A package that can perform on-the-fly denormalization

Project description
db_extract
Overview
db_extract is a python module that can perform on-the-fly denormalization from a relational dataset. The module calculates metadata to construct a graph representation of the dataset, and with this construct, finds ways to join widely separated tables without having to perform manual table inspection. This is similar to Neo4j, however setup and querying with this module requires only a couple of lines of code.
For example, if you are interested in data from tables A and D that have two join paths:
- A JOIN B ON AB JOIN C ON BC JOIN D ON CD
- A JOIN XYZ ON AXYZ JOIN D ON XYZD
You can simply input parameters [A, D] and the module will provide all possible join paths for you, which can then in turn be used to get a dataframe containing the data of interest.
The user will find this module to be of most use when working with highly normalized datasets, however it can also be used with datasets with only a few tables as well.
Current support for
- Data separated into files (most commonly CSV)
- Microsoft SQL Server
Requirements
If you are connecting to a MS SQL Server database, then you must have an ODBC driver installed on your system for use with pyodbc.
First-time setup
Run the following command
python setup.py
This will set up the SQLite database metadata.db which will be used to store information about the datasets and will also store connections between tables. If interested, you can browse the data using DB Browser for SQLite.
Algorithm Explanation
Many-one and one-one relationships can be joined in any order, but many-many relationships cannot be joined together directly. The problem becomes more evident as you start chaining together many joins where you might be able to join A with B, and B with C, but can't join together A, B, and C all together.
This module uses networkx to construct a directed graph showing these relationships, representing tables as nodes and joining columns as edges.
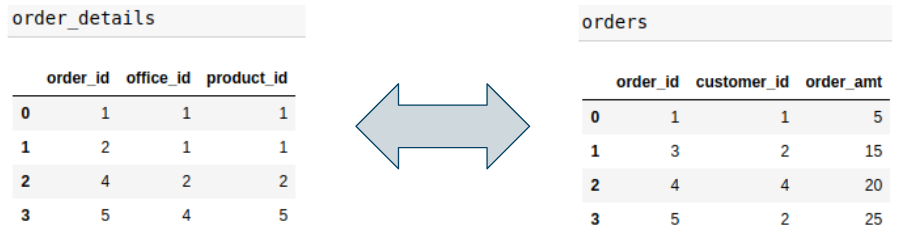
order_details and orders share a one-to-one relationship on column order_id, and are represented with a bidirectional edge.

order_details and offices share a many-to-one relationship on column office_id, and are represented with a unidirectional edge starting from the many table and pointing to the one table.

Above we can see that order_details and offices can be joined together as a many-to-one relationship, and employees and offices can also be joined in the same manner. However see what happens when we try to join all three tables together:
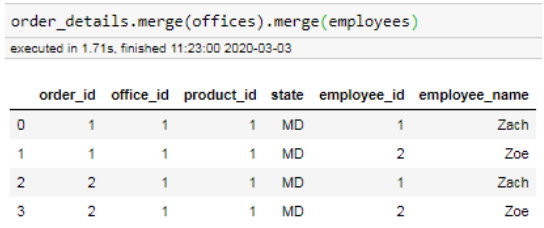
The result is nonsensical.
The module identifies valid join paths by identifying whether there is a singular origin node from which it can draw a path to every other node that needs to be included. Sometimes this origin node may be upstream from the tables that you are interested in. In the above example, there is no way to start from any single table and draw a path to the other two tables, and so the module recognizes this as an invalid combination of tables.
Demonstration
We will use a modified version of the Northwind dataset (CSV files originally taken from here), the files are included in this package. To initialize the dataset, run the following code:
from db_extract import DBSetup, DBExtractor, Filter
import db_extract.constants as c
nw_setup = DBSetup('Northwind')
nw_setup.create_metadata(
data_folder_path='/your/python/lib/path/db_extract/datasets/Northwind/',
dump_to_data_db=True
)
Supplying the dump_to_data_db option will store a copy of the data in a data.db SQLite file located in the same folder (only available when using a collection of files) for more efficient joining.
We still haven't defined any relationships between the tables. If we run
nw_setup.get_common_column_names()
This will spit out a list of columns that have the same names in multiple files, which usually are used for joining. We see that there are a lot of common column names such as supplierID, categoryID, contactName, contactTitle, etc. It's clear that the columns used for joining are all labeled with "ID" so we can run the following code to connect all tables.
for i in nw_setup.get_common_column_names():
if i[-2:] == 'ID':
nw_setup.add_global_fk(i)
That's all the setup that is required. If you wanted to visualize the graph in a Jupyter notebook, you can run the following code- (WARNING: networkx only has rudimentary visualization capabilities so the result will likely look strange and may require a few tries to get something that looks legible because networkx draws it differently each time. pygraphviz is another option but also takes work to get it to look right.):
import networkx as nx
import matplotlib.pyplot as plt
nw_extractor = DBExtractor('Northwind')
nx.draw_networkx(nw_extractor.G, node_shape="None")
. You'll get something similar to the following:
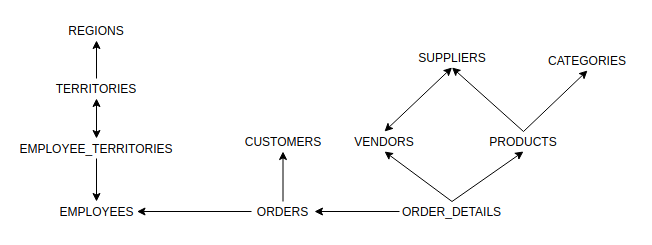
Let's say we are interested in figuring out how many units each supplier has provided. The tables of interest are order_details and suppliers
nw_extractor.find_paths_multi_tables(['order_details', 'suppliers'])
#RESULT
[
[
('order_details', 'vendors'),
('vendors', 'suppliers')
],
[
('order_details', 'products'),
('products', 'suppliers')
]
]
So there are two ways to join order_details and products together, either going through vendors or through suppliers, both are valid ways to do it. Later you realize that you also want the category of the products sold.
nw_extractor.find_paths_multi_tables(['order_details', 'suppliers', 'categories'])
#RESULT
[
[
('order_details', 'products'),
('products', 'suppliers'),
('products', 'categories')
]
]
Now there's only one path. Going through vendors is superfluous because you must go through products to get to categories anyway.
Now let's get a dataframe out of this:
filters = {
'categories': [
Filter(filter_type=c.FILTER_TYPE_SELECTION, column='categoryName', selection=['Condiments'])
],
'order_details': [
Filter(filter_type=c.FILTER_TYPE_RANGE, column='quantity', range_min=10, range_max=30)
]
}
select_table_columns = {
'order_details': ['quantity', 'discount'],
'suppliers': ['contactName'],
'products': ['productName']
}
df = nw_extractor.get_df_from_path(
[('order_details', 'products'),
('products', 'suppliers'),
('products', 'categories')],
filters=filters,
select_table_columns=select_table_columns
)
| order_details_quantity | order_details_discount | suppliers_contactName | products_productName |
|---|---|---|---|
| 14 | 0 | Charlotte Cooper | Aniseed Syrup |
| 20 | 0 | Charlotte Cooper | Aniseed Syrup |
| 20 | 0.1 | Charlotte Cooper | Aniseed Syrup |
| 20 | 0.1 | Charlotte Cooper | Aniseed Syrup |
| 10 | 0 | Shelley Burke | Chef Anton's Cajun Seasoning |
| 10 | 0.1 | Shelley Burke | Chef Anton's Cajun Seasoning |
| 12 | 0.1 | Shelley Burke | Chef Anton's Cajun Seasoning |
filters and select_table_columns are optional parameters. Above, we have decided that we only are interested in orders involving condiments, with a quantity of 10-30. The data that we are interested in is quantity, discount amount, supplier contact name, and product name.
As mentioned earlier, the module will also prevent trying to do joins that make no sense.
nw_extractor.find_paths_multi_tables(['orders', 'territories'])
#RESULT
[]
Looking at the schema above, there's no node that you can start from and draw a path to both orders and territories. On inspecting the data, it becomes evident that this is because an employee may sell to multiple territories, so we can't connect the order to the territories because we only have data on the employee that made the order.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file db_extract-0.2-py3-none-any.whl.
File metadata
- Download URL: db_extract-0.2-py3-none-any.whl
- Upload date:
- Size: 23.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.1.0 requests-toolbelt/0.9.1 tqdm/4.43.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
95199386e085ab82a2066f742cedd699fc4f46e16400af873794d266816d11a0
|
|
| MD5 |
0a0024fd3556a930c1d8a681ac335da2
|
|
| BLAKE2b-256 |
0261bc0c58c3c2047f7c7949308d563a09084ab35b98c62cd3f70e23b49d0dc5
|







