Data Augmentation for Time series Data: A Review
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
⚠️ Alert: If you are using this code with Keras v3, make sure you are using Keras ≥ 3.6.0. Earlier versions of Keras v3 do not honor
trainable=False, which will result in training hand-crafted filters in LITEMV unexpectedly.
| Overview | |
|---|---|
| CI/CD |   |
| Code |     |
| Community |  |
Re-framing Time Series Augmentation Through the Lens of Generative Models
Authors: Ali Ismail-Fawaz1, Maxime Devanne1, Stefano Berreti2, Jonathan Weber1 and Germain Forestier1,3
1 IRIMAS, Universite de Haute-Alsace, France
2 MICC, University of Florence, Italy
3 DSAI, Monash University, Australia
This repository is the source code of the article titled "Re-framing Time Series Augmentation Through the Lens of Generative Models" accepted in the 10th Workshop on Advanced Analytics and Learning on Temporal Data (AALTD 2025) in conjunction with the 2025 European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD 2025). In this article, we present a benchmark comparison between 22 data augmentation techniques on 131 time series classification datasets of the UCR archive.
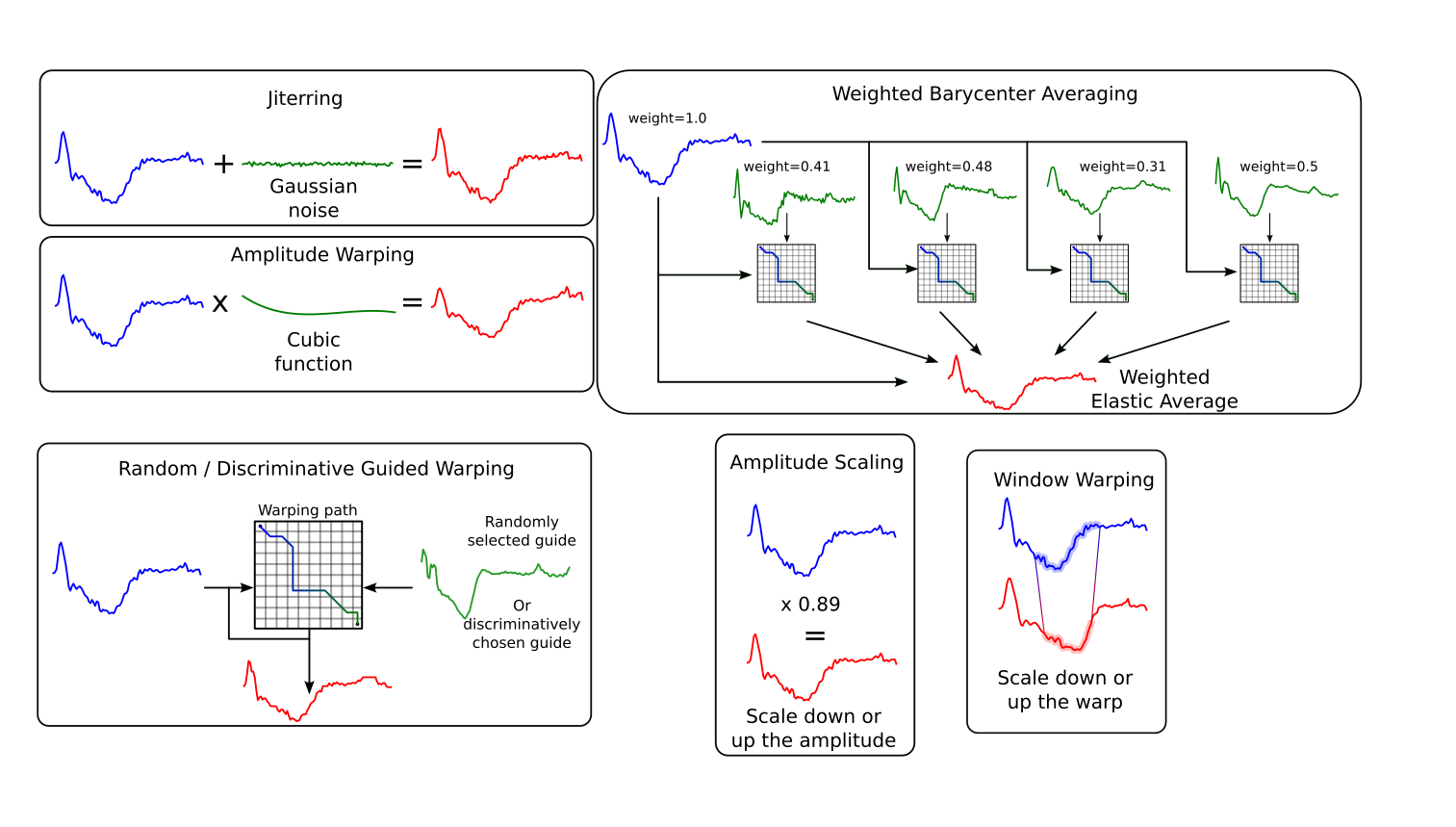
Abstract
Time series classification is widely used in many fields, but it often suffers from a lack of labeled data. To address this, researchers commonly apply data augmentation techniques that generate synthetic samples through transformations such as jittering, warping, or resampling. However, with an increasing number of available augmentation methods, it becomes difficult to choose the most suitable one for a given task. In many cases, this choice is based on intuition or visual inspection. Assessing the impact of this choice on classification accuracy requires training models, which is time-consuming and depends on the dataset. In this work, we adopt a generative model perspective and evaluate augmentation methods prior to training any classifier, using metrics that quantify both fidelity and diversity of the generated samples. We benchmark 22 augmentation techniques on 131 public datasets using eight metrics. Our results provide a practical and efficient way to compare augmentation methods without relying solely on classifier performance.
Data
In this work we utilize 131 datasets of the UCR archive taken from the original repository and the new added datasets.
However you are not obligated to download them as our code loads the datasets through the Time Series Classification webpage using aeon-toolkit.
Docker
This repository supports the usage of docker. In order to create the docker image using the dockerfile, simply run the following command (assuming you have docker installed and nvidia cuda container as well):
docker build --build-arg USER_ID=$(id -u) --build-arg GROUP_ID=$(id -g) -t data-augmentation-review-image .
After the image has been successfully built, you can create the docker container using the following command:
docker run --gpus all -it --name data-augmentation-review-container -v "$(pwd):/home/myuser/code" --user $(id -u):$(id -g) data-augmentation-review-image bash
The code will be stored under the directory /home/myuser/code/ inside the docker container. This will allow you to use GPU acceleration.
Requirements
If you do not want to use docker, simply install the project using the following command:
python3 -m venv ./data-augmentation-review-venv
source ./data-augmentation-review-venv/bin/activate
pip install --upgrade pip
pip install -e .[dev]
Make sure you have jq installed on your system. This project supports python>=3.10 only.
You can see the list of dependencies and their required version in the pyptoject.toml file.
Running the code on a single experiment
If you wish to run a single experiment on a single dataset, using a single augmentation method, using a single model then first you have to execute your docker container to open a terminal inside if you're not inside the container:
docker exec -it data-augmentation-review-container bash
Then you can run the following command for example to run Amplitude Warping on the Adiac dataset:
python3 main.py task=generate_data dataset_name=Adiac generate_data.method=AW
The code uses hydra for the parameter configuration, simply see the hydra configuration file for a detailed view on the parameters of our experiments.
Running the whole benchmark
If you wish to run all the experiments to reproduce the results of our article simply run the following for data generation experiments:
chmod +x run_generate_data.sh
nohup ./run_generate_data.sh &
and the following for training the feature extractor:
chmod +x run_train_feature_extractor.sh
nohup ./run_train_feature_extractor.sh &
and the following for evaluation of the generations:
chmod +x run_evaluate_generation.sh
nohup ./run_evaluate_generation.sh &
Cite this work
If you use this work please cite the following:
@inproceedings{ismail-fawaz2025Data-Aug-4-TSC,
author = {Ismail-Fawaz, Ali and Devanne, Maxime and Berretti, Sefano and Weber, Jonathan and Forestier, Germain},
title = {Re-framing Time Series Augmentation Through the Lens of Generative Models},
booktitle = {ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data},
city = {Porto},
country = {Portugal},
year = {2025}
}
Acknowledgments
This work was supported by the ANR DELEGATION project (grant ANR-21-CE23-0014) of the French Agence Nationale de la Recherche. The authors would like to acknowledge the High Performance Computing Center of the University of Strasbourg for supporting this work by providing scientific sup- port and access to computing resources. Part of the computing resources were funded by the Equipex Equip@Meso project (Programme Investissements d’Avenir) and the CPER Alsacalcul/Big Data. The authors would also like to thank the creators and providers of the UCR Archive
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file data_aug_4_tsc-0.0.2.tar.gz.
File metadata
- Download URL: data_aug_4_tsc-0.0.2.tar.gz
- Upload date:
- Size: 18.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c5420cf4d210d6d18e63d9155f9356a0655b30a50eb8c5721bbcc490fa79cfad
|
|
| MD5 |
0b8663faf0ae897859e1380a3e990a3d
|
|
| BLAKE2b-256 |
12721c2aeab28b25fe81f315de0eb33d00c586694f1510a1fa3ac055fd5a42c7
|
Provenance
The following attestation bundles were made for data_aug_4_tsc-0.0.2.tar.gz:
Publisher:
publish.yml on MSD-IRIMAS/Data-Augmentation-4-TSC
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
data_aug_4_tsc-0.0.2.tar.gz -
Subject digest:
c5420cf4d210d6d18e63d9155f9356a0655b30a50eb8c5721bbcc490fa79cfad - Sigstore transparency entry: 1753607763
- Sigstore integration time:
-
Permalink:
MSD-IRIMAS/Data-Augmentation-4-TSC@f0a2d2bbb5dc75b40c8049cf09d14dca522723d5 -
Branch / Tag:
refs/tags/v0.0.2 - Owner: https://github.com/MSD-IRIMAS
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@f0a2d2bbb5dc75b40c8049cf09d14dca522723d5 -
Trigger Event:
release
-
Statement type:
File details
Details for the file data_aug_4_tsc-0.0.2-py3-none-any.whl.
File metadata
- Download URL: data_aug_4_tsc-0.0.2-py3-none-any.whl
- Upload date:
- Size: 17.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
04521f6d57fbb4a95585d6833e4280859c90394dfda305d20f6febff6206eff7
|
|
| MD5 |
b878a93917a1ec5040f3cd464ecf3b73
|
|
| BLAKE2b-256 |
85373cf0b467c82eddb329db2d92d62108874a30e139f659c8daa14becd03384
|
Provenance
The following attestation bundles were made for data_aug_4_tsc-0.0.2-py3-none-any.whl:
Publisher:
publish.yml on MSD-IRIMAS/Data-Augmentation-4-TSC
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
data_aug_4_tsc-0.0.2-py3-none-any.whl -
Subject digest:
04521f6d57fbb4a95585d6833e4280859c90394dfda305d20f6febff6206eff7 - Sigstore transparency entry: 1753607778
- Sigstore integration time:
-
Permalink:
MSD-IRIMAS/Data-Augmentation-4-TSC@f0a2d2bbb5dc75b40c8049cf09d14dca522723d5 -
Branch / Tag:
refs/tags/v0.0.2 - Owner: https://github.com/MSD-IRIMAS
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@f0a2d2bbb5dc75b40c8049cf09d14dca522723d5 -
Trigger Event:
release
-
Statement type:







