Easy to use text extractor, from PDF, DOC, DOCX and other document types, using the awesome Textract, including if necessary using OCR (via Tesseract).

Project description



Easy to use text extractor, from PDF, DOC, DOCX and other documents, including if necessary using OCR (via Tesseract).
This library can extract text from any type supported by Textract.
This library only exists because of the awesome work of the Textract team and Tesseract.
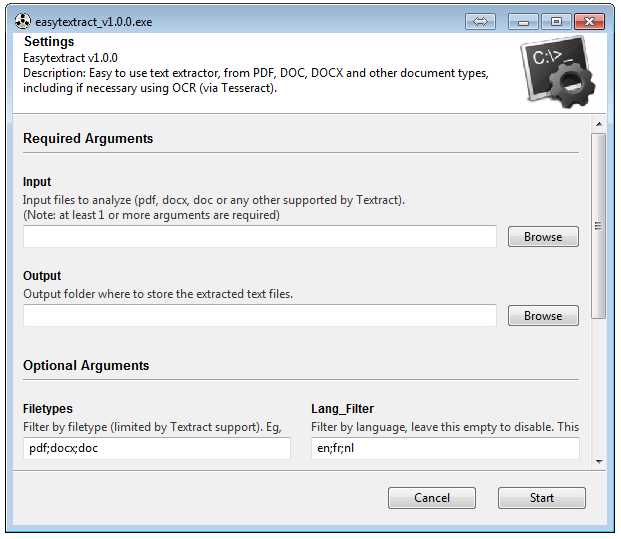
It runs under Python 2.7 (it was not tested nor developped with compatibility with Python 3 in mind, although it might work with some slight changes).
INSTALL
In general, please refer to Textract documentation to install the appropriate softwares needed to extract text from the filetypes you need.
The rest of this section will describe the details for a basic setup.
PYTHON (all platforms: Linux, MacOSX, Windows)
To run Easytextract from Python, you need Python > 2.7 and to pip install textract.
Then install the following libraries to support the filetypes you want:
For PDF, pip install PDFMiner. To get additional features and better PDF extraction, you can install pdftotext, part of poppler or Xpdf.
For OCR, you need to install Tesseract >= 3.02 (but not 3.0 nor 4!) and pdftoppm.
For DOCX, pip install python-docx2txt.
For DOC, install antiword in the location on Windows: C:antiwordantiword.exe , for Linux and Mac you will need to change the path inside the script.
to support other types such as audio, see https://textract.readthedocs.io/en/stable/#currently-supporting
WINDOWS
By using the Windows binary (only for Windows 64-bits), PDF and DOCX are directly supported.
To enable OCR, and install tesseract >= v3.02 (not v4!) for your platform beforehand. You also need to install pdftoppm.exe.
For DOC support (not DOCX as it is already supported natively), you will also need antiword installed in C:antiwordantiword.exe.
LICENSE
easytextract was initially made by Stephen Larroque <LRQ3000> for the Coma Science Group - GIGA Consciousness - CHU de Liege, Belgium. The application is licensed under MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file easytextract-1.1.5.tar.gz.
File metadata
- Download URL: easytextract-1.1.5.tar.gz
- Upload date:
- Size: 2.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d94f74ba1f1db653d05c70097be43dea016184ef747144522b9d4c5682c9c9f2
|
|
| MD5 |
a6936691da3cb9b8d1b9b8607a69561e
|
|
| BLAKE2b-256 |
fb254417e03841cbc0fa4c716a2677ed64004dded0860df5487af2e1b36060be
|







