Continuous active inference for Python — the continuous-state sibling of pymdp.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
cpomdp





Continuous active inference for Python. The continuous-state sibling of pymdp.
pymdp is great, but it speaks in discrete states. A lot of the world isn't discrete. Positions, velocities, temperatures, the kinds of things you'd actually want an agent to track and steer, don't come in neat little categories. cpomdp fills that gap. You hand it a linear-Gaussian model of how the world moves and what you can see of it, and you get back an agent that perceives and acts in the same infer_states / sample_action loop pymdp users already know.
That's the whole idea: keep the pymdp muscle memory, swap the discrete machinery underneath for continuous.
Full documentation — API reference and guides — lives at cpomdp.inferogenesis.com.
Example
Four bacilli seeking food in the same world — the continuous-state answer to pymdp's mouse-seeking-cheese, now with the epistemic term v0.3 adds. Each body sits at its true hidden state; the orange + is where it believes it is (belief.mean); the ellipse is its uncertainty (belief.cov); the star is the food (the goal). A beacon marks where the sensor is sharp, so visiting it collapses the agent's uncertainty. The four differ in one number only — the goal precision Λ each is built with (ObservationGoal(precision=…)). They all minimise the same Expected Free Energy G = pragmatic − epistemic; because the pragmatic (goal) term scales with Λ while the epistemic (information) term doesn't, Λ alone tips the balance: classic LQR (no epistemic term) beelines to the food; a sharp Λ barely deflects; a balanced Λ detours to the beacon to localise, then heads to the food; a weak Λ never leaves the beacon. One real knob — the precision you'd actually pass — four behaviours.
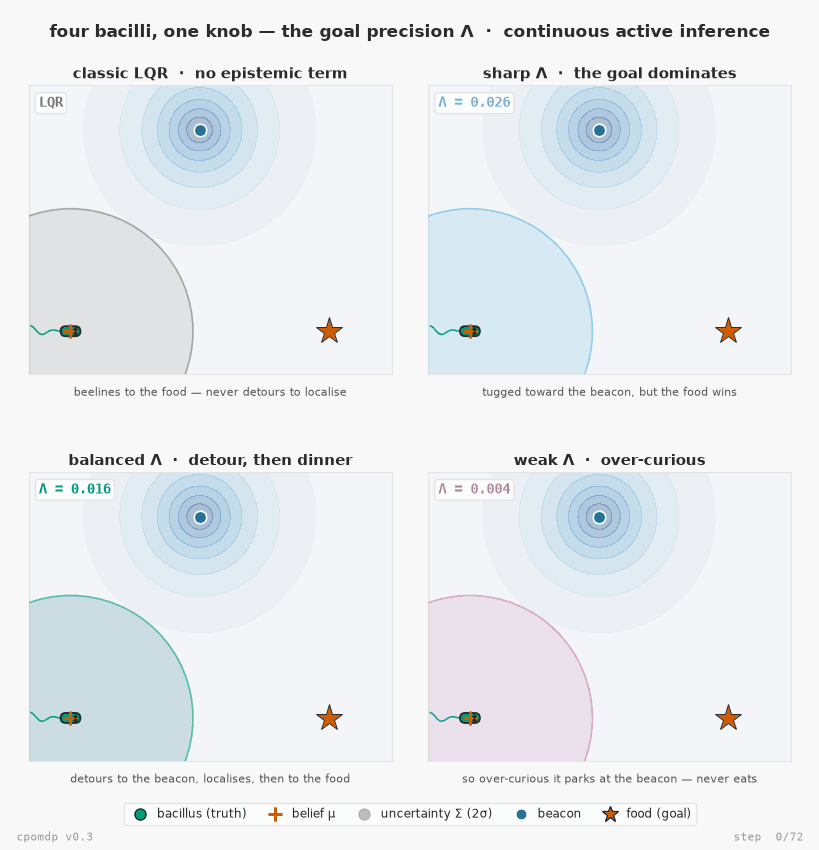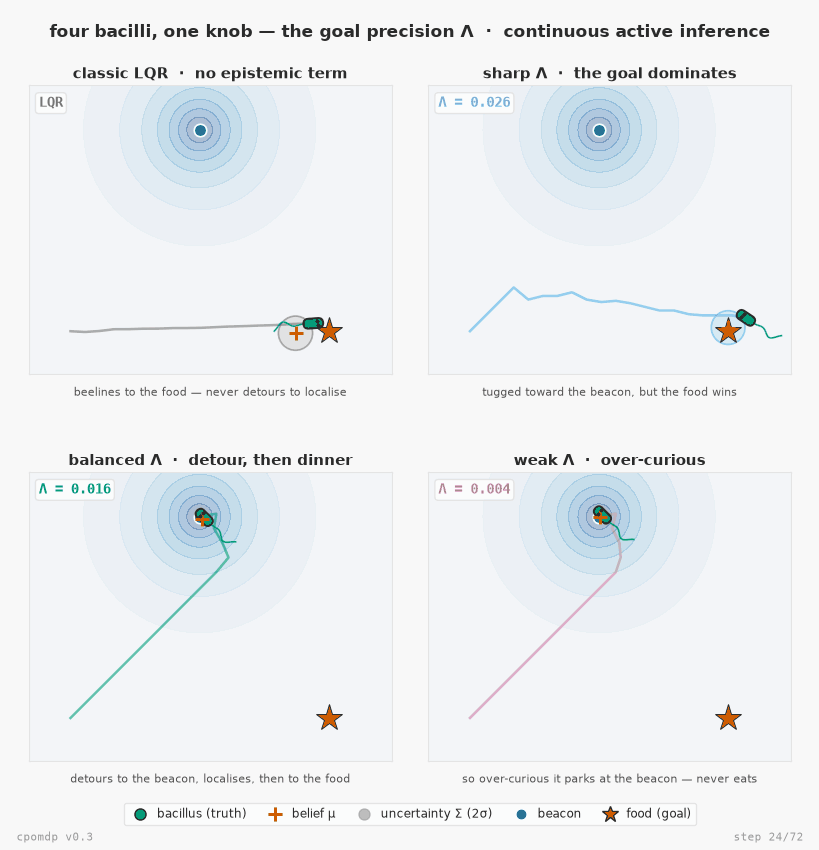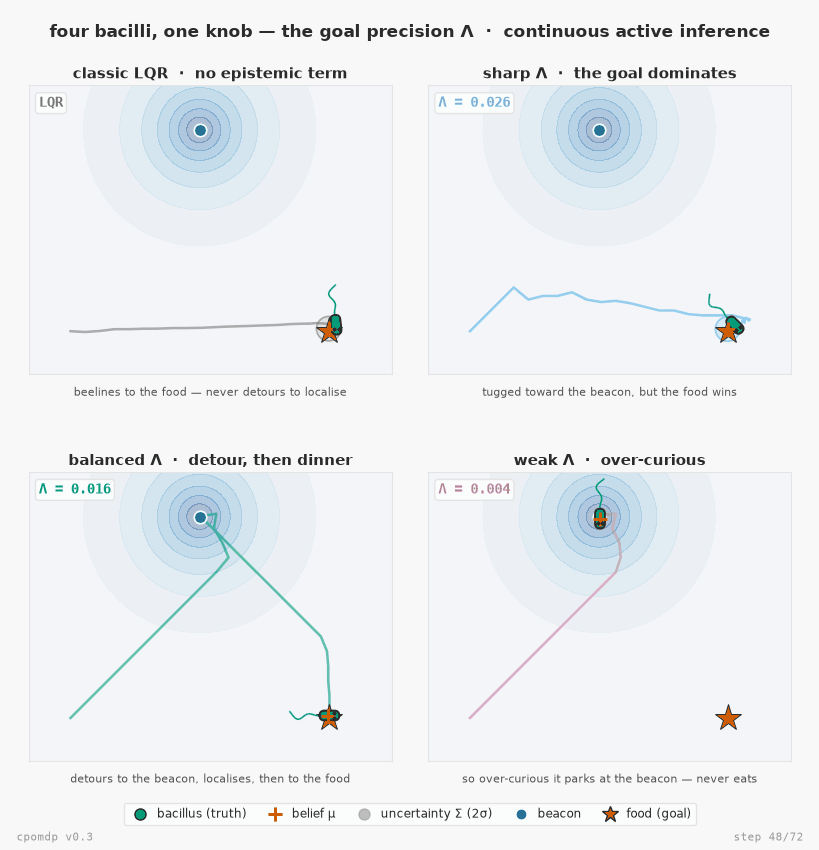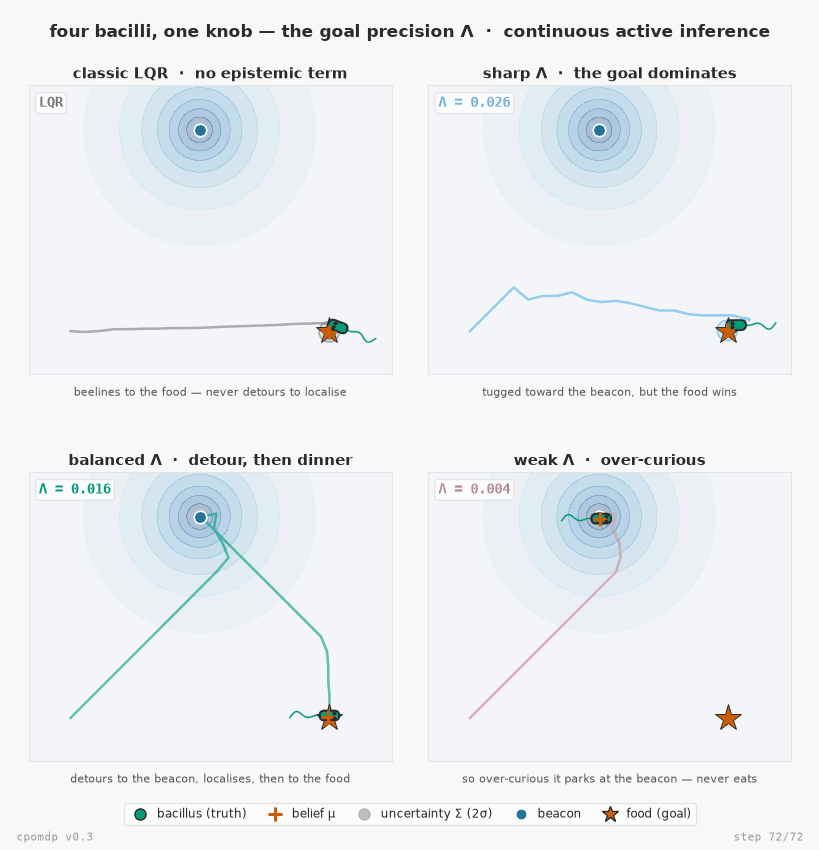
Reproduce it with examples/bacillus_seeking_food.py (pip install "cpomdp[examples]"). More — including the original v0.2 single-bacillus demo — in the examples gallery.
Install
pip install cpomdp
Or the latest from source:
pip install git+https://github.com/inferogenesis/cpomdp
That's all you need for normal use. There's also an optional RxInfer (Julia) backend that the test suite leans on as a correctness oracle. You almost certainly don't need it, but if you want it:
pip install "cpomdp[rxinfer]"
It pulls in a Julia bridge and bootstraps itself the first time you use it.
Quickstart
Here's an agent steering a point mass to a target. It can push the mass and it can see where the mass is, but it never sees the velocity. The filter has to work that out from how the position moves.
import jax.numpy as jnp
from cpomdp import Agent, Belief, LinearGaussianModel, StateGoal
# State is [position, velocity]. A push changes velocity, velocity carries
# position along, and we only ever observe position (through a noisy sensor).
dt = 0.1
model = LinearGaussianModel(
dynamics=[[1, dt], [0, 1]], # velocity carries position along
control=[[0], [dt]], # a push nudges velocity
sensor_model=[[1, 0]], # we observe position only
dynamics_noise=jnp.eye(2) * 1e-6,
sensor_noise=[[1e-2]],
prior=Belief(mean=[0, 0], cov=jnp.eye(2)),
)
# Tell it where to go: sit still at position 1.
agent = Agent(model, StateGoal([1.0, 0.0]))
true_state = jnp.array([0.0, 0.0])
for _ in range(100):
obs = model.sensor_model @ true_state # what the agent gets to see
agent.infer_states(obs) # perceive
action = agent.sample_action() # act
true_state = model.dynamics @ true_state + model.control @ action
print(jnp.round(agent.belief.mean, 3)) # ≈ [1, 0]
Run that and the belief lands on [1, 0]. The agent worked out it was at position 1 and sitting still, which is exactly where we asked it to go, and it did it without ever seeing the velocity it had to control.
The pymdp parallel
If you've used pymdp, the loop is the same and most of the names are too. Four carry over verbatim:
Agent·qs·infer_states·sample_action
(qs is a read-only alias for belief, cpomdp's canonical name — so agent.qs and agent.belief are the same posterior. Use whichever your fingers reach for.)
Only two things are spelled differently:
| pymdp | cpomdp | what it is |
|---|---|---|
C |
StateGoal / ObservationGoal |
the goal you pursue, and how sharply |
D |
model.prior |
belief before you've seen anything |
One honest difference in behaviour. sample_action here is deterministic, not a sample from a policy posterior. For a linear-Gaussian sensor the action that minimises expected free energy turns out to be exactly the LQR optimum, so there's a single best action and that's what comes back. Same loop, exact answer. The reasoning is in DECISIONS.md (ADR-003) if you want it.
Just want to track, not act?
A model with no control matrix is a pure tracker. Drop the goal and infer_states still folds in observations and sharpens the belief, while sample_action stops you — there's nothing to steer toward, and nothing to steer with.
tracker = LinearGaussianModel( # no control matrix -> pure tracking
dynamics=[[1, dt], [0, 1]],
sensor_model=[[1, 0]],
dynamics_noise=jnp.eye(2) * 1e-6,
sensor_noise=[[1e-2]],
prior=Belief(mean=[0, 0], cov=jnp.eye(2)),
)
agent = Agent(tracker) # no objective
agent.infer_states([0.5]) # perceiving is fine
agent.sample_action() # ValueError: this Agent has no objective ...
What it handles
cpomdp handles linear-Gaussian models end to end — and, as of v0.3, a little past the "linear-Gaussian" label. The mean dynamics and observations are linear and the noise is Gaussian, so perception is exact Kalman filtering, no approximation. For action you get both steady-state LQR (reach a target state) and Expected Free Energy selection (seek information) — the epistemic, information-seeking behaviour that arrived in v0.3.
What v0.3 added beyond the fixed linear-Gaussian model is state-dependence in the noise. The mean stays linear, but:
- state-dependent sensing
R(x)— the observation noise can vary with the state, so some places see more sharply than others (the beacon in the example above); - state-dependent process noise
Q(x)— the dynamics can diffuse more in some states than others; - an H-step planning horizon for EFE selection;
- an optional declarable model-structure layer.
It's the state-dependent noise that gives the agent a reason to seek information: when sensing is sharper somewhere, going there is worth something. The mean is still linear, though — genuinely nonlinear sensors (a curved g(x) that needs a second-order moment match) are the next step, not here yet.
Swappable backends
You can swap the inference engine if you want to. KalmanBackend is the default and does the real work; RxInferBackend re-derives the same answers through Julia and exists mainly so the fast path has something independent to check itself against. Both sit behind the InferenceBackend protocol, so you can write your own.
Status
Still pre-1.0: v0.3 aims to secure the public API, however if you have a request or suggest to make this front-facing API more usual please open an Github issue, Im happy to listen. Until 1.0 a minor version is where breaking changes can land.
Development
I designed and built cpomdp — the architecture, the conditionally-linear-Gaussian formulation, the API, and every decision in DECISIONS.md are mine. The design draws on my day-to-day work as a full-time software engineer and on hands-on expertise integrating and developing large machine-learning models at scale using event-driven microservice architecture.
I used an AI coding assistant (Claude Opus-4.8) as a tool under close review: to draft docstrings, probe for edge cases and candidate bugs, and expand the test suite, including adversarial ones. Everything it produced I read, checked, and approved before it landed. None of it is taken on trust — the numbers are validated independently against the RxInfer (Julia) and analytic NumPy oracles described above. Correctness rests on those checks, not on the tool that helped write the code.
Contributions
If you would like to contribute either your dev time or help steer the direction of the toolbox, please add a Github issue or discussion thread. I am monitoring this repository closely and would love to collaborate.
If you notice a better method in something I've already done or are just curious and want to chat I am more than happy to talk through my decision processes. I intend to blog my construction of cpomdp provided it doesn't interfere with developing it.
Acknowledgements
Thanks to Kevin Backhouse (Postgraduate Researcher in Cognitive Neuroscience, Durham University) for guidance on the active-inference formulation, collaboration on related discrete generative-model projects, and for being a consistent sounding board throughout the design of this work.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file cpomdp-0.3.0.tar.gz.
File metadata
- Download URL: cpomdp-0.3.0.tar.gz
- Upload date:
- Size: 6.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c4f06bc52ee7bac76941152d5f610f327f8ad3382d51fac93e78ebc4fc0fe4c
|
|
| MD5 |
2c16e21937b0b2f076b574733e90ec53
|
|
| BLAKE2b-256 |
3dbfadfa2c1faa95f9e72ab70daf6c23c7004e720aff5082a36a6340998bfd13
|
Provenance
The following attestation bundles were made for cpomdp-0.3.0.tar.gz:
Publisher:
publish.yml on inferogenesis/cpomdp
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
cpomdp-0.3.0.tar.gz -
Subject digest:
8c4f06bc52ee7bac76941152d5f610f327f8ad3382d51fac93e78ebc4fc0fe4c - Sigstore transparency entry: 1908447063
- Sigstore integration time:
-
Permalink:
inferogenesis/cpomdp@96ff12c05b2b9b5ebddee3acb419bd1a54e6a067 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/inferogenesis
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@96ff12c05b2b9b5ebddee3acb419bd1a54e6a067 -
Trigger Event:
release
-
Statement type:
File details
Details for the file cpomdp-0.3.0-py3-none-any.whl.
File metadata
- Download URL: cpomdp-0.3.0-py3-none-any.whl
- Upload date:
- Size: 48.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c36492ecc08976045c28b9f8a9cc76ec1b842cbb070c27ffb3190cf4deda9600
|
|
| MD5 |
5016b985899a4fbadd0f4b35143a8bfb
|
|
| BLAKE2b-256 |
7424abab17537aec2d39e8dc6df087c4144a38d2af202662bd078c3578b3a147
|
Provenance
The following attestation bundles were made for cpomdp-0.3.0-py3-none-any.whl:
Publisher:
publish.yml on inferogenesis/cpomdp
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
cpomdp-0.3.0-py3-none-any.whl -
Subject digest:
c36492ecc08976045c28b9f8a9cc76ec1b842cbb070c27ffb3190cf4deda9600 - Sigstore transparency entry: 1908447109
- Sigstore integration time:
-
Permalink:
inferogenesis/cpomdp@96ff12c05b2b9b5ebddee3acb419bd1a54e6a067 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/inferogenesis
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@96ff12c05b2b9b5ebddee3acb419bd1a54e6a067 -
Trigger Event:
release
-
Statement type:







