DAPPER benchmarks the performance of data assimilation (DA) methods.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

DAPPER is a set of templates for benchmarking the performance of data assimilation (DA) methods. The numerical experiments provide support and guidance for new developments in DA. The typical set-up is a synthetic (twin) experiment, where you specify a dynamic model and an observational model, and use these to generate a synthetic truth (multivariate time series), and then estimate that truth given the models and noisy observations.





Getting started
- Read & run examples/
basic_1.pyandbasic_2.py, or their corresponding notebooks(requires Google login).
- This screencast provides an overview to DAPPER.
- Install.
- The documentation includes general guidelines and the API reference, but most users must expect to read the code as well.
- If used towards a publication, please cite as
The experiments used (inspiration from) DAPPER [ref], version 1.6.0,
or similar, where [ref] points to
.
- Also see the interactive tutorials on DA theory with Python.
Highlights
DAPPER enables the numerical investigation of DA methods
through a variety of typical test cases and statistics. It
(a) reproduces numerical benchmarks results reported in the literature, and
(b) facilitates comparative studies, thus promoting the
(a) reliability and
(b) relevance of the results.
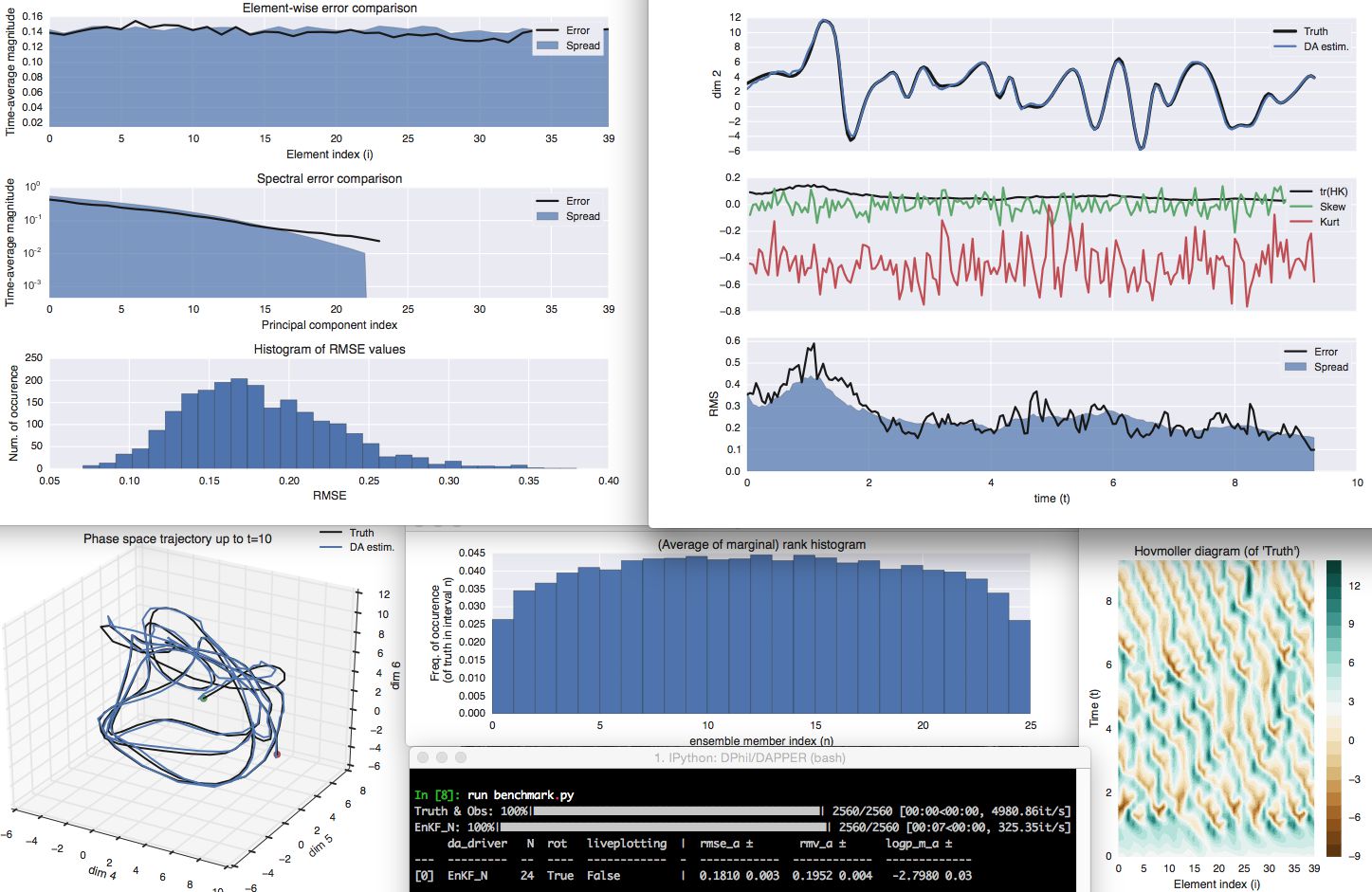
For example, the figure below is generated by docs/examples/basic_3.py,
reproduces figure 5.7 of these lecture notes.
DAPPER is
(c) open source, written in Python, and
(d) focuses on readability;
this promotes the
(c) reproduction and
(d) dissemination of the underlying science,
and makes it easy to adapt and extend.

DAPPER demonstrates how to parallelise ensemble forecasts (e.g., the QG model),
local analyses (e.g., the LETKF), and independent experiments (e.g., docs/examples/basic_3.py).
It includes a battery of diagnostics and statistics,
which all get averaged over subdomains (e.g., "ocean" and "land") and then in time.
Confidence intervals are computed, taking into account auto-correlations,
and used for uncertainty quantification, and significant digits printing.
Several diagnostics are included in the on-line "liveplotting" illustrated below,
which may be paused for further interactive inspection.
In summary, DAPPER is well suited for teaching and fundamental DA research.
Also see its drawbacks.
Installation
Successfully tested on Linux/Mac/Windows. Also see: developer guide.
Prerequisite: Python ≥ 3.12 and a virtual environment
Can be installed from python.org/downloads but Miniconda or uv will give you more options.
Either way, subsequently check your current python by opening a terminal,
and typing python --version
Create and activate (and keep using!) a virtual environment using your chosen tool.
Install
- Download and unzip (or
git clone) DAPPER. - Move the resulting folder wherever you like.
- In the terminal, navigate (
cd) into that "DAPPER" folder and enter pip install -e .
PS: If all you need is to use (but not modify and play around with) DAPPER as a library package,
then all of the above can be replaced simply by pip install dapper
Try it out
Assuming you are in the DAPPER dir, do
python docs/examples/basic_1.py
DA methods
| Method | Literature reproduced |
|---|---|
| EnKF 1 | Sakov08, Hoteit15, Grudzien2020 |
| EnKF-N | Bocquet12, Bocquet15 |
| EnKS, EnRTS | Raanes2016 |
| iEnKS / iEnKF / EnRML / ES-MDA 2 | Sakov12, Bocquet12, Bocquet14 |
| LETKF, local & serial EAKF | Bocquet11 |
| Sqrt. model noise methods | Raanes2014 |
| Particle filter (bootstrap) 3 | Bocquet10 |
| Optimal/implicit Particle filter 3 | Bocquet10 |
| NETF | Tödter15, Wiljes16 |
| Rank histogram filter (RHF) | Anderson10 |
| 4D-Var | |
| 3D-Var | |
| Extended KF | |
| Optimal interpolation | |
| Climatology |
1: Stochastic, DEnKF (i.e. half-update), ETKF (i.e. sym. sqrt.).
Serial forms are also available.
Tuned with inflation and "random, orthogonal rotations".
2: Also supports the bundle version,
and "EnKF-N"-type inflation.
3: Resampling: multinomial
(including systematic/universal and residual).
The particle filter is tuned with "effective-N monitoring",
"regularization/jittering" strength, and more.
For a list of ready-made experiments with suitable,
tuned settings for a given method (e.g., the iEnKS), use:
grep -r "xp.*iEnKS" dapper/mods
Test cases (models)
Simple models facilitate the reliability, reproducibility, and interpretability of experiment results.
| Model | Lin | TLM** |
PDE? | Phys.dim. | State len | Lyap≥0 | Implementer |
|---|---|---|---|---|---|---|---|
| Id | Yes | Yes | No | N/A | * |
0 | Raanes |
| Linear Advect. (LA) | Yes | Yes | Yes | 1d | 1000 * |
51 | Evensen/Raanes |
| DoublePendulum | No | Yes | No | 0d | 4 | 2 | Matplotlib/Raanes |
| Ikeda | No | Yes | No | 0d | 2 | 1 | Raanes |
| LotkaVolterra | No | Yes | No | 0d | 5 * |
1 | Wikipedia/Raanes |
| Lorenz63 | No | Yes | "Yes" | 0d | 3 | 2 | Sakov |
| Lorenz84 | No | Yes | No | 0d | 3 | 2 | Raanes |
| Lorenz96 | No | Yes | No | 1d | 40 * |
13 | Raanes |
| Lorenz96s | No | Yes | No | 1d | 10 * |
4 | Grudzien |
| LorenzUV | No | Yes | No | 2x 1d | 256 + 8 * |
≈60 | Raanes |
| LorenzIII | No | No | No | 1d | 960 * |
≈164 | Raanes |
| Vissio-Lucarini 20 | No | Yes | No | 1d | 36 * |
10 | Yumeng |
| Kuramoto-Sivashinsky | No | Yes | Yes | 1d | 128 * |
11 | Kassam/Raanes |
| Quasi-Geost (QG) | No | No | Yes | 2d | 129²≈17k | ≈140 | Sakov |
*: Flexible; set as necessary**: Tangent Linear Model included?
The models are found as subdirectories within dapper/mods.
A model should be defined in a file named __init__.py,
and illustrated by a file named demo.py.
Most other files within a model subdirectory
are usually named authorYEAR.py and define a HMM object,
which holds the settings of a specific twin experiment,
using that model,
as detailed in the corresponding author/year's paper.
A list of these files can be obtained using
find dapper/mods -iname '[a-z]*[0-9]*.py'
Some files contain settings used by several papers.
Moreover, at the bottom of each such file should be (in comments)
a list of suitable, tuned settings for various DA methods,
along with their expected, average rmse.a score for that experiment.
As mentioned above, DAPPER reproduces literature results.
You will also find results that were not reproduced by DAPPER.
Statistics
Each experiment (xp) populates xp.stats with per-timestep timeseries diagnostics
and xp.avrgs with time-averages and their confidence intervals.
Most of these carry subscripts .f, .a, .s, .i
corresponding to forecast, analysis, smoothed (smoothers only), and integrational statistics.
Vector statistics (one value per state dimension) are also summarised spatially
via rms, m, ma, ms, gm, and per HMM.sectors if defined.
| Statistic | Type | Description |
|---|---|---|
mu |
vector | Mean estimate (ensemble mean or Kalman/variational estimate) |
spread |
vector | Spread (ensemble std dev or posterior std dev) |
err |
vector | Error of mean estimate vs. truth (mu − truth) |
gscore |
vector | Gaussian (log) score: 2·log(spread) + (err/spread)² |
crps |
vector | Continuous ranked probability score (proper scoring rule) |
mad |
scalar | Mean absolute deviation of ensemble from its mean |
skew |
scalar e | Skewness of the ensemble |
kurt |
scalar e | Excess kurtosis (0 for Gaussians) |
svals |
vector e,s | Singular values of the ensemble anomalies |
umisf |
vector e,s | Error projected onto the leading ensemble directions |
w |
vector p | Importance weights |
rh |
vector e | Rank histogram (rank of truth among sorted ensemble members) |
trHK |
scalar † | Trace of the obs-space gain matrix HK |
infl |
scalar † | Inflation factor applied at this step |
iters |
scalar † | Iteration count (iterative methods) |
N_eff |
scalar p,† | Effective ensemble size 1 / Σwᵢ² |
wroot |
scalar p,† | Root for optimal weight tempering |
resmpl |
scalar p,† | Resampling indicator/count |
duration |
— | Wall-clock time (s) for the full assimilate() call |
e: Ensemble methods only.
s: Only computed when √(Nx·N) ≤ rc.comps.max_spectral.
p: Particle filter (weighted ensemble) methods only.
†: Analysis-only (no .f or .i subscript).
Similar projects
DAPPER is aimed at research and teaching (see discussion up top). Example of limitations:
- It is not suited for very big models (>60k unknowns).
- Non-uniform time sequences.
The scope of DAPPER is restricted because
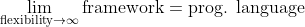
Moreover, even straying beyond basic configurability appears unrewarding when already building on a high-level language such as Python. Indeed, you may freely fork and modify the code of DAPPER, which should be seen as a set of templates, and not a framework.
Also, DAPPER comes with no guarantees/support. Therefore, if you have an operational or real-world application, such as WRF, you should look into one of the alternatives, sorted by approximate project size.
| Name | Developers | Purpose (approximately) |
|---|---|---|
| DART | NCAR | General |
| PDAF | AWI | General |
| JEDI | JCSDA (NOAA, NASA, ++) | General |
| OpenDA | TU Delft | General |
| EMPIRE | Reading (Met) | General |
| ERT | Statoil | History matching (Petroleum DA) |
| PIPT | CIPR | History matching (Petroleum DA) |
| MIKE | DHI | Oceanographic |
| OAK | Liège | Oceanographic |
| Siroco | OMP | Oceanographic |
| Verdandi | INRIA | Biophysical DA |
| PyOSSE | Edinburgh, Reading | Earth-observation DA |
Below is a list of projects with a purpose more similar to DAPPER's (research in DA, and not so much using DA):
| Name | Developers | Notes |
|---|---|---|
| DAPPER | Raanes, Chen, Grudzien | Python |
| SANGOMA | Conglomerate* | Fortran, Matlab |
| hIPPYlib | Villa, Petra, Ghattas | Python, adjoint-based PDE methods |
| FilterPy | R. Labbe | Python. Engineering oriented. |
| DASoftware | Yue Li, Stanford | Matlab. Large inverse probs. |
| Pomp | U of Michigan | R |
| EnKF-Matlab | Sakov | Matlab |
| EnKF-C | Sakov | C. Light-weight, off-line DA |
| pyda | Hickman | Python |
| PyDA | Shady-Ahmed | Python |
| DasPy | Xujun Han | Python |
| DataAssim.jl | Alexander-Barth | Julia |
| DataAssimilationBenchmarks.jl | Grudzien | Julia, Python |
| EnsembleKalmanProcesses.jl | Clim. Modl. Alliance | Julia, EKI (optim) |
| Datum | Raanes | Matlab |
| IEnKS code | Bocquet | Python |
The EnKF-Matlab and IEnKS codes have been inspirational
in the development of DAPPER.
*: AWI/Liege/CNRS/NERSC/Reading/Delft
Contributing
Issues and Pull requests
Do not hesitate to open an issue, whether to report a problem or ask a question. It may take some time for us to get back to you, since DAPPER is primarily a volunteer effort. Please start by perusing the documentation and searching the issue tracker for similar items.
Pull requests are very welcome. Examples: adding a new DA method, dynamical models, experimental configuration reproducing literature results, or improving the features and capabilities of DAPPER. Please keep in mind the intentional limitations and read the developers guidelines.
Contributors
Patrick N. Raanes, Yumeng Chen, Colin Grudzien, Maxime Tondeur, Remy Dubois
DAPPER is developed and maintained at NORCE (Norwegian Research Institute) and the Nansen Environmental and Remote Sensing Center (NERSC), in collaboration with the University of Reading, the UK National Centre for Earth Observation (NCEO), and the Center for Western Weather and Water Extremes (CW3E).





Publications
- Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model
- Adaptive covariance inflation in the ensemble Kalman filter by Gaussian scale mixtures
- Revising the stochastic iterative ensemble smoother
- p-Kernel Stein Variational Gradient Descent for Data Assimilation and History Matching
- Springer book chapter: Data Assimilation for Chaotic Dynamics
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dapper-1.8.1.tar.gz.
File metadata
- Download URL: dapper-1.8.1.tar.gz
- Upload date:
- Size: 2.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5afa9697fcf48b873b13e22341d60e57faa544b2f80834d0f5f1ebab4e35bce0
|
|
| MD5 |
40397b6a59d10966ad83078c19c57f33
|
|
| BLAKE2b-256 |
7da3118ff5e6da911ad0ae56e8e535fa4c7cd4c7d0d86d36c0d85c2406ae40b6
|
Provenance
The following attestation bundles were made for dapper-1.8.1.tar.gz:
Publisher:
publish.yml on nansencenter/DAPPER
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dapper-1.8.1.tar.gz -
Subject digest:
5afa9697fcf48b873b13e22341d60e57faa544b2f80834d0f5f1ebab4e35bce0 - Sigstore transparency entry: 1924528741
- Sigstore integration time:
-
Permalink:
nansencenter/DAPPER@b72433c4603192e5eb16633b7e166a26e7c0b5e0 -
Branch / Tag:
refs/tags/v1.8.1 - Owner: https://github.com/nansencenter
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b72433c4603192e5eb16633b7e166a26e7c0b5e0 -
Trigger Event:
push
-
Statement type:
File details
Details for the file dapper-1.8.1-py3-none-any.whl.
File metadata
- Download URL: dapper-1.8.1-py3-none-any.whl
- Upload date:
- Size: 309.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
85742d78f75bfea08b88d39a4ed1fd0102629108bd9c76bf68454b0b098a8ed6
|
|
| MD5 |
bf19ad8f7eba0114a7762efa383a1aa5
|
|
| BLAKE2b-256 |
19b95d7f184d5e3241b153b8a626ac408f85311a70eba20d5e22ea55d889be46
|
Provenance
The following attestation bundles were made for dapper-1.8.1-py3-none-any.whl:
Publisher:
publish.yml on nansencenter/DAPPER
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dapper-1.8.1-py3-none-any.whl -
Subject digest:
85742d78f75bfea08b88d39a4ed1fd0102629108bd9c76bf68454b0b098a8ed6 - Sigstore transparency entry: 1924528804
- Sigstore integration time:
-
Permalink:
nansencenter/DAPPER@b72433c4603192e5eb16633b7e166a26e7c0b5e0 -
Branch / Tag:
refs/tags/v1.8.1 - Owner: https://github.com/nansencenter
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b72433c4603192e5eb16633b7e166a26e7c0b5e0 -
Trigger Event:
push
-
Statement type:







