数据同步工具

Project description
DuckCP
同步数据的小工具,支持以下类型的数据源之间同步数据:
- PostgreSQL数据库:以及兼容的数据库。例如Hologres。
- MaxCompute数据库:即ODPS。
- SQLite数据库:文件型OLTP数据库。
- DuckDB数据库:文件型OLAP数据库。
- 本地文件:基于DuckDB实现,支持CSV、Parquet、JSON三种格式的读写。
- 飞书多维表格:基于DuckDB实现。多维表格被映射成DuckDB的只读View,可执行SQL查询。
一、功能简介
DuckCP按照以下步骤同步数据:
- 连接数据源,并执行SQL查询数据。
- 清空目标存储单元里的存量数据。
- 将查询结果批量保存到目标存储单元内。
二、安装与使用
- 安装方法:
pip install duckcp==0.1.2 - 使用方法:
duckcp -h
三、案例演示
假设在data目录下有一个programmers.csv文件,保存了每位程序员使用的编程语言。内容如下:
| id | name | language |
|---|---|---|
| 1 | Joe | Java |
| 2 | Alice | JavaScript |
| 3 | Leon | C/C++ |
| 4 | William | Java |
| 5 | James | C/C++ |
| 6 | Enson | C/C++ |
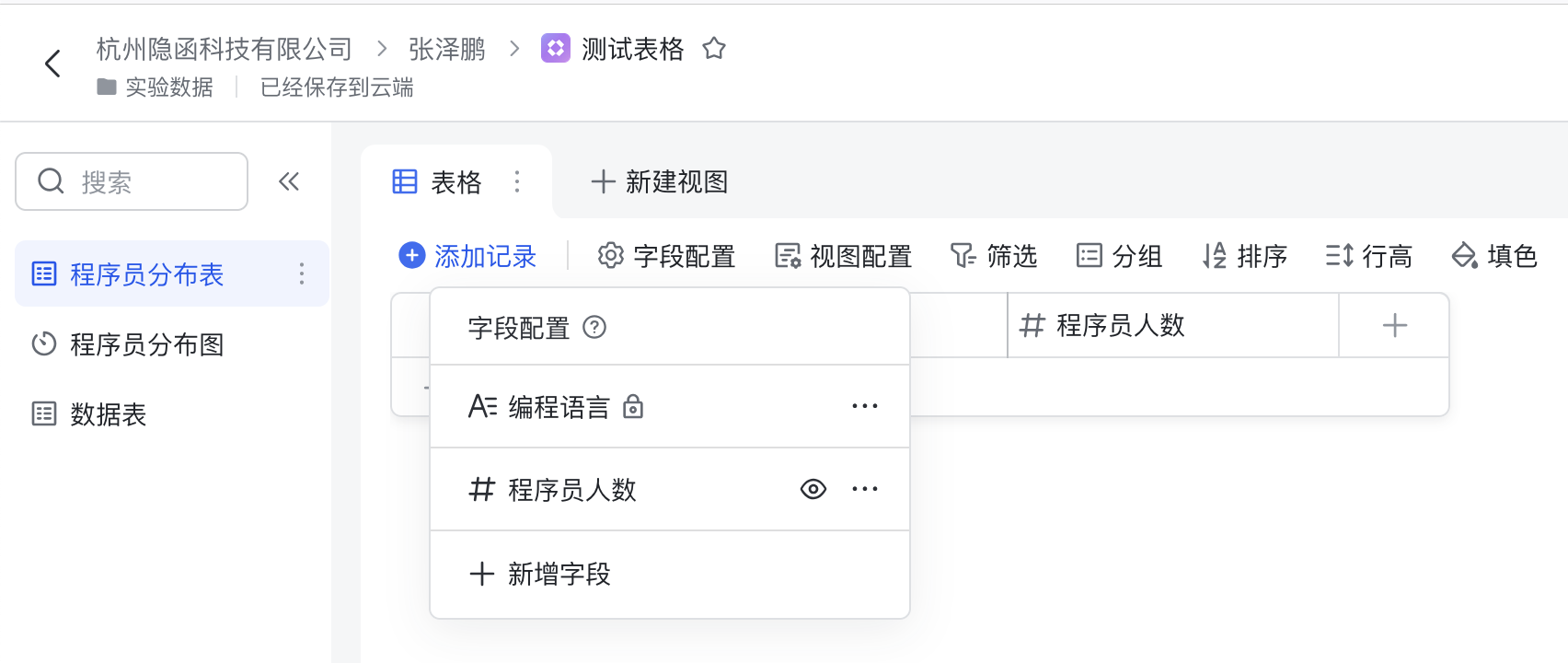
本案例将演示从上述CSV文件中读取数据,统计使用各种编程语言的程序员人数,并将统计结果保存到飞书多维表格中,表格包含以下两个字段:
- 编程语言:文本类型。
- 程序员人数:整数类型。
如下图所示:
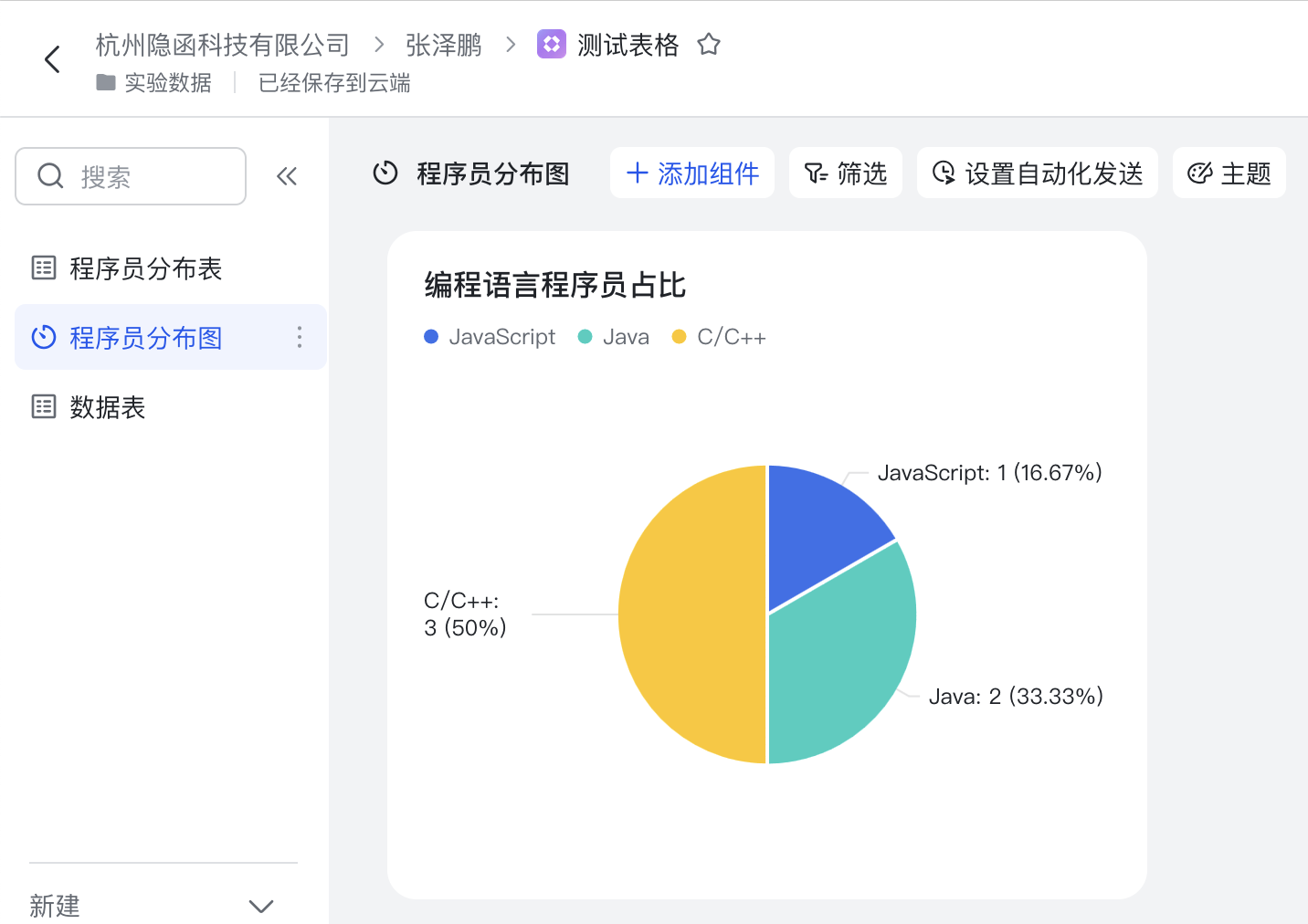
多维表格将自动基于统计结果绘制图表,如下图所示:
3.1 初始化
DuckCP在本地SQLite3数据库中管理以下元信息:
- 数据仓库(Repository):定义各类数据库的连接信息。
- 存储单元(Storage):定义数据仓库内的存储单元。例如数据库的表、目录下的文件等。
- 迁移任务(Transformer):定义来源仓库、目标仓库、迁移脚本(SQL)等迁移信息。
- 迁移作业(Task):定义可同时执行的迁移任务,及其执行顺序。
使用以下命令创建元信息数据库:
duckcp meta create
元信息数据库默认保存在以下路径:
- Linux系统:
$HOME/.config/com.yinfn.duckcp/configuration.db - macOS系统:
$HOME/Library/Application\ Support/com.yinfn.duckcp/configuration.db - Windows系统:
%LOCALAPPDATA%\com.yinfn.duckcp\configuration.db
可以通过全局选项-c/--config-file指定数据库文件路径:
duckcp -c <PATH> meta create
3.2 创建数据仓库
本案例中需要创建两个数据仓库:
- 文件类型(kind=
file)数据仓库:即前文中数据文件所在的目录data。取名为『文件仓库』。 - 多维表格(kind=
bitable)数据仓库:可管理多维表格的飞书开放平台应用。取名为『多维表格』。
命令如下:
duckcp repository create 文件仓库 -k file --folder data
duckcp repository create 多维表格 -k bitable --access-key <APP-ID> --access-secret <APP-SECRET>
其中文件类型(-k file)仓库的连接选项:
--folder <FOLDER>:CSV等数据文件所在的目录。本例中『FOLDER』为『data』。
多维表格类型(-k bitable)仓库的连接选项:
--access-key <APP-ID>:飞书开放平台中应用凭证的『App ID』。--access-secret <APP-SECRET>:飞书开放平台中应用凭证的『App Secret』。
飞书开放平台上创建应用并凭证的获取方式步骤如下:
- 进入飞书开发者后台页面。
- 点击『创建企业自建应用』按钮,填写信息并点击『创建』。
- 进入应用详情页面后,点击左侧『凭证与基础信息』菜单,可看到如下图所示的应用凭证。

不同类型的仓库连接选项不一样,细节请参见duckcp repository create -h。
3.3 创建存储单元
作为数据来源的『文件仓库』不需要创建存储单元;作为存储目标,数据仓库『多维表格』必须创建具体的『存储单元』,即目标最终保存在仓库的那张表或哪个文件内。
本例中,数据最终保存到多维表格『程序员分布表』数据表中。创建存储单元的方法如下:
duckcp storage create 程序员分布表 -r 多维表格 --document <DOCUMENT> --table <TABLE>
存储介质选项包括:
-r/--repository <REPOSITORY>:指定所属的数据仓库。本例中『REPOSITORY』为『多维表格』。--document <DOCUMENT>:飞书多维表格文档的编码。--table <TABLE>:飞书多维表格数据表的编码。
飞书多维表格文档与数据表的编码获取步骤如下:
- 进入飞书企业云盘产品页面。
- 点击『进入飞书』按钮。
- 点击『新建』-『多维表格』按钮。
- 此时会新的页面,其中URL类似:
https://yinfn-tech.feishu.cn/base/D3yhboIwZazNERsGfDscLt5onee?table=tblrfAQHyWUlNG1q&view=vewwQlhsgf
其中:
/base/之后的路径参数就是文档编码:即D3yhboIwZazNERsGfDscLt5onee。- 查询参数
table的值就是数据表编码,即tblrfAQHyWUlNG1q。。
注意:请填写您自己创建的多维表格文档的编码;并且按照以下步骤为多维表格文档添加文档应用:
- 点击右上角『...』按钮。
- 进入『... 更多』菜单。
- 点击『添加文档应用』。
- 在添加出的『文档应用』窗口中搜索上面创建的企业应用名称,并为其添加『可编辑』权限。如下图所示:

3.4 创建迁移
创建迁移之前,首先需要创建一个SQL迁移脚本。在本例中我在data目录下创建了一个迁移脚本.sql文件,内容如下:
select
"language" as "编程语言",
count(*) as "程序员人数"
from
read_csv('programmers.csv')
group by
"language"
order by
"程序员人数" desc
DuckCP的文件类型仓库本质上是一个临时的DuckDB数据库,因此读取CSV使用DuckDB内置的read_csv函数。
接着可以创建迁移,指定从文件数据源中用迁移脚本读取数据,并保存至多维表格的数据表中。方法如下:
duckcp transformer create 数据统计 -s 文件仓库 -t 多维表格 -o 程序员分布表 -f data/迁移脚本.sql
其中选项包括:
-s/--source REPOSITORY:指定来源数据仓库。本例中『REPOSITORY』为『文件仓库』。-t/--target REPOSITORY:指定目标数据仓库。本例中『REPOSITORY』为『多维表格』。-o/--storage STORAGE:指定目标存储单元。本例中『STORAGE』为『多维表格』的『程序员分布表』。-f/--script FILE:指定迁移脚本,用于从来源数据仓库内读取数据和加工数据。本例中『FILE』为『data/迁移脚本.sql』。
3.5 执行迁移
最后,可以执行前文创建的迁移。方法如下:
duckcp transformer execute 数据统计
问题反馈
DuckCP在2023年9月开始在公司内部使用,前后重写超过6次,近期(2025年6月)才开始筹备开源。 代码难免有错误和不足,欢迎在Github上提交问题,或发邮件至 redraiment@gmail.com 交流。
感谢!


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file duckcp-0.1.2.tar.gz.
File metadata
- Download URL: duckcp-0.1.2.tar.gz
- Upload date:
- Size: 32.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4152068c2c1c341ff400218964d5fd39343c82038246b917489a0c803897a2df
|
|
| MD5 |
cde9096a3cee6002ca23da172e7cac3a
|
|
| BLAKE2b-256 |
5a4e1824533689741519e524227393d1fcae50a002164283586ac1615cef19bd
|
File details
Details for the file duckcp-0.1.2-py3-none-any.whl.
File metadata
- Download URL: duckcp-0.1.2-py3-none-any.whl
- Upload date:
- Size: 63.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2998a18afdb0017a2f7b4d4c04c41da7e6025838b88e51b374881c7ce2ceb124
|
|
| MD5 |
6b8fbc5478eefe96efdb9a14aeb794ed
|
|
| BLAKE2b-256 |
385687d580619ca3fd6573daa29a9f5a91d25fe9716b379ae333e01fb4491ee2
|







