Open Source Development Team Operation Analytics

Project description
dev-health-ops
Development team and developers' operational help should be available for all.
This project's goal is to provide tools and quick-win implementations by integrating with a majority of popular tooling.
Why this exists
Developer health tooling drifted into expensive, opaque “scoring” systems that are easy to misuse. This project is intentionally different.
Principles
- Accessibility over extraction: derived from data teams already own; should be cheap to run and never gated behind per-seat pricing.
- Learning, not judgment: metrics are signals about system behavior (WIP, churn, cycle time, blocked work), not performance rankings.
- Trends > absolutes: compare change over time and distributions, not “who’s best”.
- Inspectable by default: open schemas, explicit definitions, and reproducible computation.
Non-goals
- Individual leaderboards and “scores”
- HR/performance-management tooling
- Executive theater dashboards that hide context
Installation
If you are not developing on this project and just want to use the tools, you can install the package directly:
pip install dev-health-ops
This provides the dev-hops command in your terminal.
dev-hops --help
Note: In the documentation below, you can replace dev-hops with dev-hops if you have installed the package.
Private Repository Support ✅
Both GitHub and GitLab connectors fully support private repositories! When provided with tokens that have appropriate permissions, you can access and sync data from private repositories just as easily as public ones.
- GitHub: Requires
reposcope on your personal access token - GitLab: Requires
read_apiandread_repositoryscopes on your private token
See PRIVATE_REPO_TESTING.md for detailed instructions on setting up and testing private repository access, or VERIFICATION_SUMMARY.md for a comprehensive overview.
Batch Repository Processing ✅
The GitHub connector supports batch processing of repositories with:
- Pattern matching - Filter repositories using fnmatch-style patterns (e.g.,
chrisgeo/*,*/api-*) - Configurable batch size - Process repositories in batches to manage memory and API usage
- Rate limiting - Delay between batches plus shared backoff across workers (avoids stampedes; honors server reset/
Retry-Afterwhen available) - Async processing - Process multiple repositories concurrently for better performance
- Callbacks - Get notified as each repository is processed
Example Usage
from connectors import GitHubConnector
connector = GitHubConnector(token="your_token")
# List repos with pattern matching (integrated into list_repositories)
repos = connector.list_repositories(
org_name="myorg",
pattern="myorg/api-*", # Filter repos matching this pattern
max_repos=50,
)
# Get all repos matching a pattern with stats
results = connector.get_repos_with_stats(
org_name="myorg",
pattern="myorg/api-*", # Filter repos matching this pattern
batch_size=10, # Process 10 repos at a time
max_concurrent=4, # Use 4 concurrent workers
rate_limit_delay=1.0, # Wait 1 second between batches
max_commits_per_repo=100, # Limit commits analyzed per repo
max_repos=50, # Maximum repos to process
)
for result in results:
if result.success:
print(f"{result.repository.full_name}: {result.stats.total_commits} commits")
Async Processing
For even better performance, use the async version:
import asyncio
from connectors import GitHubConnector
async def main():
connector = GitHubConnector(token="your_token")
results = await connector.get_repos_with_stats_async(
org_name="myorg",
pattern="myorg/*",
batch_size=10,
max_concurrent=4,
)
for result in results:
if result.success:
print(f"{result.repository.full_name}: {result.stats.total_commits} commits")
asyncio.run(main())
Pattern Matching Examples
| Pattern | Matches |
|---|---|
chrisgeo/m* |
chrisgeo/dev-health-ops, chrisgeo/my-app |
*/api-* |
anyorg/api-service, myuser/api-gateway |
org/repo |
Exactly org/repo |
chrisgeo/* |
All repositories owned by chrisgeo |
*sync* |
Any repository with sync in the name |
Developer Health Metrics (Work + Git) + Grafana ✅
DEPRECATION NOTICE: The Grafana panels and plugin integration have been moved to a separate repository (
dev-health-panels) and are being superseded by the full-stack web applicationdev-health-web.
This repo can compute daily “developer health” metrics and provision Grafana dashboards on top of:
- Git + PR/MR facts (from GitHub/GitLab/local syncs)
- Work tracking items (Jira issues, GitHub issues/Projects, GitLab issues)
Jira is not a replacement for pull request data — it’s used to track associated project work (throughput, WIP, work-item cycle/lead times). PR metrics still come from the Git provider data (e.g., GitHub PRs / GitLab MRs) synced by the CLI (dev-hops sync <target> --provider ...).
Docs
- Metrics definitions + tables:
docs/metrics.md - Implementation plans, metrics inventory, requirements/roadmap:
docs/project.md,docs/metrics-inventory.md,docs/roadmap.md - Task tracker configuration (Jira/GitHub/GitLab, status mapping, teams):
docs/task_trackers.md - Grafana dashboards + provisioning:
docs/grafana.md
Quickstart (ClickHouse + Grafana)
- Start ClickHouse + Grafana:
docker compose -f compose.yml up -d
- Sync Git data into ClickHouse (choose one):
# Local repo (commits + stats)
dev-hops sync git --provider local --db "clickhouse://localhost:8123/default" --repo-path .
# GitHub repo (commits + stats)
dev-hops sync git --provider github --db "clickhouse://localhost:8123/default" --owner <owner> --repo <repo>
# GitLab project (commits + stats)
dev-hops sync git --provider gitlab --db "clickhouse://localhost:8123/default" --project-id <id>
- Compute derived metrics (Git + Work Items):
# (Optional) Sync work items from provider APIs (recommended)
dev-hops sync work-items --provider all --date 2025-02-01 --backfill 30 --db "clickhouse://localhost:8123/default"
# One day (derived Git metrics; enriches IC metrics from already-synced work items when available)
dev-hops metrics daily --date 2025-02-01 --db "clickhouse://localhost:8123/default"
# Backfill last 30 days ending at date
dev-hops metrics daily --date 2025-02-01 --backfill 30 --db "clickhouse://localhost:8123/default"
- Open Grafana:
- http://localhost:3000 (default
admin/admin) - Dashboards are provisioned under the “Developer Health” folder.
API (FastAPI)
Run the Developer Health Ops API for the web app:
dev-hops api --db "clickhouse://localhost:8123/default" --reload
OpenAPI docs are available at http://localhost:8000/docs.
Container images
This repo ships two reusable images built from docker/Dockerfile, which provides a multi-stage build (base, api, runner). The images cover demo runners and REST APIs:
dev-hops-apirunsdev-hops apiand exposesport 8000.dev-hops-runnerusesdev-hopsas the entrypoint so you can invokesync,fixtures,metrics, etc., through a container.
Building the images
Use scripts/build-images.sh to build both images (it sets SETUPTOOLS_SCM_PRETEND_VERSION so setuptools_scm doesn't require .git). The base stage installs the package and then drops the source tree so the runtime image contains only the installed wheel. Override the defaults with:
-
Note: the API runtime loads packaged SQL files from
dev_health_ops/api/sql. If you extend the build, make sure those SQL files are included in the wheel (the Docker build will fail fast if they're missing). -
IMAGE_REGISTRY(defaults toghcr.io/chrisgeo/dev-health-ops) -
VERSION(tags the images; defaultlatest) -
SETUPTOOLS_SCM_PRETEND_VERSION(needed when building from a released archive without Git metadata)
cd /path/to/dev-health-ops
IMAGE_REGISTRY=ghcr.io/myorg/dev-health-ops \
VERSION=$(git describe --tags --abbrev=0 2>/dev/null || echo latest) \
./scripts/build-images.sh
Any extra arguments (--no-cache, --pull, etc.) are forwarded to both docker build invocations.
Running the API container
Expose port 8000 and point the container at your ClickHouse backend:
docker run --rm -p 8000:8000 \
-e DATABASE_URI=clickhouse://ch:ch@clickhouse:8123/stats \
dev-hops-api:latest
Add flags after the image name (e.g., --reload) to modify the default api invocation (--host 0.0.0.0 --port 8000 is already applied).
Using the runner container
Mount repositories or fixtures directories and run any dev-hops command you need. Share a Docker network with ClickHouse (Compose uses dev-health-ops_default by default):
docker run --rm -it \
--network dev-health-ops_default \
-v "$(pwd)":/app \
-w /app \
-e DATABASE_URI=clickhouse://ch:ch@clickhouse:8123/stats \
dev-hops-runner:latest \
fixtures generate --db clickhouse://ch:ch@clickhouse:8123/stats --days 14
Replace the final arguments with any dev-hops subcommand you need (sync, metrics daily, etc.). The entrypoint handles argument parsing so you can run the same image in CI, demos, or release flows.
Automated builds
docker-images.yml runs on GitHub when a v* tag is pushed or a release is published. It logs into ghcr.io, builds both runner/api targets from docker/Dockerfile, and pushes :latest plus the tag pulled from the workflow context (${{ github.ref_name }} or the release tag). Make sure GITHUB_TOKEN has packages: write (default) so the workflow can publish into ghcr.io/chrisgeo/dev-health-ops.
“Download” work tracking data (Jira/GitHub/GitLab)
Work items are fetched from provider APIs via a dedicated sync command. This is separate from PR ingestion:
- Configure credentials + mapping (see
docs/task_trackers.md) - Sync work items:
dev-hops sync work-items --provider jira|github|gitlab|all ...(use-sto filter repos;--authfor GitHub/GitLab token override) metrics dailydoes not need--providerunless you want backward-compatible "sync-then-compute" behavior in one step.
src/dev_health_ops/cli.py automatically loads a local .env file from the repo root (without overriding already-set environment variables). Disable with DISABLE_DOTENV=1.
Sync Teams
You can sync team definitions into the database from multiple sources. This allows dashboards to group data by teams.
# Sync from a local YAML config (default)
dev-hops sync teams --db "sqlite+aiosqlite:///stats.db" --path config/teams.yaml
# Sync from Jira Projects (uses JIRA_* env vars)
dev-hops sync teams --db "sqlite+aiosqlite:///stats.db" --provider jira
# Generate synthetic teams for testing
dev-hops sync teams --db "sqlite+aiosqlite:///stats.db" --provider synthetic
Database Configuration
This project supports PostgreSQL, MongoDB, SQLite, and ClickHouse as storage backends.
Environment Variables
DATABASE_URI(optional): Default DB URI fordev-hops metrics daily --db ...and for Alembic migrations. Also acceptsDATABASE_URLas an alias.SECONDARY_DATABASE_URI(optional): Secondary database URI for--sink bothmode (writes to both primary and secondary databases).DB_ECHO(optional): Enable SQL query logging for PostgreSQL and SQLite. Set totrue,1, oryes(case-insensitive) to enable. Any other value (includingfalse,0,no, or unset) disables it. Default:false. Note: Enabling this in production can expose sensitive data and impact performance.REPO_UUID(optional): UUID for the repository. If not provided, a deterministic UUID will be derived from the git repository's remote URL (or repository path if no remote exists). This ensures the same repository always gets the same UUID across runs.MAX_WORKERS(optional): Number of parallel workers for processing git blame data. Higher values can speed up processing but use more CPU and memory. Default:4LOG_LEVEL(optional): Logging level (e.g.INFO,DEBUG). Default:INFODISABLE_DOTENV(optional): Set to1to disable.envloading from the repo root.GITHUB_TOKEN(optional): Default GitHub token when--authis not provided.GITLAB_TOKEN(optional): Default GitLab token when--authis not provided.GITLAB_URL(optional): Default GitLab base URL when--gitlab-urlis not provided (default:https://gitlab.com).
Command-Line Arguments
You can also configure the database using command-line arguments, which will override environment variables:
Core Arguments
--db: Database connection string (required forsync; optional formetrics dailyifDATABASE_URIis set)--db-type: Database backend override (postgres,mongo,sqlite, orclickhouse) - optional if URL scheme is clear--provider: Source provider for sync targets (local,github,gitlab,synthetic)--auth: Authentication token (GitHub/GitLab)--repo-path: Path to the git repository (for--provider local)--since: Lower-bound date/time filter for sync targets. Uses ISO formats (e.g.,2024-01-01or2024-01-01T00:00:00).
Connector-Specific Arguments
--owner: GitHub repository owner/organization--repo: GitHub repository name--gitlab-url: GitLab instance URL (default: https://gitlab.com)--project-id: GitLab project ID (numeric)
Batch Processing Options
These unified options work with both GitHub and GitLab connectors:
-s, --search: fnmatch-style pattern to filter repositories/projects (e.g.,owner/repo*,group/p*)--batch-size: Number of repositories/projects to process in each batch (default: 10)--group: Organization/group name to fetch repositories/projects from--max-concurrent: Maximum concurrent workers for batch processing (default: 4)--rate-limit-delay: Delay in seconds between batches for rate limiting (default: 1.0)--max-commits-per-repo: Maximum commits to analyze per repository/project--max-repos: Maximum number of repositories/projects to process--use-async: Use async processing for better performance
Example usage:
# Using PostgreSQL (auto-detected from URL)
dev-hops sync git --provider local --db "postgresql+asyncpg://user:pass@localhost:5432/stats"
# Using MongoDB (auto-detected from URL)
dev-hops sync git --provider local --db "mongodb://localhost:27017"
# Local repo filtered to recent activity
dev-hops sync git --provider local \
--db "sqlite+aiosqlite:///stats.db" \
--repo-path /path/to/repo \
--since 2024-01-01
# Commits and stats are limited to changes on/after this date.
# Using SQLite (file-based, auto-detected)
dev-hops sync git --provider local --db "sqlite+aiosqlite:///stats.db"
# Using SQLite (in-memory)
dev-hops sync git --provider local --db "sqlite+aiosqlite:///:memory:"
# GitHub repository with unified auth
dev-hops sync git --provider github \
--db "postgresql+asyncpg://user:pass@localhost:5432/stats" \
--auth "$GITHUB_TOKEN" \
--owner torvalds \
--repo linux
# GitLab project with unified auth
dev-hops sync git --provider gitlab \
--db "mongodb://localhost:27017" \
--auth "$GITLAB_TOKEN" \
--project-id 278964
# Batch process repositories matching a pattern (GitHub)
dev-hops sync git --provider github \
--db "sqlite+aiosqlite:///stats.db" \
--auth "$GITHUB_TOKEN" \
-s "chrisgeo/dev-health-*" \
--group "chrisgeo" \
--batch-size 5 \
--max-concurrent 2 \
--max-repos 10 \
--use-async
# Batch process projects matching a pattern (GitLab)
dev-hops sync git --provider gitlab \
--db "sqlite+aiosqlite:///stats.db" \
--auth "$GITLAB_TOKEN" \
--gitlab-url "https://gitlab.com" \
--group "mygroup" \
-s "mygroup/api-*" \
--batch-size 5 \
--max-concurrent 2 \
--max-repos 10 \
--use-async
MongoDB Connection String Format
MongoDB connection strings follow the standard MongoDB URI format:
- Basic:
mongodb://host:port - With authentication:
mongodb://username:password@host:port - With database:
mongodb://username:password@host:port/database_name - With options:
mongodb://host:port/?authSource=admin&retryWrites=true
Note: Include the database name in the URI (e.g., mongodb://host:port/stats).
SQLite Connection String Format
SQLite connection strings use the following format:
- File-based:
sqlite+aiosqlite:///path/to/database.db(relative path) orsqlite+aiosqlite:////absolute/path/to/database.db(absolute path - note the four slashes) - In-memory:
sqlite+aiosqlite:///:memory:(data is lost when the process exits)
SQLite is ideal for:
- Local development and testing
- Single-user scenarios
- Small to medium-sized repositories
- Environments where running a database server is not practical
Note: SQLite does not use connection pooling since it is a file-based database.
Performance Tuning
The script includes several configuration options to optimize performance:
-
MAX_WORKERS: Controls parallel processing of git blame data. Set this based on your CPU cores (e.g., 2-8). Higher values speed up processing but use more CPU and memory. -
Connection Pooling: PostgreSQL automatically uses connection pooling with these defaults:
- Pool size: 20 connections
- Max overflow: 30 additional connections
- Connections are recycled every hour
Example for large repositories:
export MAX_WORKERS=8
dev-hops sync git --provider local --db "sqlite+aiosqlite:///stats.db" --repo-path .
Example for resource-constrained environments:
export MAX_WORKERS=2
dev-hops sync git --provider local --db "sqlite+aiosqlite:///stats.db" --repo-path .
Performance Optimizations
This project includes several key performance optimizations to speed up git data processing:
1. Increased Batch Size (10x improvement)
- Batching: Uses batched inserts to reduce database round-trips
- Impact: Significantly reduces database round-trips, improving insertion speed
2. Parallel Git Blame Processing (4-8x improvement)
- Implementation: Uses asyncio with configurable worker pool
- Default: 4 parallel workers processing files concurrently
- Impact: Multi-core CPU utilization, dramatically faster blame processing
- Configuration: Set
MAX_WORKERS=8for more powerful machines
3. Database Connection Pooling (PostgreSQL)
- Pool size: 20 connections (up from default 5)
- Max overflow: 30 additional connections (up from default 10)
- Impact: Better handling of concurrent operations, reduced connection overhead
- Auto-configured: No manual setup required
4. Optimized Bulk Operations
- All database insertions use bulk operations
- MongoDB operations use
ordered=Falsefor better performance - SQLAlchemy uses
add_all()for efficient batch inserts
5. Smart File Filtering
- Skips binary files (images, videos, archives, etc.)
- Skips files larger than 1MB for content reading
- Reduces unnecessary I/O and processing time
Expected Performance Improvements
For a typical repository with 1000 files and 10,000 commits:
| Operation | Before | After | Improvement |
|---|---|---|---|
| Git Blame | 50 min | 6-12 min | 4-8x faster |
| Commits | - | 1-2 min | New feature |
| Commit Stats | - | 2-4 min | New feature |
| Files | - | 30-60 sec | New feature |
| Total | 50+ min | 10-20 min | ~3-5x faster |
Actual performance depends on hardware, repository size, and configuration.
PostgreSQL vs MongoDB vs SQLite: Setup and Migration Considerations
Using PostgreSQL
-
Requires running database migrations with Alembic before first use
-
Provides strong relational data structure
-
Best for complex queries and joins
-
Example setup:
# Start PostgreSQL with Docker Compose docker compose up postgres -d # Run migrations (Alembic reads DATABASE_URI) export DATABASE_URI="postgresql+asyncpg://postgres:postgres@localhost:5333/postgres" alembic upgrade head # Sync a local repo dev-hops sync git --provider local --db "$DATABASE_URI" --repo-path .
Using MongoDB
-
No migrations required - collections are created automatically
-
Schema-less design allows for flexible data structures
-
Best for quick setup and document-based storage
-
Example setup:
# Start MongoDB with Docker Compose docker compose up mongo -d dev-hops sync git --provider local --db "mongodb://localhost:27017/stats" --repo-path .
Using SQLite
-
No migrations required - tables are created automatically using SQLAlchemy
-
Simple file-based or in-memory database
-
No external database server required
-
Best for local development, testing, and single-user scenarios
-
Example setup:
dev-hops sync git --provider local --db "sqlite+aiosqlite:///stats.db" --repo-path .
Or for an in-memory database (data lost when process exits):
dev-hops sync git --provider local --db "sqlite+aiosqlite:///:memory:" --repo-path .
Using ClickHouse
-
No migrations required - tables are created automatically using
ReplacingMergeTree -
Best for analytics and large datasets
-
Example setup:
dev-hops sync git --provider local --db "clickhouse://default:@localhost:8123/default" --repo-path .
Switching Between Databases
- The different backends use different storage mechanisms and are not directly compatible
- Data is not automatically migrated when switching between PostgreSQL, MongoDB, SQLite, and ClickHouse
- If you need to switch backends, you'll need to re-run the analysis to populate the new database
- PostgreSQL and MongoDB can run simultaneously on the same machine using different ports (see
compose.yml)
Local Repository Pull Request Handling Warning
Important: When processing local repositories, pull request records are inferred from merge commit messages and local refs. These inferences are estimation-based and highly volatile:
- Dates (created_at, merged_at) may be inaccurate due to limited information in local repositories
- PR states (open/closed/merged) are estimated from commit history
- Some PRs may be missed entirely if they don't match expected patterns
- The accuracy depends heavily on repository history and commit message conventions
This behavior is different from GitHub/GitLab connectors, which provide accurate PR data directly from the provider API.
Example Running Order
- Sync teams
dev-hops sync teams --provider config --path config/teams.yaml --db "<DB_CONN>"
or: dev-hops sync teams --provider jira --db "<DB_CONN>"
- Sync git facts (example: GitHub)
dev-hops sync git --provider github --owner "" --repo "" --db "<DB_CONN>" dev-hops sync prs --provider github --owner "" --repo "" --db "<DB_CONN>" dev-hops sync blame --provider github --owner "" --repo "" --db "<DB_CONN>" dev-hops sync cicd --provider github --owner "" --repo "" --db "<DB_CONN>" dev-hops sync deployments --provider github --owner "" --repo "" --db "<DB_CONN>" dev-hops sync incidents --provider github --owner "" --repo "" --db "<DB_CONN>"
- Sync work items (and derived work‑item tables)
dev-hops sync work-items --provider github --db "<DB_CONN>" --date YYYY-MM-DD --backfill 30
use --provider jira|gitlab|all as needed
- Compute daily metrics (uses stored facts)
dev-hops metrics daily --db "<DB_CONN>" --date YYYY-MM-DD --backfill 30
- Compute complexity snapshots
dev-hops metrics complexity --repo-path /path/to/repo --db "<DB_CONN>" --date YYYY-MM-DD --backfill 30
Sample Dashboards
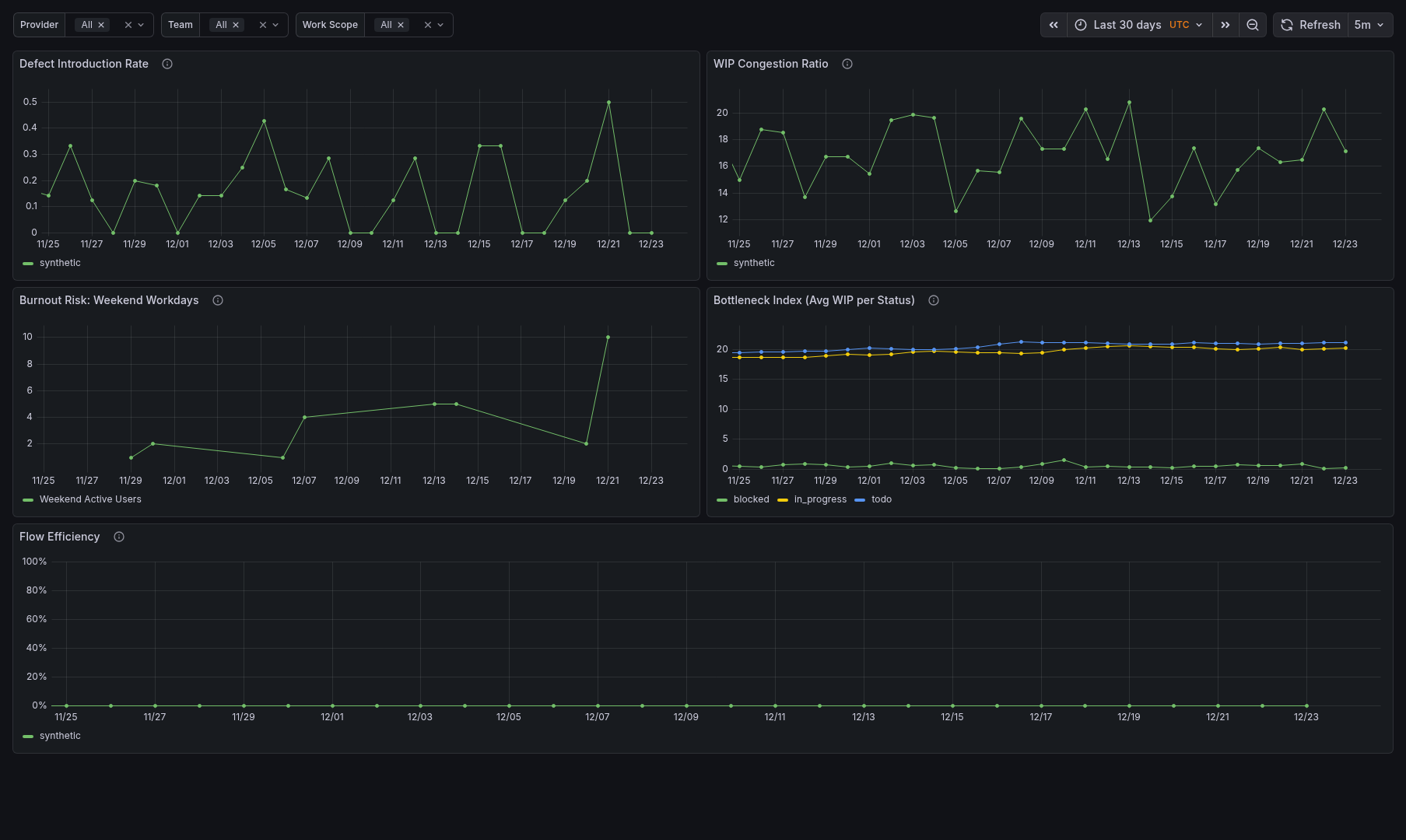
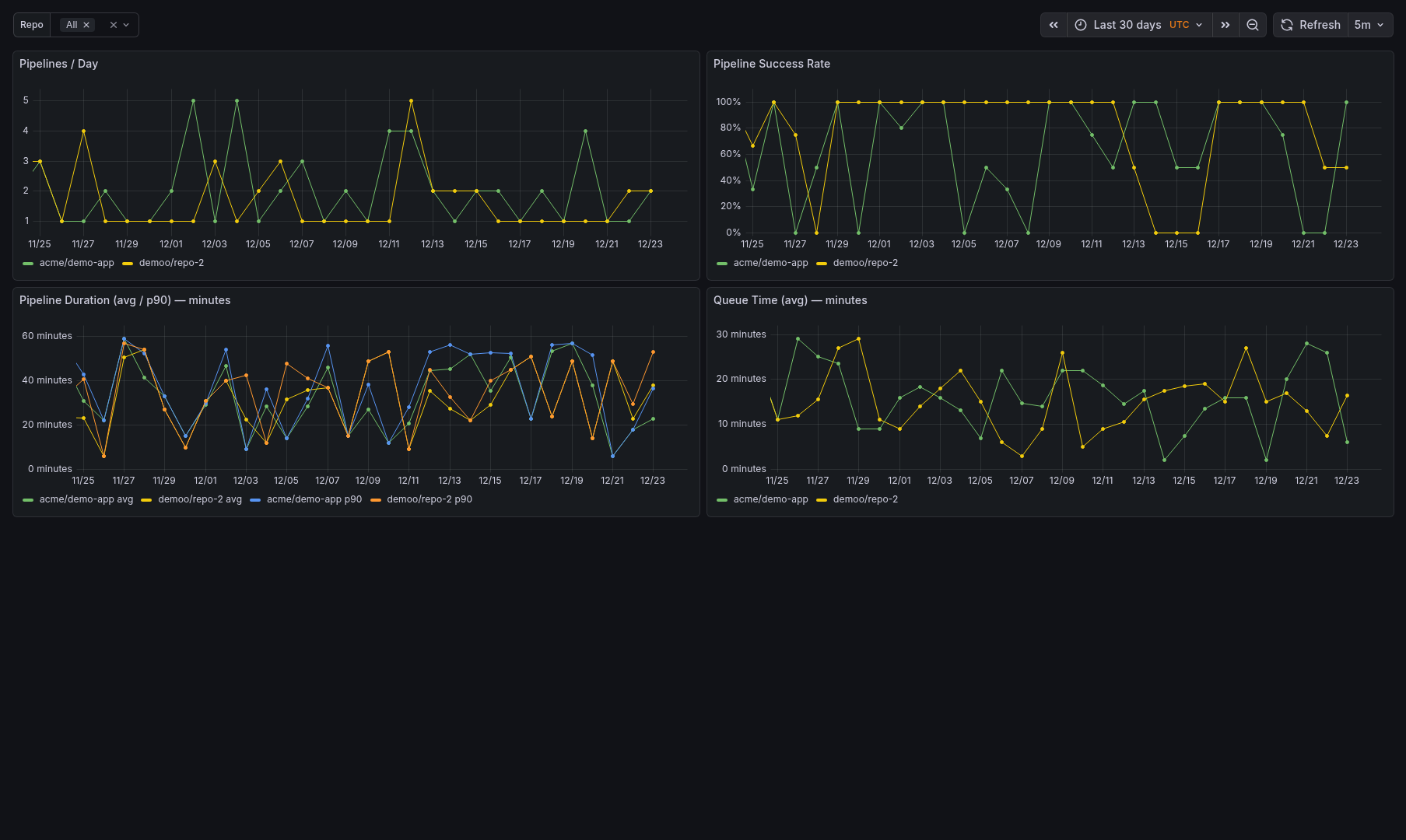
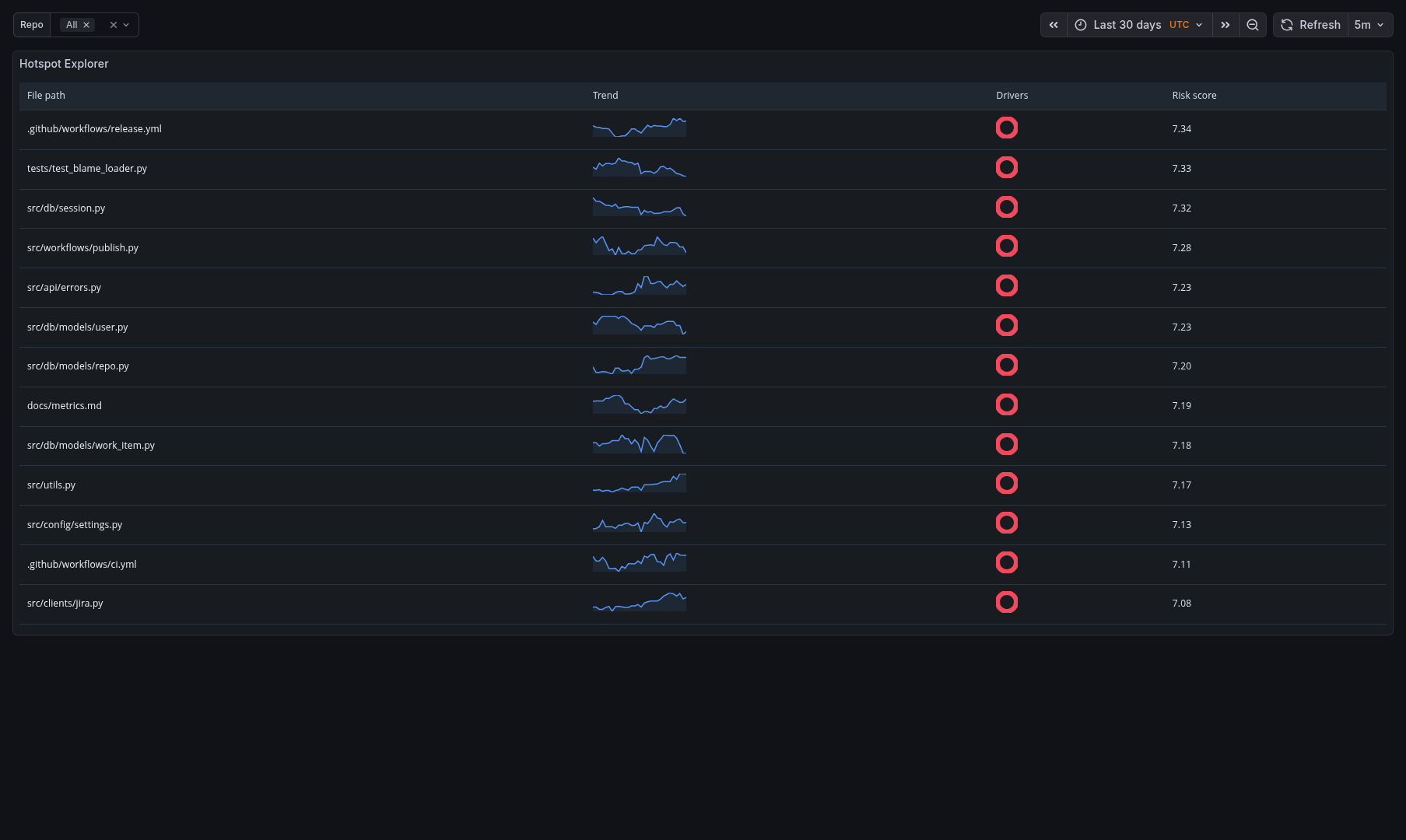
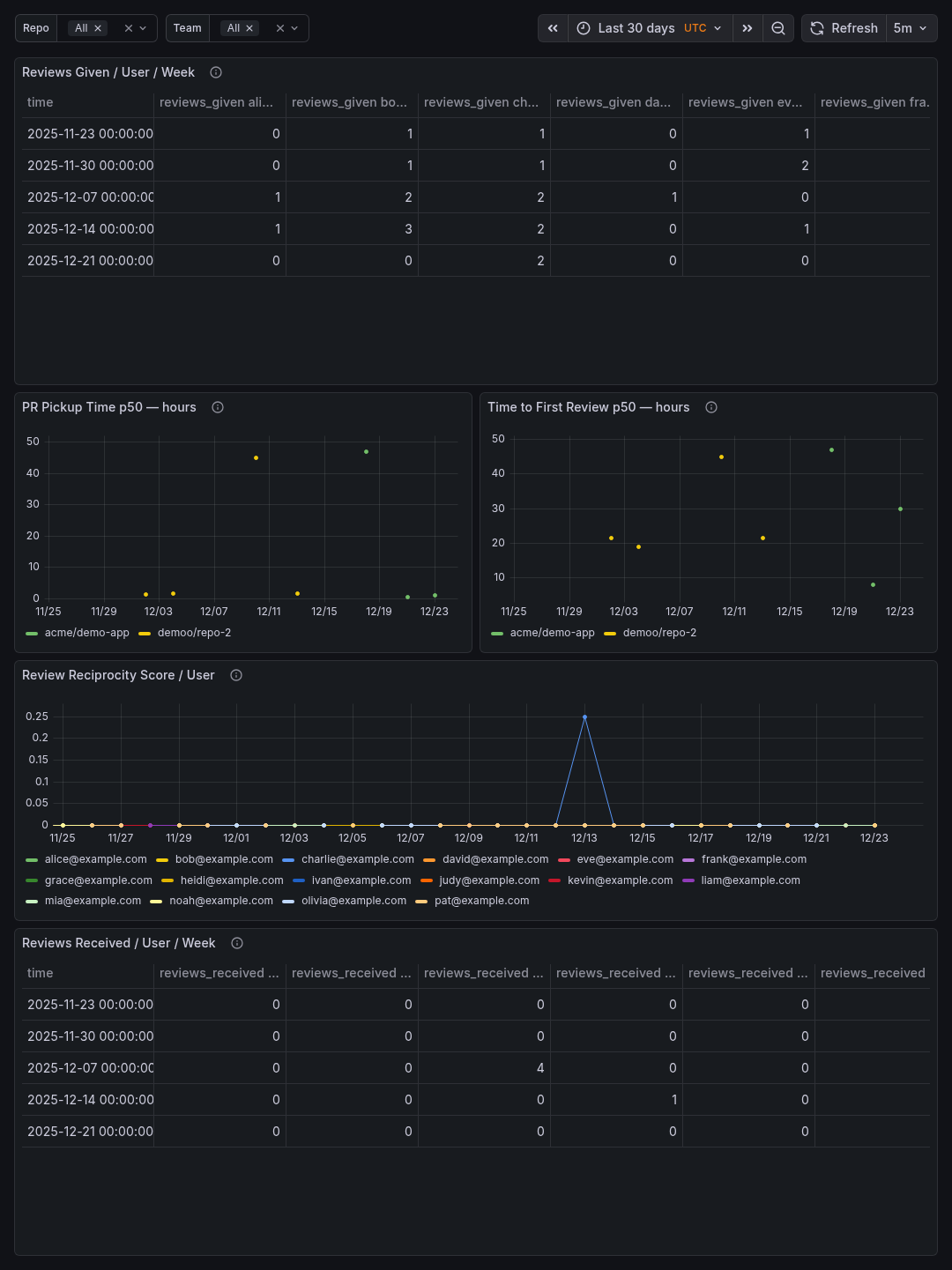
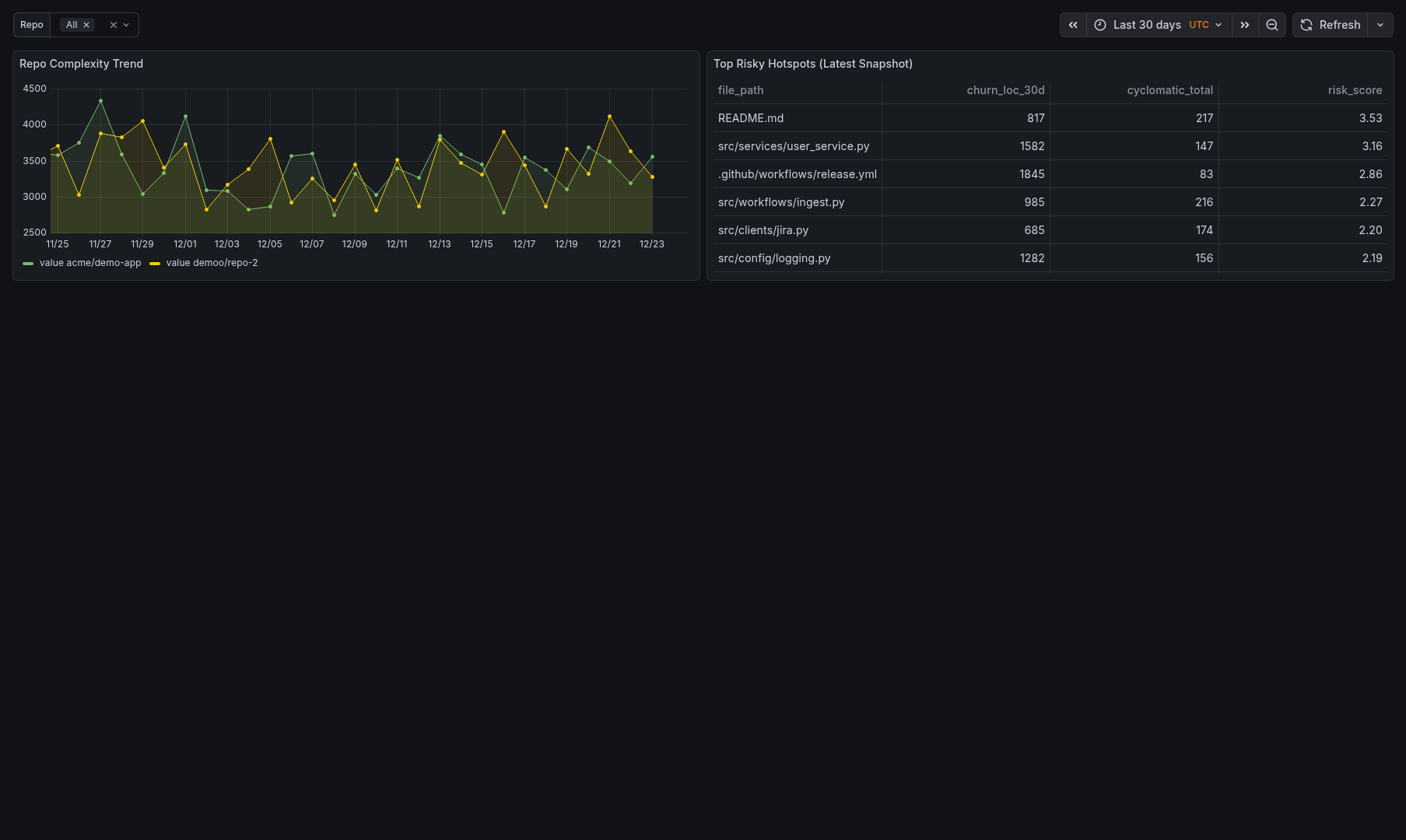
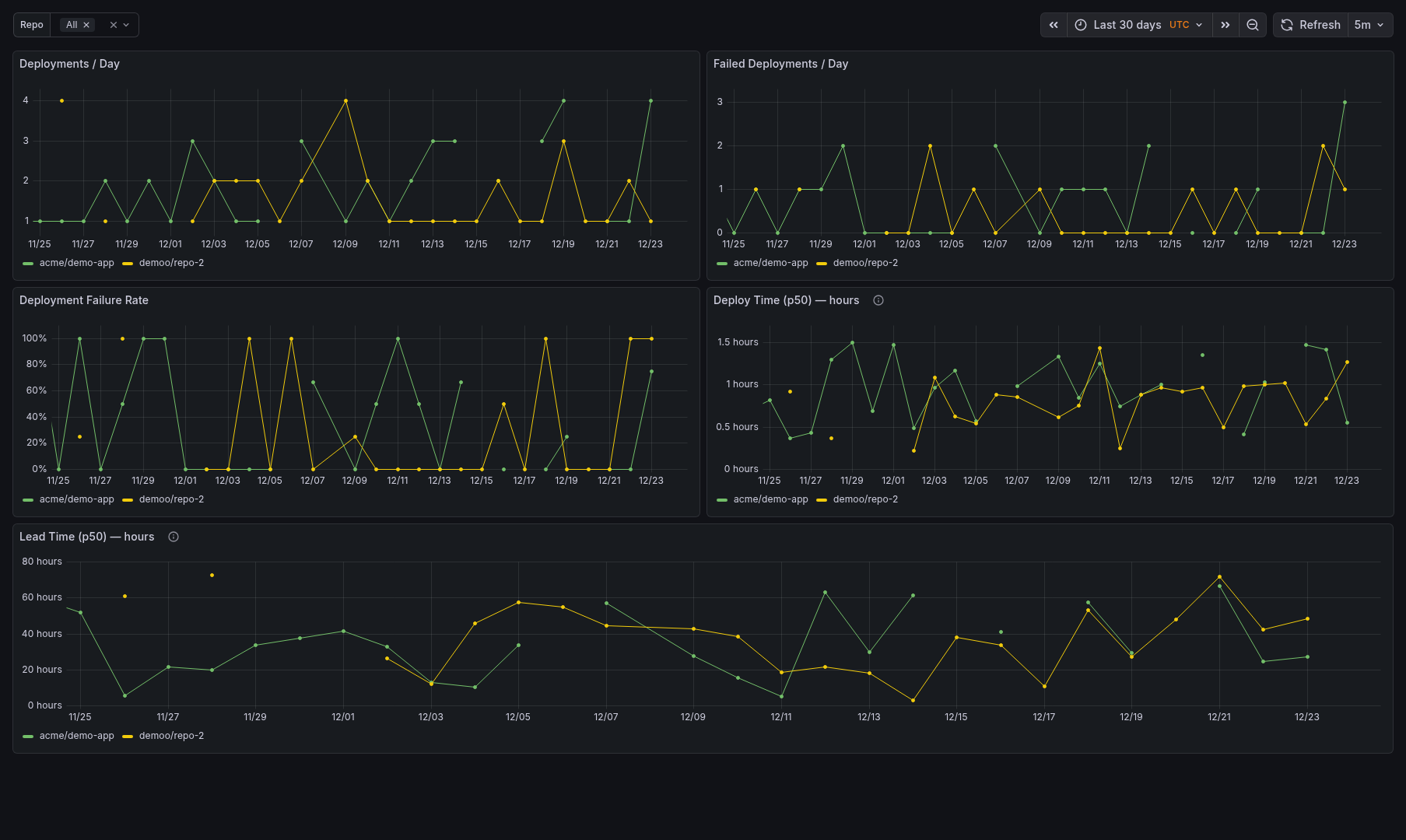
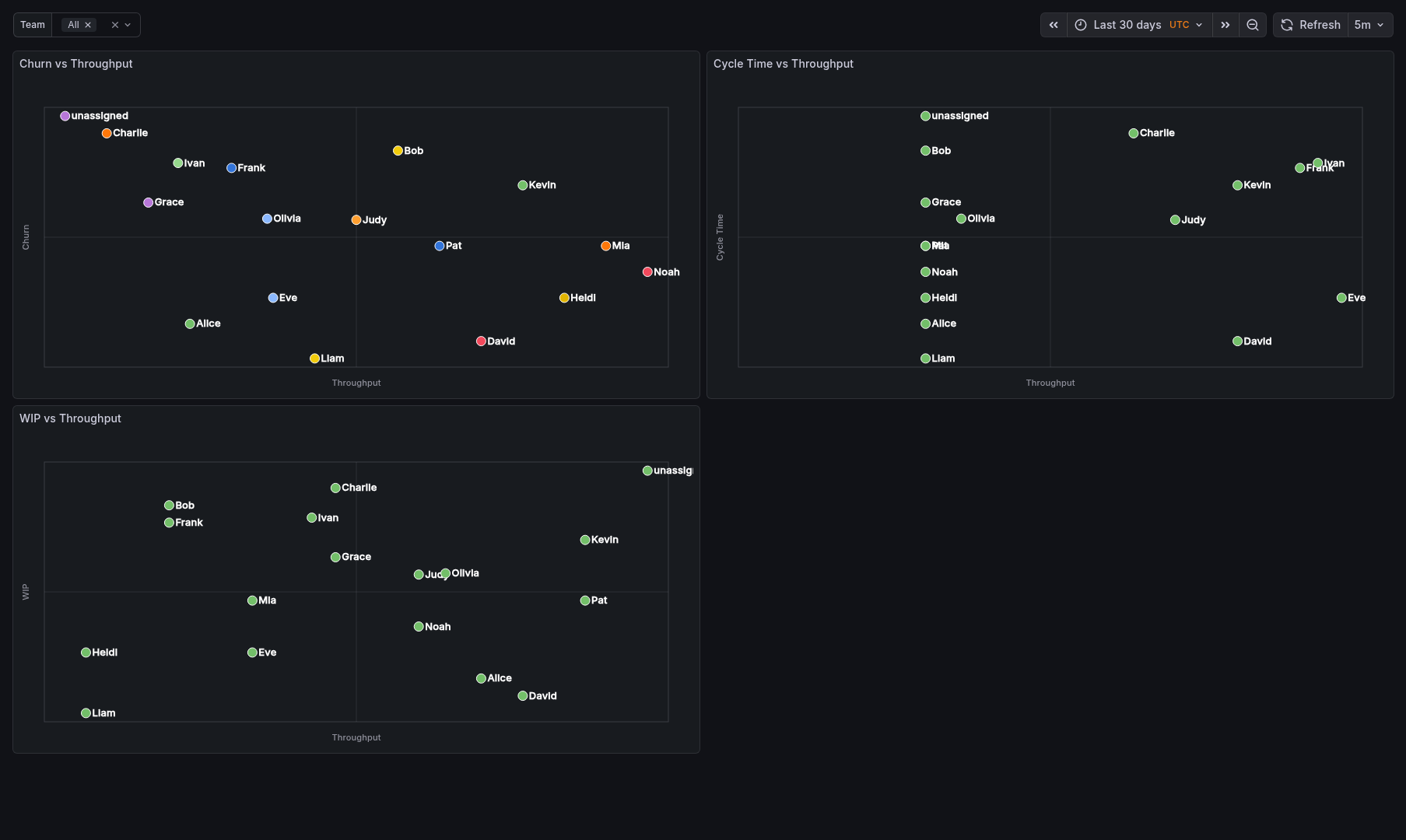
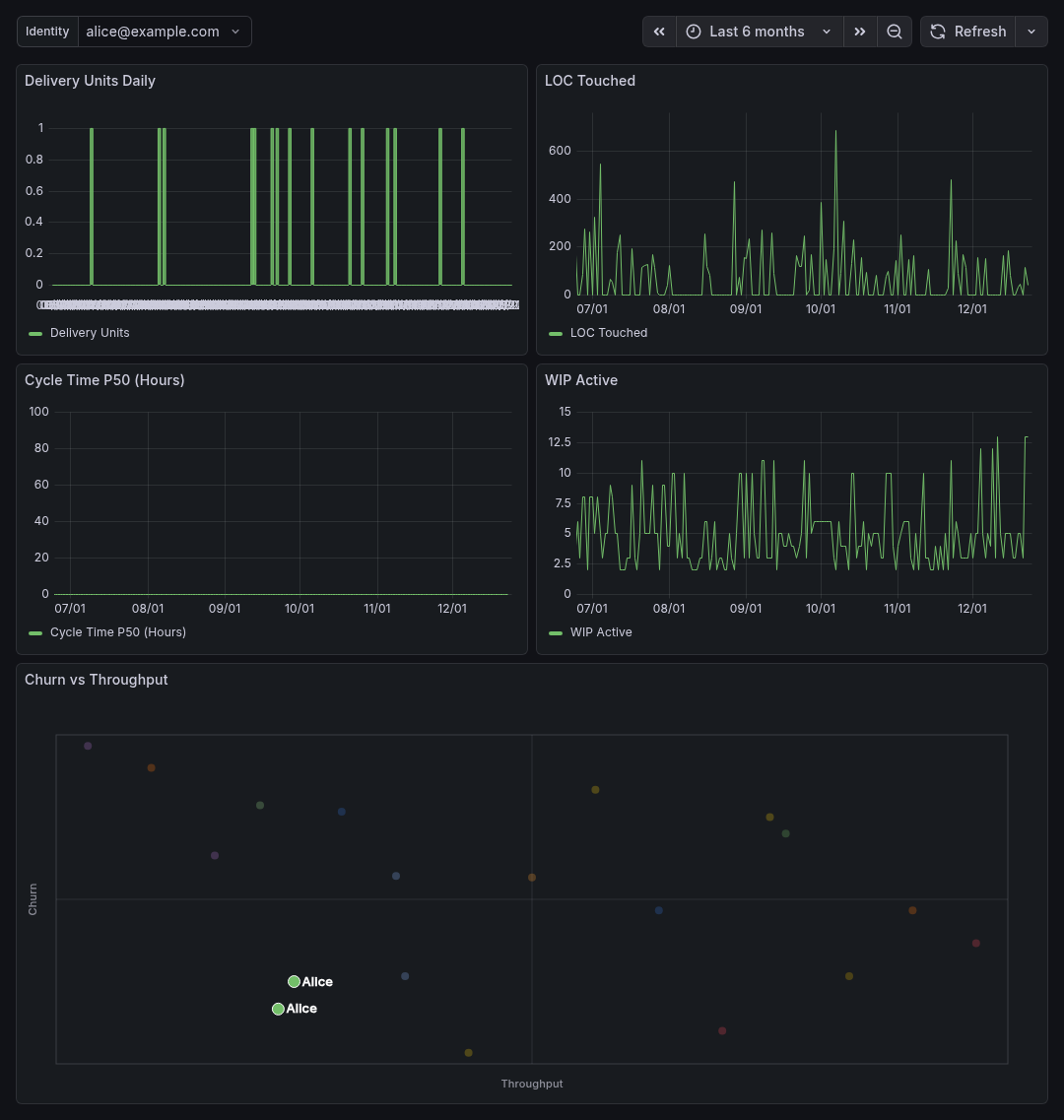
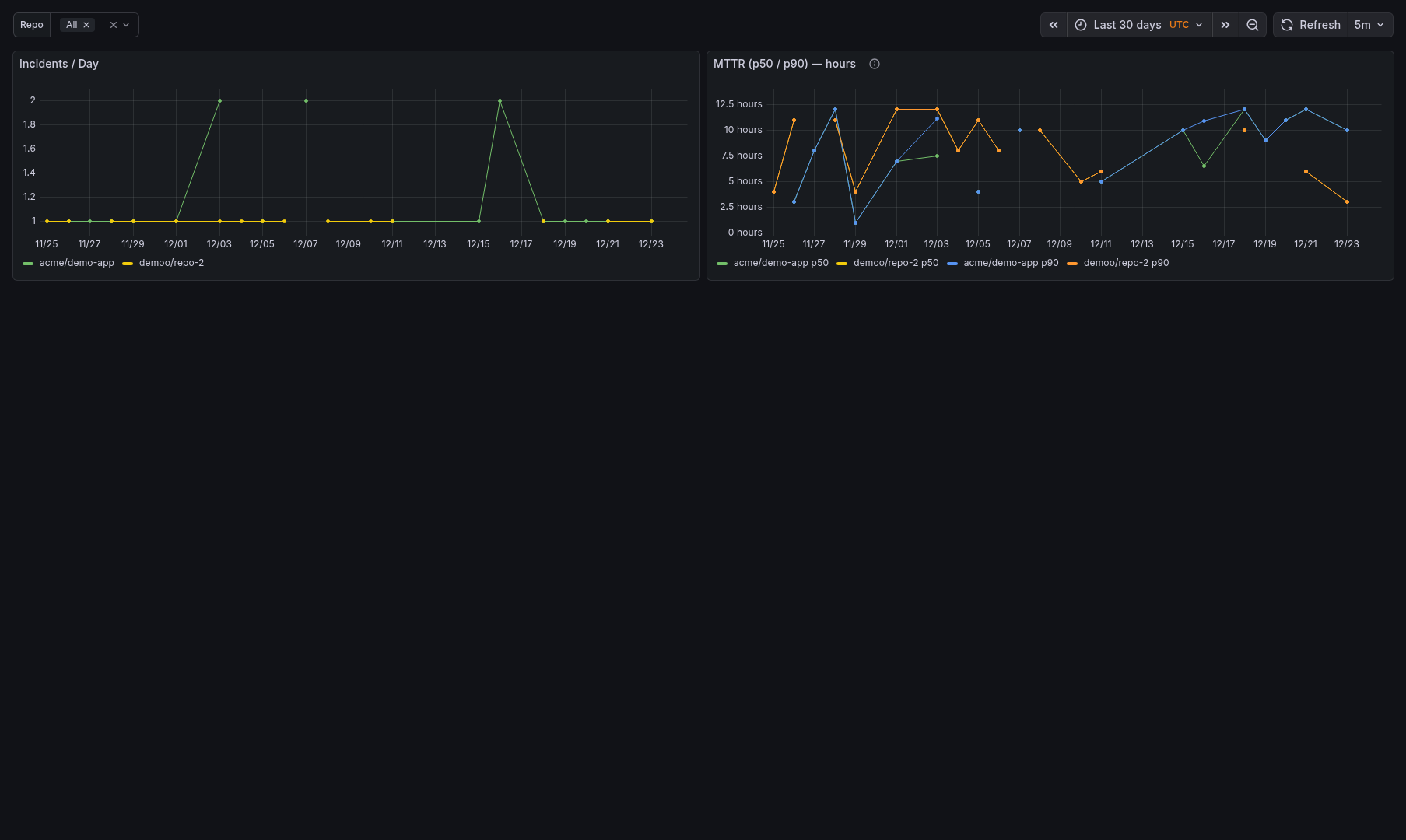
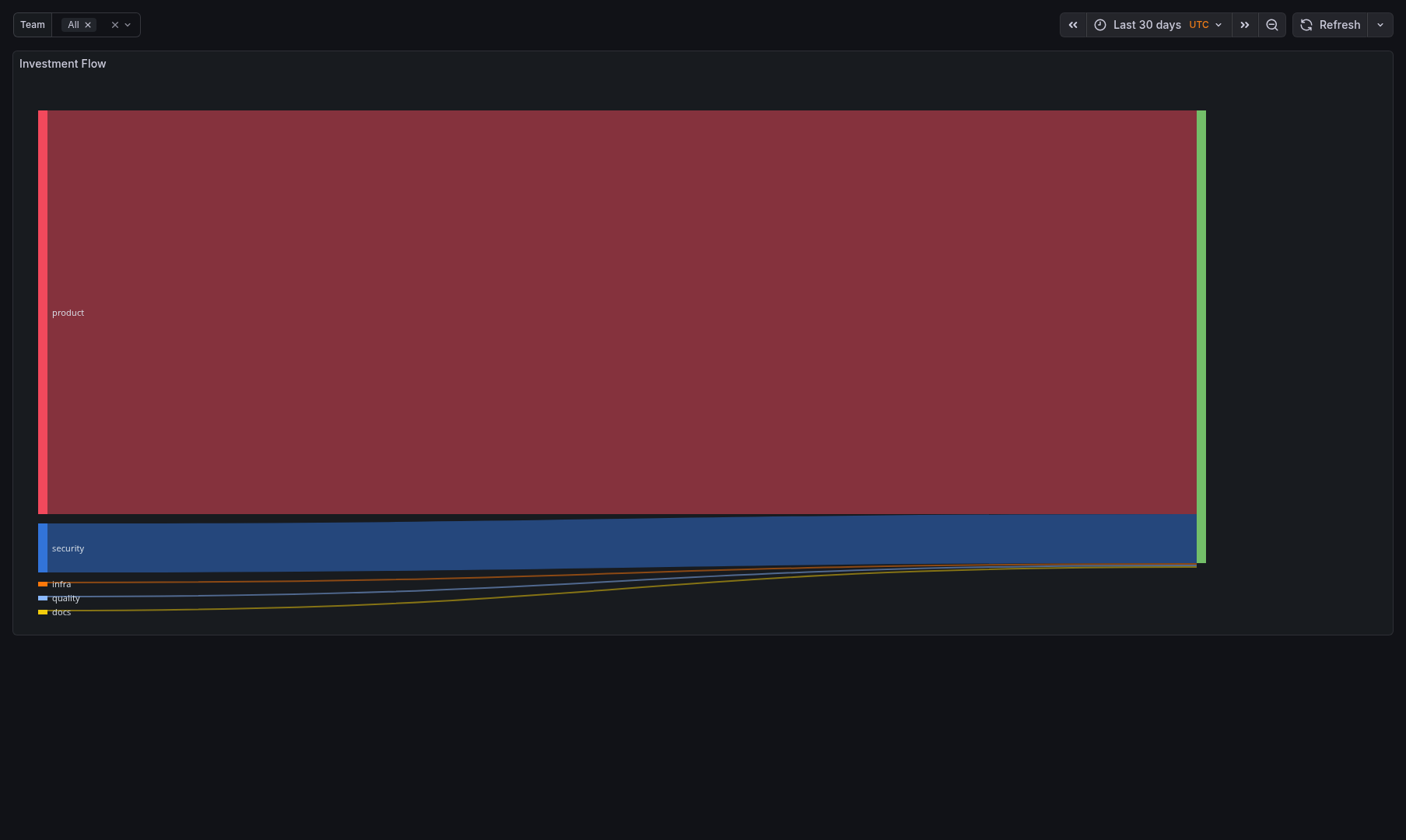
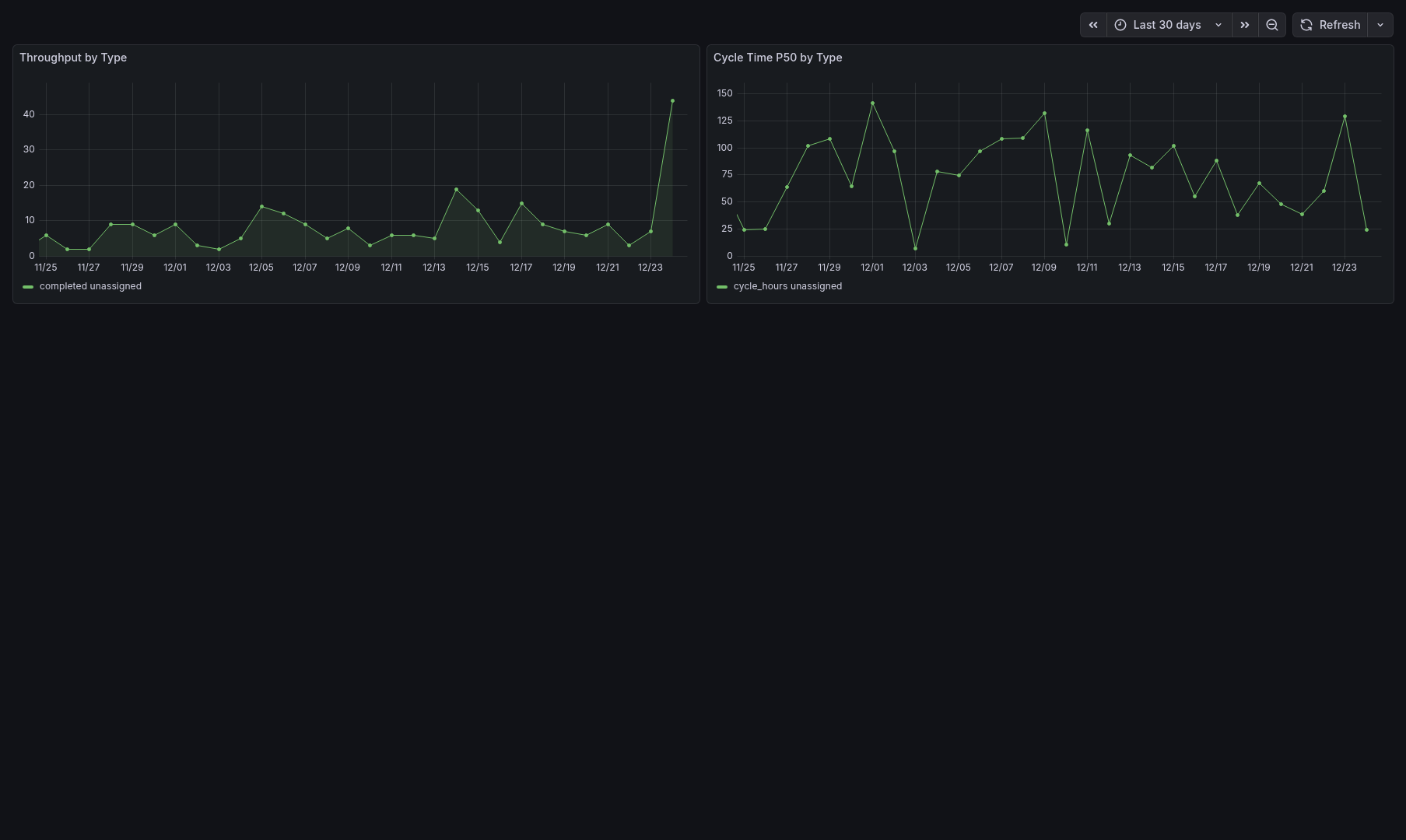
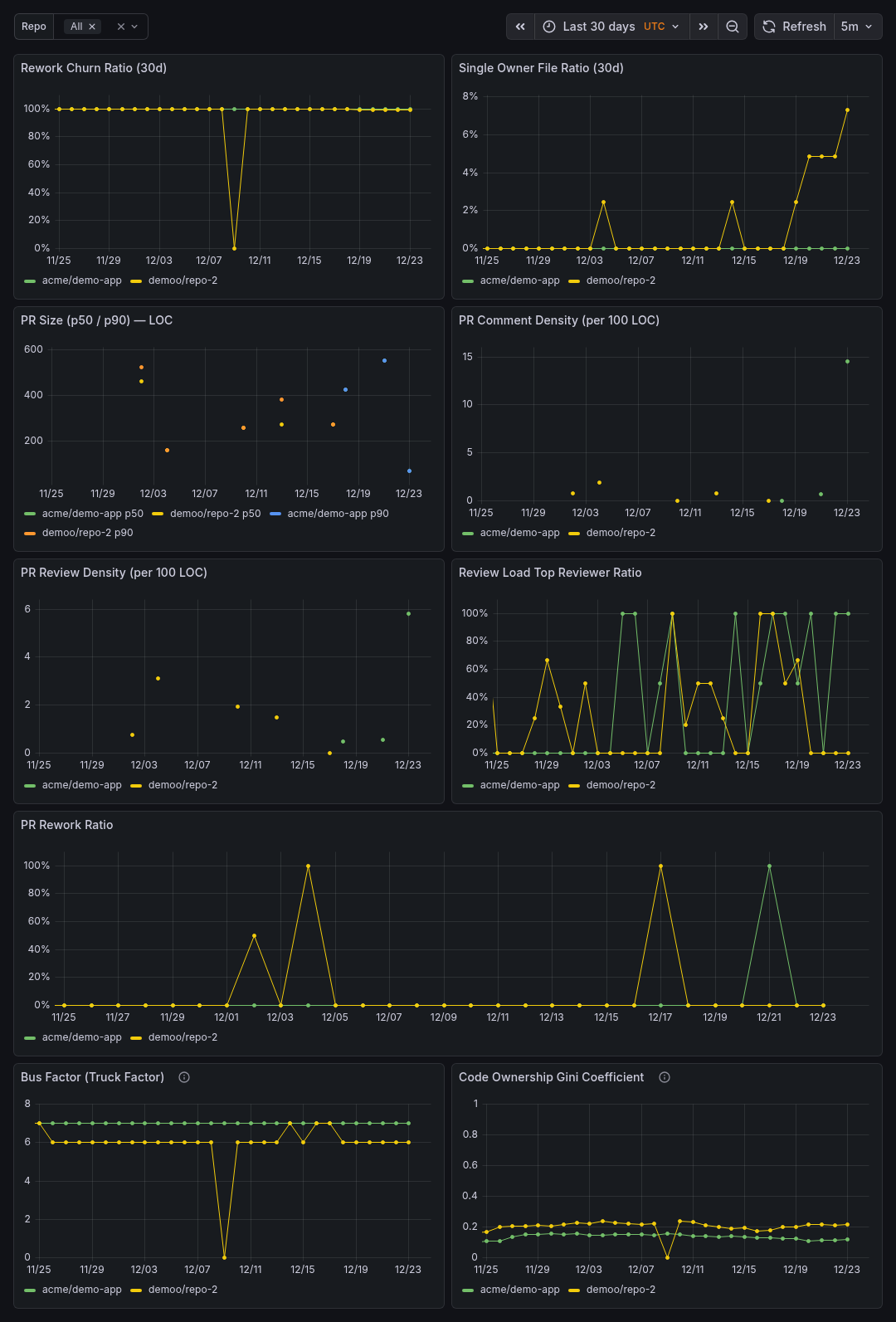
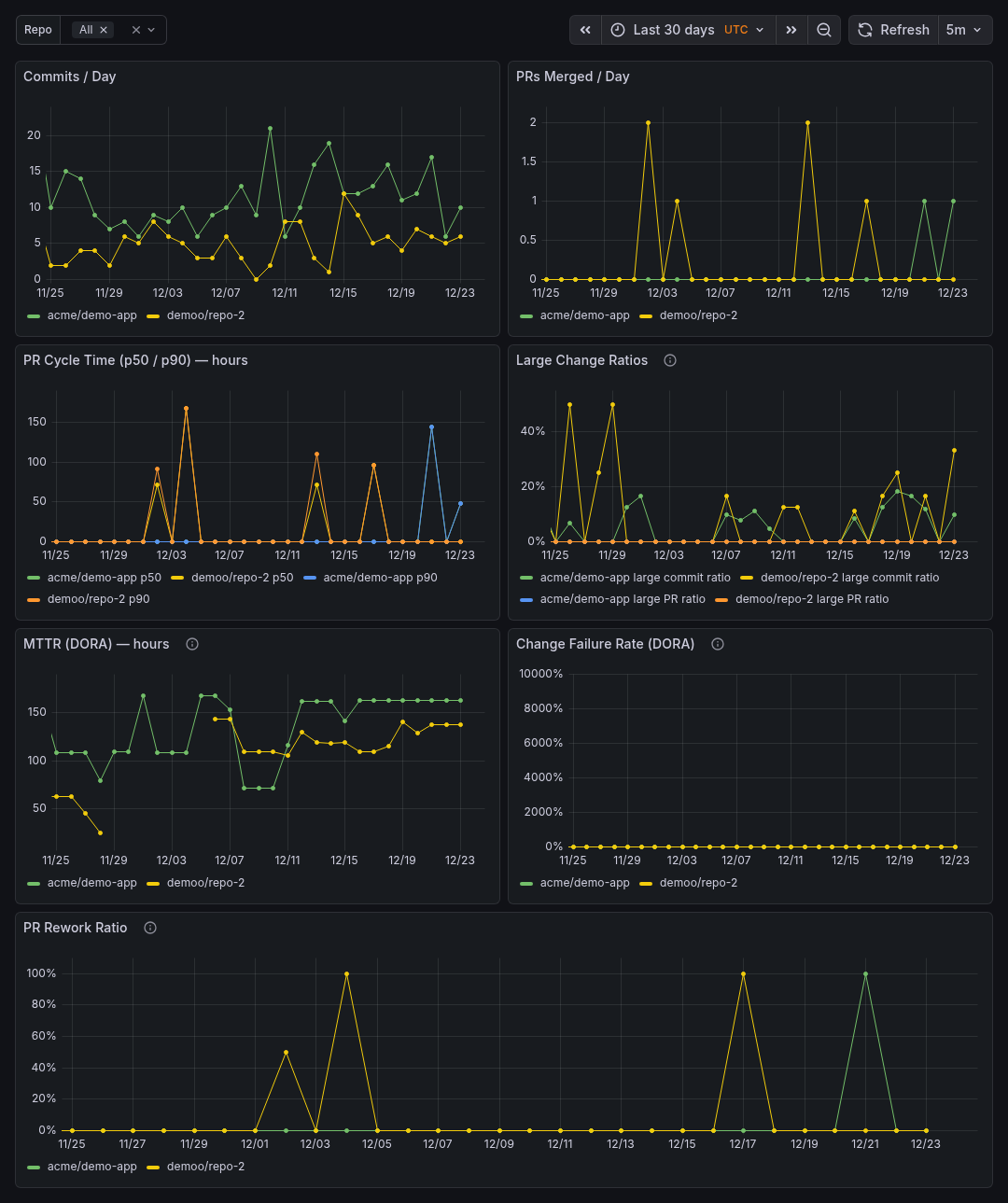
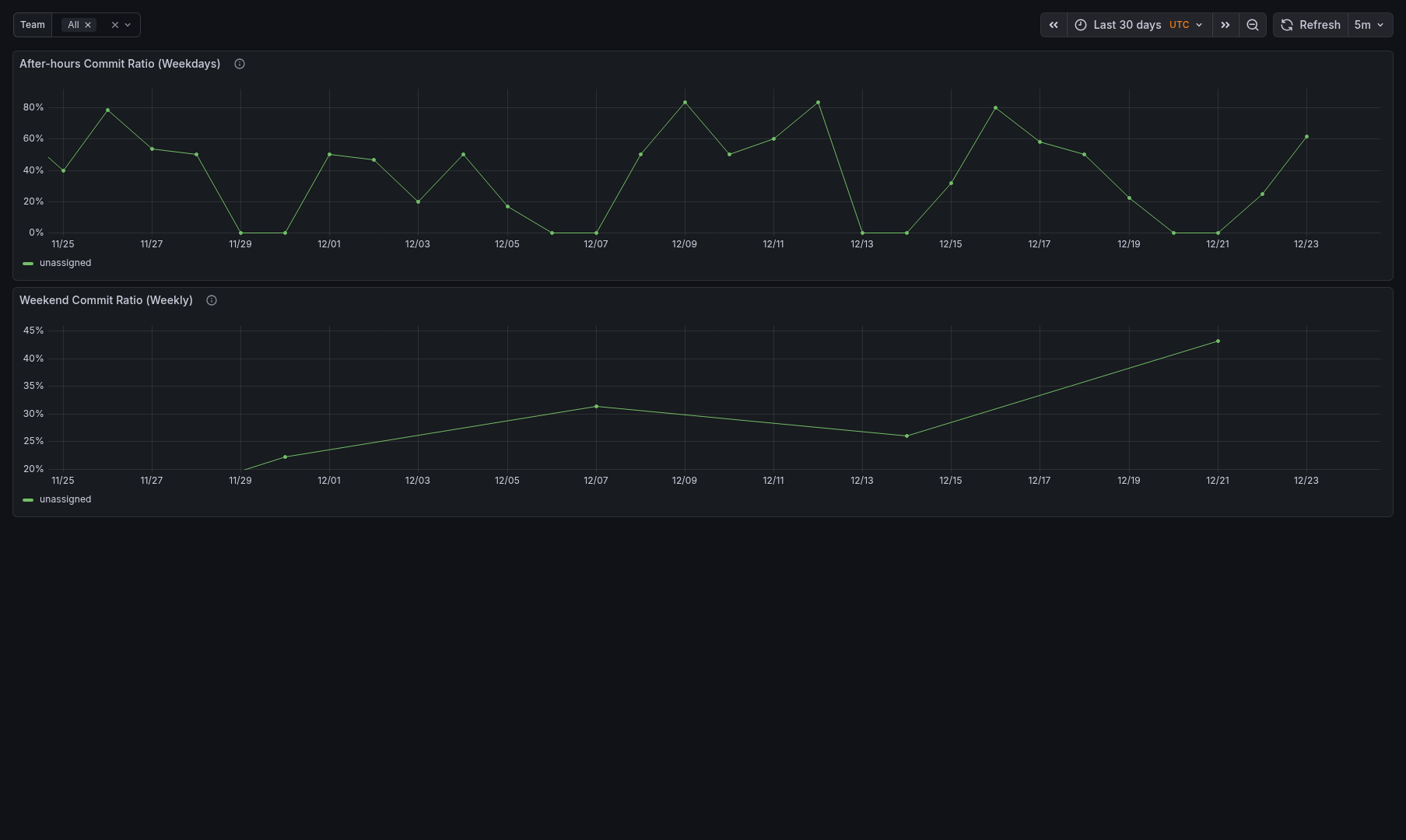
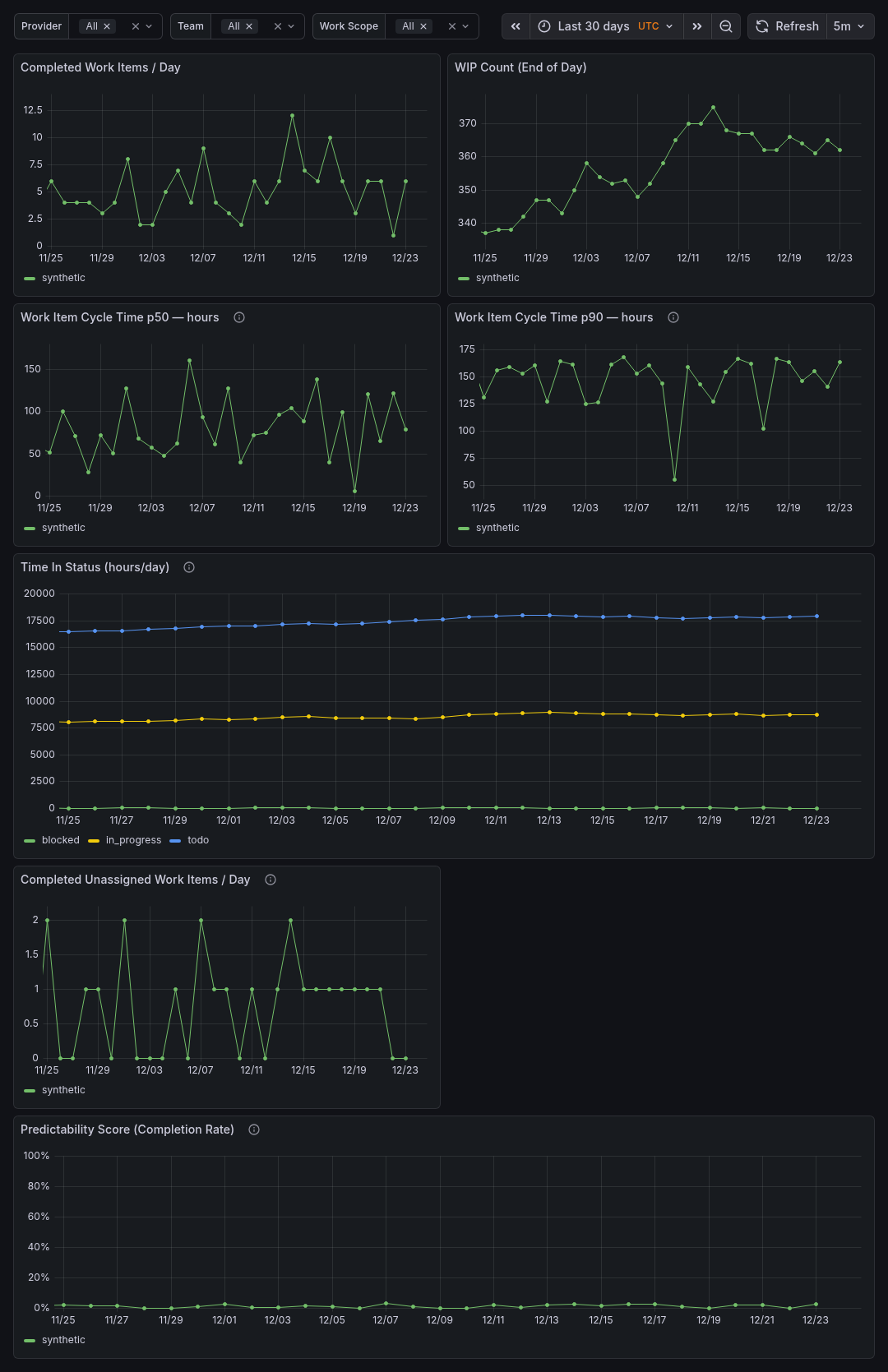
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dev_health_ops-0.4.0b2.tar.gz.
File metadata
- Download URL: dev_health_ops-0.4.0b2.tar.gz
- Upload date:
- Size: 814.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
53e100c031c04254f598217fae9aae69f07ff0da98c9c6fa5ed196d817918aaa
|
|
| MD5 |
301ee6509d917901c8a839bf61a6d069
|
|
| BLAKE2b-256 |
fb29d791c472144ec4f8b00143c4f0951932f2b71f1467d808096c708ed52b79
|
Provenance
The following attestation bundles were made for dev_health_ops-0.4.0b2.tar.gz:
Publisher:
publish-pypi.yml on full-chaos/dev-health-ops
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dev_health_ops-0.4.0b2.tar.gz -
Subject digest:
53e100c031c04254f598217fae9aae69f07ff0da98c9c6fa5ed196d817918aaa - Sigstore transparency entry: 868653984
- Sigstore integration time:
-
Permalink:
full-chaos/dev-health-ops@427257f97f38bb336ebda28e4fa7328eaf763d19 -
Branch / Tag:
refs/tags/v0.4.0-beta.2 - Owner: https://github.com/full-chaos
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@427257f97f38bb336ebda28e4fa7328eaf763d19 -
Trigger Event:
release
-
Statement type:
File details
Details for the file dev_health_ops-0.4.0b2-py3-none-any.whl.
File metadata
- Download URL: dev_health_ops-0.4.0b2-py3-none-any.whl
- Upload date:
- Size: 539.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
514493e8f9734f5c25617ab3d3e7a438342cbdab8a211431559e06fc3b8691ae
|
|
| MD5 |
eab6ad850d0e49f7b50fcc7054e6a350
|
|
| BLAKE2b-256 |
365d1daef9fd4a9178ad0e51224cf62b81960e0b1b69913f981eb7908b5fb36f
|
Provenance
The following attestation bundles were made for dev_health_ops-0.4.0b2-py3-none-any.whl:
Publisher:
publish-pypi.yml on full-chaos/dev-health-ops
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dev_health_ops-0.4.0b2-py3-none-any.whl -
Subject digest:
514493e8f9734f5c25617ab3d3e7a438342cbdab8a211431559e06fc3b8691ae - Sigstore transparency entry: 868653990
- Sigstore integration time:
-
Permalink:
full-chaos/dev-health-ops@427257f97f38bb336ebda28e4fa7328eaf763d19 -
Branch / Tag:
refs/tags/v0.4.0-beta.2 - Owner: https://github.com/full-chaos
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-pypi.yml@427257f97f38bb336ebda28e4fa7328eaf763d19 -
Trigger Event:
release
-
Statement type:







