lib to build dagster pipelines from standalone notebooks

Project description
Dsml4s8e
Dsml4s8e is a Python library that extends Dagster to help manage the ML workflow around Jupyter notebooks development.
Dsml4s8e addresses issues:
- Building of pipelines from standalone notebooks
- Standardizing a structure of ML/DS pipeline projects to easy share and continuous improve them
- Managing constantly evolving pipelines
Dsml4s8e designed to support the following workflow:
- Define a project structure and a structure of the pipeline data catalog for your pipeline by using class
Storage Catalog ABC - Develop standalone Jupyter notebooks corresponding specification requirements
- Difine a pipeline -- a sequence of notebooks and deloy the pipelien in vary environments(experimental/test/prod)
- Execute pipelines many times with different configurations in vary environments and on vary infrastructure
A job is a set of notebooks arranged into a DAG. Dsml4s8e simplify jobs definition based on a set of Jupyter notebooks.
# dag.py
from dsml4s8e.define_job import define_job
from dagstermill import local_output_notebook_io_manager
from dagster import job
from pathlib import Path
@job(
name='simple_pipeline',
tags={"cdlc_stage": "dev"},
resource_defs={
"output_notebook_io_manager": local_output_notebook_io_manager,
}
)
def dagstermill_pipeline():
module_path = Path(__file__)
define_job(
root_path=module_path.parent.parent,
nbs_sequence=[
"data_load/nb_0.ipynb",
"data_load/nb_1.ipynb",
"data_load/nb_2.ipynb"
]
)
In this code block, we use define_job to automate a dagstermil job definition:
As a result, a dagster pipeline will be built from standalone notebooks:

Dsml4s8e proper for build a cloud agnostic DSML platform.
You can play with a demo pipeline skeleton project.
Installation of local dev container
# Create a work directory to clone a git repository. The work directory will be mounted to the container
mkdir work
#Step into the work directory
cd work
# Clone repository
git clone https://github.com/dsml4/dsml4s8e.git
# Step into a derictory with a Dockerfile
cd dsml4s8e/images/dev
# Build a image
docker build -t dsml4s8e .
# Go back into the work directory to a correct using pwd command inside the next docker run instruction
cd ../../../
# Create and run a container staying in the work directory.
docker run --rm --name my_dag -p 3000:3000 -p 8888:8888 -v $(pwd):/home/jovyan/work -e DAGSTER_HOME=/home/jovyan/work/daghome dsml4s8e bash setup_pipeline.sh
Open JupyterLab in a browser: http://localhost:8888/lab
Open Dagster in a browser: http://localhost:3000/
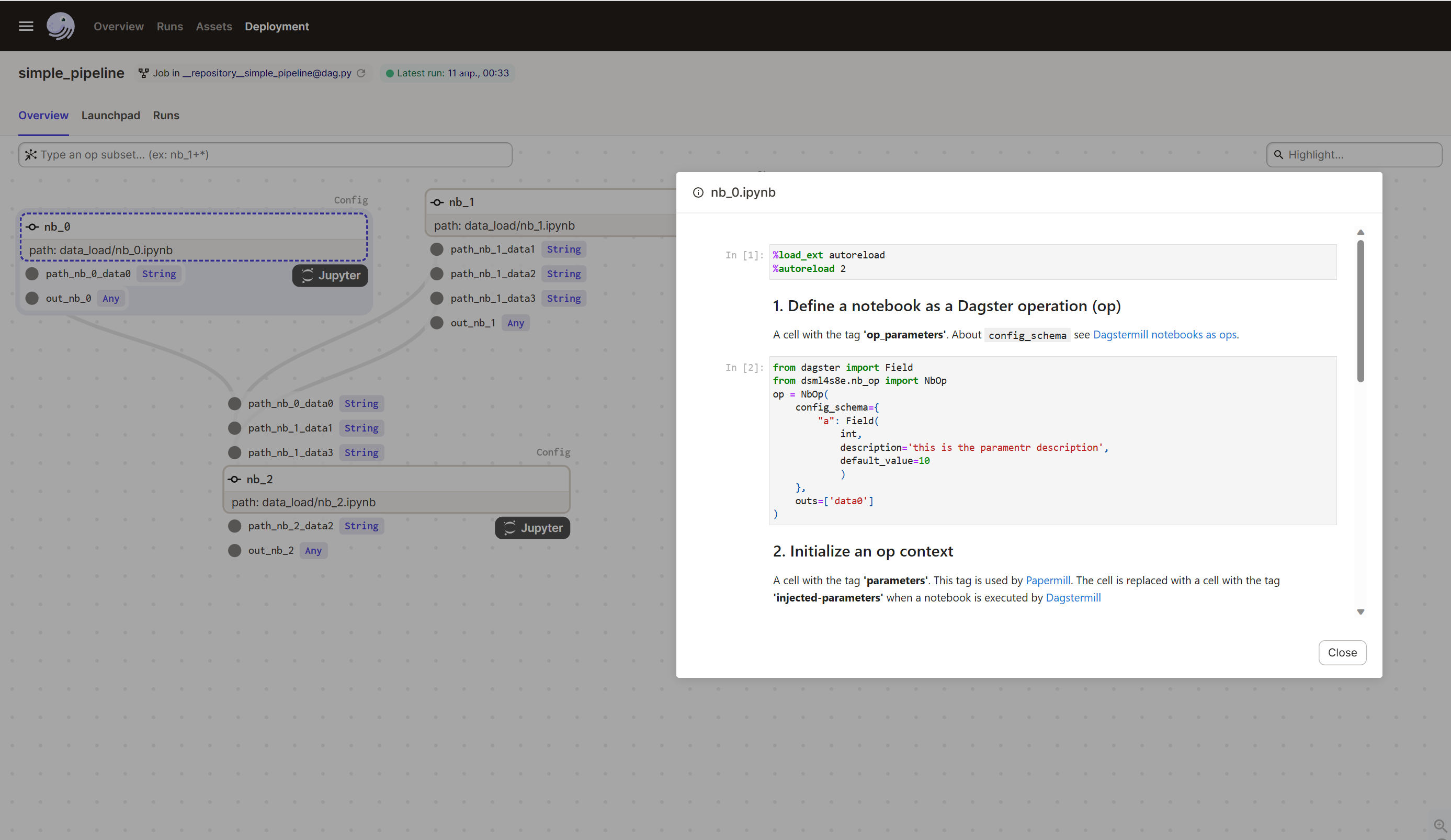
The standalone notebook specification
A standalone notebook is a main building block in our pipelines development flow.
