Deep CFR Poker AI with Opponent Modeling

Project description
DeepCFR Poker AI
Project Update (March 2025)
Due to the success of this project, I'm committing more time and attention to further development. I've outlined two key initiatives:
-
Release Schedule: I'll be publishing regular updates with new features and improvements.
- v2.1 (April 2025): ✅ Fixed bet calculation for stable training, ✅ Implemented opponent modeling capabilities, Expanded bet sizing options and performance optimizations, Advanced architectures and training methods
- v2.2 (June 2025): Web interface for playing against the AI, API Endpoints for integration, Export to ONNX format for deployment
-
Feature Roadmap: I've created a comprehensive checklist of upcoming features that I plan to implement, including model architecture enhancements, training improvements, and advanced techniques.
I welcome contributions and feedback from the community as this project continues to evolve!
A deep learning implementation of Counterfactual Regret Minimization (CFR) for No-Limit Texas Hold'em Poker. This project demonstrates advanced reinforcement learning techniques applied to imperfect information games.
Note: This project builds on the straightforward and flexible Pokers environment—a minimalistic no-limit Texas Hold'em simulator designed for reinforcement learning. Pokers cuts out the fuss by using a simple
new_state = state + actionmodel, making it really easy to integrate with any framework. While its simplicity is a major plus, it's also a side project that might have some bugs in less-tested areas. If you need rock-solid reliability, you might consider alternatives like RLCard. Huge thanks to the creators of Pokers for their innovative and accessible work!
Note A more comprehensive explanation of this project can be found here: Mastering Poker with Deep CFR: Building an AI for 6-Player No-Limit Texas Hold'em
Introduction: Why Poker AI Matters
Poker represents one of the greatest challenges in artificial intelligence—a game of incomplete information where players must make decisions without knowing all the relevant facts. Unlike chess or Go, where all information is visible to both players, poker requires reasoning under uncertainty, risk assessment, opponent modeling, and strategic deception. This project implements Deep Counterfactual Regret Minimization (Deep CFR), a cutting-edge algorithm that has revolutionized how AI approaches imperfect information games. By building a poker AI that can compete at a high level, we're developing capabilities that transfer to numerous real-world scenarios:
Real-World Applications
- Financial Trading: Making investment decisions under market uncertainty with incomplete information
- Healthcare: Treatment planning with uncertain patient outcomes and incomplete medical history
- Cybersecurity: Defending systems when attacker capabilities and targets are unknown
- Business Negotiation: Strategic decision-making when counterparty intentions are hidden
- Resource Allocation: Optimizing distribution under uncertainty (emergency services, supply chain)
- Autonomous Vehicles: Decision-making in dynamic traffic environments with unpredictable human behavior
Overview
This repository implements Deep Counterfactual Regret Minimization (Deep CFR), an advanced reinforcement learning algorithm for solving imperfect information games. The implementation focuses on No-Limit Texas Hold'em Poker, one of the most challenging games for AI due to:
- Hidden information (opponents' cards)
- Stochastic elements (card dealing)
- Sequential decision-making
- Large state and action spaces
The agent learns by playing against random opponents, specialized opponents via opponent modeling, and self-play, using neural networks to approximate regret values and optimal strategies.
Architecture
The implementation consists of four main components:
-
Model Architecture (
model.py)- Neural network definition
- State encoding/representation
- Forward pass implementation
-
Deep CFR Agent (
deep_cfr.py)- Advantage network for regret estimation
- Strategy network for action selection
- Memory buffers for experience storage
- CFR traversal implementation
- Training procedures
-
Opponent Modeling (
opponent_modeling/)- RNN-based action history encoding
- Opponent tendency prediction
- Adaptive strategy selection
- Behavioral pattern exploitation
-
Training Pipeline (
training/)- Basic training implementation (against random agents)
- Self-play training (against checkpoints)
- Mixed training (against pools of agents)
- Opponent modeling training variants
- Metrics tracking and logging
- Model checkpointing and saving
Architecture Diagram
flowchart TB
subgraph InputState["State Encoding (500 dimensions)"]
direction TB
Input1["Player's Cards (52)"]
Input2["Community Cards (52)"]
Input3["Game Stage (5)"]
Input4["Pot Size (1)"]
Input5["Button Position (n_players)"]
Input6["Current Player (n_players)"]
Input7["Player States (n_players * 4)"]
Input8["Min Bet (1)"]
Input9["Legal Actions (4)"]
Input10["Previous Action (5)"]
end
subgraph PokerNetwork["PokerNetwork Neural Network"]
direction TB
FC1["FC1: Linear(500, 256)"]
FC2["FC2: Linear(256, 256)"]
FC3["FC3: Linear(256, 256)"]
FC4["FC4: Linear(256, 4)"]
ReLU1["ReLU Activation"]
ReLU2["ReLU Activation"]
ReLU3["ReLU Activation"]
FC1 --> ReLU1
ReLU1 --> FC2
FC2 --> ReLU2
ReLU2 --> FC3
FC3 --> ReLU3
ReLU3 --> FC4
end
subgraph DeepCFRAgent["DeepCFR Agent"]
direction TB
AdvNet["Advantage Network\n(PokerNetwork)"]
StratNet["Strategy Network\n(PokerNetwork)"]
AdvMem["Advantage Memory\n(deque, max_size=200000)"]
StratMem["Strategy Memory\n(deque, max_size=200000)"]
AdvOpt["Adam Optimizer\n(lr=0.0001, weight_decay=1e-5)"]
StratOpt["Adam Optimizer\n(lr=0.0001, weight_decay=1e-5)"]
end
subgraph OpponentModeling["Opponent Modeling System"]
direction TB
HistEnc["Action History Encoder\n(RNN-based)"]
OppModel["Opponent Model\n(Tendency Prediction)"]
OppMem["Opponent Memory\n(Historical Actions)"]
AdaptStrat["Adaptive Strategy"]
end
subgraph TrainingPhase["Deep CFR Training Process"]
direction TB
CFRTraverse["CFR Traverse\n(MCCFR with external sampling)"]
TrainAdv["Train Advantage Network\n(Huber Loss)"]
TrainStrat["Train Strategy Network\n(Cross-Entropy Loss)"]
CFRTraverse --> TrainAdv
CFRTraverse --> TrainStrat
end
subgraph ActionSelection["Action Selection"]
direction TB
Legal["Filter Legal Actions"]
Strategy["Get Strategy from Network"]
ActionConvert["Convert to Poker Actions"]
Legal --> Strategy
Strategy --> ActionConvert
end
InputState --> PokerNetwork
PokerNetwork --> DeepCFRAgent
InputState --> OpponentModeling
OpponentModeling --> DeepCFRAgent
DeepCFRAgent --> TrainingPhase
DeepCFRAgent --> ActionSelection
subgraph DataFlow["Data Flow During Training"]
direction TB
State1["Encode State"]
RegretCalc["Calculate Counterfactual Regrets"]
MemoryStore["Store in Memory Buffers"]
BatchSample["Sample Batches"]
UpdateNets["Update Networks"]
State1 --> RegretCalc
RegretCalc --> MemoryStore
MemoryStore --> BatchSample
BatchSample --> UpdateNets
end
TrainingPhase --> DataFlow
subgraph ActionMapping["Action Mapping"]
Action0["0: Fold"]
Action1["1: Check/Call"]
Action2["2: Raise (0.5x pot)"]
Action3["3: Raise (1x pot)"]
end
ActionSelection --> ActionMapping
Technical Implementation
Neural Networks
The project uses PyTorch to implement:
- Advantage Network: Predicts counterfactual regrets for each action
- Strategy Network: Outputs a probability distribution over actions
- Opponent History Encoder: RNN-based network that processes opponent action sequences
- Opponent Model: Predicts opponent tendencies based on encoded history
The architecture includes:
- Fully connected layers with ReLU activations for advantage and strategy
- GRU-based sequence processing for opponent history encoding
- Enhanced networks with opponent feature integration
- Input size determined by state encoding (cards, bets, game state)
- Output size matching the action space
Opponent Modeling
The opponent modeling system includes:
- Action History Tracking: Records sequences of actions by each opponent
- Context-Aware Encoding: Pairs actions with game state contexts
- RNN-Based Processing: Uses recurrent networks to identify patterns in play
- Adaptive Strategy Selection: Modifies the agent's strategy based on opponent tendencies
- Separate Models Per Opponent: Maintains individualized models for different opponents
State Representation
Game states are encoded as fixed-length vectors that capture:
- Player hole cards (52 dimensions for card presence)
- Community cards (52 dimensions)
- Game stage (5 dimensions for preflop, flop, turn, river, showdown)
- Pot size (normalized)
- Player positions and button
- Current player
- Player states (active status, bets, chips)
- Legal actions
- Previous actions
Action Space
The agent can select from four strategic actions:
- Fold
- Check/Call
- Raise 0.5x pot
- Raise 1x pot
Counterfactual Regret Minimization
The implementation uses external sampling Monte Carlo CFR:
- Regret values are used to guide exploration
- Strategy improvement over iterations
- Regret matching for action selection
- Importance sampling for efficient learning
Training Process
The training procedure includes:
- Data generation through game tree traversal
- Experience collection in memory buffers
- Regular network updates
- Periodic strategy network training
- Opponent modeling updates
- Regular evaluation against random and model opponents
- Progress tracking via TensorBoard
Performance Optimizations
The implementation includes various optimizations:
- Gradient clipping to prevent exploding gradients
- Huber loss for robust learning with outliers
- Regret normalization and clipping
- Linear CFR weighting for faster convergence
- Efficient memory management
- Fixed bet calculation for stable training
- Enhanced error handling and monitoring
Requirements
- Python 3.8+
- PyTorch 1.9+
- NumPy
- Matplotlib
- TensorBoard
- Pokers ("Embarrassingly simple" poker environment from Bruno Santidrian and Betagmr)
Installation
# Clone the repository
git clone https://github.com/dberweger2017/deepcfr.git
cd deepcfr-poker
# Create a virtual environment
python3 -m venv venv
source venv/bin/activate # On Windows, use `venv\Scripts\activate`
# Install dependencies
pip install -r requirements.txt
pip install -e .
# Install the poker environment
pip install pokers
Usage Guides
DeepCFR Poker Training Guide
This guide provides a quick reference for training your Deep Counterfactual Regret Minimization (Deep CFR) poker agent using different methods.
Training Commands
Basic Training (vs Random Agents)
Train a new agent against random opponents:
python -m src.training.train --iterations 1000 --traversals 200
Continue Training from Checkpoint
Resume training from a saved checkpoint against random opponents:
python -m src.training.train --checkpoint models/checkpoint_iter_1000.pt --iterations 1000
Self-Play Training
Train against a fixed checkpoint opponent:
python -m src.training.train --checkpoint models/checkpoint_iter_1000.pt --self-play --iterations 1000
Mixed Checkpoint Training
Train against a rotating pool of checkpoint opponents:
python -m src.training.train --mixed --checkpoint-dir models --model-prefix t_ --refresh-interval 1000 --num-opponents 5 --iterations 10000
Continue an existing agent with mixed checkpoint training:
python -m src.training.train --mixed --checkpoint models/checkpoint_iter_1000.pt --checkpoint-dir models --model-prefix t_ --iterations 1000
Basic Opponent Modeling Training
Train a new agent with opponent modeling against random opponents:
python -m src.training.train_with_opponent_modeling --iterations 1000 --traversals 200 --save-dir models_om --log-dir logs/deepcfr_om
Mixed Opponent Modeling Training
Train with opponent modeling against a rotating pool of checkpoint opponents:
python -m src.training.train_mixed_with_opponent_modeling --checkpoint-dir models_om --model-prefix "*" --iterations 10000 --traversals 200 --refresh-interval 1000 --num-opponents 5 --save-dir models_mixed_om --log-dir logs/deepcfr_mixed_om
Parameters
| Parameter | Description | Default |
|---|---|---|
--iterations |
Number of training iterations | 1000 |
--traversals |
Number of game traversals per iteration | 200 |
--save-dir |
Directory to save model checkpoints | "models" |
--log-dir |
Directory for TensorBoard logs | "logs/deepcfr" |
--checkpoint |
Path to checkpoint file to continue training | None |
--verbose |
Enable detailed output | False |
--self-play |
Train against checkpoint instead of random agents | False |
--mixed |
Use mixed checkpoint training | False |
--checkpoint-dir |
Directory containing checkpoint models for mixed training | "models" |
--model-prefix |
Prefix for models to include in mixed training pool | "t_" |
--refresh-interval |
How often to refresh opponents in mixed training | 1000 |
--num-opponents |
Number of checkpoint opponents to use in mixed training | 5 |
Training Strategies
Random Opponent Training
- Fastest training method
- Good for initial learning
- Agent may overfit to exploit random play
Self-Play Training
- Trains against a fixed strong opponent
- Helps develop more balanced strategies
- May develop specific counter-strategies to the opponent
Mixed Checkpoint Training
- Most robust training method
- Prevents overfitting to specific opponent types
- Provides diverse learning experiences
- Closest approximation to Nash equilibrium training
Opponent Modeling Training
- Learns to identify and exploit opponent patterns
- Adapts strategy based on individual opponents
- Provides more human-like adaptability
- Best for developing agents that exploit weaknesses
Monitoring Training
Monitor training progress with TensorBoard:
tensorboard --logdir=logs
Then open http://localhost:6006 in your browser.
Deep CFR Poker Play Guide
This guide will help you play against your trained Deep CFR poker agents using the interactive command-line interface.
Getting Started
To start a poker game against AI opponents, use one of the following scripts:
play.py- Play against randomly selected models from a directory
Play Commands
Playing Against Random Models
python play_against_random_models.py --models-dir models
Command Line Options
| Option | Description | Default |
|---|---|---|
--models |
List of specific model paths to use as opponents | [] |
--models-dir |
Directory containing model checkpoint files | None |
--model-pattern |
File pattern to match model files (e.g., "*.pt") | "*.pt" |
--num-models |
Number of models to select randomly | 5 |
--position |
Your position at the table (0-5) | 0 |
--stake |
Initial chip stack for all players | 200.0 |
--sb |
Small blind amount | 1.0 |
--bb |
Big blind amount | 2.0 |
--verbose |
Show detailed debug output | False |
--no-shuffle |
Keep the same random models for all games | False |
Game Interface
During gameplay, you'll see the current game state displayed, including:
- Your hand cards
- Community cards
- Pot size
- Position of each player
- Current bets
- Available actions
Available Actions
When it's your turn to act, you can use these commands:
| Command | Action |
|---|---|
f |
Fold |
c |
Check (if available) or Call |
r |
Raise (custom amount) |
h |
Raise half the pot |
p |
Raise the full pot amount |
m |
Raise a custom amount |
For raises, you can use the shortcuts above or enter a custom amount when prompted.
Example Game State
======================================================================
Stage: Flop
Pot: $12.00
Button position: Player 3
Community cards: 2♥ K♠ 10♣
Your hand: A♥ K♥
Players:
Player 0 (YOU): $195.00 - Bet: $3.00 - Active
Player 1 (AI): $195.00 - Bet: $3.00 - Active
Player 2 (AI): $200.00 - Bet: $0.00 - Folded
Player 3 (AI): $198.00 - Bet: $2.00 - Active
Player 4 (AI): $199.00 - Bet: $1.00 - Active
Player 5 (AI): $195.00 - Bet: $3.00 - Active
Legal actions:
c: Check
r: Raise (min: $3.00, max: $195.00)
h: Raise half pot
p: Raise pot
m: Custom raise amount
======================================================================
Advanced Usage
Playing Against Models of Different Strengths
# Use only models that have been trained for at least 1000 iterations
python play_against_random_models.py --models-dir models --model-pattern "*_iter_1???.pt"
Mixing in Random Agents
# Use only 2 trained models, the rest will be random agents
python play_against_random_models.py --models-dir models --num-models 2
Changing Table Position
# Play from the button position (typically position 5 in 6-player game)
python play_against_random_models.py --models-dir models --position 5
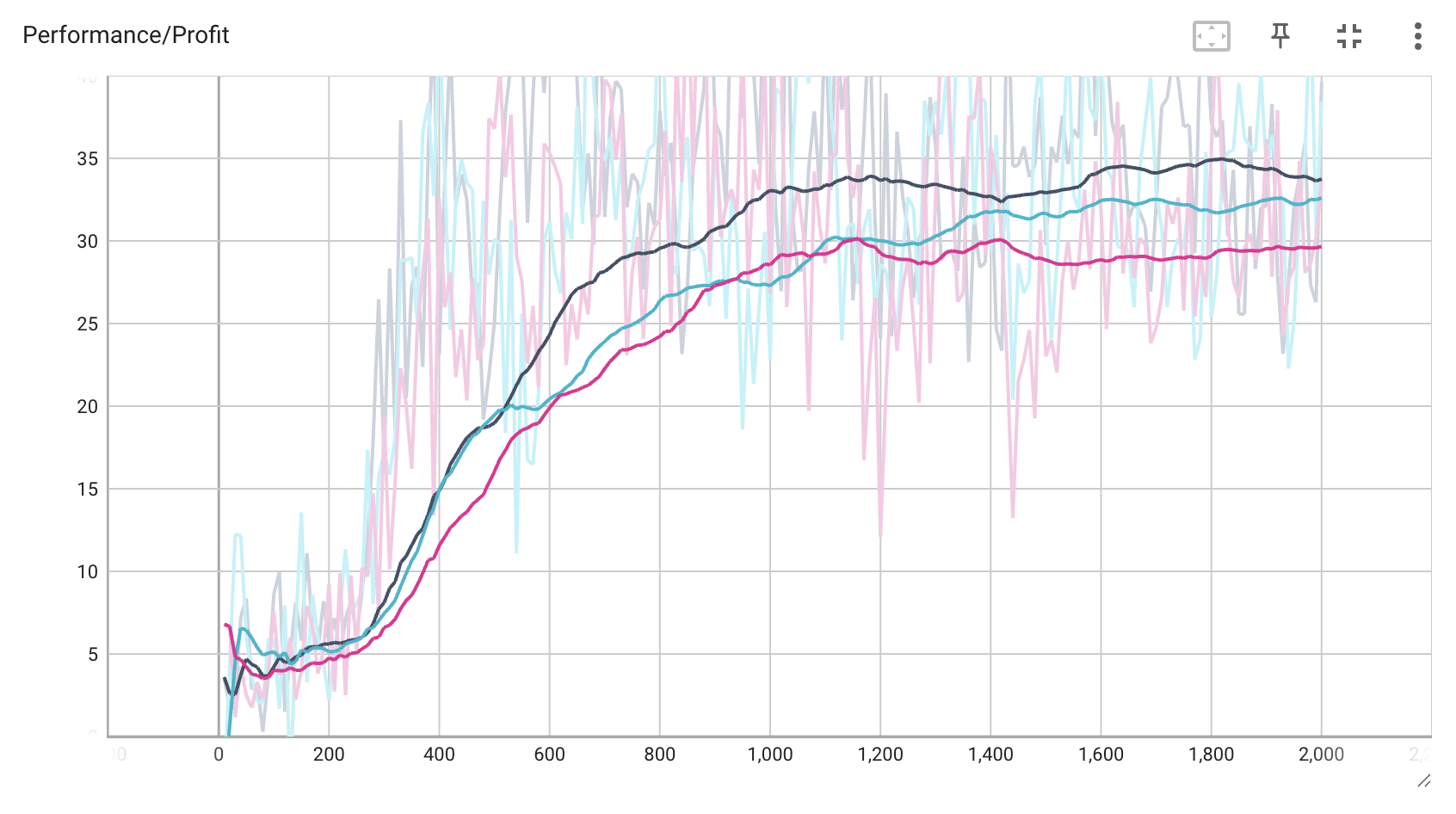
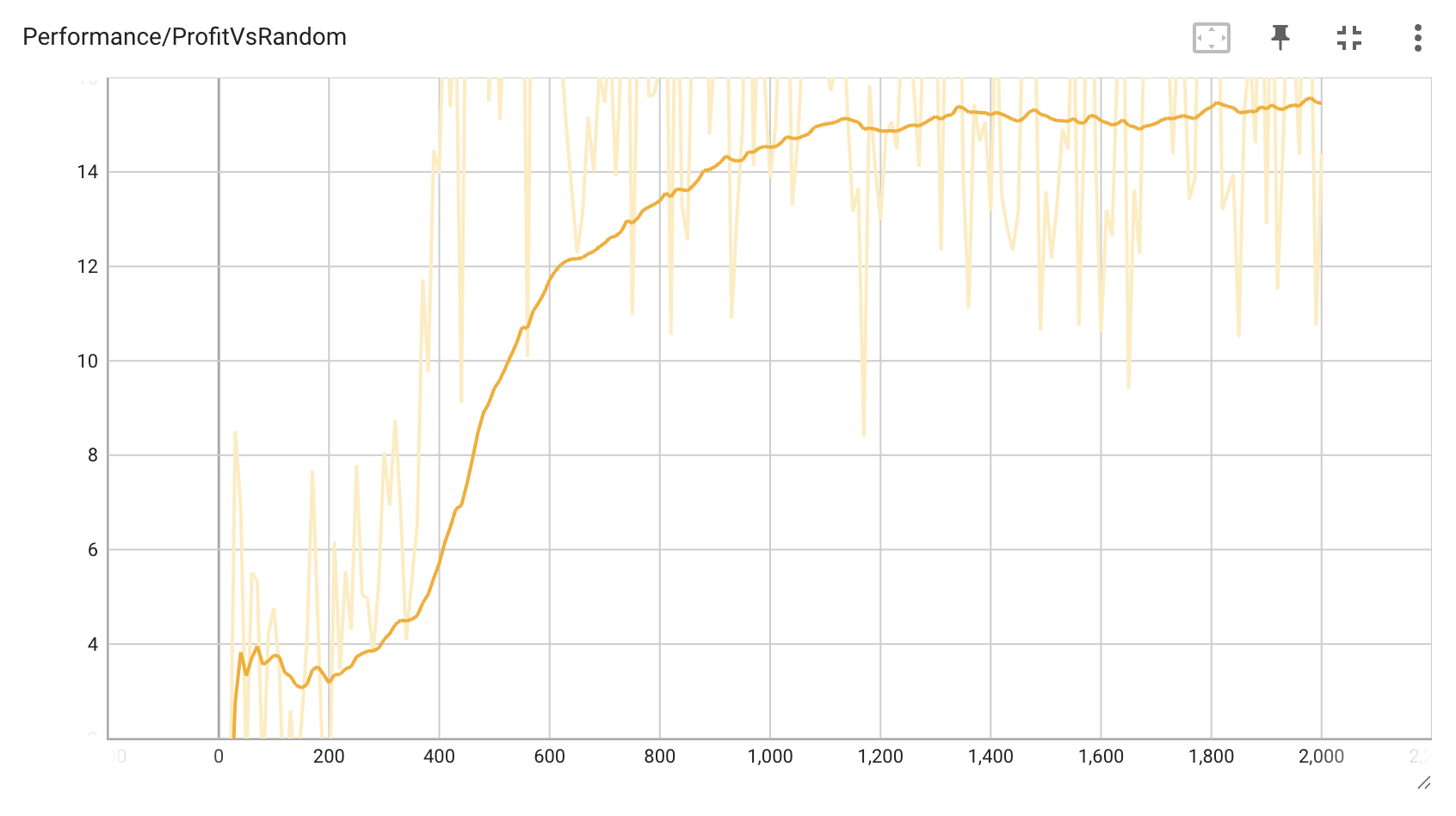
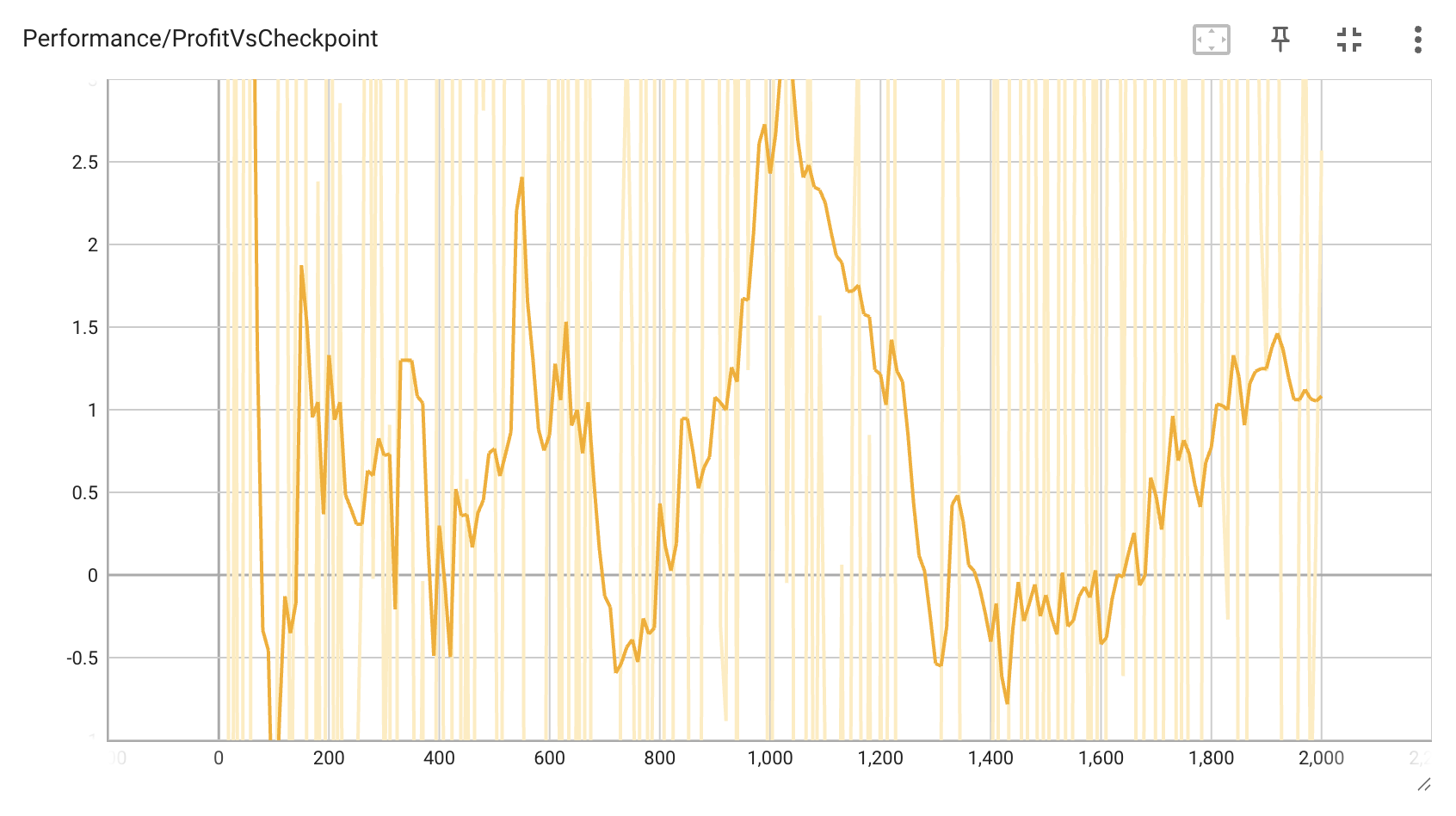
Results
After training, the agent achieves:
- Positive expected value against random opponents
- Increasing performance over training iterations
- Sophisticated betting strategies
- Adaptive play against different opponent styles
Repository Growth
Because apparently every cool GitHub repository needs to show off its star history chart, here's mine too:

Future Work
- Expand the action space with more bet sizing options
- Experiment with alternative network architectures (CNN, Transformers)
- Parallel data generation for faster training
- Develop a more diverse set of evaluation opponents
- Enhanced opponent clustering for group-based modeling
- Meta-learning approaches for faster adaptation
References
- Brown, N., & Sandholm, T. (2019). Deep Counterfactual Regret Minimization. ICML.
- Zinkevich, M., Johanson, M., Bowling, M., & Piccione, C. (2008). Regret Minimization in Games with Incomplete Information. NIPS.
- Heinrich, J., & Silver, D. (2016). Deep Reinforcement Learning from Self-Play in Imperfect-Information Games. arXiv preprint.
License
This project is licensed under the MIT License - see the LICENSE file for details.
In non-lawyer terms: Do whatever you want with this software. If you use my code or models without making significant modifications, I'd appreciate it if you acknowledged my work.
Acknowledgments
- The creators and maintainers of Reinforcement-Poker/pokers for providing a straightforward and effective poker environment that really makes the project shine
- The Annual Computer Poker Competition for inspiration
- OpenAI and DeepMind for pioneering work in game AI
- The PyTorch team for their excellent deep learning framework
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file deepcfr_poker-0.2.1.tar.gz.
File metadata
- Download URL: deepcfr_poker-0.2.1.tar.gz
- Upload date:
- Size: 52.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
47bb008751c166fd9dd04bd136c09486f1d202cbf194e65106907228f48b96ad
|
|
| MD5 |
e2b5767b5ab37fa9430ab4be50c2e870
|
|
| BLAKE2b-256 |
3a0891b5604cfd231bb603e37ef63338b2cf5ed233ea264e340323be2008c621
|
File details
Details for the file deepcfr_poker-0.2.1-py3-none-any.whl.
File metadata
- Download URL: deepcfr_poker-0.2.1-py3-none-any.whl
- Upload date:
- Size: 48.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ca27ca1bb421e92bb6d7494eb03a2879c7fdd1c8da131b5dc69c4b0d5b3dda83
|
|
| MD5 |
44300a9a3cdc1ca2a0517a237feb61dd
|
|
| BLAKE2b-256 |
1c41050ef3e4160757d6ef87d333e30af7d4705099fbecee80a8aaafe48d00a3
|







