/memory/query |
Hybrid recall within a token budget |
POST |
/v1/memory/query/stream |
Hybrid recall streamed as Server-Sent Events |
GET |
/v1/memory |
List / paginate records by namespace |
GET · DELETE |
/v1/memory/{id} |
Fetch / remove a single record |
DELETE |
/v1/memory?namespace=&session_id= |
Erase all memory for a namespace/session |
POST |
/v1/memory/summarize |
Compress a session into a summary memory |
POST |
/v1/memory/feedback |
Signal whether a recalled memory was useful |
GET |
/v1/sessions/{id}/timeline |
Episodic / provenance view |
POST · GET |
/v1/sessions/{id}/turns |
Append / read ephemeral conversational turns |
POST |
/v1/sessions/{id}/distill |
Promote salient turns into durable cross-session memory |
POST |
/v1/maintenance/sweep |
Delete TTL-expired memories |
POST |
/v1/maintenance/consolidate |
Cluster & synthesize insights for a namespace |
POST |
/v1/maintenance/run |
Run a full housekeeping cycle (sweep + per-namespace upkeep) |
GET |
/v1/conflicts · POST /v1/conflicts/{id}/resolve |
Inspect / resolve contradictions |
POST |
/v1/conflicts/auto-resolve |
Auto-close decisive contradictions (belief revision) |
GET |
/v1/graph/neighbors |
Traverse the knowledge graph |
POST |
/v1/graph/aliases · /v1/graph/align |
Map an alias · auto-merge entity variants |
GET |
/v1/agents |
Agent reputation leaderboard |
POST |
/v1/outcomes |
Credit a session's memories & agents by outcome |
GET · POST |
/v1/procedures · …/{id}/outcome |
Playbooks with success tracking |
GET · POST |
/v1/lessons · …/{id}/confirm |
Capture / list / confirm lessons from past mistakes |
POST |
/v1/lessons/distill |
Auto-draft lessons from memories implicated in failures |
POST |
/v1/preflight |
Pre-task briefing: lessons to avoid + playbooks that worked |
GET |
/v1/quality |
Collaboration-quality score for a namespace |
GET |
/v1/namespaces/{ns}/health |
Memory health panel for a namespace |
GET |
/v1/namespaces/{ns}/beliefs?query=… |
Belief timeline (memory diff) for a topic |
GET · POST |
/v1/namespaces/{ns}/export · …/import |
Back up / migrate a namespace's knowledge |
GET |
/health · /healthz · /metrics |
Liveness · readiness · Prometheus |
Interactive OpenAPI docs are served at /docs.
Configuration
| Variable | Default | Description |
|---|---|---|
QDRANT_URL |
:memory: |
Qdrant location or :memory: |
EMBED_PROVIDER |
hashing |
hashing · fastembed · openai · cohere |
RERANK_PROVIDER |
identity |
identity · fastembed · cohere |
DATABASE_URL |
sqlite+pysqlite:///./context_bridge.db |
Episodic store |
WORKING_PROVIDER |
memory |
memory or redis |
SUMMARIZER_PROVIDER |
extractive |
extractive or llm |
DEFAULT_TOKEN_BUDGET |
2048 |
Default recall token budget |
API_KEYS |
(empty) | Comma-separated keys; empty = open |
API_KEY_POLICIES |
(empty) | JSON RBAC: key → namespace globs + read/write |
RATE_LIMIT_PER_MINUTE |
0 |
Per-identity limit; 0 = disabled |
SWEEP_INTERVAL_SECONDS |
0 |
Background TTL sweep; 0 = disabled |
See .env.example for the complete list.
Proof: token savings benchmark
A runnable benchmark compares transcript passing vs. shared-memory recall over a synthetic multi-agent task:
python -m context_bridge.benchmark
agents transcript bridge savings
------------------------------------------
4 216 222 -2.8%
8 1,008 670 33.5%
16 4,320 1,566 63.8%
32 17,856 3,358 81.2%
With a handful of agents the transcript is cheap, but the advantage compounds: transcript passing grows ~quadratically while budgeted recall stays bounded, so by 32 agents Context Bridge uses ~81% fewer context tokens.
Deployment
Docker
docker build -t context-bridge .
docker run -p 8000:8000 \
-e QDRANT_URL=http://qdrant:6333 \
-e DATABASE_URL=postgresql+psycopg://user:pass@postgres/context_bridge \
context-bridge
The image runs as a non-root user and ships a /health healthcheck. Apply
database migrations with alembic upgrade head (the API also auto-creates
tables for local development).
Kubernetes (Helm)
helm install cb deploy/helm/context-bridge \
--set image.repository=ghcr.io/you/context-bridge \
--set ingress.enabled=true
The chart includes a Deployment, Service, ConfigMap, ServiceAccount, optional Ingress and a CPU-based HorizontalPodAutoscaler.
Observability
/metrics exposes write/query/dedup counters, token-usage and chunk-count
histograms, sweep totals and a request-latency histogram. Every response carries
an X-Request-ID. Spin up a ready-made Prometheus + Grafana stack (a dashboard
is auto-provisioned):
docker compose -f docker-compose.yml -f docker-compose.observability.yml up -d
# Grafana -> http://localhost:3000 (admin / admin)
For distributed tracing, install the otel extra and set TRACING_ENABLED=true
with OTEL_EXPORTER_OTLP_ENDPOINT — the write/query pipeline stages emit spans
via OTLP to Jaeger/Tempo/Grafana.
Development
make test # pytest (hermetic: in-memory Qdrant + SQLite)
make lint # ruff
make typecheck # mypy
make fmt # ruff format + autofix
See CONTRIBUTING.md. The test suite needs no network: it uses in-process Qdrant, SQLite and a deterministic embedder; model-dependent tests skip automatically when offline.
Roadmap
- Hybrid sparse vectors for OpenAI/Cohere providers (SPLADE side-car)
- gRPC API surface alongside REST
- Per-tenant usage accounting & quotas
- Managed cloud offering
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file context_bridge_memory-0.1.1.tar.gz.
File metadata
- Download URL: context_bridge_memory-0.1.1.tar.gz
- Upload date:
- Size: 315.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
78d9296f8cd0b623ae04733dcda494d65ff047c9d0dbd841cafbe93da2e18a2f
|
|
| MD5 |
54cb23db139e0293a2004ee59ef87a6b
|
|
| BLAKE2b-256 |
9622b53a9f65eaed69c72ebaddb154703c2090b8ed3abc13c61721bd5c430713
|
Provenance
The following attestation bundles were made for context_bridge_memory-0.1.1.tar.gz:
Publisher:
release.yml on sa-aris/Context-Bridge
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
context_bridge_memory-0.1.1.tar.gz -
Subject digest:
78d9296f8cd0b623ae04733dcda494d65ff047c9d0dbd841cafbe93da2e18a2f - Sigstore transparency entry: 1965733422
- Sigstore integration time:
-
Permalink:
sa-aris/Context-Bridge@585fb997751295ddf136336b2a49af4aab4ed401 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/sa-aris
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@585fb997751295ddf136336b2a49af4aab4ed401 -
Trigger Event:
push
-
Statement type:
File details
Details for the file context_bridge_memory-0.1.1-py3-none-any.whl.
File metadata
- Download URL: context_bridge_memory-0.1.1-py3-none-any.whl
- Upload date:
- Size: 103.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
caf30a498ba8a55b83a39fc5cd5384702efa2e58ddc2b7e8125253961b4a794d
|
|
| MD5 |
8341ccb7abf6ec262802f57997c32300
|
|
| BLAKE2b-256 |
eb14184928bdc7643d2c2a3c867c2196656d3910e2e24ddb4f2eb265a8e47d6f
|
Provenance
The following attestation bundles were made for context_bridge_memory-0.1.1-py3-none-any.whl:
Publisher:
release.yml on sa-aris/Context-Bridge
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
context_bridge_memory-0.1.1-py3-none-any.whl -
Subject digest:
caf30a498ba8a55b83a39fc5cd5384702efa2e58ddc2b7e8125253961b4a794d - Sigstore transparency entry: 1965733561
- Sigstore integration time:
-
Permalink:
sa-aris/Context-Bridge@585fb997751295ddf136336b2a49af4aab4ed401 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/sa-aris
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@585fb997751295ddf136336b2a49af4aab4ed401 -
Trigger Event:
push
-
Statement type:







