An inference runtime offering GPU-class performance on CPUsand APIs to integrate ML into your application

Project description
 DeepSparse
DeepSparse
An inference runtime offering GPU-class performance on CPUs and APIs to integrate ML into your application
A CPU runtime that takes advantage of sparsity within neural networks to reduce compute. Read more about sparsification.
Neural Magic's DeepSparse is able to integrate into popular deep learning libraries (e.g., Hugging Face, Ultralytics) allowing you to leverage DeepSparse for loading and deploying sparse models with ONNX. ONNX gives the flexibility to serve your model in a framework-agnostic environment. Support includes PyTorch, TensorFlow, Keras, and many other frameworks.
DeepSparse is available in two editions:
- DeepSparse Community is open-source and free for evaluation, research, and non-production use with our DeepSparse Community License.
- DeepSparse Enterprise requires a Trial License or can be fully licensed for production, commercial applications.
Features
🧰 Hardware Support and System Requirements
Review Supported Hardware for DeepSparse to understand system requirements. DeepSparse works natively on Linux; Mac and Windows require running Linux in a Docker or virtual machine; it will not run natively on those operating systems.
DeepSparse is tested on Python 3.7-3.10, ONNX 1.5.0-1.12.0, ONNX opset version 11+, and manylinux compliant. Using a virtual environment is highly recommended.
Installation
Install DeepSparse Community as follows:
pip install deepsparse
To install the DeepSparse Enterprise, trial or inquire about licensing for DeepSparse Enterprise, see the DeepSparse Enterprise documentation.
Features
🔌 DeepSparse Server
DeepSparse Server allows you to serve models and pipelines from the terminal. The server runs on top of the popular FastAPI web framework and Uvicorn web server. Install the server using the following command:
pip install deepsparse[server]
Single Model
Once installed, the following example CLI command is available for running inference with a single BERT model:
deepsparse.server \
task question_answering \
--model_path "zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/12layer_pruned80_quant-none-vnni"
To look up arguments run: deepsparse.server --help.
Multiple Models
To serve multiple models in your deployment you can easily build a config.yaml. In the example below, we define two BERT models in our configuration for the question answering task:
num_cores: 1
num_workers: 1
endpoints:
- task: question_answering
route: /predict/question_answering/base
model: zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/base-none
batch_size: 1
- task: question_answering
route: /predict/question_answering/pruned_quant
model: zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/12layer_pruned80_quant-none-vnni
batch_size: 1
Finally, after your config.yaml file is built, run the server with the config file path as an argument:
deepsparse.server config config.yaml
Getting Started with DeepSparse Server for more info.
📜 DeepSparse Benchmark
The benchmark tool is available on your CLI to run expressive model benchmarks on DeepSparse with minimal parameters.
Run deepsparse.benchmark -h to look up arguments:
deepsparse.benchmark [-h] [-b BATCH_SIZE] [-shapes INPUT_SHAPES]
[-ncores NUM_CORES] [-s {async,sync}] [-t TIME]
[-nstreams NUM_STREAMS] [-pin {none,core,numa}]
[-q] [-x EXPORT_PATH]
model_path
Getting Started with CLI Benchmarking includes examples of select inference scenarios:
- Synchronous (Single-stream) Scenario
- Asynchronous (Multi-stream) Scenario
👩💻 NLP Inference Example
from deepsparse import Pipeline
# SparseZoo model stub or path to ONNX file
model_path = "zoo:nlp/question_answering/bert-base/pytorch/huggingface/squad/12layer_pruned80_quant-none-vnni"
qa_pipeline = Pipeline.create(
task="question-answering",
model_path=model_path,
)
my_name = qa_pipeline(question="What's my name?", context="My name is Snorlax")
NLP Tutorials:
Tasks Supported:
- Token Classification: Named Entity Recognition
- Text Classification: Multi-Class
- Text Classification: Binary
- Text Classification: Sentiment Analysis
- Question Answering
🦉 SparseZoo ONNX vs. Custom ONNX Models
DeepSparse can accept ONNX models from two sources:
-
SparseZoo ONNX: our open-source collection of sparse models available for download. SparseZoo hosts inference-optimized models, trained on repeatable sparsification recipes using state-of-the-art techniques from SparseML.
-
Custom ONNX: your own ONNX model, can be dense or sparse. Plug in your model to compare performance with other solutions.
> wget https://github.com/onnx/models/raw/main/vision/classification/mobilenet/model/mobilenetv2-7.onnx
Saving to: ‘mobilenetv2-7.onnx’
Custom ONNX Benchmark example:
from deepsparse import compile_model
from deepsparse.utils import generate_random_inputs
onnx_filepath = "mobilenetv2-7.onnx"
batch_size = 16
# Generate random sample input
inputs = generate_random_inputs(onnx_filepath, batch_size)
# Compile and run
engine = compile_model(onnx_filepath, batch_size)
outputs = engine.run(inputs)
The GitHub repository includes package APIs along with examples to quickly get started benchmarking and inferencing sparse models.
Scheduling Single-Stream, Multi-Stream, and Elastic Inference
DeepSparse offers up to three types of inferences based on your use case. Read more details here: Inference Types.
1 ⚡ Single-stream scheduling: the latency/synchronous scenario, requests execute serially. [default]
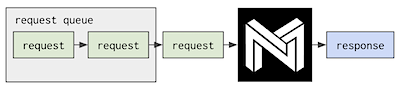
Use Case: It's highly optimized for minimum per-request latency, using all of the system's resources provided to it on every request it gets.
2 ⚡ Multi-stream scheduling: the throughput/asynchronous scenario, requests execute in parallel.

PRO TIP: The most common use cases for the multi-stream scheduler are where parallelism is low with respect to core count, and where requests need to be made asynchronously without time to batch them.
3 ⚡ Elastic scheduling: requests execute in parallel, but not multiplexed on individual NUMA nodes.
Use Case: A workload that might benefit from the elastic scheduler is one in which multiple requests need to be handled simultaneously, but where performance is hindered when those requests have to share an L3 cache.
Resources
Libraries
Versions
-
DeepSparse | stable
-
DeepSparse-Nightly | nightly (dev)
-
GitHub | releases
Info
Community
Be Part of the Future... And the Future is Sparse!
Contribute with code, examples, integrations, and documentation as well as bug reports and feature requests! Learn how here.
For user help or questions about DeepSparse, sign up or log in to our Deep Sparse Community Slack. We are growing the community member by member and happy to see you there. Bugs, feature requests, or additional questions can also be posted to our GitHub Issue Queue. You can get the latest news, webinar and event invites, research papers, and other ML Performance tidbits by subscribing to the Neural Magic community.
For more general questions about Neural Magic, complete this form.
License
DeepSparse Community is licensed under the Neural Magic DeepSparse Community License. Some source code, example files, and scripts included in the deepsparse GitHub repository or directory are licensed under the Apache License Version 2.0 as noted.
DeepSparse Enterprise requires a Trial License or can be fully licensed for production, commercial applications.
Cite
Find this project useful in your research or other communications? Please consider citing:
@InProceedings{
pmlr-v119-kurtz20a,
title = {Inducing and Exploiting Activation Sparsity for Fast Inference on Deep Neural Networks},
author = {Kurtz, Mark and Kopinsky, Justin and Gelashvili, Rati and Matveev, Alexander and Carr, John and Goin, Michael and Leiserson, William and Moore, Sage and Nell, Bill and Shavit, Nir and Alistarh, Dan},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
pages = {5533--5543},
year = {2020},
editor = {Hal Daumé III and Aarti Singh},
volume = {119},
series = {Proceedings of Machine Learning Research},
address = {Virtual},
month = {13--18 Jul},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v119/kurtz20a/kurtz20a.pdf},
url = {http://proceedings.mlr.press/v119/kurtz20a.html}
}
@article{DBLP:journals/corr/abs-2111-13445,
author = {Eugenia Iofinova and
Alexandra Peste and
Mark Kurtz and
Dan Alistarh},
title = {How Well Do Sparse Imagenet Models Transfer?},
journal = {CoRR},
volume = {abs/2111.13445},
year = {2021},
url = {https://arxiv.org/abs/2111.13445},
eprinttype = {arXiv},
eprint = {2111.13445},
timestamp = {Wed, 01 Dec 2021 15:16:43 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-13445.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file deepsparse-1.3.0.tar.gz.
File metadata
- Download URL: deepsparse-1.3.0.tar.gz
- Upload date:
- Size: 39.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.24.0 setuptools/45.2.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9900e2fe00762c4d5dea29111186a672690f3a551a191580698bd67f46cb975c
|
|
| MD5 |
8c49fbdb86c66d936783a26d8bb9156e
|
|
| BLAKE2b-256 |
0c9c32cda03bcafba201d1bba7a4d0daa161fe28ba07e564fdad5029f358e758
|
File details
Details for the file deepsparse-1.3.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: deepsparse-1.3.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 39.9 MB
- Tags: CPython 3.10, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.24.0 setuptools/45.2.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
593ff0762288ba94817bacd18241dedffefd19182b968da2addaedb4f661d26f
|
|
| MD5 |
be9e8f47caefba96294a3d6306124275
|
|
| BLAKE2b-256 |
7b29944378e24b7fa78e49ebbb537c1b2e33ce2baa5fb5e2ae3cc2820069d368
|
File details
Details for the file deepsparse-1.3.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: deepsparse-1.3.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 39.9 MB
- Tags: CPython 3.9, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.24.0 setuptools/45.2.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4b039ff5b2f4a0ccfe9e195926464c8c01da422cba702254fe1dcf6119f94bbc
|
|
| MD5 |
f51711e8b38841ef88540e2b147212cd
|
|
| BLAKE2b-256 |
7de76076f81a4cc07869853d7b6e81e13187266959a335502ecdca8b3c8c2d1d
|
File details
Details for the file deepsparse-1.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: deepsparse-1.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 39.9 MB
- Tags: CPython 3.8, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.24.0 setuptools/45.2.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6f060af9856ac8b5639f8939a30be130680763cd4de45f8695e0019685f2eaa8
|
|
| MD5 |
1bcbabc3967b1f57eb209149d029c522
|
|
| BLAKE2b-256 |
b17e240053a86bafe15c3158c2415188ba172515b6c1904f13f1ffcf1ec15104
|
File details
Details for the file deepsparse-1.3.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: deepsparse-1.3.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 40.0 MB
- Tags: CPython 3.7m, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.24.0 setuptools/45.2.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
45c733382de70200f0cef3bbd40021434cd726de238d77af0540ed74b6eecf7a
|
|
| MD5 |
2c0ed57adcf62fb06e1f4807215f5afa
|
|
| BLAKE2b-256 |
7f0190bc2aed009586516d5c83d7a1b526393e00837a4027ae2496c7b20bbacd
|







