Persistent causal agent memory with lossless compaction
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description



Causal memory for AI agents.
Structured memory objects + causal trace over durable events — so agents can recall why, not just what.
Quickstart · Features · Supported Clients · Contributing
Core Memory
Give your AI agents persistent memory built for the way conversations actually work. Core Memory is a plug and play, self-hosted conversational memory MCP server that captures each turn as a memory object, builds causal links as the dialogue unfolds, and recalls with full evidence. Works with Claude Code, Cursor, ChatGPT, or any MCP-compatible client.
Transcripts are where most decision making actually happens, across agent conversations, email threads, and Slack. Yet every tool treats them as a noisier version of a document. Core Memory is built specifically for that problem.
Remember every turn: Each turn produces a memory object linked to prior turns by typed causal edges. Claims are tracked and superseded when contradicted, so memory stays truthful as the dialogue develops.
Stored as a causal graph: Memory objects are linked by the relationship between them, like caused_by, contradicts, and supports. When you ask a question, your agent follows the chain of reasoning, not just a ranked vector similarity score. Every result shows you the path of causality between the memory events.
Depth on demand: Tune recall(query, effort="low" | "medium" | "high") for your needs. Fast lookup when that is enough, full causal traversal when the question needs it. The orchestrator decides.
Rolling context injection on a budget: Compacted memory objects carry only their title, type, and causal associations, allowing 10+ sessions of history to be injected for a fraction of the token cost of naive loading. Promoted objects stay full context when active, and the agent can expand any compacted memory on demand with a single tool call.
Watch the Core Memory live demo on YouTube
Quick Start
Core Memory auto-detects your embeddings provider from OPENAI_API_KEY, GEMINI_API_KEY, or GOOGLE_API_KEY. No configuration needed.
uvx "core-memory[mcp]" mcp serve
Core Memory starts on http://localhost:8000/mcp and stores data in ~/.core-memory/store.
For Claude Code, add to your MCP config:
{
"mcpServers": {
"core-memory": {
"type": "streamable-http",
"url": "http://localhost:8000/mcp"
}
}
}
Start a new conversation. MCP-capable agents can capture and recall through the bundled Core Memory tools and agent guide.
Or install directly from PyPI for Python SDK use:
pip install "core-memory[mcp]"
To ingest existing transcripts, use the CLI command:
core-memory ingest transcript my-transcript.jsonl
Or call the ingest tool directly from any connected MCP client. Accepts JSONL or JSON with user/assistant, human/ai, or customer/agent roles.
See the full setup guide for MCP client configuration and adapter configurations for OpenClaw, PydanticAI, LangChain, and SpringAI.
Features
Transcript-native storage: Built specifically for conversational data, each turn is normalized into a memory object rather than chunked and indexed alongside authored documents.
Captures every turn automatically: The LLM applies causal labels from a fixed taxonomy rather than judging importance, so nothing is filtered before storage and no explicit "remember this" is required.
Rolling context injection on a budget: Compacted memory objects carry only their title, type, and causal associations, fitting 10+ sessions of history into a fraction of the token cost of naive loading.
Causal graph, not a flat index: Memory objects are linked by typed relationships (caused_by, contradicts, supports, and more), so recall follows reasoning chains instead of ranking similarity scores.
Claims tracked and superseded: Statements like "user prefers PostgreSQL" are monitored and updated when later turns contradict them. Memory stays truthful, not just full.
Full context is always retrievable: Full transcripts are preserved and linked via turn and session_ID references, so full context is always a tool call away.
Inspectable retrieval with provenance: Every recall() returns the source conversation, the traversal path that found it, and a verifiable hash. Retrieval is never a black box.
Depth on demand: recall(query, effort="low" | "medium" | "high") scales from fast lookup to full causal traversal. The orchestrator decides what the question needs.
Self-hosted MCP: Streamable-HTTP server at /mcp with a canonical agent guide that loads automatically at connection. No system prompt changes needed.
Auto-detected embedding model: Picks up OPENAI_API_KEY, GEMINI_API_KEY, or GOOGLE_API_KEY from your environment. Runs in degraded mode with one hint if none are set.
Plug and play adoption: Your data stays on your infrastructure. No cloud dependencies. A single MCP server setup works across any MCP-compatible client.
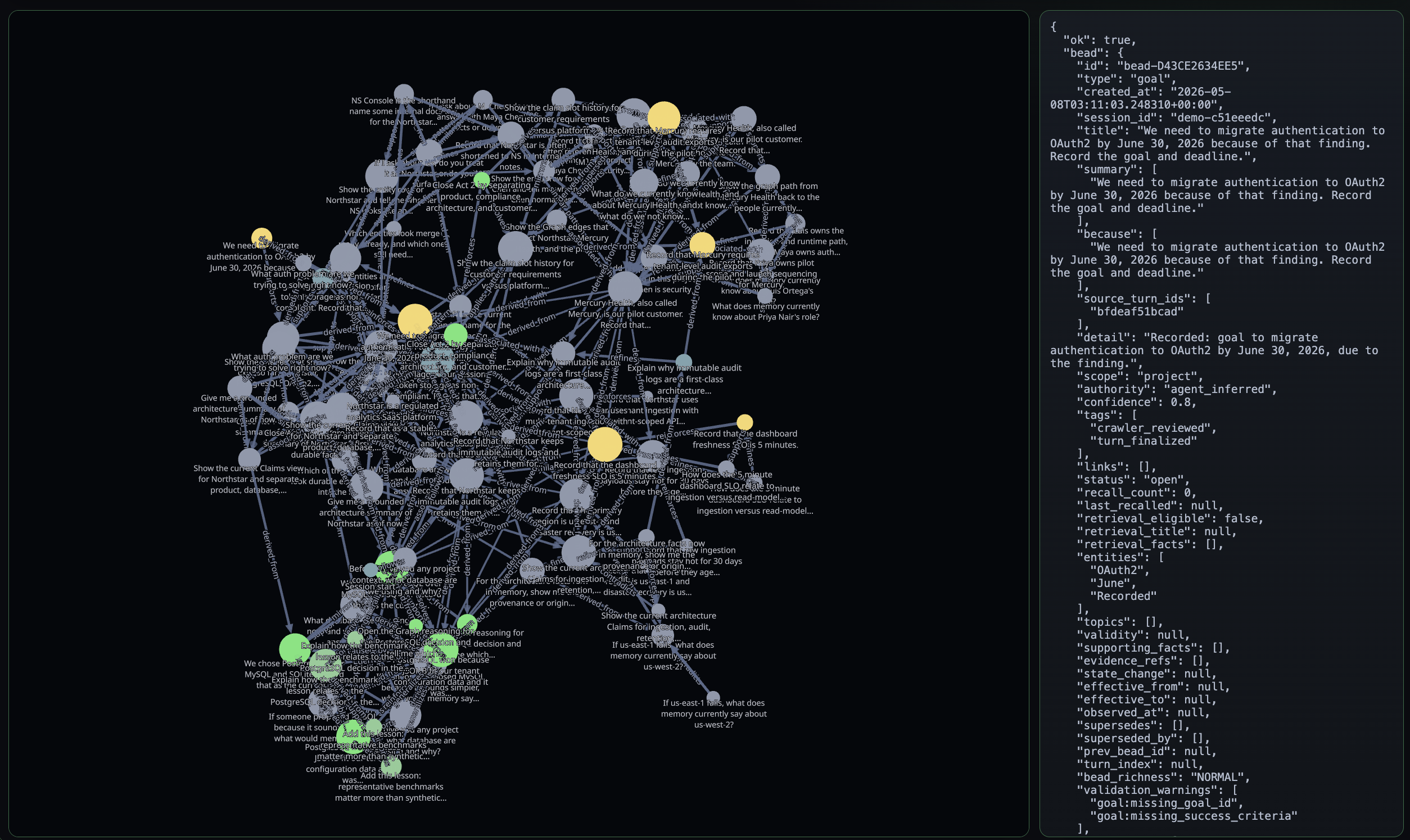
The causal memory graph (left) and the grounded bead JSON returned by recall() (right) — type, entities, session_id, and source_turn_ids make every retrieval inspectable.
Supported Clients
MCP Connection
Any client that can connect to MCP streamable-HTTP servers can use Core Memory through the /mcp endpoint. See the MCP Quickstart for setup instructions and example client configuration.
Adapter Layer Use Core Memory as a memory backend directly within your agent harness:
| Client | Plugin | Quickstart | Integration Guide | API Reference | Adapter Spec |
|---|---|---|---|---|---|
| OpenClaw | Plugin and Skill | Quickstart and Setup Guide | Guide | API Reference | Adapter Spec |
| PydanticAI | — | Quickstart | Guide | API Reference | Adapter Spec |
| SpringAI | — | Quickstart | Guide | API Reference | Adapter Spec |
| LangChain | — | Quickstart | Guide | API Reference | Adapter Spec |
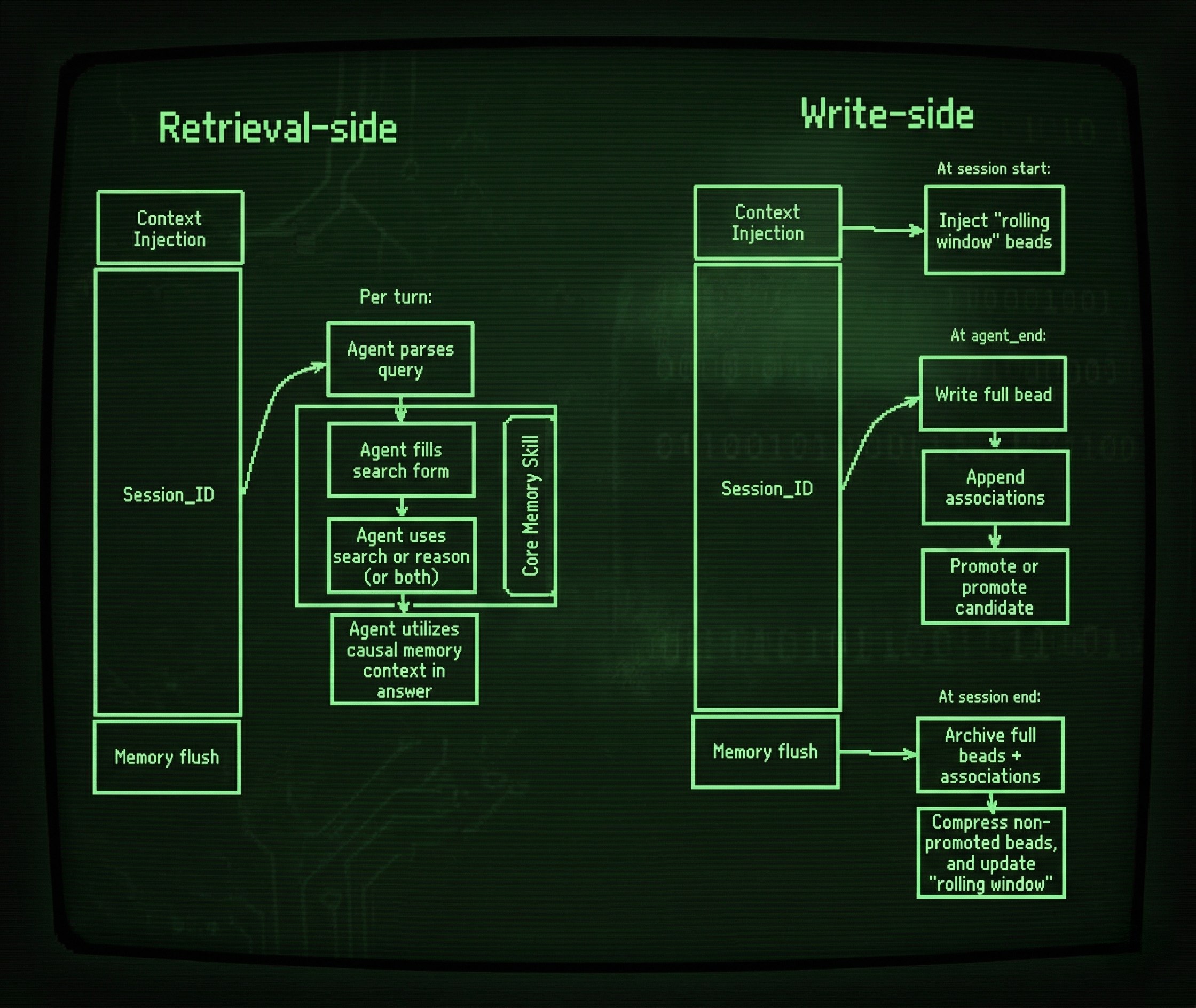
How It Works
Core Memory separates retrieval from writes, connected through session-scoped storage. Each agent turn follows the same loop:
Capture: Call capture() after each turn — or connect via MCP and it happens automatically. Each turn becomes a memory object typed as a decision, lesson, outcome, evidence, or context. An agent judge assigns typed causal associations (caused_by, contradicts, supports, and more), and claims are tracked and superseded when later turns update them. Nothing is filtered before storage — the LLM assigns structure, not importance.
Recall: recall(query, effort="low" | "medium" | "high") is the single read verb. Before each agent turn, a bounded context packet is built from the rolling window: promoted memory objects at full context, compacted ones as lightweight stubs. effort="low" runs lexical and semantic anchor search. effort="medium" adds temporal routing. effort="high" runs the full orchestration pipeline: causal traversal, multi-hop chains, goal resolution, and claim-slot enrichment. The orchestrator decides what the question needs.
Grounding: Every recall() returns a RecallResult — not just the memory, but the source conversation it came from, the traversal path that found it, and a verifiable hash. The result carries per-memory evidence records and a planning trace showing exactly which retrieval surfaces fired. Retrieval is deterministic from indexed state.
Maintain: Memory objects are either promoted (full context in the rolling window) or compacted to title, type, and associations only. Compacted objects remain queryable and their associations stay intact — the agent expands any on demand with a single tool call. Frequently-walked causal edges strengthen over time; rarely-accessed memory compacts naturally.
Core Concepts
Memory Object A memory object is a structured unit of recall typed as a decision, lesson, outcome, evidence, context, or another typed event. Each object is either promoted (full context in the rolling window) or compacted (title, type, and associations only). Promoted objects are immediately available; compacted objects can be expanded on demand via a single tool call.
Rolling Window Before each agent turn, Core Memory builds a bounded context packet from the rolling window — the session-scoped set of memory objects visible to the current conversation. Promoted objects contribute full context; compacted stubs contribute their title, type, and associations. The rolling window allows 10+ sessions of history to fit within a standard token budget.
Associations Associations are typed causal or temporal links between memory objects, assigned by an agent judge from a fixed 28-label taxonomy (caused_by, contradicts, supports, and more). Associations remain queryable even as memory objects compact. Unlike semantic similarity links, associations encode the reason one memory relates to another.
Claims Claims are verifiable statements extracted from conversation turns and tracked across sessions. When a later turn contradicts an existing claim, the association graph is updated — the prior claim is superseded, not deleted. The full history of a changing belief is preserved while the current state remains accurate.
Retrieval Pipeline Three canonical surfaces, exposed through recall(query, effort=...):
search— lexical and semantic anchor retrieval (effort="low")trace— causal traversal from search anchors (effort="medium")execute— full orchestration: search + trace + goal resolution + claim-slot enrichment (effort="high")
Hydration is explicit post-selection source recovery (turn/tools/adjacent) — not a general retrieval mode and not the same as the rolling window. Retrieval is deterministic from indexed state.
RecallResult
Every recall() returns a typed RecallResult with evidence[] (memory objects with grounding hashes), sources[], steps[] (which surfaces fired and in what order), resolved_goals[], and claim_slots{}. Stable across MCP, REST, and Python SDK.
Semantic Mode
| Mode | Behavior |
|---|---|
required (default) |
Fails closed when semantic backend is unavailable |
degraded_allowed |
Lexical fallback with degraded markers |
Storage Backend
| Backend | Use case |
|---|---|
local-faiss |
Development, single-process only ([semantic]) |
qdrant |
Production, distributed ([qdrant]) |
pgvector |
Production, Postgres-native ([pgvector]) |
chromadb |
Development alternative ([chromadb]) |
Set via CORE_MEMORY_VECTOR_BACKEND. Avoid local-faiss for multi-worker deployments. See semantic backend docs.
Learn more in the architecture docs.
Recall Example
Request
from core_memory import recall
result = recall(
"what database did we decide on for Project Heron?",
effort="high",
root="~/.core-memory"
)
Response
{
"contract": "recall_result",
"schema_version": "recall_result.v1",
"status": "answered",
"answer": "PostgreSQL",
"why": "Decision recorded in session 2026-04-12: PostgreSQL selected for Project Heron tenant config",
"evidence": [
{
"bead_id": "b_a3f9c2",
"type": "decision",
"title": "PostgreSQL selected for Project Heron tenant config",
"content_excerpt": "We decided to use PostgreSQL for the main tenant config database.",
"score": 0.94,
"grounding_hash": "sha256:e3b0c44..."
}
],
"sources": [
{
"turn_id": "turn_042",
"session_id": "session_2026_04_12",
"bead_id": "b_a3f9c2",
"speaker": "user",
"ts": "2026-04-12T14:23:00Z"
}
],
"steps": [
{ "tier": "semantic", "status": "ok", "result_count": 3, "why": "anchor search" },
{ "tier": "causal", "status": "ok", "result_count": 1, "why": "causal chains resolved" }
],
"planning": {
"selected_effort": "high",
"reason": "full orchestration: search + trace + goal resolution + claim enrichment"
},
"claim_slots": {
"project_heron.database": {
"subject": "project_heron",
"slot": "database",
"current_value": "PostgreSQL",
"status": "active",
"current_claim_id": "claim_b3f1a9",
"chain_seq": 1,
"grounding_hash": "sha256:e3b0c44..."
}
},
"resolved_goals": [],
"warnings": []
}
Documentation
Repo Map
core_memory/
├── persistence/
├── schema/
├── retrieval/
├── graph/
├── write_pipeline/
├── runtime/
├── association/
├── integrations/
├── policy/
└── cli.py
Other useful folders:
- examples/ runnable examples
- tests/ behavioral and regression coverage
- docs/ architecture, integration guides, and contracts
- plugins/ OpenClaw bridge assets
- demo/ live demo app and assets
Contributing
git clone https://github.com/JohnnyFiv3r/Core-Memory.git
cd Core-Memory
python3 -m venv .venv
source .venv/bin/activate
pip install -U pip
pip install -e ".[dev]"
core-memory --help
python3 -c "import core_memory; print('core_memory import ok')"
pytest
Useful docs:
CONTRIBUTING.md Public Surface Index
Maintainers
Core Memory is maintained by:
John Inniger (@JohnnyFiv3r) Chris Dedow (@chrisdedow)
For bugs and feature requests, please open an issue. For anything else related to the project, feel free to reach out to the maintainers directly.
Inspiration
Inspired in part by Steve Yegge's writing on beads and memory systems: https://github.com/steveyegge/beads
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file core_memory-1.1.1.tar.gz.
File metadata
- Download URL: core_memory-1.1.1.tar.gz
- Upload date:
- Size: 530.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b682c69b41b8cefc9dfc8fc13e0e23c37021cc4884e496977a0760aaa107e0db
|
|
| MD5 |
629bd0692dd823021d9f867d7e3c6c2f
|
|
| BLAKE2b-256 |
68ef1157aff464ac1fc8f78a8e547d650f55244d11017ade8153d9ad6474c445
|
Provenance
The following attestation bundles were made for core_memory-1.1.1.tar.gz:
Publisher:
publish-pypi.yml on JohnnyFiv3r/Core-Memory
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
core_memory-1.1.1.tar.gz -
Subject digest:
b682c69b41b8cefc9dfc8fc13e0e23c37021cc4884e496977a0760aaa107e0db - Sigstore transparency entry: 1610725087
- Sigstore integration time:
-
Permalink:
JohnnyFiv3r/Core-Memory@aaefa7f08fc8b43d03d2871b7c34f762bdef4755 -
Branch / Tag:
refs/heads/master - Owner: https://github.com/JohnnyFiv3r
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@aaefa7f08fc8b43d03d2871b7c34f762bdef4755 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file core_memory-1.1.1-py3-none-any.whl.
File metadata
- Download URL: core_memory-1.1.1-py3-none-any.whl
- Upload date:
- Size: 442.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5dba72670d539e0cc209da47cc333af201ae8628aa3704b64169a914b7b988fd
|
|
| MD5 |
a437501527bd878c38bd2ec5e3c3f577
|
|
| BLAKE2b-256 |
ca66603fc23a718c95b23c5db9c9ab14174c901c8da088182819d8bd4075eb6b
|
Provenance
The following attestation bundles were made for core_memory-1.1.1-py3-none-any.whl:
Publisher:
publish-pypi.yml on JohnnyFiv3r/Core-Memory
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
core_memory-1.1.1-py3-none-any.whl -
Subject digest:
5dba72670d539e0cc209da47cc333af201ae8628aa3704b64169a914b7b988fd - Sigstore transparency entry: 1610725149
- Sigstore integration time:
-
Permalink:
JohnnyFiv3r/Core-Memory@aaefa7f08fc8b43d03d2871b7c34f762bdef4755 -
Branch / Tag:
refs/heads/master - Owner: https://github.com/JohnnyFiv3r
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@aaefa7f08fc8b43d03d2871b7c34f762bdef4755 -
Trigger Event:
workflow_dispatch
-
Statement type:







