Neural Architecture Search Powered by Swarm Intelligence

Project description

Neural Architecture Search Powered by Swarm Intelligence 🐜
DeepSwarm 

DeepSwarm is an open-source library which uses Ant Colony Optimization to tackle the neural architecture search problem. The main goal of DeepSwarm is to automate one of the most tedious and daunting tasks, so people can spend more of their time on more important and interesting things. DeepSwarm offers a powerful configuration system which allows you to fine-tune the search space to your needs.
Example 🖼
from deepswarm.backends import Dataset, TFKerasBackend
from deepswarm.deepswarm import DeepSwarm
dataset = Dataset(training_examples=x_train, training_labels=y_train, testing_examples=x_test, testing_labels=y_test)
backend = TFKerasBackend(dataset=dataset)
deepswarm = DeepSwarm(backend=backend)
topology = deepswarm.find_topology()
trained_topology = deepswarm.train_topology(topology, 50)
Installation 💾
-
Install the package
pip install deepswarm
-
Install one of the implemented backends that you want to use
pip install tensorflow-gpu==1.13.1
Usage 🕹
-
Create a new file containing the example code
touch train.py -
Create settings directory which contains
default.yamlfile. Alternatively you can run the script and instantly stop it, as this should automatically create settings directory which containsdefault.yamlfile -
Update the newly created YAML file to your dataset needs. The only two important changes you must make are: (1) change the loss function to reflect your task (2) change the shape of input and output nodes
Search 🔎
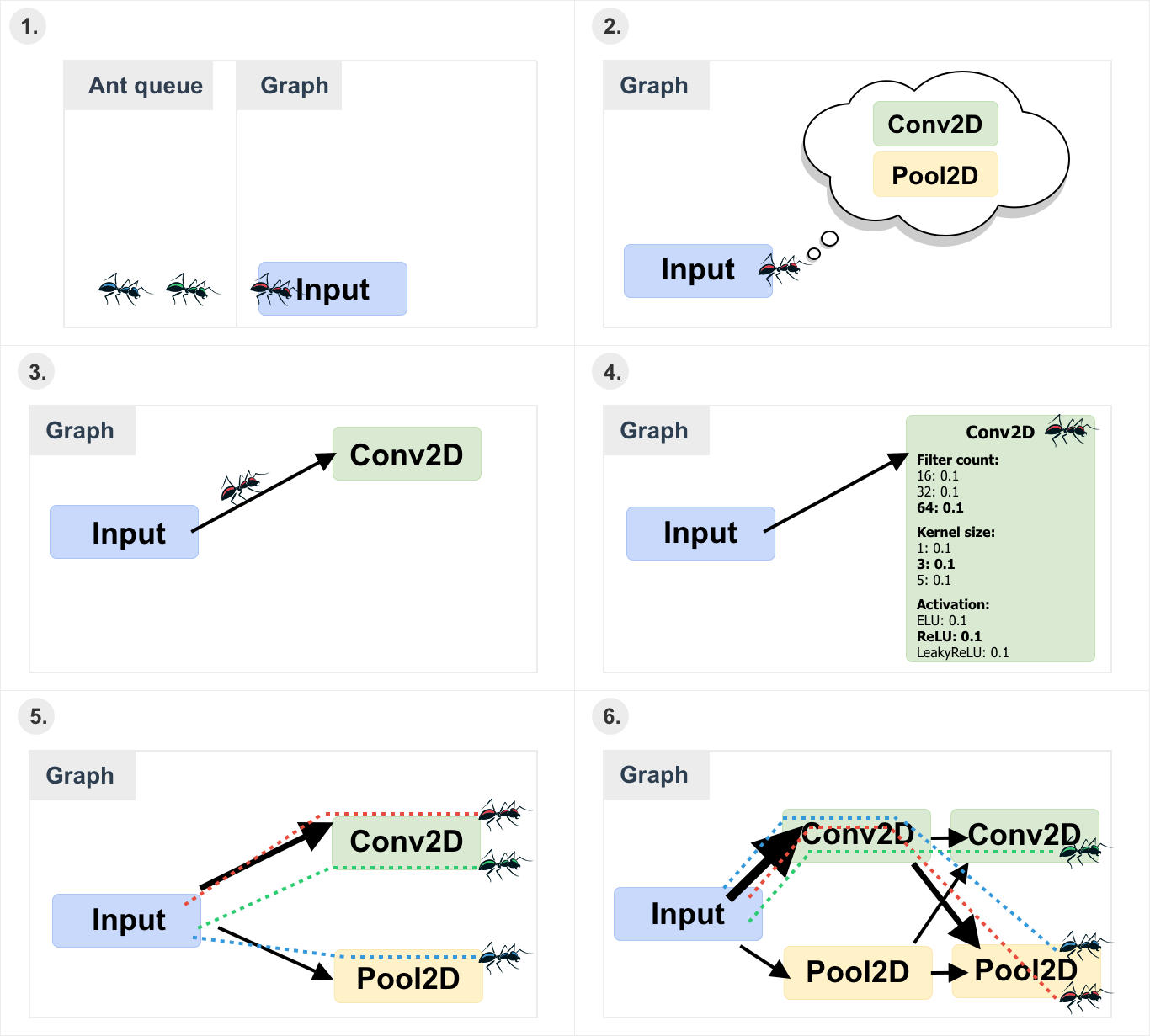
(1) The ant is placed on the input node. (2) The ant checks what transitions are available. (3) The ant uses the ACS selection rule to choose the next node. (4) After choosing the next node the ant selects node’s attributes. (5) After all ants finished their tour the pheromone is updated. (6) The maximum allowed depth is increased and the new ant population is generated.
Note: Arrow thickness indicates the pheromone amount, meaning that thicker arrows have more pheromone.
Configuration 🛠
| Node type | Attributes |
|---|---|
| Input | shape: tuple which defines the input shape, depending on the backend could be (width, height, channels) or (channels, width, height). |
| Conv2D | filter_count: defines how many filters can be used. kernel_size: defines what size kernels can be used. For example, if it is set to [1, 3], then only 1x1 and 3x3 kernels will be used. activation: defines what activation functions can be used. Allowed values are: ReLU, ELU, LeakyReLU, Sigmoid and Softmax. |
| Dropout | rate: defines the allowed dropout rates. For example, if it is set to [0.1, 0.3], then either 10% or 30% of input units will be dropped. |
| BatchNormalization | - |
| Pool2D | pool_type: defines the types of allowed pooling nodes. Allowed values are: max (max pooling) and average (average pooling). pool_size: defines the allowed pooling window sizes. For example, if it is set to [2], then only 2x2 pooling windows will be used. stride: defines the allowed stride sizes. |
| Flatten | - |
| Dense | output_size: defines the allowed output space dimensionality. activation: defines what activation functions can be used. Allowed values are: ReLU, ELU, LeakyReLU, Sigmoid and Softmax. |
| Output | output_size: defines the output size (how many different classes to classify). activation: defines what activation functions can be used. Allowed value are ReLU, ELU, LeakyReLU, Sigmoid and Softmax. |
| Setting | Description |
|---|---|
| save_folder | Specifies the name of the folder which should be used to load the backup. If not specified the search will start from zero. |
| metrics | Specifies what metrics should algorithm use to evaluate the models. Currently available options are: accuracy and loss. |
| max_depth | Specifies the maximum allowed network depth (how deeply the graph can be expanded). The search is performed until the maximum depth is reached. However, it does not mean that the depth of the best architecture will be equal to the max_depth. |
| reuse_patience | Specifies the maximum number of times that weights can be reused without improving the cost. For example, if it is set to 1 it means that when some model X reuses weights from model Y and model X cost did not improve compared to model Y, next time instead of reusing model Y weights, new random weights will be generated. |
| start | Specifies the starting pheromone value for all the new connections. |
| decay | Specifies the local pheromone decay rate in percentage. For example, if it is set to 0.1 it means that during the local pheromone update the pheromone value will be decreased by 10%. |
| evaporation | Specifies the global pheromone evaporation rate in percentage. For example, if it is set to 0.1 it means that during the global pheromone update the pheromone value will be decreased by 10%. |
| greediness | Specifies how greedy should ants be during the edge selection (the number is given in percentage). For example, 0.5 means that 50% of the time when ant selects a new edge it should select the one with the highest associated probability. |
| ant_count | Specifies how many ants should be generated during each generation (time before the depth is increased). |
| epochs | Specifies for how many epochs each candidate architecture should be trained. |
| batch_size | Specifies the batch size (number of samples used to calculate a single gradient step) used during the training process. |
| patience | Specifies the early stopping number used during the training (after how many epochs when the cost is not improving the training process should be stopped). |
| loss | Specifies what loss function should be used during the training. Currently available options are sparse_categorical_crossentropy and categorical_crossentropy. |
| spatial_nodes | Specifies which nodes are placed before the flattening node. Values in this array must correspond to node names. |
| flat_nodes | Specifies which nodes are placed after the flattening node (array should also include the flattening node). Values in this array must correspond to node names. |
| verbose | Specifies if the associated component should log the output. |
Future goals 🌟
- Add a node which can combine the input from the two previous nodes.
- Add a node which can skip the depth n in order to connect to the node in depth n+1.
- Delete the models which are not referenced anymore.
- Add an option to assemble the best n models into one model.
- Add functionality to reuse the weights from the non-continues blocks, i.e. take the best weights for depth n-1 from one model and then take the best weights for depth n+1 from another model.
Citation 🖋
Online version is available at: arXiv:1905.07350
@article{byla2019deepswarm,
title = {DeepSwarm: Optimising Convolutional Neural Networks using Swarm Intelligence},
author = {Edvinas Byla and Wei Pang},
journal = {arXiv preprint arXiv:1905.07350},
year = {2019}
}
Acknowledgments 🎓
DeepSwarm was developed under the supervision of Dr Wei Pang in partial fulfilment of the requirements for the degree of Bachelor of Science of the University of Aberdeen.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file deepswarm-0.0.10.tar.gz.
File metadata
- Download URL: deepswarm-0.0.10.tar.gz
- Upload date:
- Size: 20.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1970ad5e481864f4be2f95dea1e7673094a864b6d645b5d7eedeee74582e2f01
|
|
| MD5 |
8558e5378ee0b11eac920c4583d01f68
|
|
| BLAKE2b-256 |
1e613ea286ee6f9e49fb7472daecd7cdd0c22b2d3d14359d93ec09d1257c1bc3
|
File details
Details for the file deepswarm-0.0.10-py3-none-any.whl.
File metadata
- Download URL: deepswarm-0.0.10-py3-none-any.whl
- Upload date:
- Size: 21.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.6.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ec5e0f2e68219f110dbe8bf5d7188dcb8291032f2c5d2135bfccdc867bd8a57e
|
|
| MD5 |
94008c217cbe60534f699e59683adfc8
|
|
| BLAKE2b-256 |
e467cb9a136d1d1b63dab32c42bad37fd99d9dc3fac858958cdc81fc644df8ec
|







