A Python library for feature selection in tabular datasets
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
dataclr: The feature selection library




dataclr is a Python library for feature selection, enabling data scientists and ML engineers to identify optimal features from tabular datasets. By combining filter and wrapper methods, it achieves state-of-the-art results, enhancing model performance and simplifying feature engineering.
Features
-
Comprehensive Methods:
-
Filter Methods: Statistical and data-driven approaches like
ANOVA,MutualInformation, andVarianceThreshold.Method Regression Classification ANOVAYes Yes Chi2No Yes CumulativeDistributionFunctionYes Yes CohensDNo Yes CramersVNo Yes DistanceCorrelationYes Yes EntropyYes Yes KendallCorrelationYes Yes KurtosisYes Yes LinearCorrelationYes Yes MaximalInformationCoefficientYes Yes MeanAbsoluteDeviationYes Yes mRMRYes Yes MutualInformationYes Yes SkewnessYes Yes SpearmanCorrelationYes Yes VarianceThresholdYes Yes VarianceInflationFactorYes Yes ZScoreYes Yes -
Wrapper Methods: Model-based iterative methods like
BorutaMethod,ShapMethod, andOptunaMethod.Method Regression Classification BorutaMethodYes Yes HyperoptMethodYes Yes OptunaMethodYes Yes ShapMethodYes Yes Recursive Feature EliminationYes Yes Recursive Feature AdditionYes Yes
-
-
Flexible and Scalable:
- Supports both regression and classification tasks.
- Handles high-dimensional datasets efficiently.
-
Interpretable Results:
- Provides ranked feature lists with detailed importance scores.
- Shows used methods along with their parameters.
-
Seamless Integration:
- Works with popular Python libraries like
pandasandscikit-learn.
- Works with popular Python libraries like
Installation
Install dataclr using pip:
pip install dataclr
Getting Started
1. Load Your Dataset
Prepare your dataset as pandas DataFrames or Series and preprocess it (e.g., encode categorical features and normalize numerical values):
import pandas as pd
from sklearn.preprocessing import StandardScaler
# Example dataset
X = pd.DataFrame({...}) # Replace with your feature matrix
y = pd.Series([...]) # Replace with your target variable
# Preprocessing
X_encoded = pd.get_dummies(X) # Encode categorical features
scaler = StandardScaler()
X_normalized = pd.DataFrame(scaler.fit_transform(X_encoded), columns=X_encoded.columns)
2. Use FeatureSelector
The FeatureSelector is a high-level API that combines multiple methods to select the best feature subsets:
from sklearn.ensemble import RandomForestClassifier
from dataclr.feature_selection import FeatureSelector
# Define a scikit-learn model
my_model = RandomForestClassifier(n_estimators=100, random_state=42)
# Initialize the FeatureSelector
selector = FeatureSelector(
model=my_model,
metric="accuracy",
X_train=X_train,
X_test=X_test,
y_train=y_train,
y_test=y_test,
)
# Perform feature selection
selected_features = selector.select_features(n_results=5)
print(selected_features)
3. Use Singular Methods
For granular control, you can use individual feature selection methods:
from sklearn.linear_model import LogisticRegression
from dataclr.methods import MutualInformation
# Define a scikit-learn model
my_model = LogisticRegression(solver="liblinear", max_iter=1000)
# Initialize a method
method = MutualInformation(model=my_model, metric="accuracy")
# Fit and transform
results = method.fit_transform(X_train, X_test, y_train, y_test)
print(results)
Benchmarks
As our algorithm produces multiple results, we selected benchmark results that balance feature count with performance, while being capable of achieving the best performance if needed.
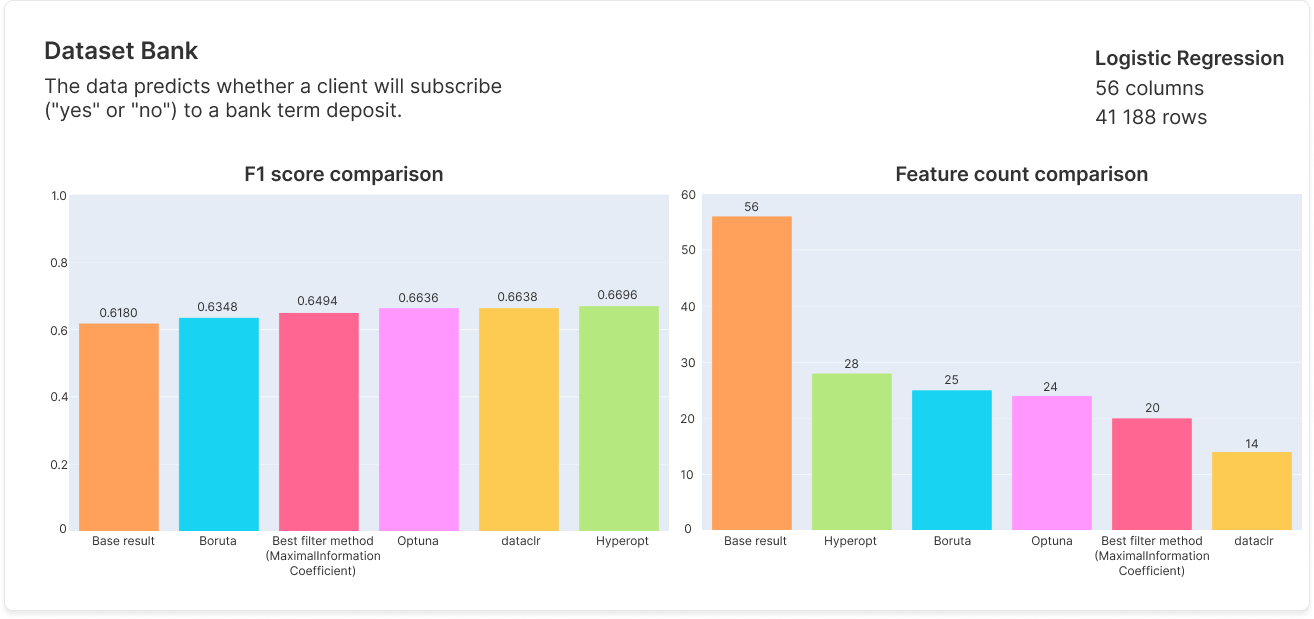
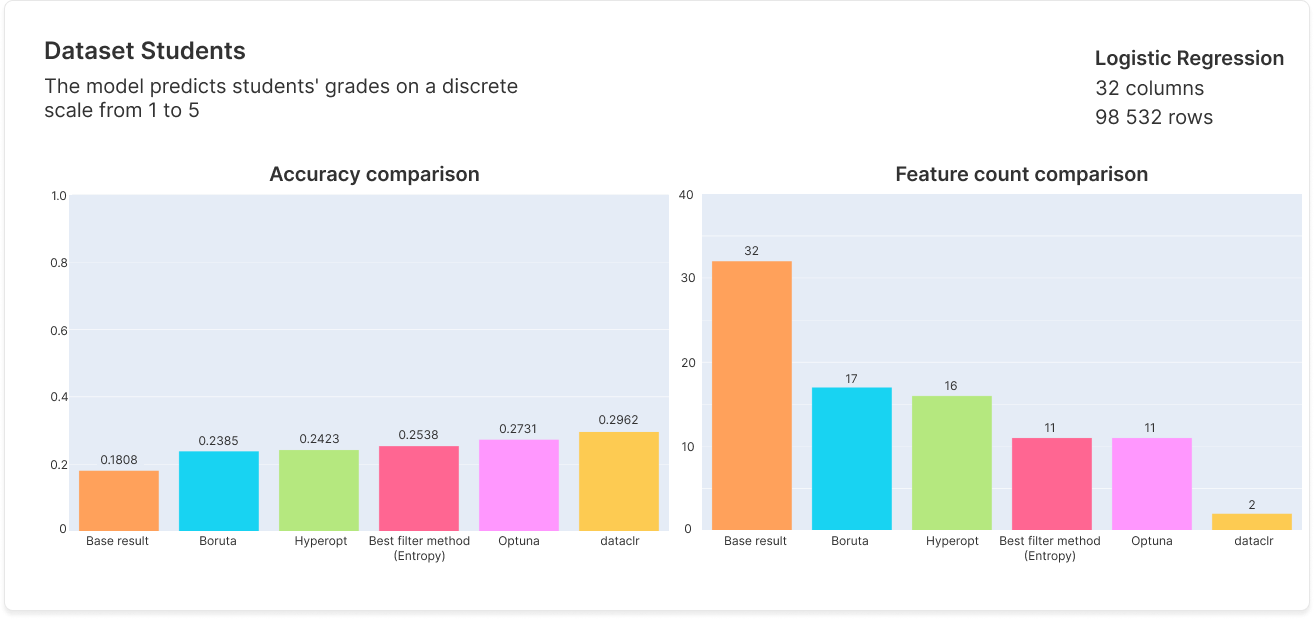
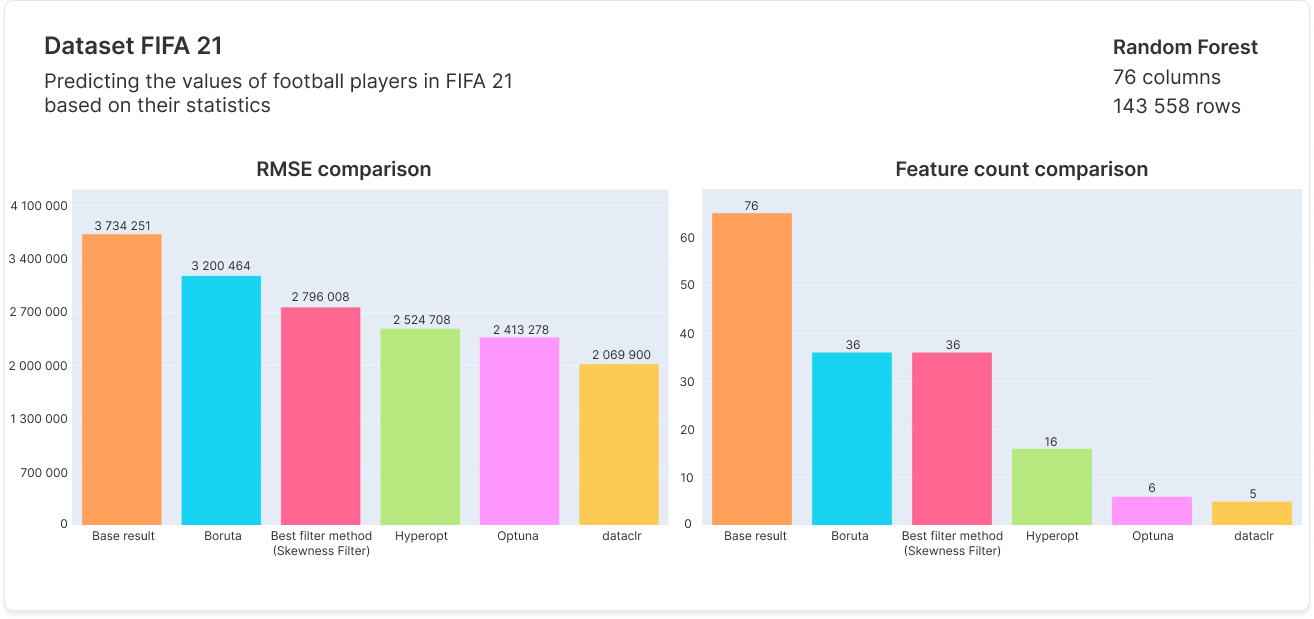
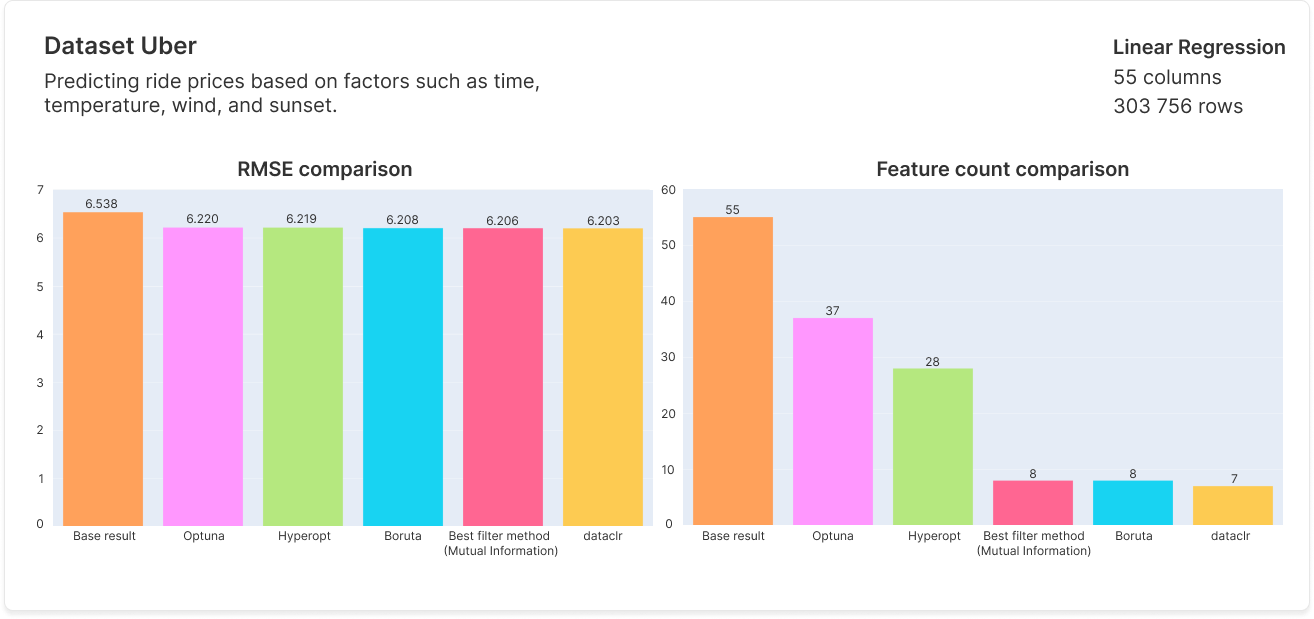
Documentation
Explore the full documentation for detailed usage instructions, API references, and examples.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dataclr-0.3.0.tar.gz.
File metadata
- Download URL: dataclr-0.3.0.tar.gz
- Upload date:
- Size: 39.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9c98e3d08bfc34a94ce0018ec5837e1ccdb1f74df3100bc4c5c6147fa702d2d7
|
|
| MD5 |
2da432325508240d36229e9ffe3a6f2e
|
|
| BLAKE2b-256 |
9e58bd9aabc19a2a9574418c86f1ee4fa0a54131731e0b6afff807e654962a9b
|
Provenance
The following attestation bundles were made for dataclr-0.3.0.tar.gz:
Publisher:
release.yml on dataclr/dataclr
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dataclr-0.3.0.tar.gz -
Subject digest:
9c98e3d08bfc34a94ce0018ec5837e1ccdb1f74df3100bc4c5c6147fa702d2d7 - Sigstore transparency entry: 177627029
- Sigstore integration time:
-
Permalink:
dataclr/dataclr@ef616bc2f4c7362612d91c11c1cd32db02a7b7c6 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/dataclr
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@ef616bc2f4c7362612d91c11c1cd32db02a7b7c6 -
Trigger Event:
release
-
Statement type:
File details
Details for the file dataclr-0.3.0-py3-none-any.whl.
File metadata
- Download URL: dataclr-0.3.0-py3-none-any.whl
- Upload date:
- Size: 61.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f4f4a856ab6d86f5fff735167cf787113fbfc3b97e5e04838dab50e0e5e419ba
|
|
| MD5 |
c2477480641bc3812cb12fde1db3de71
|
|
| BLAKE2b-256 |
2c8ee0cb6dbe0a84a35b034952aa3b7b4e1951292e909420de19e6788a365cf1
|
Provenance
The following attestation bundles were made for dataclr-0.3.0-py3-none-any.whl:
Publisher:
release.yml on dataclr/dataclr
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dataclr-0.3.0-py3-none-any.whl -
Subject digest:
f4f4a856ab6d86f5fff735167cf787113fbfc3b97e5e04838dab50e0e5e419ba - Sigstore transparency entry: 177627030
- Sigstore integration time:
-
Permalink:
dataclr/dataclr@ef616bc2f4c7362612d91c11c1cd32db02a7b7c6 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/dataclr
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@ef616bc2f4c7362612d91c11c1cd32db02a7b7c6 -
Trigger Event:
release
-
Statement type:







