Library for computing Deterministic Acyclic Finite State Automata (DAFSA)

Project description
DAFSA





DAFSA is a library for computing Deterministic Acyclic Finite State Automata (also known as "directed acyclic word graphs", or DAWG). DAFSA are data structures derived from tries that allow to represent a set of sequences (typically character strings or n-grams) in the form of a directed acyclic graph with a single source vertex (the start symbol of all sequences) and at least one sink edge (end symbols, each pointed to by one or more sequences). In the current implementation, a trait of each node expresses whether it can be used a sink.
The primary difference between DAFSA and tries is that the latter eliminates suffix and infix redundancy, as in the example of Figure 1 (from the linked Wikipedia article) storing the set of strings "tap", "taps", "top", and "tops". Even though DAFSAs cannot be used to store precise frequency information, given that multiple paths can reach the same terminal node, they still allow to estimate the sampling frequency; being acyclic, they can also reject any sequence not included in the training. Fuzzy extensions will allow to estimate the sampling probability of unobserved sequences.
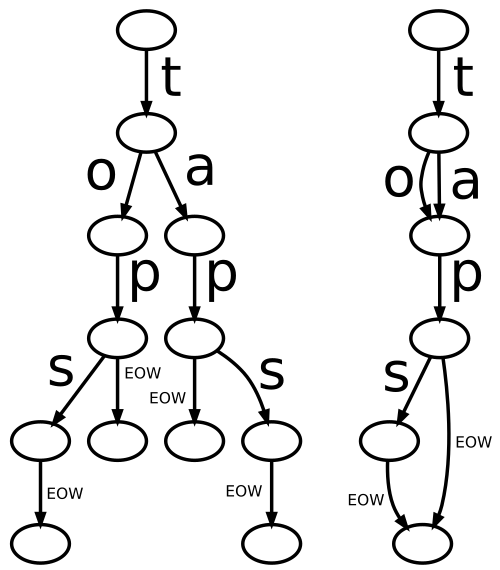
This data structure is a special case of a finite state recognizer that acts as a deterministic finite state automaton, as it recognizes all and only the sequences it was built upon. Frequently used in computer science for the space-efficient storage of sets of sequences without common compression techniques, such as dictionary or entropy types, or without probabilistic data structures, such as Bloom filters, the automata generated by this library are intended for linguistic exploration, and extend published models by allowing to approximate probability of random observation by carrying information on the weight of each graph edge.
Full documentation is available here.
Installation
In any standard Python environment, dafsa can be installed with:
pip install dafsa
How to use
The library offers a DAFSA object to compute automata, along with methods for checking a sequence acceptance and for exporting the graph. A minimal usage is shown here:
>>> import dafsa
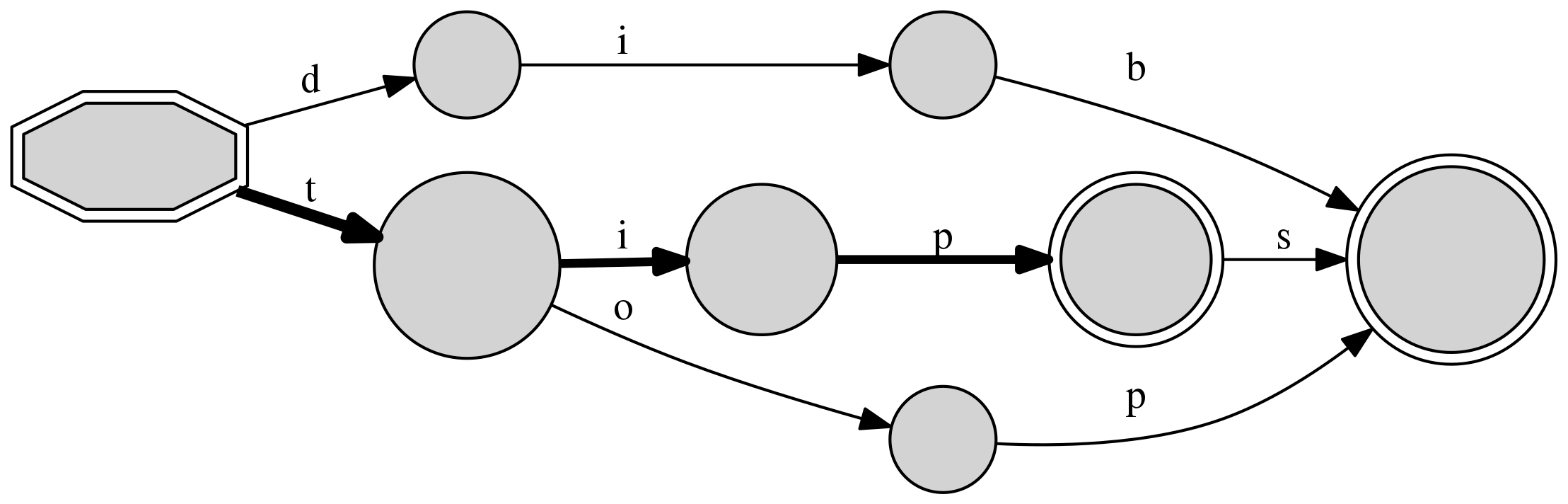
>>> d = dafsa.DAFSA(["tap", "taps", "top", "tops", "dibs"])
>>> print(d)
DAFSA with 7 nodes and 8 edges (5 sequences)
+-- #0: 0(#1:<d>/1|#5:<t>/4) [('t', 5), ('d', 1)]
+-- #1: n(#2:<i>/1) [('i', 2)]
+-- #2: n(#3:<b>/1) [('b', 3)]
+-- #3: n(#4:<s>/3) [('s', 4)]
+-- #4: F() []
+-- #5: n(#6:<a>/2|#6:<o>/2) [('o', 6), ('a', 6)]
+-- #6: n(#3:<p>/4) [('p', 3)]
Note how the resulting graph includes the 5 training sequences, with one starting node (#0) that advances with either a t (observed four times) or a d symbol (observed a single time), a subsequent node to t that only advances with a and o symbols (#1), and so on.
The visualization is much clearer with a graphical representation:
>>> d.graphviz_output("example.png")
A DAFSA object allows to check for the presence or absence of a sequence in its structure, returning a terminal node if it can find a path:
>>> d.lookup("tap")
F(#4:<s>/3)
>>> d.lookup("tops")
F()
>>> d.lookup("tapap") is None
True
>>> d.lookup("ta") is None
True
A command-line tool for reading files with lists of strings, with one string per line, is also available:
$ cat resources/dna.txt
CGCGAAA
CGCGATA
CGGAAA
CGGATA
GGATA
AATA
$ dafsa resources/dna.txt -t png -o dna.png
Which will produce the following graph:

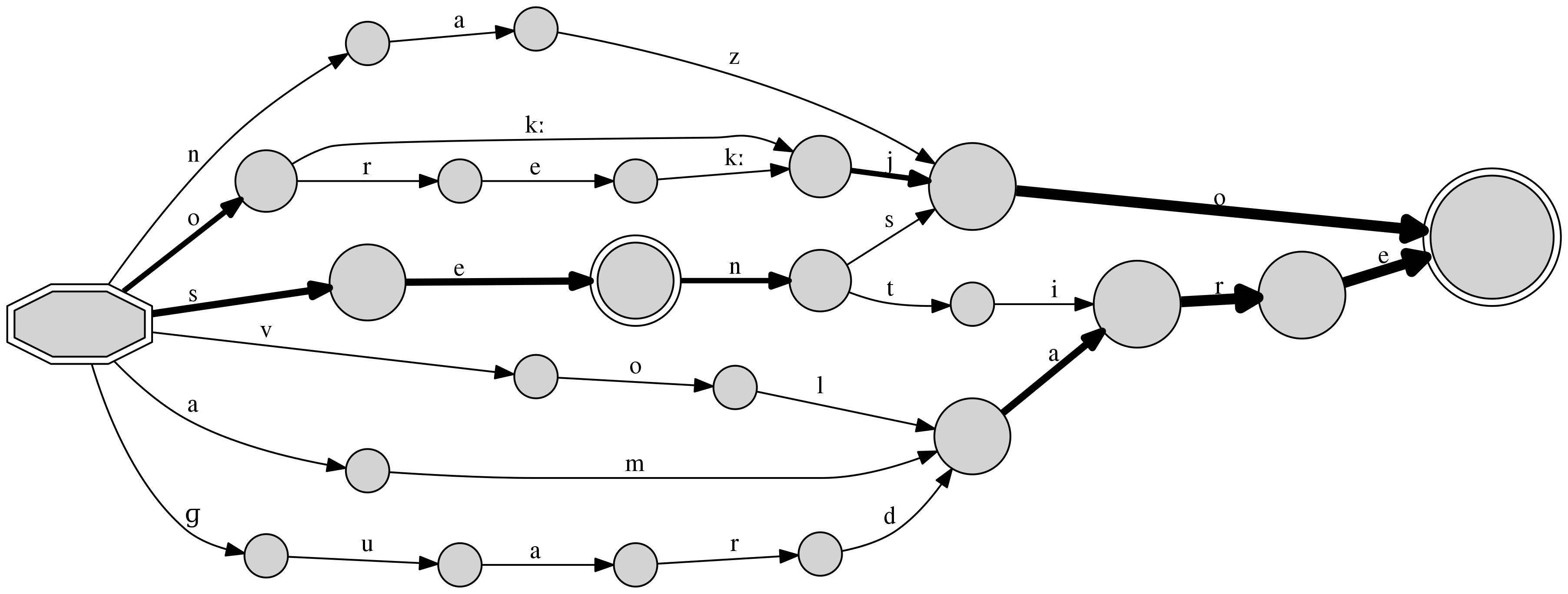
Sequences are by default processed one character at time, with each character assumed to be a single token. Pre-tokenized data can be provided to the library in the format of a Python list or tuple, or specified in source by using spaces as token delimiters:
$ cat resources/phonemes.txt
o kː j o
o r e kː j o
n a z o
s e n t i r e
s e n s o
ɡ u a r d a r e
a m a r e
v o l a r e
$ dafsa resources/phonemes.txt -t png -o phonemes.png
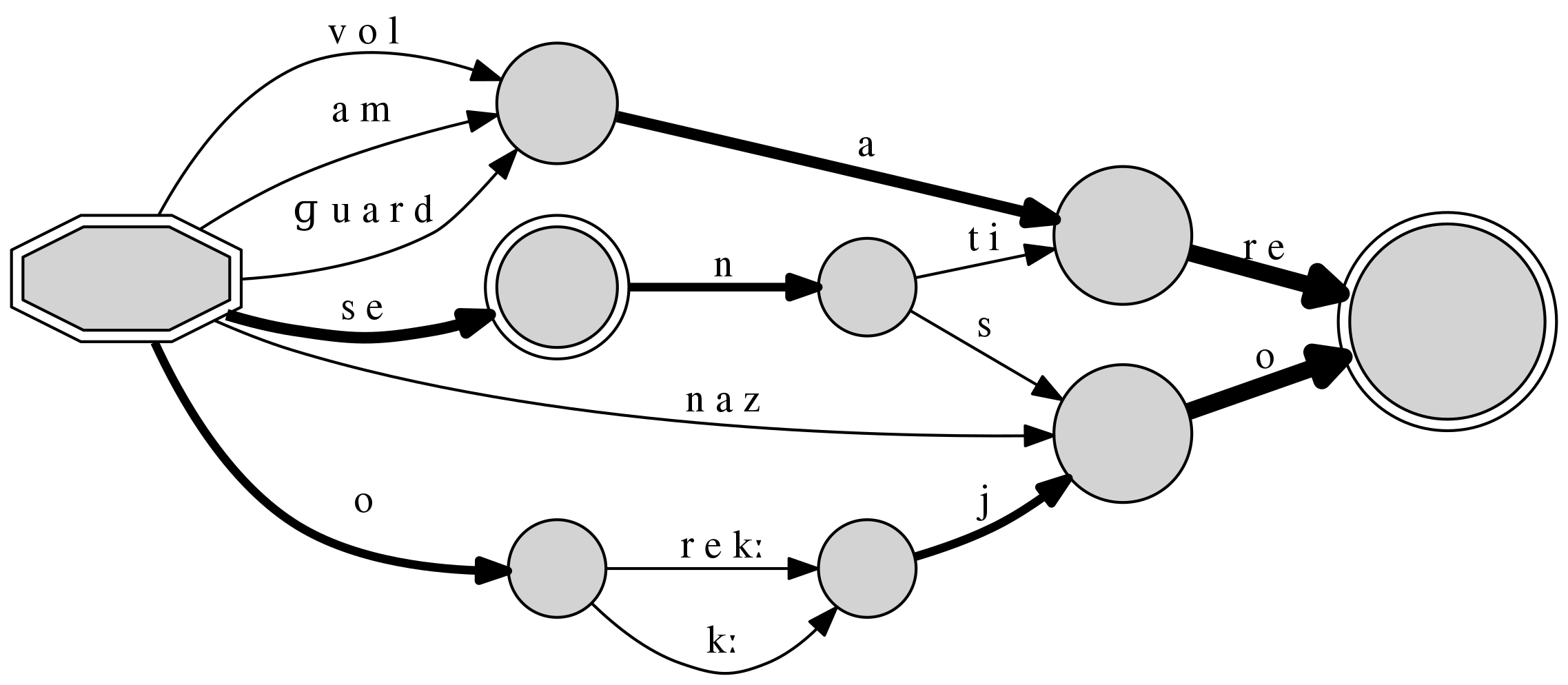
Graphs can have paths of single transitions condensed to a sole transition, as in:
Changelog
Version 0.3:
- Allow to join transitions in single sub-paths
- Allows to export a DAFSA as a
networkxgraph - Preliminary documentation at ReadTheDocs
Version 0.2.1:
- Added support for segmented data
Version 0.2:
- Added support for weighted edges and nodes
- Added DOT export and Graphviz generation
- Refined minimization method, which can be skipped if desired (resulting in a standard trie)
- Added examples in the resources, also used for test data
Version 0.1:
- First public release.
Roadmap
Version 0.4:
- Full documentation for existing code
- Consider allowing the generation of graphs with no emissions from final states (replaced with an edge to a final token)
- Consider allowing the generation of empty transitions without the usage of alignments
- Work on options for nicer graphviz output (colors, widths, etc.)
- Allow to access all options from command-line
- Consider adding GML export, perhaps even as a standard
Version 0.5:
- Profile code and make faster and less resource hungry, using multiple threads wherever possible, memoization, etc.
- Decide how (and if) to implement a
.__gt__()method for the nodes, both before and after the final minimization
Version 1.0:
- Add code from Daciuk's packages in an extra directory, along with notes on license
After 1.0:
- Preliminary generation of minimal regular expressions matching the contents of a DAFSA
- Consider the addition of empty transitions (or depend on the user aligning those)
Please note that this library is under development and still needs performance optimizations: common experiments such as building a DAFSA for the contents of /usr/share/dict/words will take many minutes in a common machine.
Alternatives
The main alternative to this library is the dawg one, available at https://github.com/pytries/DAWG. dawg wraps the dwagdic C++ library, and is intended to production usage of DAFSAs as a space-efficient data structure. It does not support the computation of edge weights, nor it is intended for exporting the internal structure as a graph.
Other alternatives are the adfa and minim packages, written in C/C++, written by Jan Daciuk. The personal webpage hosting them has been offline for years, with a version at the Wayback Machine available. Note that the archived version does not include the packages.
How to cite
If you use dafsa, please cite it as:
Tresoldi, Tiago (2019). DAFSA, a a library for computing Deterministic Acyclic Finite State Automata. Version 0.3. Jena. Available at: https://github.com/tresoldi/dafsa
In BibTeX:
@misc{Tresoldi2019dafsa,
author = {Tresoldi, Tiago},
title = {DAFSA, a a library for computing Deterministic Acyclic Finite State Automata. Version 0.3},
howpublished = {\url{https://github.com/tresoldi/dafsa}},
address = {Jena},
year = {2019},
}
References
Black, Paul E. and Pieterse, Vreda (eds.). 1998. "Directed acyclic word graph", Dictionary of Algorithms and Data Structures. Gaithersburg: National Institute of Standards and Technology.
Blumer, Anselm C.; Blumer, Janet A.; Haussler, David; Ehrenfeucht, Andrzej; Chen, M.T.; Seiferas, Joel I. 1985. "The smallest automaton recognizing the subwords of a text", Theoretical Computer Science, 40: 31–55. doi:10.1016/0304-3975(85)90157-4.
Ciura, Marcin G. and Deorowicz, Sebastian. 2002. "How to sequeeze a lexicon", Software-Practice and Experience 31(11):1077-1090.
Daciuk, Jan; Mihov, Stoyan; Watson, Bruce and Watson, Richard. 2000. "Incremental construction of minimal acyclic finite state automata." Computational Linguistics 26(1):3-16.
Havon, Steve. 2011. "Compressing dictionaries with a DAWG". Steve Hanov's Blog. url
Lucchesi, Cláudio L. and Kowaltowski, Tomasz. "Applications of finite automata representing large vocabularies". Software-Practice and Experience. 1993: 15–30. CiteSeerX 10.1.1.56.5272.
Author
Tiago Tresoldi (tresoldi@shh.mpg.de)
The author was supported during development by the ERC Grant #715618 for the project CALC (Computer-Assisted Language Comparison: Reconciling Computational and Classical Approaches in Historical Linguistics), led by Johann-Mattis List.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dafsa-0.3.tar.gz.
File metadata
- Download URL: dafsa-0.3.tar.gz
- Upload date:
- Size: 21.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0d02b8b9f84a198843cc1beac0074f112a6d2d4de7b4329b938b0567f42a9086
|
|
| MD5 |
5de93731a667d0b6ca016e321ce5e589
|
|
| BLAKE2b-256 |
85ce4b1f09655994e91cdb29ecadce11bace0c5949d34fe529ab02bac6c2de2a
|
File details
Details for the file dafsa-0.3-py3-none-any.whl.
File metadata
- Download URL: dafsa-0.3-py3-none-any.whl
- Upload date:
- Size: 18.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9d92d0162afa46314a45db6e88b4f972988a64b2f0ea3b7244eed7e785b337a
|
|
| MD5 |
fd70bbb3eee324771909a71bdc8049b9
|
|
| BLAKE2b-256 |
2bcb68e59db98dbe93480ecf4cadbd7ea7ac83c9fe7a4953d43faf67f3b0ec0e
|







