A library for dataset generation and knowledge extraction from foundation computer vision models.

Project description
DataDreamer





🚀 Quickstart
To generate your dataset with custom classes, you need to execute only two commands:
pip install datadreamer
datadreamer --class_names person moon robot
🌟 Overview

DataDreamer is an advanced toolkit engineered to facilitate the development of edge AI models, irrespective of initial data availability. Distinctive features of DataDreamer include:
-
Synthetic Data Generation: Eliminate the dependency on extensive datasets for AI training. DataDreamer empowers users to generate synthetic datasets from the ground up, utilizing advanced AI algorithms capable of producing high-quality, diverse images.
-
Knowledge Extraction from Foundational Models:
DataDreamerleverages the latent knowledge embedded within sophisticated, pre-trained AI models. This capability allows for the transfer of expansive understanding from these "Foundation models" to smaller, custom-built models, enhancing their capabilities significantly. -
Efficient and Potent Models: The primary objective of
DataDreameris to enable the creation of compact models that are both size-efficient for integration into any device and robust in performance for specialized tasks.
✨ New: Pre-annotate Real Data with DataDreamer
DataDreamer helps you accelerate your annotation process by pre-annotating real data with minimal effort. Simply provide your dataset, and DataDreamer generates high-quality initial annotations for further refinement.
Available tasks: classification, object detection, and instance segmentation.
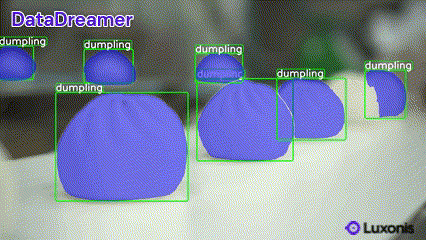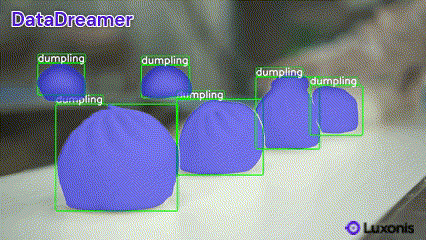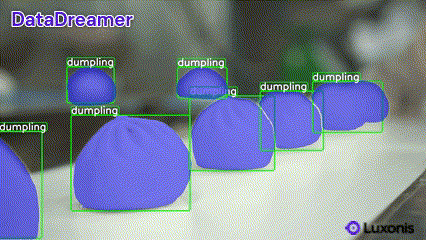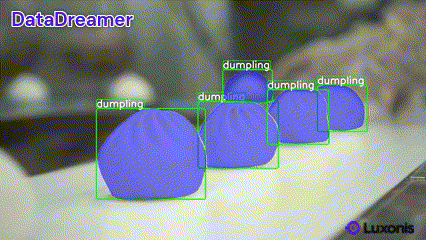
Example
Run the following to pre-annotate images in your dataset:
datadreamer --task instance-segmentation --image_annotator owlv2-slimsam --save_dir dataset_path --class_names dumpling --annotate_only
📚 Tutorial: Training a Semantic Segmentation Model using luxonis-train and DataDreamer
📜 Table of contents
- 🚀 Quickstart
- 🌟 Overview
- 🛠️ Features
- 💻 Installation
- ⚙️ Hardware Requirements
- 📋 Usage
- ⚠️ Limitations
- 📄 License
- 🙏 Acknowledgements
🛠️ Features
-
Prompt Generation: Automate the creation of image prompts using powerful language models.
Provided class names: ["horse", "robot"]
Generated prompt: "A photo of a horse and a robot coexisting peacefully in the midst of a serene pasture."
-
Image Generation: Generate synthetic datasets with state-of-the-art generative models.
-
Dataset Annotation: Leverage foundation models to label datasets automatically.
-
Edge Model Training: Train efficient small-scale neural networks for edge deployment. (not part of this library)


💻 Installation
There are two ways to install the datadreamer library:
Using pip:
To install with pip:
pip install datadreamer
Using Docker (for Linux/Windows):
Pull Docker Image from GHCR:
docker pull ghcr.io/luxonis/datadreamer:latest
Or build Docker Image from source:
# Clone the repository
git clone https://github.com/luxonis/datadreamer.git
cd datadreamer
# Build Docker Image
docker build -t datadreamer .
Run Docker Container (assuming it's GHCR image, otherwise replace ghcr.io/luxonis/datadreamer:latest with datadreamer)
Run on CPU:
docker run --rm -v "$(pwd):/app" ghcr.io/luxonis/datadreamer:latest --save_dir generated_dataset --device cpu
Run on GPU, make sure to have nvidia-docker installed:
docker run --rm --gpus all -v "$(pwd):/app" ghcr.io/luxonis/datadreamer:latest --save_dir generated_dataset --device cuda
These commands mount the current directory ($(pwd)) to the /app directory inside the container, allowing you to access files from your local machine.
⚙️ Hardware Requirements
To ensure optimal performance and compatibility with the libraries used in this project, the following hardware specifications are recommended:
GPU: A CUDA-compatible GPU with a minimum of 16 GB memory. This is essential for libraries liketorch,torchvision,transformers, anddiffusers, which leverage CUDA for accelerated computing in machine learning and image processing tasks.RAM: At least 16 GB of system RAM, although more (32 GB or above) is beneficial for handling large datasets and intensive computations.
📋 Usage
The datadreamer/pipelines/generate_dataset_from_scratch.py (datadreamer command) script is a powerful tool for generating and annotating images with specific objects. It uses advanced models to both create images and accurately annotate them with bounding boxes for designated objects.
Run the following command in your terminal to use the script:
datadreamer --save_dir <directory> --class_names <objects> --prompts_number <number> [additional options]
or using a .yaml config file
datadreamer --config <path-to-config>
🎯 Main Parameters
--save_dir(required): Path to the directory for saving generated images and annotations.--class_names(required): Space-separated list of object names for image generation and annotation. Example:person moon robot.--prompts_number(optional): Number of prompts to generate for each object. Defaults to10.--annotate_only(optional): Only annotate the images without generating new ones, prompt and image generator will be skipped. Defaults toFalse.
🔧 Additional Parameters
--task: Choose betweendetection,classificationandinstance-segmentation. Default isdetection.--dataset_format: Format of the dataset. Defaults toraw. Supported values:raw,yolo,coco,voc,luxonis-dataset,cls-single.--split_ratios: Split ratios for train, validation, and test sets. Defaults to[0.8, 0.1, 0.1].--num_objects_range: Range of objects in a prompt. Default is 1 to 3.--prompt_generator: Choose betweensimple,lm(Mistral-7B),tiny(tiny LM), andqwen2(Qwen2.5 LM). Default isqwen2.--image_generator: Choose image generator, e.g.,sdxl,sdxl-turbo,sdxl-lightningorshuttle-3. Default issdxl-turbo.--image_annotator: Specify the image annotator, likeowlv2for object detection oraimv2orclipfor image classification orowlv2-slimsamandowlv2-sam2for instance segmentation. Default isowlv2.--conf_threshold: Confidence threshold for annotation. Default is0.15.--annotation_iou_threshold: Intersection over Union (IoU) threshold for annotation. Default is0.2.--prompt_prefix: Prefix to add to every image generation prompt. Default is"".--prompt_suffix: Suffix to add to every image generation prompt, e.g., for adding details like resolution. Default is", hd, 8k, highly detailed".--negative_prompt: Negative prompts to guide the generation away from certain features. Default is"cartoon, blue skin, painting, scrispture, golden, illustration, worst quality, low quality, normal quality:2, unrealistic dream, low resolution, static, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, bad anatomy".--use_tta: Toggle test time augmentation for object detection. Default isFalse.--synonym_generator: Enhance class names with synonyms. Default isnone. Other options arellm,wordnet.--use_image_tester: Use image tester for image generation. Default isFalse.--image_tester_patience: Patience level for image tester. Default is1.--lm_quantization: Quantization to use for Mistral language model. Choose betweennoneand4bit. Default isnone.--annotator_size: Size of the annotator model to use. Choose betweenbaseandlarge. Default isbase.--disable_lm_filter: Use only a bad word list for profanity filtering (LM check disabled). Default isFalse.--disable_profanity_filter: Disable profanity filtering entirely. Default isFalse.--keep_unlabeled_images: Whether to keep images without any annotations. Default ifFalse.--batch_size_prompt: Batch size for prompt generation. Default is 64.--batch_size_annotation: Batch size for annotation. Default is1.--batch_size_image: Batch size for image generation. Default is1.--raw_mask_format: Format of segmentations masks when saved in raw dataset format. Default isrle.--vis_anns: Whether to save visualizations of annotations. Default isFalse.--device: Choose betweencudaandcpu. Default iscuda.--seed: Set a random seed for image and prompt generation. Default is42.--config: A path to an optional.yamlconfig file specifying the pipeline's arguments.
🤖 Available Models
| Model Category | Model Names | Description/Notes |
|---|---|---|
| Prompt Generation | Mistral-7B-Instruct-v0.1 | Semantically rich prompts |
| TinyLlama-1.1B-Chat-v1.0 | Tiny LM | |
| Qwen2.5-1.5B-Instruct | Qwen2.5 LM | |
| Simple random generator | Joins randomly chosen object names | |
| Profanity Filter | Qwen2.5-1.5B-Instruct | Fast and accurate LM profanity filter |
| Image Generation | SDXL-1.0 | Slow and accurate (1024x1024 images) |
| SDXL-Turbo | Fast and less accurate (512x512 images) | |
| SDXL-Lightning | Fast and accurate (1024x1024 images) | |
| Shuttle-3-Diffusion | Fast and accurate (512x512 images) | |
| Image Annotation | OWLv2 | Open-Vocabulary object detector |
| CLIP | Zero-shot-image-classification | |
| AIMv2 | Zero-shot-image-classification | |
| SlimSAM | Zero-shot-instance-segmentation | |
| SAM2.1 | Zero-shot-instance-segmentation |
💡 Example
datadreamer --save_dir path/to/save_directory --class_names person moon robot --prompts_number 20 --prompt_generator simple --num_objects_range 1 3 --image_generator sdxl-turbo
or using a .yaml config file (if arguments are provided with the config file in the command, they will override the ones in the config file):
datadreamer --save_dir path/to/save_directory --config configs/det_config.yaml
This command generates images for the specified objects, saving them and their annotations in the given directory. The script allows customization of the generation process through various parameters, adapting to different needs and hardware configurations.
See /configs folder for some examples of the .yaml config files.
📦 Output
The dataset comprises two primary components: images and their corresponding annotations, stored as JSON files.
save_dir/
│
├── image_1.jpg
├── image_2.jpg
├── ...
├── image_n.jpg
├── prompts.json
└── annotations.json
📝 Annotations Format
- Detection Annotations:
- Each entry corresponds to an image and contains bounding boxes and labels for objects in the image.
- Format:
{
"image_path": {
"boxes": [[x_min, y_min, x_max, y_max], ...],
"labels": [label_index, ...]
},
...
"class_names": ["class1", "class2", ...]
}
- Classification Annotations:
- Each entry corresponds to an image and contains labels for the image.
- Format:
{
"image_path": {
"labels": [label_index, ...]
},
...
"class_names": ["class1", "class2", ...]
}
- Instance Segmentation Annotations:
- Each entry corresponds to an image and contains bounding boxes, masks and labels for objects in the image.
- Format:
{
"image_path": {
"boxes": [[x_min, y_min, x_max, y_max], ...],
"masks": [[[x0, y0],[x1, y1],...], [[x0, y0],[x1, y1],...], ....]
# "masks": [{"counts": ..., "size": ...}, {"counts": ..., "size": ...}, ...] # for RLE raw_mask_format
"labels": [label_index, ...]
},
...
"class_names": ["class1", "class2", ...]
}
⚠️ Limitations
While the datadreamer library leverages advanced Generative models to synthesize datasets and Foundation models for annotation, there are inherent limitations to consider:
-
Incomplete Object Representation: Occasionally, the generative models might not include all desired objects in the synthetic images. This could result from the complexity of the scene or limitations within the model's learned patterns. -
Annotation Accuracy: The annotations created by foundation computer vision models may not always be precise. These models strive for accuracy, but like all automated systems, they are not infallible and can sometimes produce erroneous or ambiguous labels. However, we have implemented several strategies to mitigate these issues, such as Test Time Augmentation (TTA), usage of synonyms for class names and careful selection of the confidence/IOU thresholds.
Despite these limitations, the datasets created by datadreamer provide a valuable foundation for developing and training models, especially for edge computing scenarios where data availability is often a challenge. The synthetic and annotated data should be seen as a stepping stone, granting a significant head start in the model development process.
📄 License
This project is licensed under the Apache License, Version 2.0 - see the LICENSE file for details.
The above license does not cover the models. Please see the license of each model in the table above.
🙏 Acknowledgements
This library was made possible by the use of several open-source projects, including Transformers, Diffusers, and others listed in the requirements.txt. Furthermore, we utilized a bad words list from @coffeeandfun/google-profanity-words Node.js module created by Robert James Gabriel from Coffee & Fun LLC.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file datadreamer-0.2.3.tar.gz.
File metadata
- Download URL: datadreamer-0.2.3.tar.gz
- Upload date:
- Size: 79.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bac4682683a52631a08ed6b0c35e77288ab811e917ec41b0b206e6d3a85b2667
|
|
| MD5 |
f5974268015eee6c89c6cd769e484d06
|
|
| BLAKE2b-256 |
4365813c917d0dc16f4b60d0a81107c8535553cc7bce087557625760cc570999
|
File details
Details for the file datadreamer-0.2.3-py3-none-any.whl.
File metadata
- Download URL: datadreamer-0.2.3-py3-none-any.whl
- Upload date:
- Size: 108.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
932d3f0b5ac7be18a0aab94b51748495f5def4ceb6afa69f937e5057038cc44b
|
|
| MD5 |
e8f03249dea56c834114847113bd557d
|
|
| BLAKE2b-256 |
c6a73b3d8cae5cf1d7e1180d9ab5b5a2f4aae9e1dcb24f7b06166dbd9ad9513b
|







