Conformal classifiers, regressors, and predictive systems (crepes)

Project description

crepes is a Python package for conformal prediction that implements conformal classifiers,
regressors, and predictive systems on top of any standard classifier
and regressor, turning the original predictions into
well-calibrated p-values and cumulative distribution functions, or
prediction sets and intervals with coverage guarantees.
The crepes package implements standard and Mondrian conformal
classifiers as well as standard, normalized and Mondrian conformal
regressors and predictive systems. While the package allows you to use
your own functions to compute difficulty estimates, non-conformity
scores and Mondrian categories, there is also a separate module,
called crepes.extras, which provides some standard options for
these. For testing the underlying assumption of exchangeability,
you may use the classes in the module crepes.martingales.
Installation
From PyPI
pip install crepes
From conda-forge
conda install conda-forge::crepes
Documentation
For the complete documentation, see crepes.readthedocs.io.
Quickstart
Let us illustrate how we may use crepes to generate and apply
conformal classifiers with a dataset from
www.openml.org, which we first split into a
training and a test set using train_test_split from
sklearn, and then further split the
training set into a proper training set and a calibration set:
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
dataset = fetch_openml(name="qsar-biodeg", parser="auto")
X = dataset.data.values.astype(float)
y = dataset.target.values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
X_prop_train, X_cal, y_prop_train, y_cal = train_test_split(X_train, y_train,
test_size=0.25)
We now "wrap" a random forest classifier, fit it to the proper
training set, and fit a standard conformal classifier through the
calibrate method:
from crepes import WrapClassifier
from sklearn.ensemble import RandomForestClassifier
rf = WrapClassifier(RandomForestClassifier(n_jobs=-1))
rf.fit(X_prop_train, y_prop_train)
rf.calibrate(X_cal, y_cal)
We may now produce p-values for the test set (an array with as many columns as there are classes):
rf.predict_p(X_test)
array([[0.00427104, 0.74842304],
[0.07874355, 0.2950549 ],
[0.50529983, 0.01557963],
...,
[0.8413356 , 0.00201167],
[0.84402215, 0.00654927],
[0.29601955, 0.07766093]])
We can also get prediction sets, here at the 99% confidence level:
rf.predict_set(X_test, confidence=0.99)
[['2'],
['1', '2'],
['1', '2'],
...,
['1'],
['1'],
['1', '2']]
If we prefer the prediction sets to be represented by binary vectors indicating presence (1) or absence (0) of the class labels that correspond to the columns, we can request this by:
rf.predict_set(X_test, labels=False, confidence=0.99)
array([[0, 1],
[1, 1],
[1, 1],
...,
[1, 0],
[1, 0],
[1, 1]])
Since we have access to the true class labels, we can evaluate the conformal classifier (here using all available metrics which is the default), at the 99% confidence level:
rf.evaluate(X_test, y_test, confidence=0.99)
{'error': 0.007575757575757569,
'avg_c': 1.6136363636363635,
'one_c': 0.38636363636363635,
'empty': 0.0,
'ks_test': 0.0030978768439862566,
'time_fit': 9.5367431640625e-07,
'time_evaluate': 0.024116039276123047}
To control the error level across different groups of objects of
interest, we may use so-called Mondrian conformal classifiers. A
Mondrian conformal classifier is formed by providing a function or a
MondrianCategorizer (defined in crepes.extras) as an additional
argument, named mc, for the calibrate method.
