Easy creation of your own simple neural network

Project description
HOW TO DOWNLOAD
pip install easymyai
DOCUMENTATION
SimpleMyAI is a small library for creating your own simple AI. I wrote it entirely from scratch, using only numpy, and I only took basic principles of operation from the internet. I also added a lot of comments to the code, so that you can understand how everything works here and dig into the code yourself (you might even learn something new).
How to use my library:
In short:
from simplemyai import AI_ensemble, AI
# Create AI
ai = AI(architecture=[10, 50, 50, 1],
add_bias=True,
name="First_AI")
# Or you can create an ensemble
ai = AI_ensemble(amount_ais=10, architecture=[10, 50, 50, 1],
add_bias_neuron=True,
name="First_AI")
# Residual learning (transferring the gradient from 3 layers of weights and 2)
ai.make_short_ways((2, 3))
# Set coefficients
ai.alpha = 1e-3 # Learning rate
ai.batch_size = 10 # Batch size
# For Adam optimizer
ai.impulse1 = 0.9 # Usually between 0.8 and 0.999
ai.impulse2 = 0.999 # Slightly different from beta1
# Regularization
ai.l1 = 0.0 # L1 regularization
ai.l2 = 0.0 # L2 regularization
ai.what_act_func = ai.kit_act_func.tanh
ai.end_act_func = ai.kit_act_func.tanh
ai.save_dir = "Saves AIs" # The directory where we save the AIs
# Train (for example, image recognition)
for image in dataset:
data = image.tolist()
answer = [image.what_num]
ai.learning(data, answer, squared_error=True)
# There is also Q-learning (see update table functions below)
actions = ("left", "right", "up", "down")
ai.make_all_for_q_learning(actions, ai.kit_upd_q_table.standart,
gamma=0.5, epsilon=0.01, q_alpha=0.1)
state, reward = game.get_state_and_reward()
ai.q_learning(state, reward,
learning_method=2.5,
squared_error=False,
use_Adam=True,
recce_mode=False)
Details:
You can copy the package "easymyai" to your project (everything else is just examples of usage) and import AI or AI_ensemble classes from there
How to initialize AI:
from simplemyai import AI_ensemble, AI
ai = AI()
# Or
ensemble = AI_ensemble(5) # 5 is the number of AIs in the ensemble
An ensemble is several AI in one box that make a decision together and due to this, the probability of accidental error is greatly reduced (an ensemble is well suited for Q—learning (this is reinforcement learning; when there is no "right" and "wrong" answer, but only a reward for some chosen action))
P.S. As an example, take a look at the AI for Snake (in the file "AI for snake.py")
- To create an architecture:
ai = AI(architecture=[3, 4, 4, 4, 3],
add_bias_neuron=True,
name="First_AI")
# If using an ensemble
ensemble = AI_ensemble(5, architecture=[3, 4, 4, 4, 3],
add_bias_neuron=True,
name="First_AI")
or
ai = AI()
ai.create_weights([3, 4, 4, 4, 3], add_bias=True)
ai.name = "First_AI"
# Name is not mandatory, but if not provided,
# a random number will be used instead of the name
This will create the following architecture:
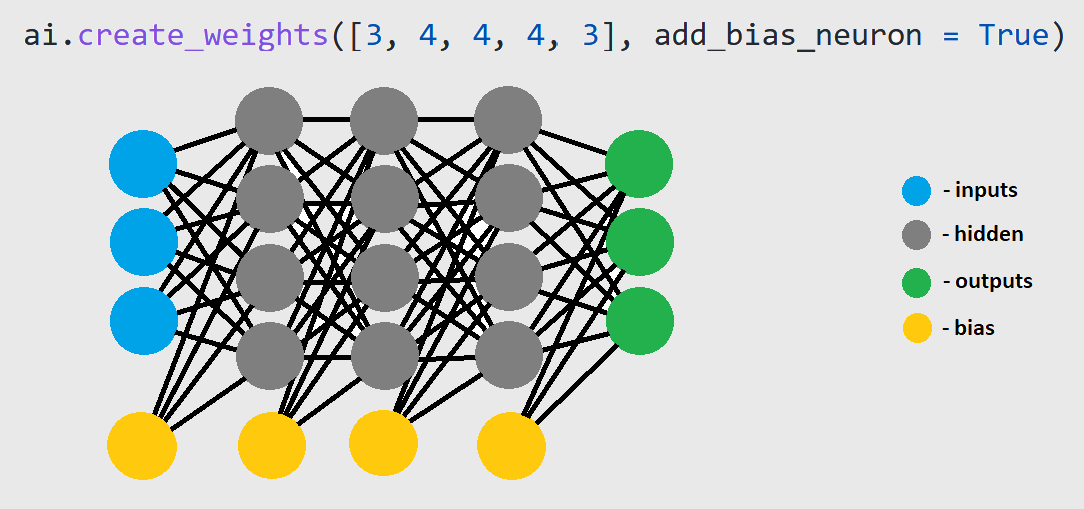
- Hyperparameters:
"""It's not necessary to specify or modify all hyperparameters."""
ai.alpha = 1e-2 # Learning rate
ai.disabled_neurons = 0.0 # Proportion of neurons to disable
# (This is to prevent overfitting)
ai.batch_size = 10 # Number of answers to average for learning
# (Speeds up learning, but in some tasks it is better not to use)
# Neuron activation function (highly recommended to leave tanh if
# possible, as AI works much faster with it)
ai.what_act_func = ai.kit_act_func.tanh
# Activation function for the last layer (similarly, recommended to leave tanh)
# P.s. end_act_func can also be absent (i.e., None can be set)
ai.end_act_func = ai.kit_act_func.tanh
# Impulse coefficients for the Adam optimizer
ai.impulse1 = 0.9
ai.impulse2 = 0.999
# If you don't know what an optimizer is, google it, it's very interesting))))
# Coefficients for weight regularization
# (Regularization - keeping weights close to 0 (or [-1; +1]))
ai.l1 = 0.001 # How much to decrease weights (it makes weights tend towards 0)
ai.l2 = 0.01 # How much to decrease weights (keeps weights close to 0)
- Training:
# Just pass a list of numbers as input and output to the neural network
data = [0, 1, 2] # Input data
answer = [0, 1, 0] # Output data
ai.learning(data, answer,
squared_error=True)
"""
Squared error allows faster learning from big mistakes
and overlooks small imperfections (but sometimes it's better to disable it)
"""
Q-learning:
Q-learning is when there is no "correct" or "incorrect" answer, only reward for some chosen action, i.e., how good it is
(0 = neutral choice, <0 = bad choice, >0 = good choice)
# The AI can only choose a specific action among the possible ones
all_possible_actions = ["left", "right", "up", "down"]
gamma = 0.4 # "Experience trust" coefficient (for "smoothing" the Q-table)
epsilon = 0.05 # Fraction of random actions (to make the AI explore the environment)
q_alpha = 0.1 # Q-table update rate (in reality, it doesn't affect much)
ai.make_all_for_q_learning(all_possible_actions,
ai.kit_upd_q_table.standart,
gamma=gamma, epsilon=epsilon, q_alpha=q_alpha)
# Update table functions have a significant impact on learning
# Similar to ordinary learning, we pass a list of numbers as input (state)
ai_state = [0, 1] # For example, neural network coordinates
ai.q_learning(ai_state, reward_for_state, learning_method=1,
recce_mode=False, squared_error=True)
# The decision made by the AI for certain data (return the name of the action)
predict = ai.q_predict(ai_state)
recce_mode: "Explore the environment" mode (constantly choose random action)
rounding: How much do we round off the state for the Q-table (this is necessary in order to classify (group) some period of data and train AI to make a specific choice on this data grapple, and it was possible to train on fractional data)
rounding=0.1: 0.333333333 -> '0.3'; rounding=10: 123,456 -> 120
Learning methods (value of learning_method determines):
- 1: "Correct" answer is chosen as the one with the maximum reward, and a maximum value of the activation function is placed in the position of the action (leading to the best answer), and a minimum activation function is placed in the other positions P.s. This is not very good because it ignores other options that bring either the same or slightly less reward (and only one "correct" option is selected). BUT IT WORKS WELL, WHEN YOU HAVE ONLY 1 CORRECT ANSWER IN THE TASK, AND THERE CANNOT BE "MORE" AND "LESS" CORRECT ONES
- 2: Make answers with higher rewards more "correct". The fractional part of the number indicates to what power we should raise the "striving for better results" (FOR EXAMPLE: 2.3 means that we use learning method 2 and raise "striving for better results" to the power of 3 (2.345 means the power will be 3.45))
- And of course, saving and loading the NN
ai.save() # Save under the current name
ai.save("First_AI") # Save with the name "First_AI"
ai.load("123") # Load the NN with name "123" from derictory for saves
You can also choose your own directory for saving AIs (why? I don't know)
# Everything will be saved in the "SAVES" directory next to the "My_AI" package
ai.save_dir = "SAVES"
- Just for fun, I also added genetic training
This is when the weights of the AIs are shuffled
# Here we shuffle the weights of ai_0 with ai_1, and leave ai_1 untouched
better_ai_0.genetic_crossing_with(better_ai_1)
- In addition to the genetic algorithm, I created the ability to create mutations
We replace a certain proportion of weights with random numbers from -1 to 1
ai.make_mutations(0.05) # 5% of weights are replaced with random numbers
- You can also pass data to the output neurons and get it back from the input (Why? I don't know, but it can be semi-interesting)
temp_data = ai.predict(data, reverse=True)
new_data = ai.predict(temp_data)
# new_data == data
- By the way, I highly recommend scaling input numbers to the range from -1 to 1 (or from 0 to 1)
It's just easier for the AI to work with numbers from -1 to 1 (or from 0 to 1) than with large, unclear values
# It's easier to use normalize, but you can also use tanh (or sigmoid)
ai.kit_act_funcs.normalize(data, 0, 1)
Good luck catching bugs


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file easymyai-6.0.tar.gz.
File metadata
- Download URL: easymyai-6.0.tar.gz
- Upload date:
- Size: 26.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2676fff107065c50870ed8ba77e0d5f985285d068cd257e51c6f820dd912150b
|
|
| MD5 |
07a847ff3c20989d1c3051b8bdb1389d
|
|
| BLAKE2b-256 |
baae3e698d991fb823dbc1ccdebf60aa30c1b71eae331544179d7c7f8544c110
|







