Diffusers




Project description




🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves as a modular toolbox for inference and training of diffusion models.
More precisely, 🤗 Diffusers offers:
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see src/diffusers/pipelines).
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference (see src/diffusers/schedulers).
- Multiple types of models, such as UNet, that can be used as building blocks in an end-to-end diffusion system (see src/diffusers/models).
- Training examples to show how to train the most popular diffusion models (see examples).
Definitions
Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet

Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
Schedulers: Algorithm class for both inference and training. The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training. Examples: DDPM, DDIM, PNDM, DEIS

Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
Diffusion Pipeline: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ... Examples: Glide, Latent-Diffusion, Imagen, DALL-E 2
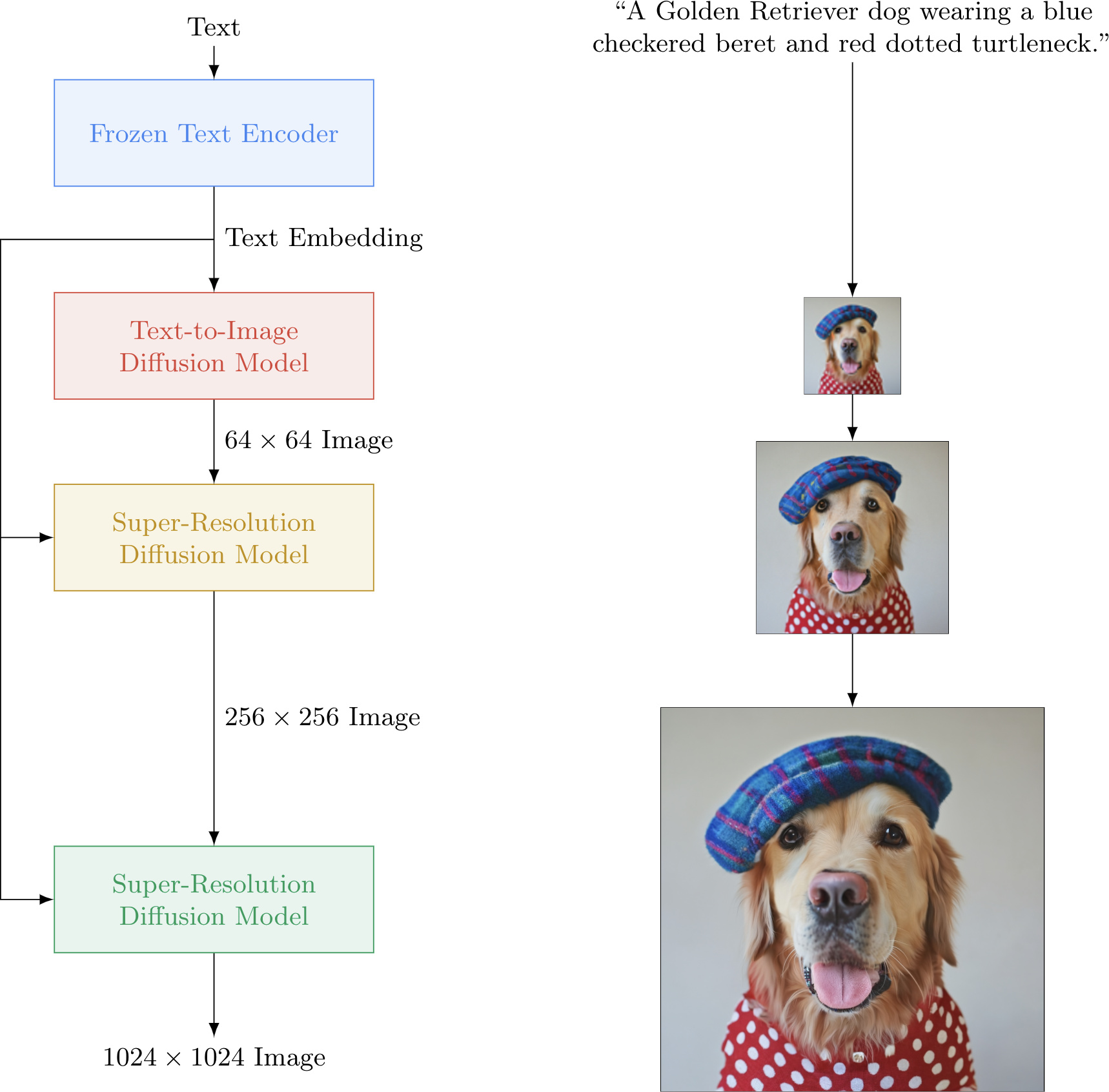
Figure from ImageGen (https://imagen.research.google/).
Philosophy
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. E.g., the provided schedulers are separated from the provided models and provide well-commented code that can be read alongside the original paper.
- Diffusers is modality independent and focusses on providing pretrained models and tools to build systems that generate continous outputs, e.g. vision and audio.
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are Glide and Latent Diffusion.
Quickstart
In order to get started, we recommend taking a look at two notebooks:
- The Diffusers notebook, which showcases an end-to-end example of usage for diffusion models, schedulers and pipelines. Take a look at this notebook to learn how to use the pipeline abstraction, which takes care of everything (model, scheduler, noise handling) for you, but also to get an understanding of each independent building blocks in the library.
- The Training diffusers notebook, which summarizes diffuser model training methods. This notebook takes a step-by-step approach to training your diffuser model on an image dataset, with explanatory graphics.
Installation
pip install diffusers # should install diffusers 0.0.4
1. diffusers as a toolbox for schedulers and models
diffusers is more modularized than transformers. The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
Both models and schedulers should be load- and saveable from the Hub.
For more examples see schedulers and models
Example for Unconditonal Image generation DDPM:
import torch
from diffusers import UNet2DModel, DDIMScheduler
import PIL.Image
import numpy as np
import tqdm
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
# 1. Load models
scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
unet = UNet2DModel.from_pretrained("fusing/ddpm-celeba-hq", ddpm=True).to(torch_device)
# 2. Sample gaussian noise
generator = torch.manual_seed(23)
unet.image_size = unet.resolution
image = torch.randn(
(1, unet.in_channels, unet.image_size, unet.image_size),
generator=generator,
)
image = image.to(torch_device)
# 3. Denoise
num_inference_steps = 50
eta = 0.0 # <- deterministic sampling
scheduler.set_timesteps(num_inference_steps)
for t in tqdm.tqdm(scheduler.timesteps):
# 1. predict noise residual
with torch.no_grad():
residual = unet(image, t)["sample"]
prev_image = scheduler.step(residual, t, image, eta)["prev_sample"]
# 3. set current image to prev_image: x_t -> x_t-1
image = prev_image
# 4. process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# 5. save image
image_pil.save("generated_image.png")
Example for Unconditonal Image generation LDM:
In the works
For the first release, 🤗 Diffusers focuses on text-to-image diffusion techniques. However, diffusers can be used for much more than that! Over the upcoming releases, we'll be focusing on:
- Diffusers for audio
- Diffusers for reinforcement learning (initial work happening in https://github.com/huggingface/diffusers/pull/105).
- Diffusers for video generation
- Diffusers for molecule generation (initial work happening in https://github.com/huggingface/diffusers/pull/54)
A few pipeline components are already being worked on, namely:
- BDDMPipeline for spectrogram-to-sound vocoding
- GLIDEPipeline to support OpenAI's GLIDE model
- Grad-TTS for text to audio generation / conditional audio generation
We want diffusers to be a toolbox useful for diffusers models in general; if you find yourself limited in any way by the current API, or would like to see additional models, schedulers, or techniques, please open a GitHub issue mentioning what you would like to see.
Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
- @CompVis' latent diffusion models library, available here
- @hojonathanho original DDPM implementation, available here as well as the extremely useful translation into PyTorch by @pesser, available here
- @ermongroup's DDIM implementation, available here.
- @yang-song's Score-VE and Score-VP implementations, available here
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available here.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file diffusers-0.1.2.tar.gz.
File metadata
- Download URL: diffusers-0.1.2.tar.gz
- Upload date:
- Size: 76.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
054f5550bd20645a1bf7c238661e2b595d98be68beba258d1113681fed7dd7bb
|
|
| MD5 |
88f6f0da1015578a4925ae380a6c6dd6
|
|
| BLAKE2b-256 |
b58351ec5b5fdf0b4a21cb60e7e0f93b847e9b613603e5ae48d3c5fc1e5e36b2
|
File details
Details for the file diffusers-0.1.2-py3-none-any.whl.
File metadata
- Download URL: diffusers-0.1.2-py3-none-any.whl
- Upload date:
- Size: 94.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7fdfbcbfa3e9cc9e8e54ca7cab630a16aa8e85c112fa492b4a80de2866a19e5c
|
|
| MD5 |
14fc92d5a99fb64cd76e7fb912b717dc
|
|
| BLAKE2b-256 |
c5309c04a27e3d61a3ca855743e17568e624daee20a988536b970971c22be45b
|