For illustration, we will use the predicted labels of the underlying model to form the categories. Note that the prediction sets are generated for the test objects using the same categorization (under the hood).
rf_mond = WrapClassifier(rf.learner)
rf_mond.calibrate(X_cal, y_cal, mc=rf_mond.predict)
rf_mond.predict_set(X_test)
[['2'],
['1', '2'],
['1'],
...,
['1'],
['1'],
['1', '2']]
The class-conditional conformal classifier is a special type of Mondrian
conformal classifier, for which the categories are formed by the true labels;
we can generate one by setting class_cond=True in the call to calibrate
rf_classcond = WrapClassifier(rf.learner)
rf_classcond.calibrate(X_cal, y_cal, class_cond=True)
rf_classcond.evaluate(X_test, y_test, confidence=0.99)
{'error': 0.0018939393939394478,
'avg_c': 1.740530303030303,
'one_c': 0.25946969696969696,
'empty': 0.0,
'ks_test': 0.11458837583733483,
'time_fit': 7.152557373046875e-07,
'time_evaluate': 0.06147575378417969}
When employing an inductive conformal predictor, the predicted
p-values (and consequently the errors made) for a test set are not
independent. Semi-online conformal predictors can however make them
independent by updating the calibration set immediately after each
prediction (assuming that the true label is then available). We can
turn the conformal classifiers into semi-online conformal classifiers
by enabling online calibration, i.e., setting online=True when calling
the above methods, while also providing the true labels, e.g.,
rf_classcond.predict_p(X_test, y_test, online=True)
array([[8.13837566e-05, 8.86436603e-01],
[6.60518590e-02, 4.02350293e-01],
[4.28646783e-01, 4.29930890e-02],
...,
[7.05118942e-01, 9.45056960e-03],
[7.27003479e-01, 1.27347189e-02],
[1.76403756e-01, 1.21434924e-01]])
Similarly, we can evaluate the conformal classifier while using online calibration:
rf_classcond.evaluate(X_test, y_test, confidence=0.99, online=True)
{'error': 0.007575757575757569,
'avg_c': 1.6117424242424243,
'one_c': 0.38825757575757575,
'empty': 0.0,
'ks_test': 0.14097384777782784,
'time_fit': 1.9073486328125e-06,
'time_evaluate': 0.05298352241516113}
Let us also illustrate how crepes can be used to generate conformal
regressors and predictive systems. Again, we import a dataset from
www.openml.org, which we split into a
training and a test set and then further split the training set into a
proper training set and a calibration set:
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
dataset = fetch_openml(name="house_sales", version=3, parser="auto")
X = dataset.data.values.astype(float)
y = dataset.target.values.astype(float)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
X_prop_train, X_cal, y_prop_train, y_cal = train_test_split(X_train, y_train,
test_size=0.25)
Let us now "wrap" a RandomForestRegressor from
sklearn using the class WrapRegressor
from crepes and fit it (in the usual way) to the proper training
set:
from sklearn.ensemble import RandomForestRegressor
from crepes import WrapRegressor
rf = WrapRegressor(RandomForestRegressor())
rf.fit(X_prop_train, y_prop_train)
We may now fit a conformal regressor using the calibration set through
the calibrate method:
rf.calibrate(X_cal, y_cal)
The conformal regressor can now produce prediction intervals for the test set, here using a confidence level of 99%:
rf.predict_int(X_test, confidence=0.99)
array([[1938866.06, 3146372.54],
[ 225335.1 , 1432841.58],
[-403305.49, 804200.99],
...,
[ 443742.33, 1651248.81],
[-343684.48, 863822. ],
[-153629.93, 1053876.55]])
The output is a NumPy array with a row for each test instance, and where the two columns specify the lower and upper bound of each prediction interval.
We may request that the intervals are cut to exclude impossible values, in this case below 0, and if we also rely on the default confidence level (0.95), the output intervals will be a bit tighter:
rf.predict_int(X_test, y_min=0)
array([[2302049.84, 2783188.76],
[ 588518.88, 1069657.8 ],
[ 0. , 441017.21],
...,
[ 806926.11, 1288065.03],
[ 19499.3 , 500638.22],
[ 209553.85, 690692.77]])
The above intervals are not normalized, i.e., they are all of the same size (at least before they are cut). We could make them more informative through normalization using difficulty estimates; objects considered more difficult will be assigned wider intervals.
We will use a DifficultyEstimator from the crepes.extras module
for this purpose. Here we estimate the difficulty by the standard
deviation of the target of the k (default k=25) nearest neighbors in
the proper training set to each object in the calibration set. A small
value (beta) is added to the estimates, which may be given through an
argument to the function; below we just use the default, i.e.,
beta=0.01.
We first fit the difficulty estimator and then calibrate the conformal regressor, using the calibration objects and labels together the difficulty estimator:
from crepes.extras import DifficultyEstimator
de = DifficultyEstimator()
de.fit(X_prop_train, y=y_prop_train)
rf.calibrate(X_cal, y_cal, de=de)
To obtain prediction intervals, we just have to provide test objects
to the predict_int method, as the difficulty estimates will be
computed by the incorporated difficulty estimator:
rf.predict_int(X_test, y_min=0)
array([[1769594.36212355, 3315644.23787645],
[ 693827.99796647, 964348.68203353],
[ 124886.97469338, 276008.52530662],
...,
[ 661373.45043166, 1433617.68956833],
[ 178769.2939384 , 341368.2260616 ],
[ 222837.12801117, 677409.49198883]])
Depending on the employed difficulty estimator, the normalized intervals may sometimes be unreasonably large, in the sense that they may be several times larger than any previously observed error. Moreover, if the difficulty estimator is uninformative, e.g., completely random, the varying interval sizes may give a false impression of that we can expect lower prediction errors for instances with tighter intervals. Ideally, a difficulty estimator providing little or no information on the expected error should instead lead to more uniformly distributed interval sizes.
A Mondrian conformal regressor can be used to address these problems,
by dividing the object space into non-overlapping so-called Mondrian
categories, and forming a (standard) conformal regressor for each
category. We may form a Mondrian conformal regressor by providing a
function or a MondrianCategorizer (defined in crepes.extras) as an
additional argument, named mc, for the calibrate method.
Here we employ a MondrianCategorizer; it may be fitted in several
different ways, and below we show how to form categories by binning of
the difficulty estimates into 20 bins, using the difficulty estimator
fitted above.
from crepes.extras import MondrianCategorizer
mc_diff = MondrianCategorizer()
mc_diff.fit(X_cal, de=de, no_bins=20)
rf.calibrate(X_cal, y_cal, mc=mc_diff)
When making predictions, the test objects will be assigned to Mondrian categories
according to the incorporated MondrianCategorizer (or labeling function):
rf.predict_int(X_test, y_min=0)
array([[1152528.9 , 3932709.7 ],
[ 692366.75, 965809.93],
[ 124254.81, 276640.69],
...,
[ 622939.57, 1472051.57],
[ 155346.82, 364790.7 ],
[ 239474.31, 660772.31]])
Similarly to semi-online conformal classifiers, we may enable online calibration
also for conformal regressors; this is again done by setting online=True when
calling any of the applicable methods, while also providing the true labels, e.g.,
rf.predict_p(X_test, y_test, online=True)
array([0.09369225, 0.52548032, 0.49992477, ..., 0.72979714, 0.87495964,
0.58352253])
We can easily switch from conformal regressors to conformal predictive systems. The latter produce cumulative distribution functions (conformal predictive distributions). From these we can generate prediction intervals, but we can also obtain percentiles, calibrated point predictions, as well as p-values for given target values. Let us see how we can go ahead to do that.
Well, there is only one thing above that changes: just provide
cps=True to the calibrate method.
We can, for example, form normalized Mondrian conformal predictive
systems, by providing both a Mondrian categorizer and difficulty estimator
to the calibrate method. Here we will consider Mondrian categories formed
from binning the point predictions:
mc_pred = MondrianCategorizer()
mc_pred.fit(X_cal, f=rf.predict, no_bins=5)
rf.calibrate(X_cal, y_cal, de=de, mc=mc_pred, cps=True)
We can now make predictions with the conformal predictive system,
through several different methods, e.g., predict_percentiles:
rf.predict_percentiles(X_test, higher_percentiles=[90, 95, 99])
array([[3120432.14791764, 3403976.16608241, 3952384.13595105],
[ 930191.36994287, 979804.59585495, 1075762.49571536],
[ 236278.82580469, 253387.66592079, 329933.49293406],
...,
[1336110.21956702, 1477739.04927264, 1751666.10820498],
[ 298621.13482031, 317029.35735016, 399388.68783836],
[ 564574.75363948, 615226.06727944, 762212.9912238 ]])
Similarly to semi-online conformal classifiers and regressors, we can enable online calibration also for conformal predictive systems; here we generate prediction intervals at the default (95%) confidence level:
rf.predict_int(X_test, y_test, y_min=0, online=True)
array([[1719676.80439219, 3707173.76806116],
[ 684289.27240227, 1032856.71531186],
[ 127189.61835749, 274385.59426486],
...,
[ 630347.70469164, 1594876.58130005],
[ 167399.51044545, 337513.60197203],
[ 232815.51352497, 641580.14787679]])
We may also obtain the full conformal predictive distribution for each test instance, as defined by the threshold values:
rf.predict_cpds(X_test)
For a Mondrian conformal predictive system (or any semi-online conformal predictive system), the output is a vector containing one CPD per test instance, while for a standard or normalized conformal predictive system (for which online calibration is not enabled), the output is a 2-dimensional array.
The resulting vector of vectors is not displayed here, but we instead provide a plot for the CPD of a random test instance:
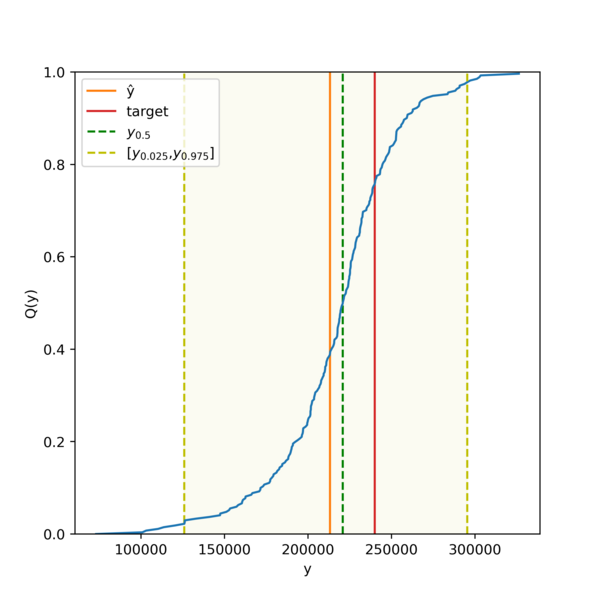
We may also test the exchangeability assumption using conformal test martingales. Assume that we have obtained p-values using a semi-online conformal predictor, e.g.,
p_values = rf.predict_p(X_test, y_test, online=True)
We can now test if the p-values are distributed independently and uniformly over [0, 1] using any of the
available conformal test martingale algorithms in crepes.martingales. If the exchangeability assumption
holds then the probability of observing a martingale value exceeding c is less than or equal to 1/c.
This means that probability of incorrectly rejecting the assumption is bounded by 1/c. We here show
how to obtain martingale values for the above p-values using Simple Jumper:
from crepes.martingales import SimpleJumper
martingale_values = SimpleJumper().apply(p_values)
We may also ask for the lowest index for which the martingale value exceeds a specified threshold:
SimpleJumper().apply(np.sort(p_values), c=100)
Since the p-values are sorted in the above example, the conformal test martingale will detect a violation of the exchangeability assumption early on and return a low index. If instead the original (unsorted) p-values are provided, it is very likely that the conformal test martingale will not detect any data drift and will just return the length of the p-value vector.
Examples
For additional examples of how to use the package and module, see the documentation. Examples on how to wrap learners to obtain conformal predictors are given in this Jupyter notebook , while this Jupyter notebook shows how to obtain conformal predictors that are decoupled from the learners. For examples on conformal test martingales, you may consult this Jupyter notebook.
You may also take a look at some tutorial slides and the accompanying Jupyter notebook.
Citing crepes
You are welcome to cite the following paper:
Boström, H. 2024. Conformal Prediction in Python with crepes. Proceedings of the 13th Symposium on Conformal and Probabilistic Prediction with Applications, PMLR 230:236-249 Link
Bibtex entry:
@inproceedings{bostrom2024,
title={Conformal Prediction in Python with crepes},
author={Bostr{\"o}m, Henrik},
booktitle={Proc. of the 13th Symposium on Conformal and Probabilistic Prediction with Applications},
pages={236--249},
year={2024},
organization={PMLR}
}
An early version of the package was described in:
Boström, H., 2022. crepes: a Python Package for Generating Conformal Regressors and Predictive Systems. Proceedings of the 11th Symposium on Conformal and Probabilistic Prediction with Applications, PMLR 179:24-41 Link
Bibtex entry:
@inproceedings{bostrom2022,
title={crepes: a Python Package for Generating Conformal Regressors and Predictive Systems},
author={Bostr{\"o}m, Henrik},
booktitle={Proc. of the 11th Symposium on Conformal and Probabilistic Prediction with Applications},
pages={24--41},
year={2022},
organization={PMLR}
}
References
[1] Vovk, V., Gammerman, A. and Shafer, G., 2022. Algorithmic learning in a random world. 2nd edition. Springer Link
[2] Papadopoulos, H., Proedrou, K., Vovk, V. and Gammerman, A., 2002. Inductive confidence machines for regression. European Conference on Machine Learning, pp. 345-356. Link
[3] Johansson, U., Boström, H., Löfström, T. and Linusson, H., 2014. Regression conformal prediction with random forests. Machine learning, 97(1-2), pp. 155-176. Link
[4] Boström, H., Linusson, H., Löfström, T. and Johansson, U., 2017. Accelerating difficulty estimation for conformal regression forests. Annals of Mathematics and Artificial Intelligence, 81(1-2), pp.125-144. Link
[5] Boström, H. and Johansson, U., 2020. Mondrian conformal regressors. In Conformal and Probabilistic Prediction and Applications. PMLR, 128, pp. 114-133. Link
[6] Vovk, V., Petej, I., Nouretdinov, I., Manokhin, V. and Gammerman, A., 2020. Computationally efficient versions of conformal predictive distributions. Neurocomputing, 397, pp.292-308. Link
[7] Boström, H., Johansson, U. and Löfström, T., 2021. Mondrian conformal predictive distributions. In Conformal and Probabilistic Prediction and Applications. PMLR, 152, pp. 24-38. Link
[8] Vovk, V., 2022. Universal predictive systems. Pattern Recognition. 126: pp. 108536 Link
Author: Henrik Boström (bostromh@kth.se) Copyright 2026 Henrik Boström License: BSD 3 clause
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file crepes-0.9.1.tar.gz.
File metadata
- Download URL: crepes-0.9.1.tar.gz
- Upload date:
- Size: 51.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
14255bfeef3d3cb76fefa78f9cef1d05ecf106dfae6f2bf76096eb7f5524c099
|
|
| MD5 |
98ab771ece5f62b667043485be091647
|
|
| BLAKE2b-256 |
675c926ea5b808fd8cc8b3cdda9c90d08897340d295bf2ece2d6fa8b1c3b5012
|
File details
Details for the file crepes-0.9.1-py3-none-any.whl.
File metadata
- Download URL: crepes-0.9.1-py3-none-any.whl
- Upload date:
- Size: 44.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d1e0c4c212c72883f2be3d3b58242782040c5c40295453f561112d23deb29fd2
|
|
| MD5 |
896647f769e0e0d7809db319bec005b1
|
|
| BLAKE2b-256 |
a7d0f30abace5048356fec034784f20afe1daa84a3d40cddd7812351b2d004a1
|







