Add your description here


Project description
DataHarvest
DataHarvest 是一个用于数据搜索🔍、爬取🕷、清洗🧽的工具。
AI时代,数据是一切的基石,DataHarvest 能够帮助快速获取干净有效的数据,开箱即用,灵活配置。
除了工具本身之外,我们还会搜集整理一些技术方案,整理成wiki。

搜索支持
| 搜索引擎 | 官网 | 支持 |
|---|---|---|
| tavily | https://docs.tavily.com/ | ✅ |
| 天工搜索 | https://www.tiangong.cn/ | ✅ |
数据爬取&清洗支持
| 网站 | 内容 | url pattern | 爬取 | 清洗 |
|---|---|---|---|---|
| 百度百科 | 词条 | baike.baidu.com/item/ | ✅ | ✅ |
| 百度百家号 | 文章 | baijiahao.baidu.com/s/ | ✅ | ✅ |
| B站 | 文章 | www.bilibili.com/read/ | ✅ | ✅ |
| 腾讯网 | 文章 | new.qq.com/rain/a/ | ✅ | ✅ |
| 360个人图书馆 | 文章 | www.360doc.com/content/ | ✅ | ✅ |
| 360百科 | 词条 | baike.so.com/doc/ | ✅ | ✅ |
| 搜狗百科 | 词条 | baike.sogou.com/v/ | ✅ | ✅ |
| 搜狐 | 文章 | www.sohu.com/a/ | ✅ | ✅ |
| 头条 | 文章 | www.toutiao.com/article/ | ✅ | ✅ |
| 网易 | 文章 | www.163.com/\w+/article/.+ | ✅ | ✅ |
| 微信公众号 | 文章 | weixin.qq.com/s/ | ✅ | ✅ |
| 马蜂窝 | 文章 | www.mafengwo.cn/i/ | ✅ | |
| 小红书 | 超链帖子 | /xhslink.com/ | ✅ | ✅ |
其他情况使用基础playwright数据爬取和html2text数据清洗,但并未做特殊适配。
安装
pip install dataharvest
playwright install
使用
==注意使用时最好使用虚拟环境,以免不必要的麻烦==
分为搜索、爬虫、数据清洗三个主要模块,互相独立,您可以按需使用对应模块。
爬取和清洗做了根据URL的自动策略匹配,您只需要使用AutoSpider和AutoPurifier即可。
最佳实践
整合
搜索+自动爬取+自动清洗
import asyncio
from dataharvest.base import DataHarvest
from dataharvest.searcher import TavilySearcher
searcher = TavilySearcher()
dh = DataHarvest()
r = searcher.search("战国水晶杯")
tasks = [dh.a_crawl_and_purify(item.url) for item in r.items]
loop = asyncio.get_event_loop()
docs = loop.run_until_complete(asyncio.gather(*tasks))
搜索
from dataharvest.searcher import TavilySearcher
api_key = "xxx" # 或者设置环境变量 TAVILY_API_KEY
searcher = TavilySearcher(api_key)
searcher.search("战国水晶杯")
SearchResult(keyword='战国水晶杯', answer=None, images=None, items=[
SearchResultItem(title='战国水晶杯_百度百科', url='https://baike.baidu.com/item/战国水晶杯/7041521', score=0.98661,
description='战国水晶杯为战国晚期水晶器皿,于1990年出土于浙江省杭州市半山镇石塘村,现藏于杭州博物馆。战国水晶杯高15.4厘米、口径7.8厘米、底径5.4厘米,整器略带淡琥珀色,局部可见絮状包裹体;器身为敞口,平唇,斜直壁,圆底,圈足外撇;光素无纹,造型简洁。',
content='')])
爬取
from dataharvest.spider import AutoSpider
url = "https://baike.so.com/doc/5579340-5792710.html?src=index#entry_concern"
auto_spider = AutoSpider()
doc = auto_spider.crawl(url)
print(doc)
代理
很多情况下我们需要配置代理,比如小红书和马蜂窝。 我们需要实现 一个代理生成类,并实现他的__call__方法。
可以在爬虫初始化时,将配置添加进去,也可以在调用时传入。
from dataharvest.proxy.base import BaseProxy, Proxy
from dataharvest.spider import AutoSpider
from dataharvest.spider.base import SpiderConfig
class MyProxy(BaseProxy):
def __call__(self) -> Proxy:
return Proxy(protocol="http", host="127.0.0.1", port="53380", username="username", password="password")
def test_proxy_constructor():
proxy_gene_func = MyProxy()
auto_spider = AutoSpider(config=SpiderConfig(proxy_gene_func=proxy_gene_func))
url = "https://baike.baidu.com/item/%E6%98%8E%E5%94%90%E5%AF%85%E3%80%8A%E7%81%8C%E6%9C%A8%E4%B8%9B%E7%AF%A0%E5%9B%BE%E8%BD%B4%E3%80%8B?fromModule=lemma_search-box"
doc = auto_spider.crawl(url)
print(doc)
def test_proxy_call():
proxy_gene_func = MyProxy()
auto_spider = AutoSpider()
config = SpiderConfig(proxy_gene_func=proxy_gene_func)
url = "https://baike.baidu.com/item/%E6%98%8E%E5%94%90%E5%AF%85%E3%80%8A%E7%81%8C%E6%9C%A8%E4%B8%9B%E7%AF%A0%E5%9B%BE%E8%BD%B4%E3%80%8B?fromModule=lemma_search-box"
doc = auto_spider.crawl(url, config=config)
print(doc)
清洗
from dataharvest.purifier import AutoPurifier
from dataharvest.spider import AutoSpider
url = "https://baike.so.com/doc/5579340-5792710.html?src=index#entry_concern"
auto_spider = AutoSpider()
doc = auto_spider.crawl(url)
print(doc)
auto_purifier = AutoPurifier()
doc = auto_purifier.purify(doc)
print(doc)
效果:
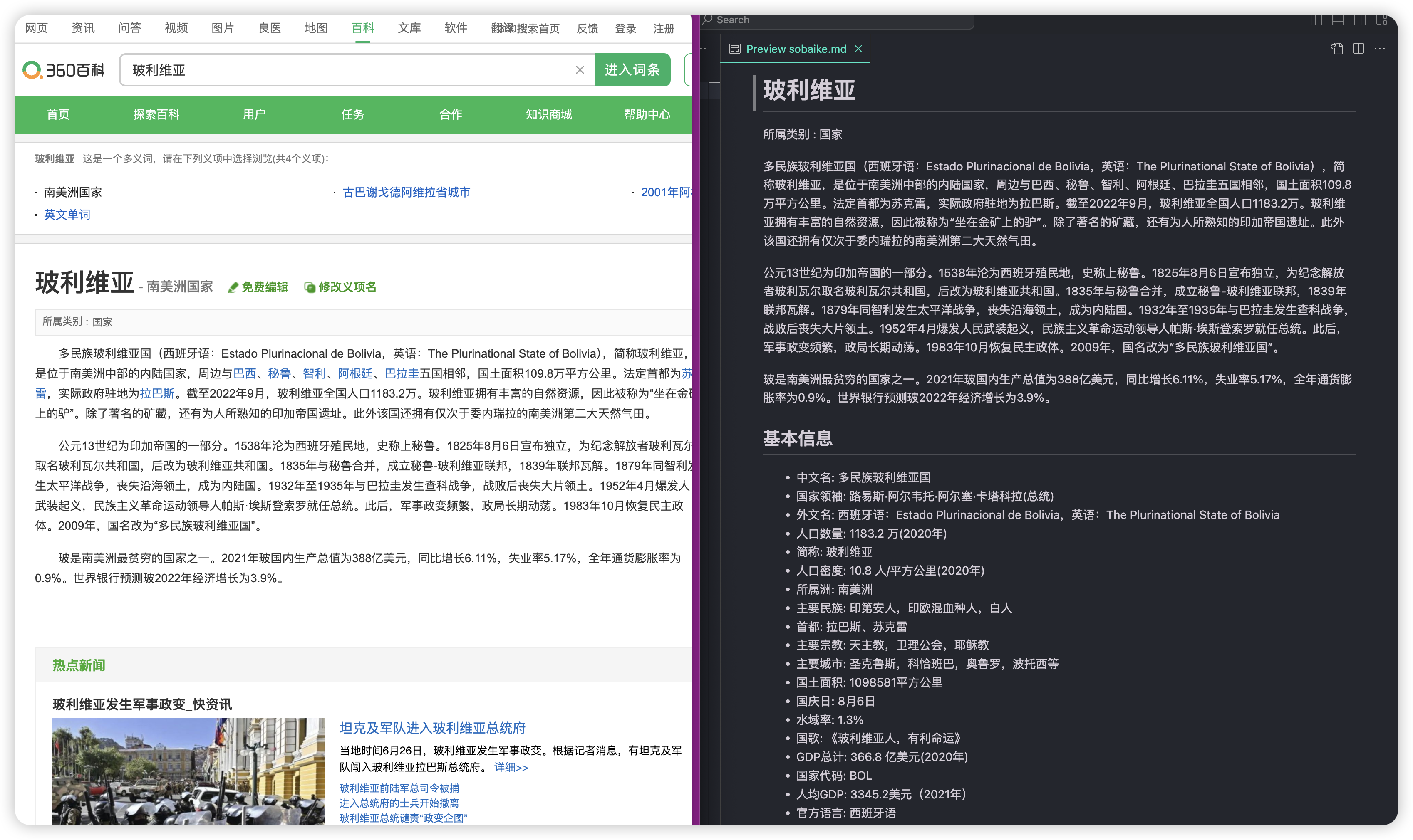
鸣谢
伙伴们如果觉着这个项目对你有帮助,那么请帮助点一个star✨。如果觉着存在问题或者有其他需求,那么欢迎在issue提出。当然,我们非常欢迎您加入帮忙完善。
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dataharvest-0.2.14.tar.gz.
File metadata
- Download URL: dataharvest-0.2.14.tar.gz
- Upload date:
- Size: 13.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f0c5f485443193577aa5aa539a3947601185d5bdaf7f21227bd01ee8968ff514
|
|
| MD5 |
4349509d059f197a357a089a1d8d674c
|
|
| BLAKE2b-256 |
c52b6f77b523a8ca9f863bd1ba68710319d180f83708cf6c4d0d41fd43d01b7a
|
File details
Details for the file dataharvest-0.2.14-py3-none-any.whl.
File metadata
- Download URL: dataharvest-0.2.14-py3-none-any.whl
- Upload date:
- Size: 24.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
356a004755713590358ba8fb31925c4bc55ff07d818770796571ad1bc093565b
|
|
| MD5 |
2670f200d30c4d0625acb7c2101c849c
|
|
| BLAKE2b-256 |
d847ad8bdfff65e7a42930f007ce2d78fb68b196e28e1426ee5c6fa947cdf4ed
|







