PyTorch DataLoader with dynamic batch sizing guided by a pre-trained GPU memory regressor.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
dynabatch




Use more of your GPU on variable-length text generation.
Long inputs force small safe batches. Later, shorter inputs could often fit more examples, but most loaders keep using the same conservative batch size. dynabatch grows those later batches automatically.

dynabatch is a drop-in PyTorch batch sampler for variable-length text workloads. It starts with max-token-style length sorting, then uses a pre-trained regressor to increase batch size on easier, shorter batches while keeping predicted memory pressure below the first, hardest batch.
Quick Start
Install:
pip install dynabatch
Use it as a DataLoader batch sampler. Omit batch_size from DataLoader; the sampler controls batch sizes.
from datasets import Dataset
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
from dynabatch import dynabatch_sampler
texts = [
"Very Short text " * 1,
"Short text " * 2,
"Medium text " * 8,
"Long text " * 32,
"Very long text " * 64,
] * 3
dataset = Dataset.from_dict({"text": texts})
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-small")
def collate_fn(batch):
batch_texts = [x["text"] for x in batch]
return tokenizer(batch_texts, padding=True, truncation=True, return_tensors="pt")
sampler = dynabatch_sampler(texts, tokenizer, batch_size=3, max_input_token_length=128, keep_batch_size_even=False)
loader = DataLoader(dataset, batch_sampler=sampler, collate_fn=collate_fn)
for i, batch in enumerate(loader):
print(f"Batch No: {i} | Batch size: {len(batch['input_ids'])}")
Or use build_dynabatch_dataloader(texts, tokenizer, batch_size=1, max_input_token_length=64) for a built-in loader.
Results
These are workload-specific results, not a universal speedup claim. dynabatch helps most when variable sequence lengths leave memory headroom unused.
| Workload | Hardware | Baseline | dynabatch | Notebook | Notes |
|---|---|---|---|---|---|
Inference generate() |
Colab T4 | max-token sampler | 1.06×-1.21× | inference Colab | Smaller gain: T4 has less compute headroom, so larger batches help less |
| Seq2Seq training | RTX 5090 | fixed batch | 3.3× | training notebook | Larger gain: the 5090 has much more compute headroom, so growing shorter batches improves utilization |
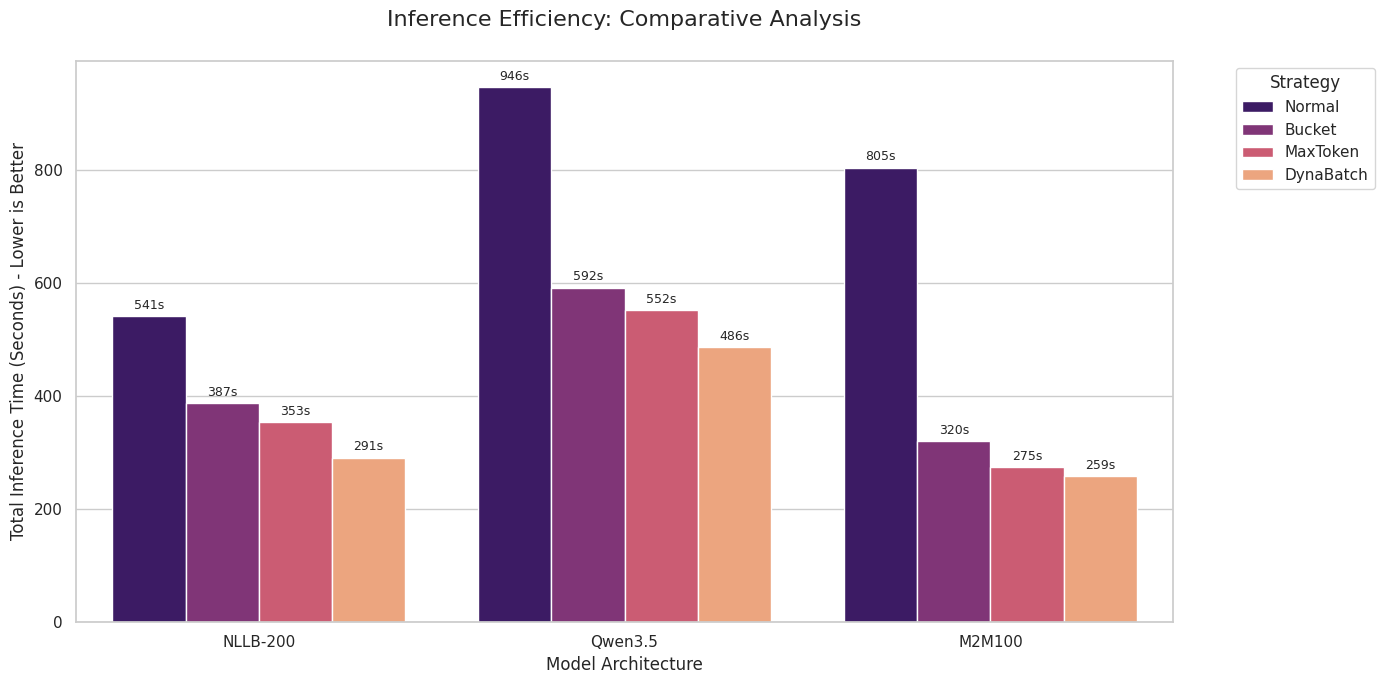

Should You Use It?
Use dynabatch if:
- you run encoder-decoder generation or training, especially translation-style workloads
- input lengths vary a lot
- a few long examples force a small safe batch size
- shorter examples later in the dataset leave GPU memory or compute underused
Probably skip it if:
- you are using decoder-only LLMs where sequence packing is the better first optimization
- your workload is already compute-bound at the smallest safe batch size
- input length is a poor proxy for generation cost
To sanity-check your workload, compare dynamic_batch_mode=True against dynamic_batch_mode=False. If both behave similarly, batching is probably not your bottleneck.
Tuning For More Throughput
Start with the largest batch_size that safely fits your longest inputs. That first hard batch becomes the baseline budget; the dynamic settings control how aggressively later, shorter batches can grow.
| Parameter | Current | Increase or change it when | Risk OOM |
|---|---|---|---|
max_batch_range |
2.0 | Shorter examples could fit much larger batches than your baseline. | Can pick overly aggressive batch sizes if set too high. |
threshold |
0.9 | You want dynabatch to accept batches closer to the first-batch memory budget. | Higher OOM risk if the regressor underestimates memory. |
Also check nvidia-smi if more batches could fit in.
➕ More Examples
Compare dynamic vs static batching
from torch.utils.data import DataLoader
from dynabatch import dynabatch_sampler
kw = dict(texts=texts, tokenizer=tokenizer, batch_size=32, max_input_token_length=256)
dynamic = DataLoader(
dataset,
batch_sampler=dynabatch_sampler(**kw, dynamic_batch_mode=True),
collate_fn=collate_fn,
)
static = DataLoader(
dataset,
batch_sampler=dynabatch_sampler(**kw, dynamic_batch_mode=False),
collate_fn=collate_fn,
)
dynamic_batch_mode=False behaves like Max Token Sampler/Batching without the regressor-driven dynamic resizing. In other words, dynabatch is:
- Max Token Sampler/Batching
- plus optional dynamic batch growth on top
That makes dynamic_batch_mode=False useful as a sanity check.
OOM-safe generation with fallback splitting
The regressor is empirical, so it can still occasionally predict a batch size that turns out too aggressive for a specific model, prompt template, GPU state, or generation setting. generate_with_oom_fallback() lets you keep the run alive by splitting only the failed batch into smaller chunks.
import torch
from torch.utils.data import DataLoader
from dynabatch import dynabatch_sampler, generate_with_oom_fallback
loader = DataLoader(
dataset,
batch_sampler=dynabatch_sampler(texts, tokenizer, batch_size=32, max_input_token_length=256),
collate_fn=collate_fn,
)
device = torch.device("cuda")
with torch.inference_mode():
for batch in loader:
generated_tokens, did_fallback = generate_with_oom_fallback(
model, batch, min_batch_size=32, device=device, max_new_tokens=128,
)
if did_fallback:
print("Fallback path used for this batch after an OOM.")
This is useful when you want throughput from dynamic batching without letting one occasional OOM kill a long inference run.
Training-style usage
For training:
- if you want hardware friendly sizes (
2^nor3 * 2^n), enablefriendly_batch_size=True - if you want to avoid odd batch sizes, keep
keep_batch_size_even=True(default) - if you want shuffled batches, set
shuffle=True shuffle_keep_first_n=3means the first 3 hardest batches stay unshuffled and only the later batches are shuffled- keeping the earliest hardest batches fixed is useful because it lets you hit the worst memory cases early and find OOM problems sooner
from torch.utils.data import DataLoader
from dynabatch import dynabatch_sampler
train_loader = DataLoader(
dataset,
batch_sampler=dynabatch_sampler(
texts,
tokenizer,
batch_size=16,
max_input_token_length=256,
friendly_batch_size=True,
shuffle=True,
shuffle_keep_first_n=3,
),
collate_fn=collate_fn,
)
Hugging Face Trainer integration (plug-and-play)
If you train with Hugging Face Trainer, use the trainer helpers so you do not have to manually inject:
get_train_dataloader()override forbatch_samplercompute_loss()reweighting for variable micro-batch sizes under gradient accumulation
from transformers import Seq2SeqTrainer # Seq2SeqTrainer as
from dynabatch import (
dynabatch_sampler,
make_dynabatch_trainer,
MemoryCleanupCallback,
)
sampler = dynabatch_sampler(
texts=train_texts,
tokenizer=tokenizer,
batch_size=8,
max_input_token_length=512,
shuffle=True,
)
DynabatchSeq2SeqTrainer = make_dynabatch_trainer(Seq2SeqTrainer)
trainer = DynabatchSeq2SeqTrainer(
dynabatch_sampler=sampler,
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
callbacks=[MemoryCleanupCallback()],
)
When this is a good fit:
- You use a Hugging Face trainer class and want dynamic batching without custom trainer boilerplate.
gradient_accumulation_steps > 1and micro-batch sizes vary by step.- You want fairer baseline-vs-dynabatch comparisons where fewer dynabatch steps can otherwise change the effective LR schedule.
Why loss reweighting exists:
- With variable micro-batch sizes, a plain accumulated loss can bias optimizer updates toward steps with smaller/larger batch sizes.
- Dynabatch rescales each micro-batch by
current_batch_size / per_device_train_batch_sizeso contribution is closer to sample-count-weighted behavior.
When to enable LR auto-scaling (Off by default):
- You are comparing against an older fixed-batch trainer/collator setup and want similar effective optimization signal per epoch.
- DynaBatch significantly reduces steps-per-epoch and you want a linear-scaling-style correction.
trainer = DynabatchSeq2SeqTrainer(..., auto_scale_lr=True)
Power-user options:
- Use
DynabatchTrainerMixindirectly if you need custom multiple inheritance:class MyTrainer(DynabatchTrainerMixin, Seq2SeqTrainer): ... - Use
scale_lr_for_dynabatch(args, sampler, dataset_size)as a standalone helper if you want explicit LR control outside trainer construction. - For non-text modalities, set
batch_size_key=...(for example"pixel_values") so batch-size extraction incompute_loss()reads the right tensor.
OOM fallback options:
oom_fallback="split_retry": ontorch.cuda.OutOfMemoryErrorduringtraining_step, retry the same step in smaller chunks and keep as many samples as possible.oom_fallback="skip": clear memory and skip the failing step by returning a zero loss.oom_fallback=None: (default) disable fallback and re-raise OOM immediately.oom_min_batch_size: chunk size used by split-retry. If unset, the trainer usesdynabatch_sampler.min_batch_size.- Every handled OOM increments an
oom_failedcounter and logs it viaTrainer.log(...), so it appears in Trainer/TQDM progress metrics.
trainer = DynabatchSeq2SeqTrainer(
...,
oom_fallback="split_retry", # "split_retry" | "skip" | None
oom_min_batch_size=2,
)
API
dynabatch_sampler
Returns a DynaBatchSampler for DataLoader(..., batch_sampler=sampler). The dataset indices must match texts.
dynabatch_sampler(
texts: list[str],
tokenizer: PreTrainedTokenizerBase,
batch_size: int,
max_input_token_length: int = 512,
**kwargs,
) -> DynaBatchSampler
build_dynabatch_dataloader
Same batching as dynabatch_sampler, but returns a DataLoader with built-in tokenizer collation.
build_dynabatch_dataloader(
texts: list[str],
tokenizer: PreTrainedTokenizerBase,
batch_size: int,
max_input_token_length: int = 512,
**tokenizer_kwargs,
) -> DataLoader
Common options:
| Option | Why you might change it |
|---|---|
batch_size |
Set this to the largest safe batch size for your longest inputs. |
threshold |
Lower it for more conservative dynamic growth; 1.0 means roughly as memory-heavy as the first batch. |
max_batch_range |
Caps how much larger later batches can get relative to batch_size. |
dynamic_batch_mode |
Turn off to compare against max-token batching without regressor-driven resizing. |
shuffle / shuffle_keep_first_n |
Shuffle built batches while keeping the first hardest batches fixed for early OOM detection. |
friendly_batch_size |
Round chosen batch sizes to hardware-friendly values like powers of two. |
token_lengths, word_lengths, char_lengths |
Provide precomputed lengths to skip the upfront length pass. |
Trainer helpers
make_dynabatch_trainer(trainer_cls: type) -> type
scale_lr_for_dynabatch(
args: Any,
sampler: DynaBatchSampler,
dataset_size: int,
baseline_batch_size: int | None = None,
) -> Any
class DynabatchTrainerMixin
make_dynabatch_trainer: builds a cached subclass combiningDynabatchTrainerMixinwith your trainer class.DynabatchTrainerMixin: overrides train dataloader + loss reweighting for variable micro-batch sizes, and adds optional OOM fallback intraining_step.scale_lr_for_dynabatch: standalone helper mainly for fair fixed-vs-dynabatch comparisons; keep it off for normal training unless you explicitly want step-count-based LR adjustment.
How It Works
- All texts are tokenized up front to estimate truncated token, word, and character lengths.
- Samples are sorted by token length from longest to shortest. This part alone is essentially Max Token Sampler/Batching.
- The first batch uses exactly
batch_sizeitems. This is the hardest batch and becomes the baseline. - For every later batch, dynabatch builds candidate batch sizes from
batch_sizeup tobatch_size * max_batch_range. - A pre-trained
XGBRegressorpredicts memory pressure for each candidate relative to the first batch. - dynabatch chooses the largest candidate whose predicted load is less than or equal to
threshold. - If
dynamic_batch_mode=False, step 5 and step 6 are skipped and the pipeline reduces to Max Token Sampler/Batching with fixed batch size.
The important intuition is:
- around
1.0means "about as memory heavy as the first batch" - below
1.0means lighter than the first batch - above
1.0means heavier than the first batch and therefore riskier
So you should choose batch_size as the largest batch of your longest inputs that safely fits on your GPU. The regressor then tries to grow from there when the later inputs get shorter.
Regressor Training
The detailed training pipeline and notebook notes live in train_regressor/readme.md. That document explains how the GPU-memory data is generated, how the XGBRegressor training rows are built, and the current caveat that new v2-style generation is NLLB-only for now; existing v1 ALMA/Marian data is still usable but not fully reproducible from the current notebook config.
In short:
- the training data stores real GPU memory usage from many batch configurations
- the target is memory usage relative to the first batch
- the notebook trains an
XGBRegressorto predict that ratio from token, word, and character statistics of the baseline batch and candidate batch
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file dynabatch-0.2.23.tar.gz.
File metadata
- Download URL: dynabatch-0.2.23.tar.gz
- Upload date:
- Size: 11.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4615c1bc89a49be024521814a046845cc4e2d21f5c576d95195eed6e8428f702
|
|
| MD5 |
b3a2e9f9f3b175c750a616967a2c72d6
|
|
| BLAKE2b-256 |
6f7f6bda9593ad5ecaccd77655263963016a95617f8ff27e49def67955fbbfef
|
Provenance
The following attestation bundles were made for dynabatch-0.2.23.tar.gz:
Publisher:
pypi.yml on bendangnuksung/dynabatch
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dynabatch-0.2.23.tar.gz -
Subject digest:
4615c1bc89a49be024521814a046845cc4e2d21f5c576d95195eed6e8428f702 - Sigstore transparency entry: 1395869117
- Sigstore integration time:
-
Permalink:
bendangnuksung/dynabatch@ccc587bb30c1234d62ab7e41bfb3108c6cef48f4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/bendangnuksung
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi.yml@ccc587bb30c1234d62ab7e41bfb3108c6cef48f4 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file dynabatch-0.2.23-py3-none-any.whl.
File metadata
- Download URL: dynabatch-0.2.23-py3-none-any.whl
- Upload date:
- Size: 11.7 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c4f030d50d0e25d593a55f8e5d257f044293ac75425e70947a44235095093f24
|
|
| MD5 |
73a7896a9e6bf9607a2ef9941c890905
|
|
| BLAKE2b-256 |
99f27697245ec89ce9369b86b1b0d07b6063da166180814ad2c5e45f819d55f8
|
Provenance
The following attestation bundles were made for dynabatch-0.2.23-py3-none-any.whl:
Publisher:
pypi.yml on bendangnuksung/dynabatch
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
dynabatch-0.2.23-py3-none-any.whl -
Subject digest:
c4f030d50d0e25d593a55f8e5d257f044293ac75425e70947a44235095093f24 - Sigstore transparency entry: 1395869140
- Sigstore integration time:
-
Permalink:
bendangnuksung/dynabatch@ccc587bb30c1234d62ab7e41bfb3108c6cef48f4 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/bendangnuksung
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi.yml@ccc587bb30c1234d62ab7e41bfb3108c6cef48f4 -
Trigger Event:
workflow_dispatch
-
Statement type:







