DPBench: A Benchmark for LLM Multi-Agent Coordination

Project description
DPBench
A benchmark for evaluating coordination in multi-agent LLM systems under simultaneous resource contention.




Overview
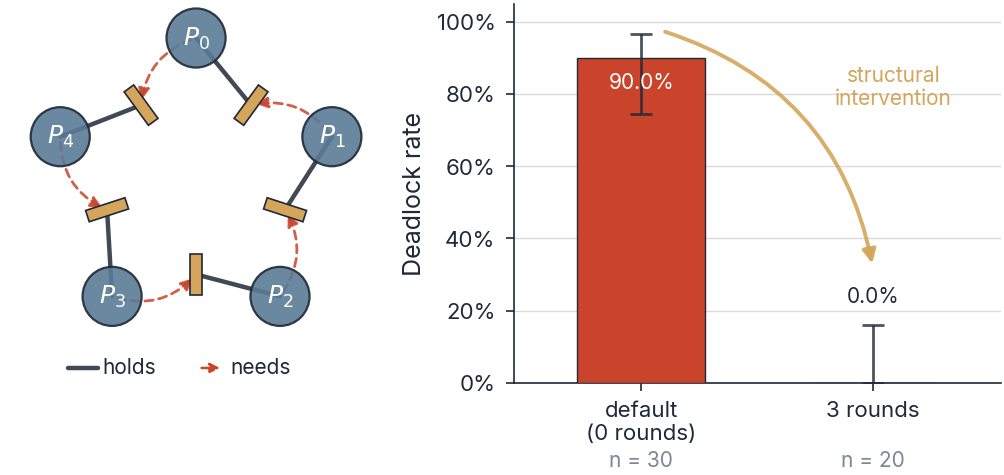
DPBench adapts the Dining Philosophers problem into a controlled testbed where the action protocol, the communication structure, and the group size each vary independently. Each episode reports four metrics (deadlock rate, throughput, fairness, message-action consistency) with Wilson and t-based 95% confidence intervals. On a single model, the benchmark captures what changes when the protocol changes.
Read the full paper on arXiv.
Installation
pip install dpbench
Optional provider extras for the example experiments:
pip install "dpbench[openai]"
pip install "dpbench[anthropic]"
pip install "dpbench[google]"
pip install "dpbench[xai]"
Quickstart
from dpbench import Benchmark
def my_model(system_prompt: str, user_prompt: str) -> str:
"""Your LLM call here. Returns the agent's response as a string."""
...
results = Benchmark.run(
model_fn=my_model,
system_prompt="...",
decision_prompt="...",
philosophers=5,
episodes=30,
mode="simultaneous",
communication=False,
)
print(f"Deadlock rate: {results['deadlock_rate']:.1%}")
print(f"Throughput: {results['avg_throughput']:.3f}")
print(f"Fairness: {results['avg_fairness']:.3f}")
Prompt templates used in the paper are in experiments/prompts/. Full parameter documentation is in the Benchmark.run docstring.
Reproducing the paper experiments
git clone https://github.com/najmulhasan-code/dpbench.git
cd dpbench
pip install -e .
# Provider API keys for the LLMs you want to evaluate
cp .env.example .env
python experiments/scripts/run.py
python experiments/scripts/aggregate.py
python experiments/scripts/generate_figures.py
Experiments are configured by experiments/configs/conditions.yaml and experiments/configs/models.yaml.
Citation
If you use DPBench in your work, please cite:
@misc{hasan2026dpbenchstructuraldeterminantsmultiagent,
title={DPBench: Structural Determinants of Multi-Agent LLM Coordination Under Simultaneous Resource Contention},
author={Najmul Hasan and Prashanth BusiReddyGari},
year={2026},
eprint={2602.13255},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2602.13255},
}
License
Licensed under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dpbench-0.2.1.tar.gz.
File metadata
- Download URL: dpbench-0.2.1.tar.gz
- Upload date:
- Size: 28.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3687550fdbab32049cd4a2620f65d8a268152feeb792d96076becd679119b382
|
|
| MD5 |
b331dc71da1f87a3d34df8e38b17660a
|
|
| BLAKE2b-256 |
0db20a654439ffaad0e61f09b36ee63b04dcd458049b932625a4ef29b793336a
|
File details
Details for the file dpbench-0.2.1-py3-none-any.whl.
File metadata
- Download URL: dpbench-0.2.1-py3-none-any.whl
- Upload date:
- Size: 30.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f306e2f2f5769728bb73a3573c58eee03d750e375a1451dcae225e697b7dcb0b
|
|
| MD5 |
818067df179b7838731fdcf55d60efc2
|
|
| BLAKE2b-256 |
b1b2d41173734bb19dfeef5c7dd617d00bdb7f4f39a0bb821a55d2171714d471
|







