Exact out-of-core Cox proportional hazards regression via streaming Newton-Raphson

Project description
coxstream
Exact out-of-core Cox proportional hazards regression via streaming Newton-Raphson.

Standard CoxPH solvers (lifelines, scikit-survival, R survival) load the
full cohort into memory before fitting, so on registry-scale data they exhaust
RAM long before the computation is hard. coxstream computes the exact Efron
partial-likelihood estimate by streaming a single time-sorted pass over the data
per Newton-Raphson iteration, holding only O(p^2) state for p covariates.
Working memory is therefore independent of the number of observations n:
the model fits on a workstation even when the cohort is far larger than RAM.
The streamed estimate is the in-memory maximum-likelihood estimate, and the Efron tie correction is carried across chunk boundaries, so heavily tied data are handled exactly.
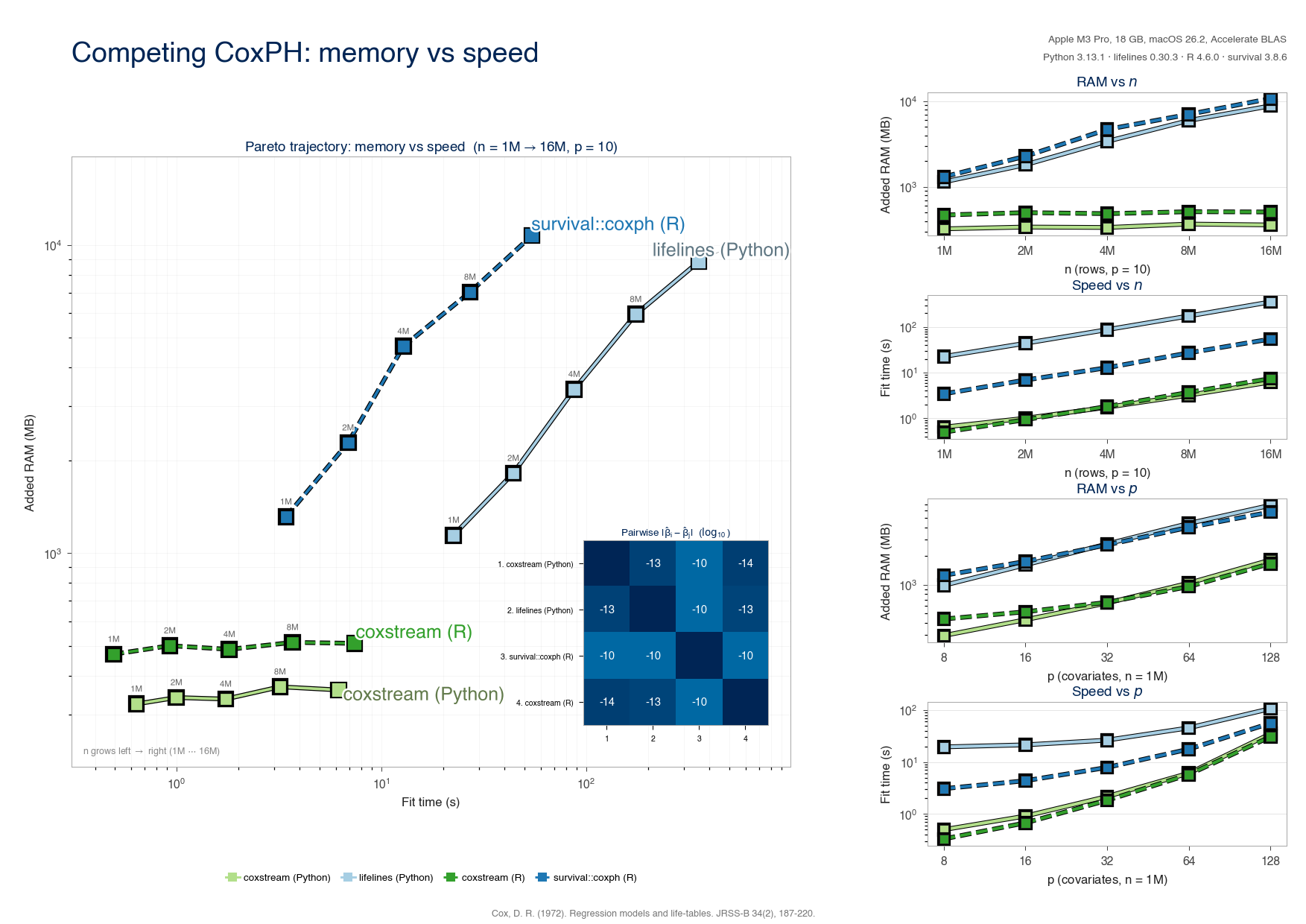
Memory vs. speed against lifelines and R survival::coxph: coxstream's peak
RAM stays flat in the number of rows while in-memory solvers grow with the
cohort, at matching coefficients. See the accompanying paper for the full
methodology.
Install
pip install coxstream # core (numpy only)
pip install coxstream[parquet] # + out-of-core fit_parquet (pyarrow)
The package builds a small Cython kernel, so a C compiler is required.
Usage
In memory:
import numpy as np
from coxstream import CoxStream
model = CoxStream().fit(durations, events, X, feature_names=names)
print(model.coef_, model.n_iter_)
Out of core, from a Parquet file pre-sorted by descending event time (never materialises the cohort):
from coxstream import CoxStream
# The file must already be sorted by duration DESC. `fit_parquet` verifies this
# from the Parquet footer statistics alone (no full pass) and rejects a file
# that is out of order; pass assume_sorted=True to skip the check.
#
# Sort it once with an out-of-core sorter -- both spill to disk, so they handle
# a cohort larger than RAM (a sort-engine benchmark found these the fastest):
# duckdb: COPY (SELECT * FROM 'cohort.parquet' ORDER BY duration DESC)
# TO 'cohort_desc.parquet' (FORMAT PARQUET);
# polars: (pl.scan_parquet("cohort.parquet")
# .sort("duration", descending=True)
# .sink_parquet("cohort_desc.parquet"))
# R: duckdb via its R client runs the same COPY ... ORDER BY DESC.
# If the cohort fits in RAM, skip the file and call .fit, which sorts for you.
model = CoxStream().fit_parquet(
"cohort_desc.parquet",
duration_col="duration",
event_col="event",
covariate_cols=["age_std", "sex", "treatment"],
)
print(model.coef_)
To validate a file's order ahead of time -- a dry run, e.g. a CI or pipeline
gate right after you sort and before a long fit -- call check_sorted, which
runs the same footer-only check without fitting and raises on a file that is
provably out of order:
from coxstream import check_sorted
check_sorted("cohort_desc.parquet", duration_col="duration") # raises if unsorted
It doubles as a shell gate -- it exits non-zero on an out-of-order file, so a pipeline step can fail fast without a bespoke CLI:
python -c "import coxstream; coxstream.check_sorted('cohort_desc.parquet', 'duration')"
Validation
coxstream is verified against lifelines and R survival::coxph:
- It reproduces the in-memory maximum-likelihood estimate to machine precision on synthetic data.
- On the heavily tied Synthea 100K cohort (51 % of event times tied) it matches
lifelinesto ~1e-6. - Peak resident memory is flat in
nwhile in-memory solvers grow with the cohort and eventually exhaust RAM.
The package's own test suite is dependency-free: it checks exactness against a
self-contained plain-numpy Cox Newton-Raphson reference. The cross-checks
against lifelines and R survival::coxph above live in the accompanying
benchmark and paper.
The methodology and full results are in the accompanying paper (see Citation).
Scope
coxstream implements the exact Efron partial likelihood for large-n,
modest-p tabular survival data. It is a focused estimator, not a full survival
suite: it does not provide baseline-hazard estimation, time-varying covariates,
or proportional-hazards diagnostics.
Testing
pip install -e '.[test]' # core suite (numpy only)
pip install -e '.[test,parquet]' # + the out-of-core fit_parquet test
pytest
Citation
If you use coxstream, please cite it via the metadata in
CITATION.cff.
License
MIT. See LICENSE.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file coxstream-0.1.0.tar.gz.
File metadata
- Download URL: coxstream-0.1.0.tar.gz
- Upload date:
- Size: 178.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c5af06e29b67510383627a24d6908090d2e5103cf615259d27afb93096d0c2bd
|
|
| MD5 |
d869d3e24b45cb028c2d895301fa2652
|
|
| BLAKE2b-256 |
1ab4aae39ed97e2363f389629017b53448d4666a3f5db649cbf99d30d8051c0a
|
File details
Details for the file coxstream-0.1.0-cp313-cp313-macosx_10_13_universal2.whl.
File metadata
- Download URL: coxstream-0.1.0-cp313-cp313-macosx_10_13_universal2.whl
- Upload date:
- Size: 346.1 kB
- Tags: CPython 3.13, macOS 10.13+ universal2 (ARM64, x86-64)
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9501f0aef76bcb52551b027fd0ca385a99405966b30399313e3f2f3abfae1171
|
|
| MD5 |
6275f4fcb1264d38a4a57d095e49c6a1
|
|
| BLAKE2b-256 |
db434b06a314f3884e4e988c85a1b09f61b213512d5fe98f2a1644b911d93c20
|







