Efficient speech quality assessment learned from SSL-based speech quality assessment model

Project description
Distill-MOS: a compact speech-quality assessment model
Distill-MOS is a compact and efficient speech quality assessment model learned from a larger speech quality assessment model based on wav2vec2.0 XLS-R embeddings. The work is described in the paper: "Distillation and Pruning for Scalable Self-Supervised Representation-Based Speech Quality Assessment".
Usage
Local Installation
To use the model locally, simply install using pip:
pip install distillmos
Sample Inference Code
Model instantiation is as easy as:
import distillmos
sqa_model = distillmos.ConvTransformerSQAModel()
sqa_model.eval()
Weights are loaded automatically.
The input to the model is a torch.Tensor with shape [batch_size, signal_length], containing mono speech waveforms sampled at 16kHz. The model returns mean opinion scores with [batch_size,] (one for each audio waveform in the batch) in the range 1 (bad) .. 5 (excellent).
import torchaudio
x, sr = torchaudio.load('my_speech_file.wav')
if x.shape[0] > 1:
print(
f"Warning: file has multiple channels, using only the first channel."
)
x = x[0, None, :]
# resample to 16kHz if needed
if sr != 16000:
x = torchaudio.transforms.Resample(sr, 16000)(x)
with torch.no_grad():
mos = sqa_model(x)
print('MOS Score:', mos)
Command Line Interface
You can also use distillmos from the command line for inference on individual .wav files, folders containing .wav files, and lists of file paths. Please call
distillmos --help
for a detailed list of available commands and options.
Example Ratings: See Distill-MOS in Action!
Below are example ratings from the GenSpeech dataset (available https://github.com/QxLabIreland/datasets/tree/597fbf9b60efe555c1f7180e48a508394d817f73/genspeech), licensed under Apache v2.0.
Example: LPCNet_listening_test/mfall/dir3/, click 🔊 to download/play
| Audio | Distill-MOS | Human MOS |
|---|---|---|
| 🔊 Uncoded Reference Speech | 4.55 | |
| 🔊 Speex (Lowest Distill-MOS) | 1.47 | 1.18 |
| 🔊 MELP | 3.09 | 1.95 |
| 🔊 LPCNet Quantized | 3.28 | 3.35 |
| 🔊 Opus | 4.05 | 4.31 |
| 🔊 LPCNet Unquantized (Highest Distill-MOS among Coded Versions) | 4.12 | 4.64 |
Install from source and test locally
- Clone this repository
- Run
pip install ".[dev]"from the repository root in a fresh Python environment to install from source. - Run
pytest. The testtest_cli.test_cli()will download some speech samples from the Genspeech dataset and compare the model output to expected scores.
Citation
If this model helps you in your work, we’d love for you to cite our paper!
@misc{stahl2025distillation,
title={Distillation and Pruning for Scalable Self-Supervised Representation-Based Speech Quality Assessment},
author={Benjamin Stahl and Hannes Gamper},
year={2025},
eprint={????.?????},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/????.?????},
}
Intended Uses
Primary Use Cases
The model released in this repository takes a short speech recording as input and predicts its perceptual speech quality by providing an estimated mean opinion score (MOS). The model is much smaller than other state-of-the-art MOS estimators, providing a trade-off between parameter count and speech quality estimation performance. The primary use of this model is to reproduce results reported in the paper and for research purposes as a relatively light-weight MOS estimation model that generalizes across a variety of tasks.
Use Case Considerations and Model Limitations
The model is only evaluated on the tasks reported in the paper, including deep noise suppression and signal improvement, and only for speech. The model may not generalize to unseen tasks or languages. Use of the model in unsupported scenarios may result in wrong or misleading speech quality estimates. When using the model for a specific task, developers should consider accuracy, safety, and fairness, particularly in high-risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
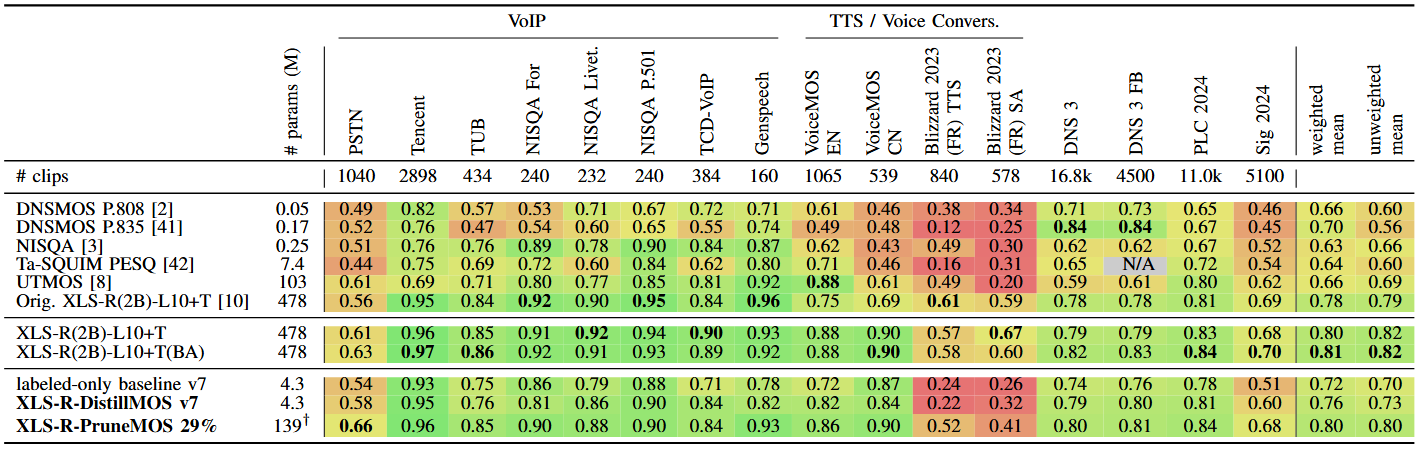
Benchmarks
Training
| Developer | Microsoft |
| Architecture | Convolutional transformer |
| Inputs | Speech recording |
| Input length | 7.68 s / arbitrary length by segmenting |
| GPUs | 4 x A6000 |
| Training data | See below |
| Outputs | Estimate of speech quality mean-opinion score (MOS) |
| Dates | Trained between May and July 2024 |
| Supported languages | English |
| Release date | Oct 2024 |
| License | MIT |
Training Datasets
The model is trained on a large set of speech samples:
- About 2600 hours of unlabeled speech and 180 hours of noise recordings from the ICASSP 2022 Deep Noise Suppression Challenge
- The output of publicly available text-to-speech synthesis models
- PSTN
- ConferencingSpeech 2022 Challenge
- NISQA
- VoiceMOS Challenge 2022
- Submissions to ICASSP 2021 Deep Noise Suppression Challenge
- Submissions to Interspeech 2022 audio deep packet loss concealment challenge
- Submissions to ICASSP 2023 Speech Signal Improvement Challenge
Responsible AI Considerations
Similarly to other (audio) AI models, the model may behave in ways that are unfair, unreliable, or inappropriate. Some of the limiting behaviors to be aware of include:
-
Quality of Service and Limited Scope: The model is trained primarily on spoken English and for speech enhancement or degradation scenarios. Evaluation on other languages, dialects, speaking styles, or speech scenarios may lead to inaccurate speech quality estimates.
-
Representation and Stereotypes: This model may over- or under-represent certain groups, or reinforce stereotypes present in speech data. These limitations may persist despite safety measures due to varying representation in the training data.
-
Information Reliability: The model can produce speech quality estimates that might seem plausible but are inaccurate.
Developers should apply responsible AI best practices and ensure compliance with relevant laws and regulations. Important areas for consideration include:
-
Fairness and Bias: Assess and mitigate potential biases in evaluation data, especially for diverse speakers, accents, or acoustic conditions.
-
High-Risk Scenarios: Evaluate suitability for use in scenarios where inaccurate speech quality estimates could lead to harm, such as in security or safety-critical applications.
-
Misinformation: Be aware that incorrect speech quality estimates could potentially create or amplify misinformation. Implement robust verification mechanisms.
-
Privacy Concerns: Ensure that the processing of any speech recordings respects privacy rights and data protection regulations.
-
Accessibility: Consider the model's performance for users with visual or auditory impairments and implement appropriate accommodations.
-
Copyright Issues: Be cautious of potential copyright infringement when using copyrighted audio content.
-
Deepfake Potential: Implement safeguards against the model's potential misuse for creating misleading or manipulated content.
Developers should inform end-users about the AI nature of the system and implement feedback mechanisms to continuously improve alignment accuracy and appropriateness.
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file distillmos-0.9.0.tar.gz.
File metadata
- Download URL: distillmos-0.9.0.tar.gz
- Upload date:
- Size: 15.6 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
588d51cb5574b8b0ab91477860dd5bd21964639c54465c04e86df6c497c92563
|
|
| MD5 |
9c1e53a149dec371fb1cc8fbf8c0cc00
|
|
| BLAKE2b-256 |
bb2fb51242e097deec123cabdfab0944dc5ea2836c33e9d4674bbc91c2b464c6
|
File details
Details for the file distillmos-0.9.0-py3-none-any.whl.
File metadata
- Download URL: distillmos-0.9.0-py3-none-any.whl
- Upload date:
- Size: 15.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad7da987b6464c7c6d4b5bf3de584adc331fc5408524375d6ca2da8c57dc6838
|
|
| MD5 |
3d1cceea28b3b757d2e04cb24142bae3
|
|
| BLAKE2b-256 |
a4cdad8d154df3785dca2c77396d60f038aa260d6cec9dd6df8a05d6904293ef
|







