Framework for crawling

Project description
About
Main objective is to secure fast deployment of crawler system that will help you setup all that you need to get started with data mining interactively over cmd/terminal. Concept is based on long working experience and mistakes that have been learned over the years in data mining and database arhitecture. It could save you a lot of time and effort using this framework. Currently works on Win OS.
Installation
Most important thing is that you have python 3 installed on your machine.
With virtual environment (recommended)
To be able to make virtual environment you will need to pip3.7 install virtualenv
Location of your virtual environment on WinOS shoud be C:\Users\YourUsername\Envs
Then create virtual environment py -3.7 -m virtualenv Envs/crawler_framework
By default now your virtual environment should be active if it isn't activate your virtual
environment by writing workon crawler_framework
Now you can install library pip install crawler_framework
Without virtual environment
Just open cmd and write pip3.7 install crawler_framework. This option is ok if you have only one version
of python installed on your system. But if you have more python version installed and you decide to go with this
option you will have to finish some additional question's during configuration of crawler framework.
Like that it will be ensured that everything works ether way.
Setup
Database configuration
Before we can deploy anything we must setup connection strings for one or more database servers that we are going to use. Currently supported are PostgreSQL, Oracle and Microsoft SQL Server.
It is recommended to create database on your server that will only be used by framework.
Open cmd/terminal and write config.py. If everything goes well you should see this options below.
It is possible that program asks for some additional information if you have more than one python interpreter
installed on your machine and you did not use virtual environment. But it will be required only once.

Create all database connection's that you think you will use, from database where you will deploy crawler_framework to database where you will store data etc. by selecting option number 1 and then database option number one.
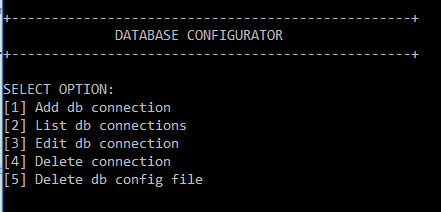
Hints
Microsoft SQL Server
If you are using default option be sure to define in ODBC Data sources administrator dsn name that will have
default database that will be used for framework. If you are using pymssql you will define server_ip, port and database
during database configuration stage.
Deploying framework
Open cmd/terminal and write config.py. Select option 2 (Deploy framework) and then select option from
the list of connections you created that is going to be used for deployment. This will deploy table structure in selected database
on selected server connection. In our case we will deploy it on PostgreSQL localhost server.
Setup tor expert bundle
You can skip this if you are not planing to use tor as your proxy provider but only public proxies.
Open cmd/terminal and write config.py. Select option 4 (Tor setup). Then from to setup option select option 1(Install),
this will automatically install tor expert bundle with all necessary directories and subdirectories.
If you have already have installed and then changed default options then this will reset those options back to default just like some kind of reinstall.
Setup option 2 (Tor options) allows you to change some of defaults when constructing our tor network such as how many tor instances should run in same time or how long time must pass before changing and identity of tor instance.
Starting proxy server
Proxy server is multifunctional program that acquires new proxies(crawlers), test proxies, creates tor network etc.
Open cmd/terminal and write config.py. Select option 3 (Run proxy server).
Suboptions
From suboptions you can select suboption 0 to run all both public proxy and tor service or suboption 1 to run only public proxy gatherer or
suboption 2 to run only tor service.
Suboption 2 is great if you want to run tor service on another pc inside your network.
By doing so you can increase number of tor that will run but it will not hog your local CPU and RAM.
All data will be saved in database where you have deployed crawler_framewok.
If you didn't made deployment then this will probably end with exceptions.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file crawler_framework-0.3.4.tar.gz.
File metadata
- Download URL: crawler_framework-0.3.4.tar.gz
- Upload date:
- Size: 41.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.18.4 setuptools/40.7.3 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.6.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
88a4bfea715006dfcbcf626b61385d79d33f6c4c4871fbcba8ccfcdb9f4506f2
|
|
| MD5 |
d735ba093e9c2ee18abc03e7a137c23a
|
|
| BLAKE2b-256 |
c1ddce77ec2a41c3ae4655faebf7211adc3a3447efb437119fa2564ce575942a
|
File details
Details for the file crawler_framework-0.3.4-py3-none-any.whl.
File metadata
- Download URL: crawler_framework-0.3.4-py3-none-any.whl
- Upload date:
- Size: 63.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.18.4 setuptools/40.7.3 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.6.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c2a7396c0af7027bc8671e79136fc07e394df75d32a4fa968e0b21a254841a71
|
|
| MD5 |
8859ae1939ccf98e0a4699aad4570a76
|
|
| BLAKE2b-256 |
3953b882d77a79fcf723f6a40f1cf34243a66125cc474544c0872c4215e1ed32
|