To transform a standalone notebook to Dagster Op(a pipeline step) we need to add 4 specific cells to the notebook. Next, we will discuss what concerns are addressed each of the cells and what library classes are responsible for each one.
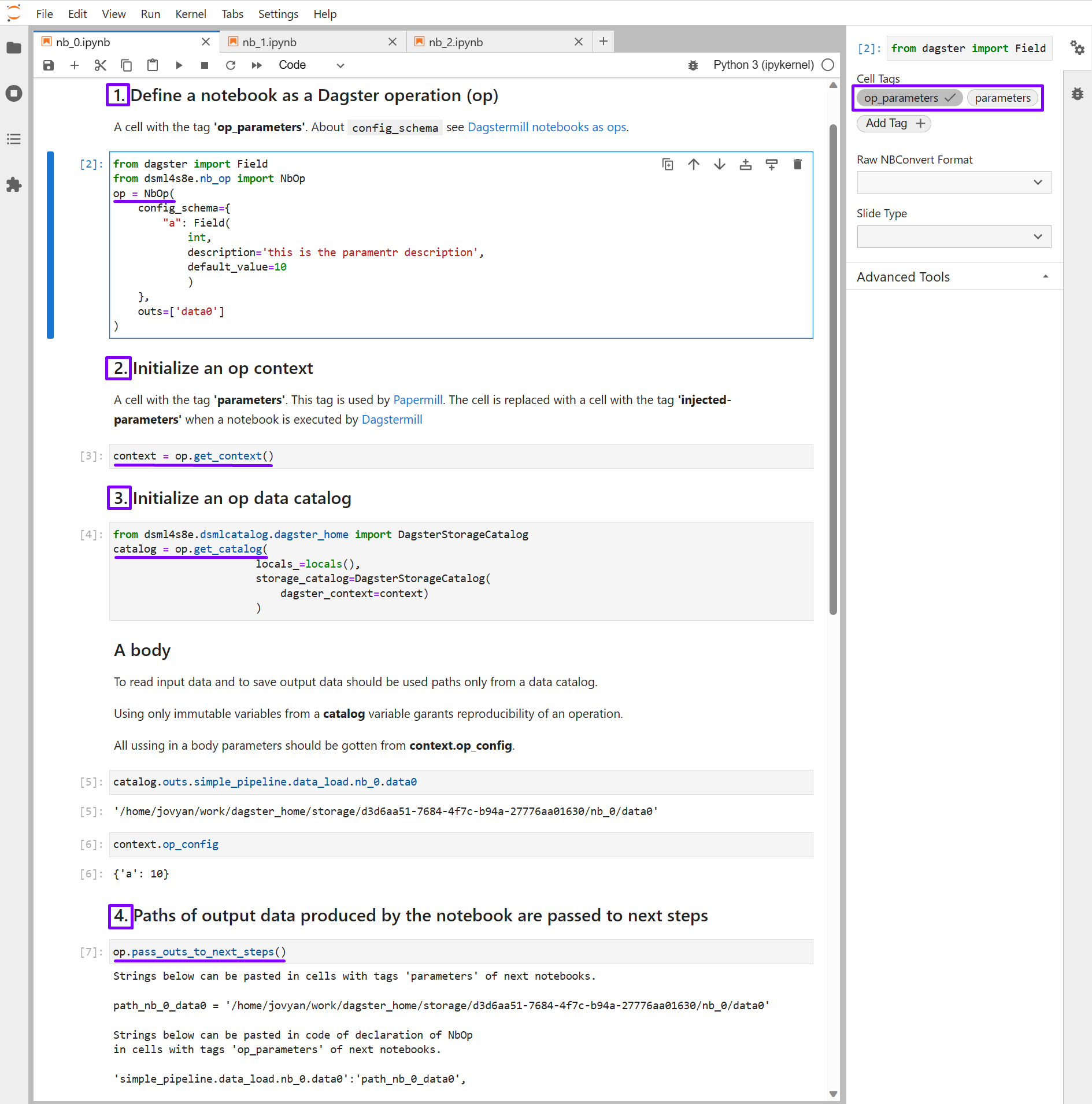
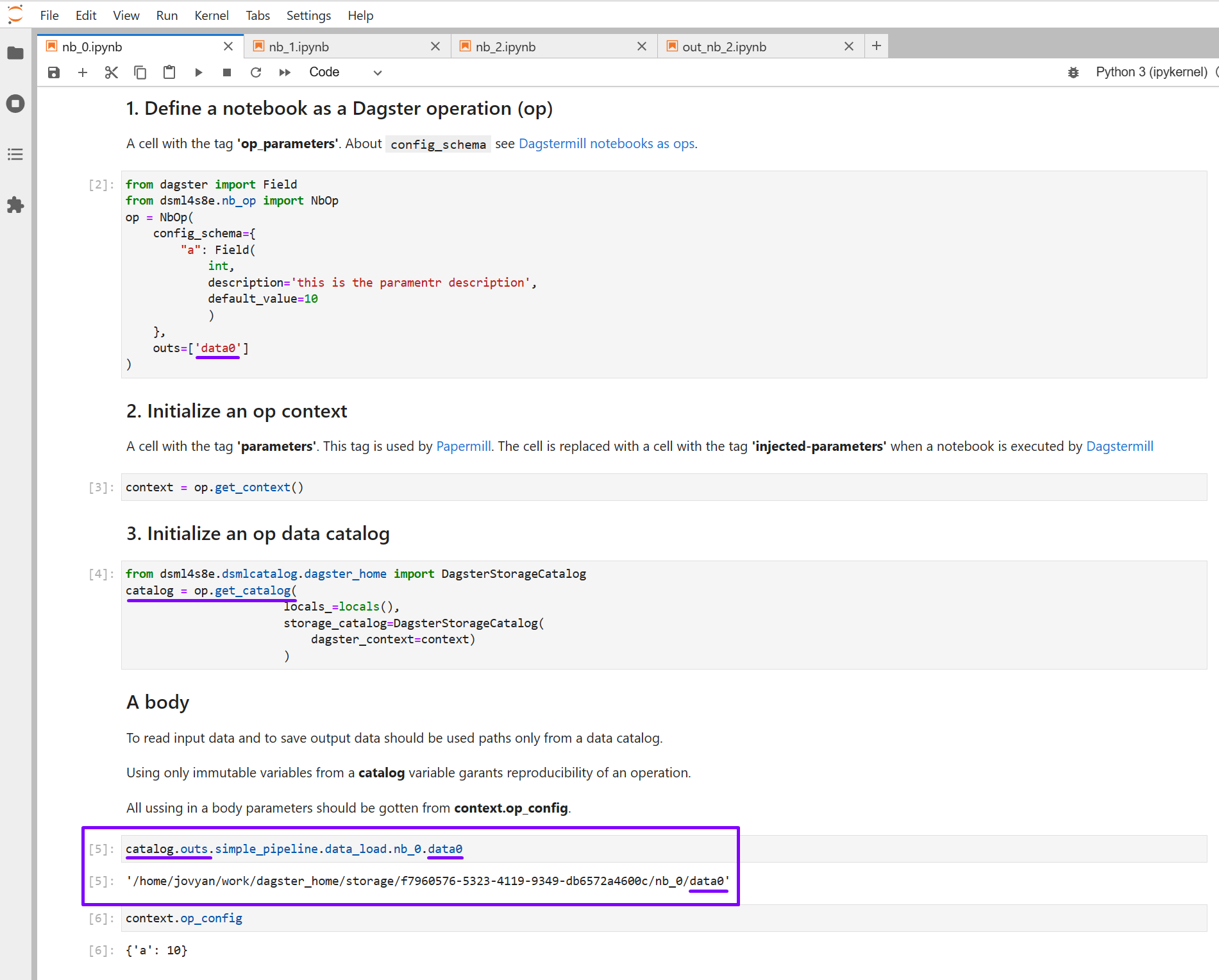
Cell 1: Op parameters defenition
In a cell with the tag op_parameters defines parameters which will be transformed and passed to define_dagstermill_op as arguments on a job definition stage.
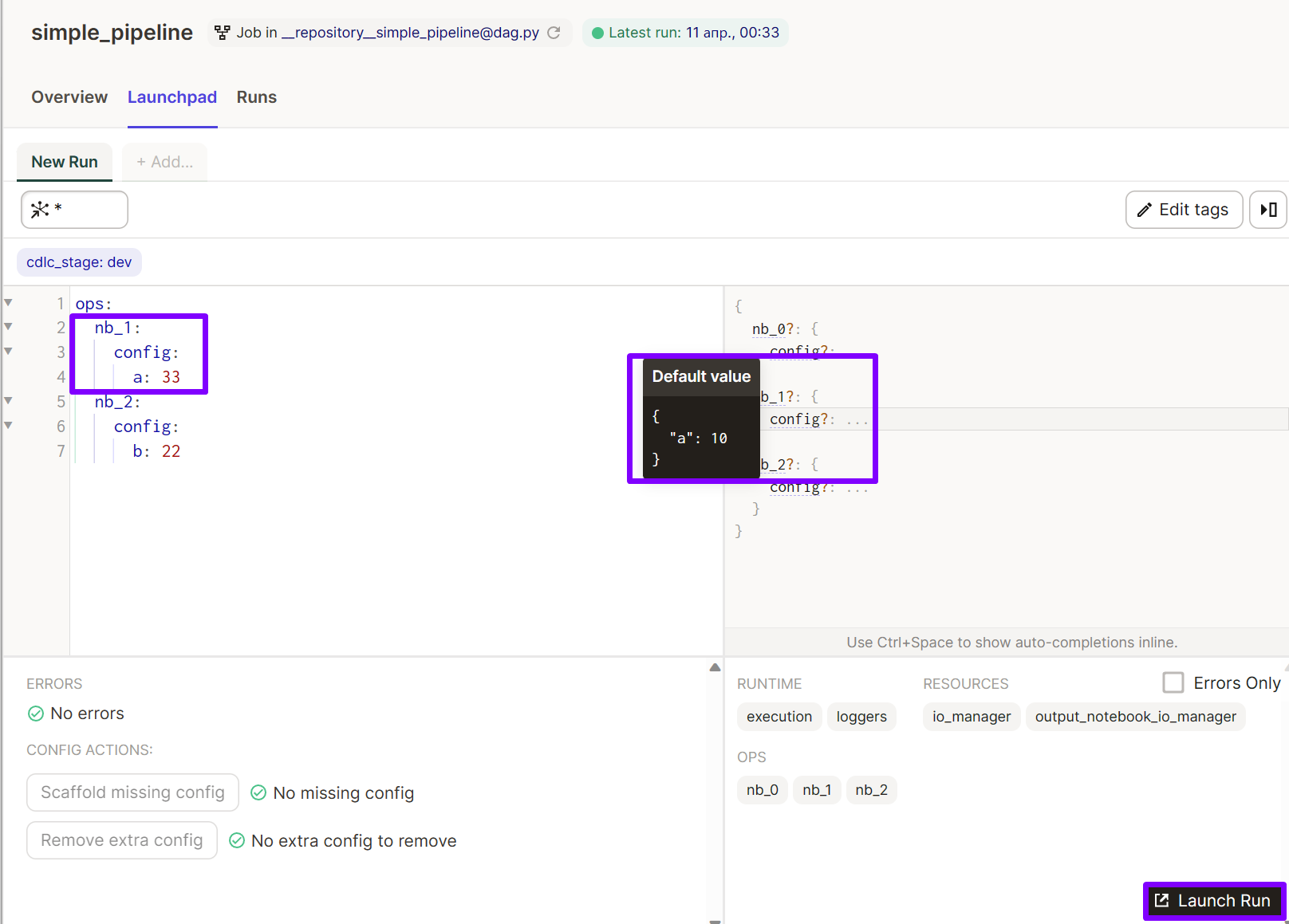
On the Dagster job definition stage this cell will be called and parametrs needed to define Op will be passed from the cell 'op' variabel to the function define_dagstermill_op from the dagstermill library. Then, these parameters will be avalible in Dagster Launchpad to edit run configuration in the launge stage.
A definition of a Dagster op in a standalone notebook in JupyterLab:
Configure op in Dagster Launchpad:
Cell 2: Op context initialization
Define variabel with 'contex' name in a cell wiht the tag parametrs.
A method get_context passes default values from config_schema in cell op_parameters to context variable.
context = op.get_context()
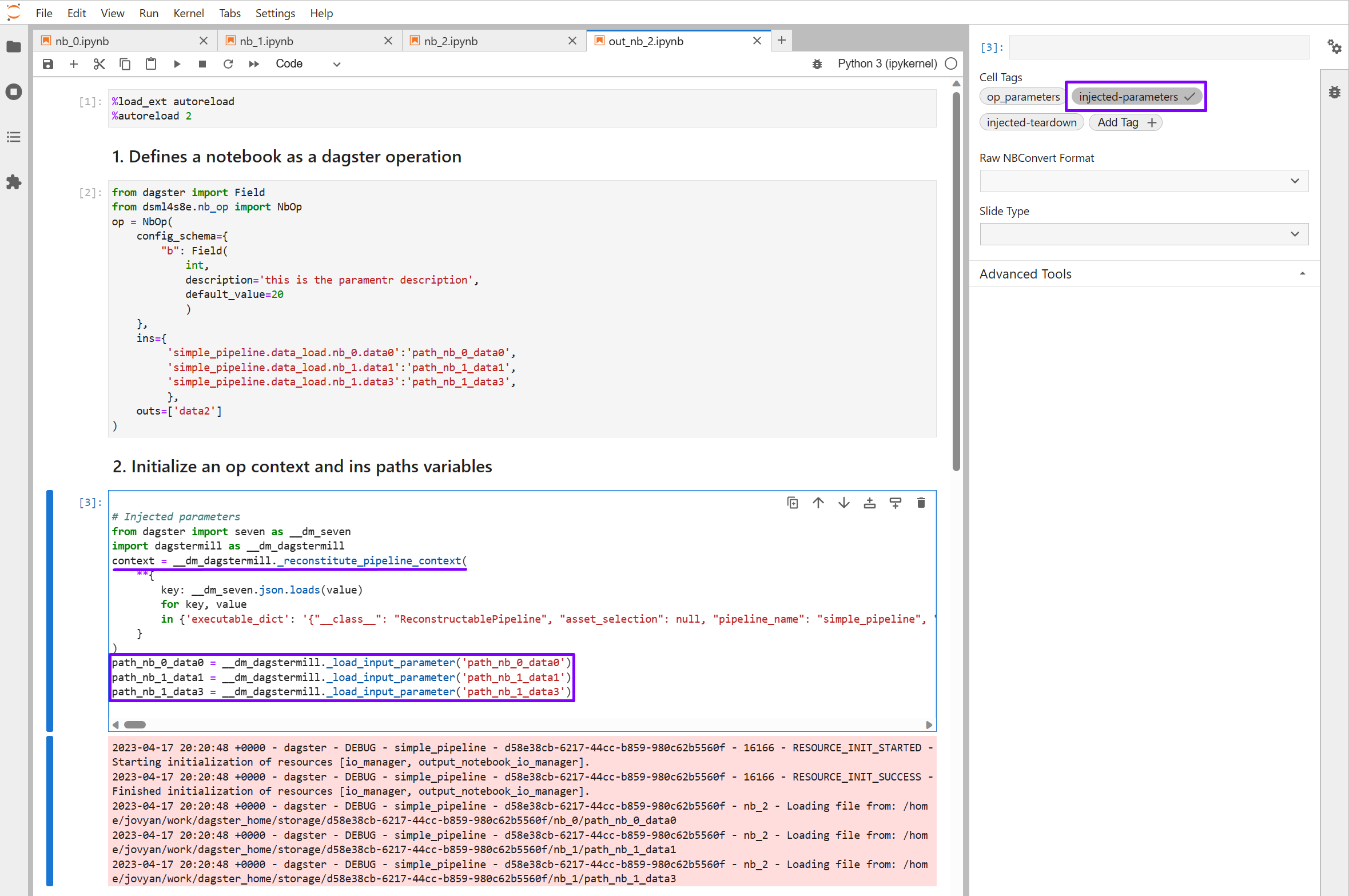
Now, if a notebook is executed by Dagster as an Op then it is replaced the parameters cell with the injected-parameters cell. Thus, the variable context can be used in the notebook body when the notebook is executed in standalone mode and when the notebook is executed as Dagster Op.
To be clear, let's look at one of the notebooks executed by Dagster:
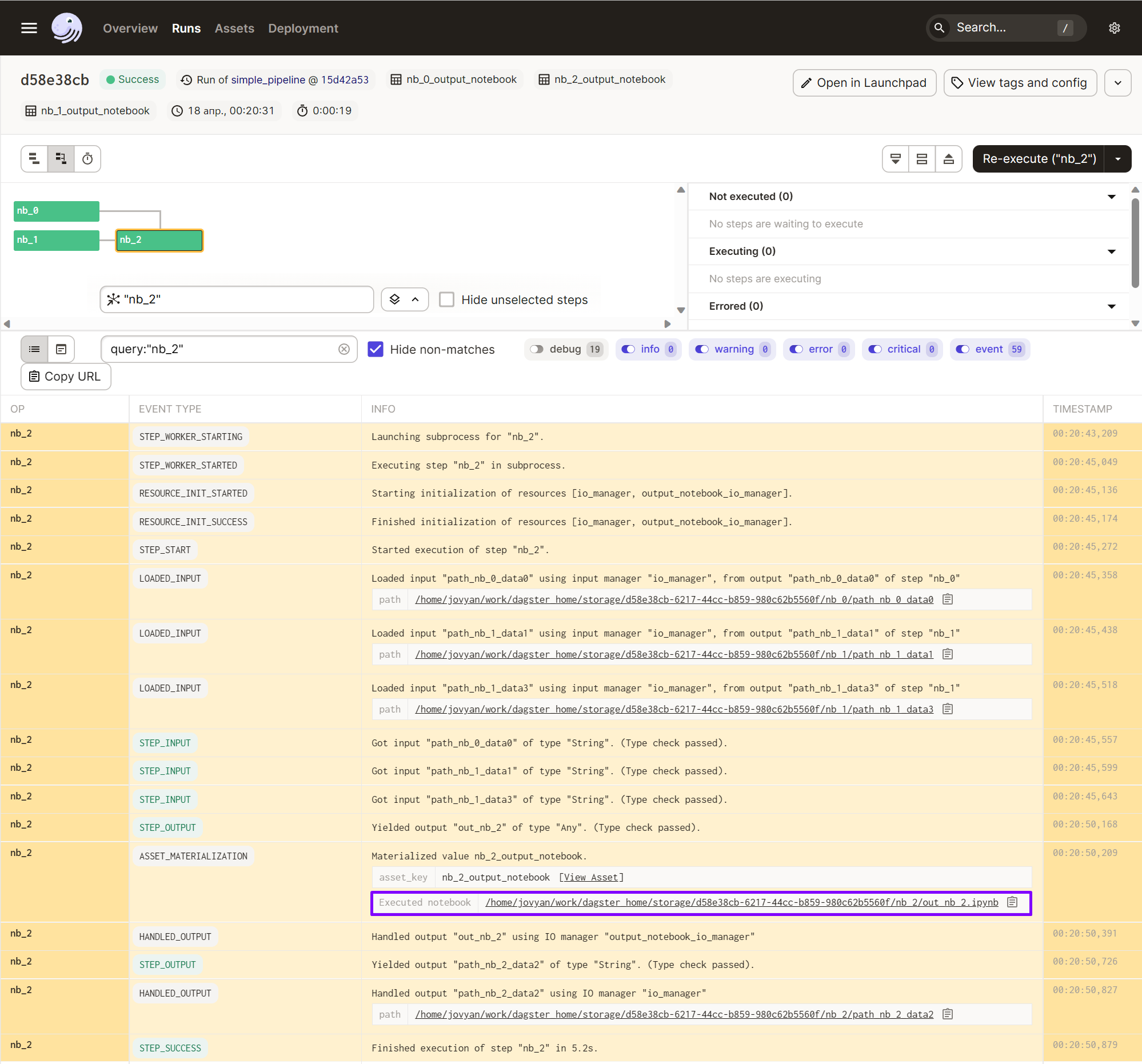
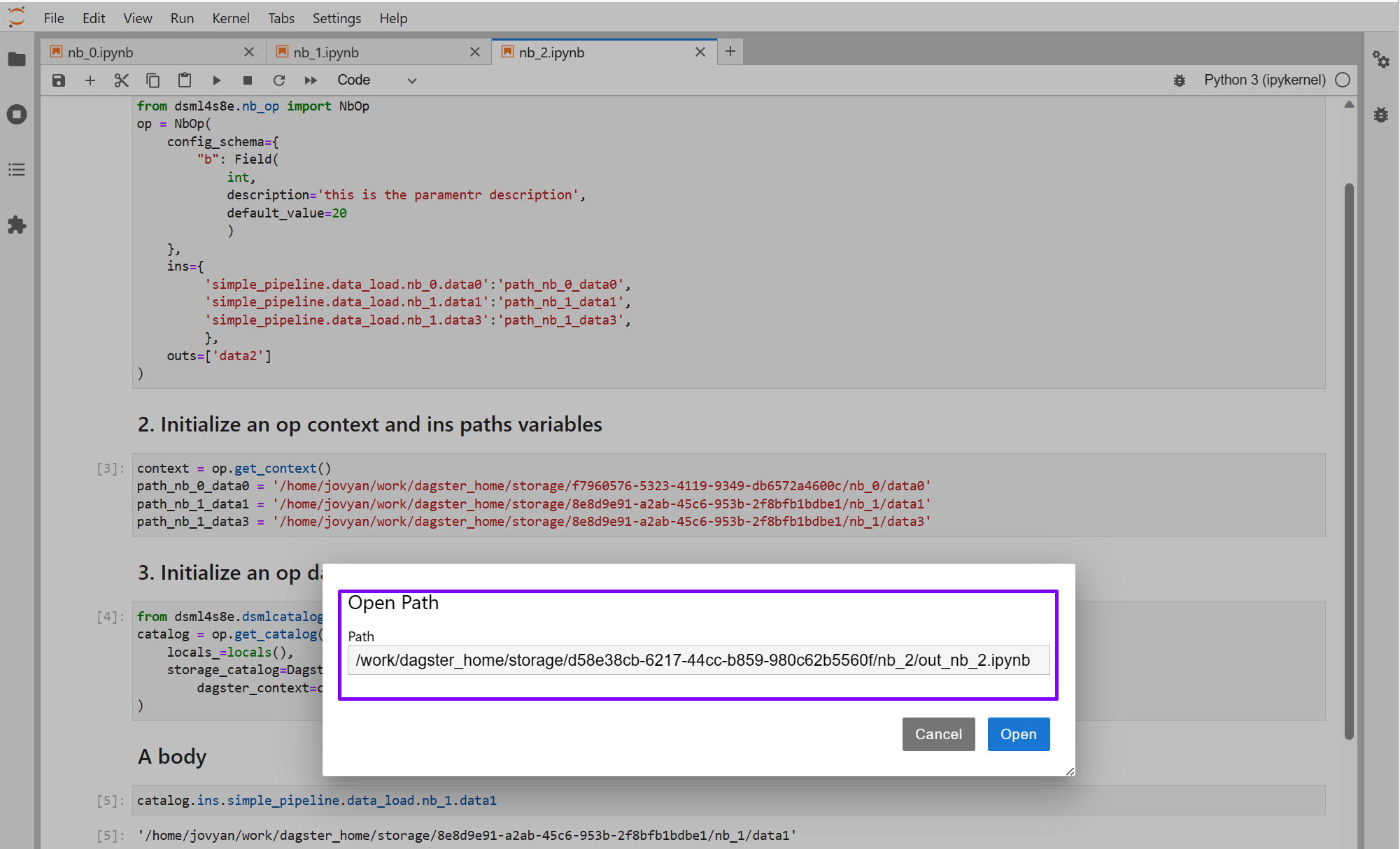
Notice that the injected-parameters cell in your output notebook defines a variable called context.
Cell 3: data catalog initialization
A data catalog is a set of paths. A catalog path is a unique name of a data entity in pipelines namespaces. Catalog paths are used for linking ops into pipeline.
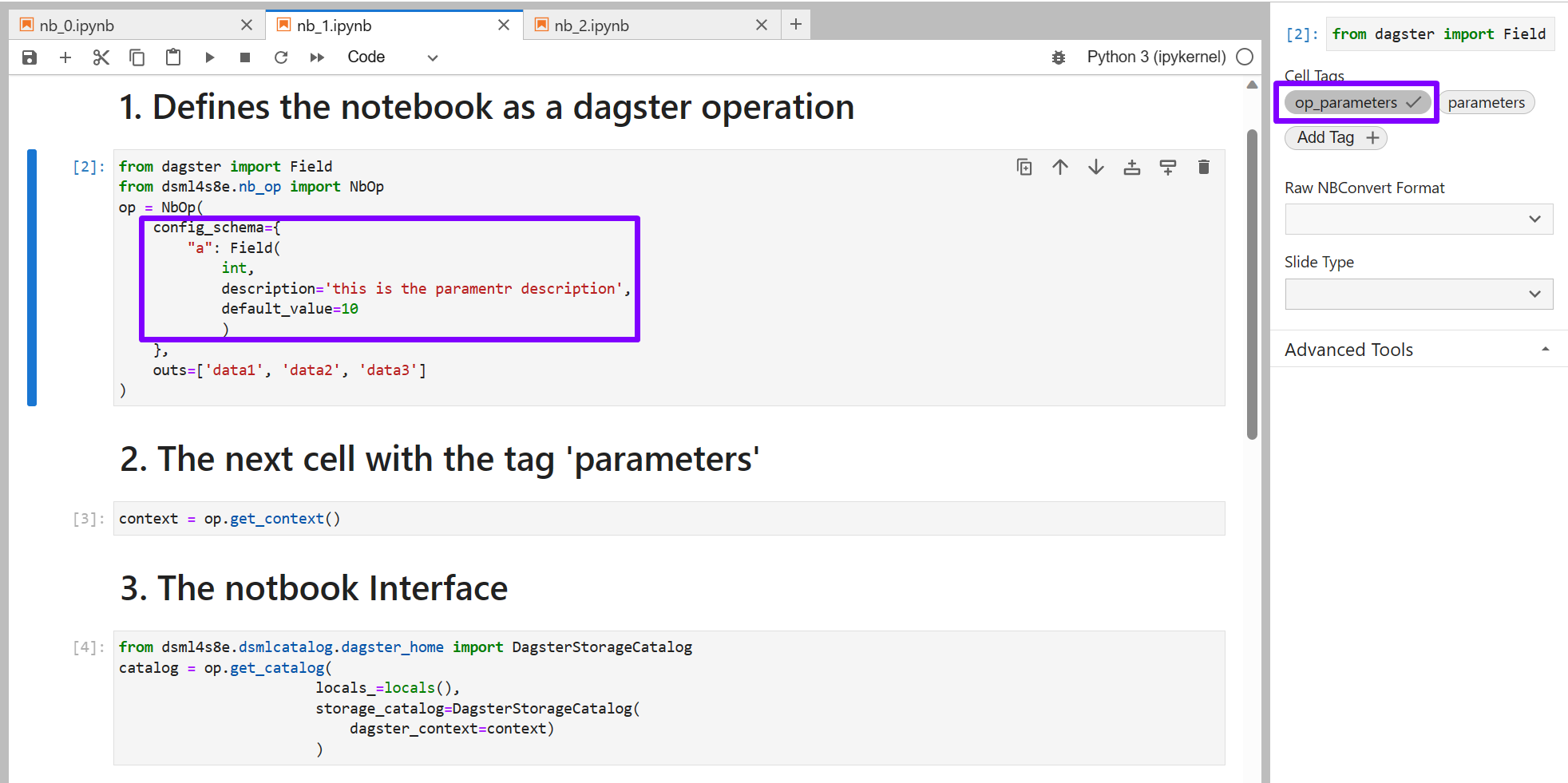
op = NbOp(
config_schema={
"b": Field(
int,
description='this is the paramentr description',
default_value=20
)
},
ins={
'simple_pipeline.data_load.nb_0.data0':'path_nb_0_data0',
'simple_pipeline.data_load.nb_1.data1':'path_nb_1_data1',
'simple_pipeline.data_load.nb_1.data3':'path_nb_1_data3',
},
outs=['data2']
)
In this code block, we use the ins argumet to link outputs produced by nb_0 and nb_1 with inputs of nb_2.
The keys if the ins dict are catalog paths. And the values are names of paths variables which are used in a notebook.
Catalog paths and paths variables names are generated automatically by the outs list, the class NbOp is responsible for generating.
A name of a path variable must be unique for each notebook namespace where the variable is used, thus a name of path variable could be shorter than the corresponding catalog path.
The method get_catalog() use 'DagsterStorageCatalog' derived from StorageCatalogABC to create paths in a file system (storage) catalog. Creating of file system paths for each the data entity name in outs list must be implemented in the method get_outs_data_paths.
class StorageCatalogABC(ABC):
@abstractmethod
def __init__(self, runid):
self.runid = runid
@abstractmethod
def is_valid(self) -> bool:
...
@abstractmethod
def get_outs_data_paths(
self,
catalog: DataCatalogPaths
) -> Dict[str, str]:
"""
A map of catalog paths to storage paths
"""
...
A catalog structure in file system is fully customizable using StorageCatalogABC.
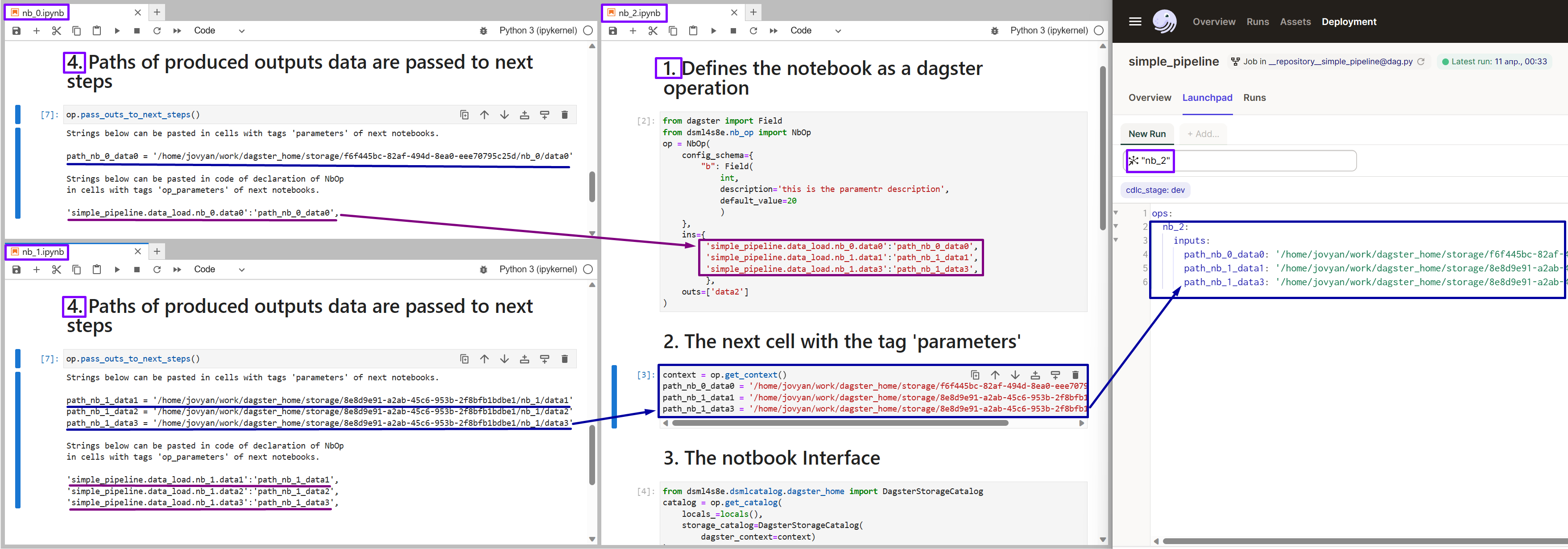
Cell 4: passing notebook outputs to next pipeline steps
In the last cell we inform next steps of the pipeline where data produced by the current notebook is stored. Now we can link this notebook(step) with the next notebooks representing pipeline steps. To do this we need to declare this notebook outputs as inputs for the next netbooks.
op.pass_outs_to_next_step()
Format of output message returning by pass_outs_to_next_step() allow as to copy strings from the cell output and paste them to NbOp declarations in the cells op_parametrs of the pipeline next steps notebooks.
Look at the illustration below:


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dsml4s8e-0.1.6.tar.gz.
File metadata
- Download URL: dsml4s8e-0.1.6.tar.gz
- Upload date:
- Size: 12.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.11.7 Linux/6.6.10-76060610-generic
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a2ed36158ba8d9d9e597e2232b13148e4615314416478dfc5905e45b9012bf9c
|
|
| MD5 |
7406fad1b17588ab0b5e79671e5a05f0
|
|
| BLAKE2b-256 |
176e3f2b7349a83e3203147c0114b8cf288e2884d64c2d2dcf607c8d63190d1b
|
File details
Details for the file dsml4s8e-0.1.6-py2.py3-none-any.whl.
File metadata
- Download URL: dsml4s8e-0.1.6-py2.py3-none-any.whl
- Upload date:
- Size: 12.4 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.11.7 Linux/6.6.10-76060610-generic
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
18274c3f554d8fc5ab88a3572dbbadbae40b12654785e78ae3d2bd6299cdf0bf
|
|
| MD5 |
f1275f735eb72220cd084e05af32cdd6
|
|
| BLAKE2b-256 |
a47f2bd9d9951e74f9a9796f824eb68847d73498a27bfbec90bcef0fb18e25de
|







