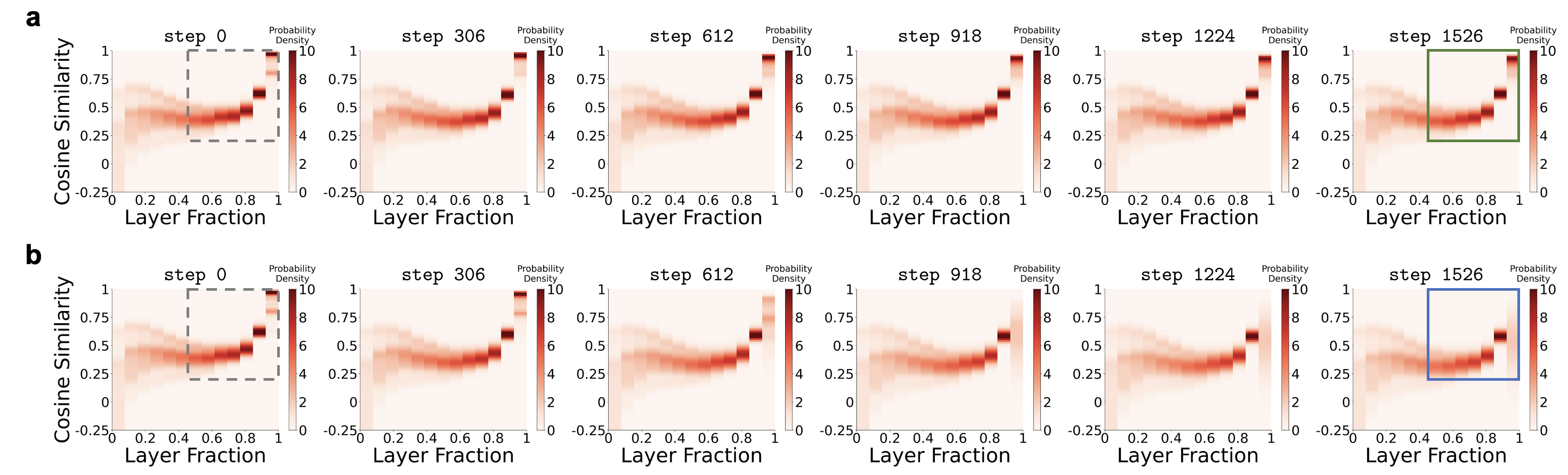
Measure layer-wise token embedding cosine similarity, assessing the severity of embedding condensation. Concept from [ICML 2026] Dispersion loss counteracts embedding condensation and improves generalization in small language models.

Project description
LM-Dispersion



















This is the author's repository for the ICML 2026 paper
Dispersion loss counteracts embedding condensation and improves generalization in small language models.
The official version is hosted at the Lab GitHub repo.
You are encouraged to read the illustrated walkthrough of the paper on the project website.
A 5-minute intro to this paper
This paper presents an observation-driven improvement on language model training.
We observe a geometric phenomenon which we term embedding condensation, where token embeddings collapse into a narrow cone-like subspace in smaller language models. We then design a training objective called dispersion loss to counteract the effect.

Feature 1: Larger model, less condensation.
Within the same model family, smaller models exhibit more severe embedding condensation, with token embeddings collapsing toward near-parallel directions, while larger models resist this collapse.
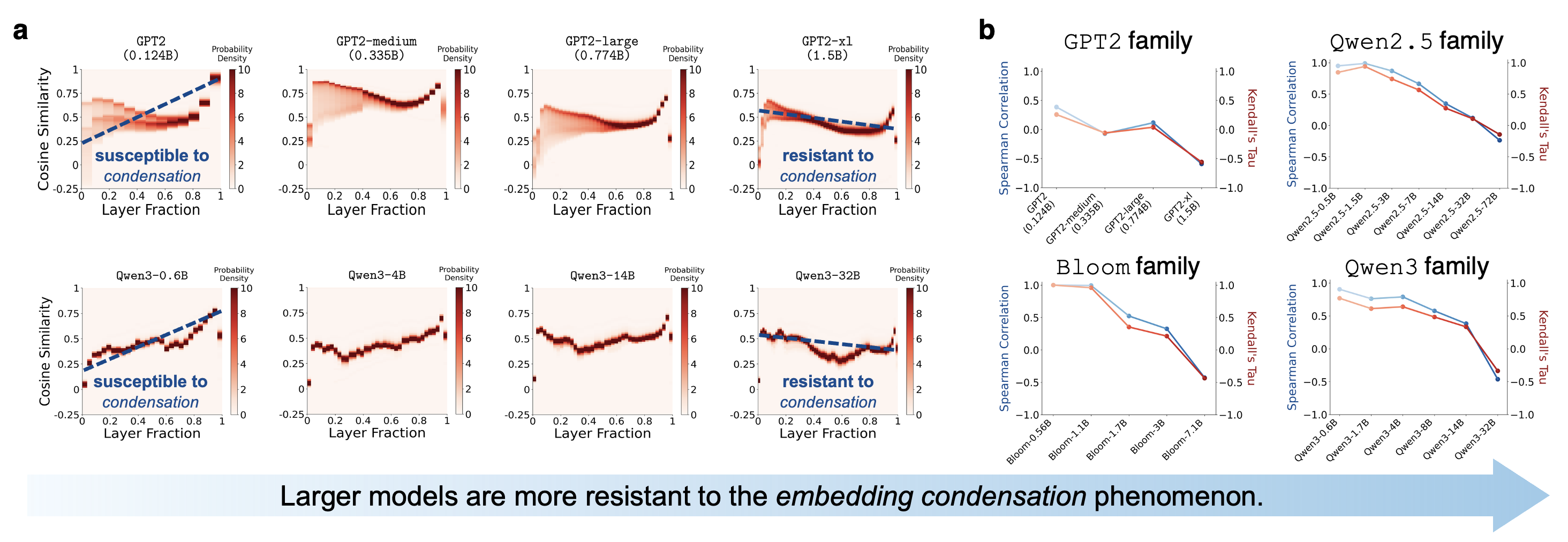
This effect is also quite robust to the choice of input datasets.
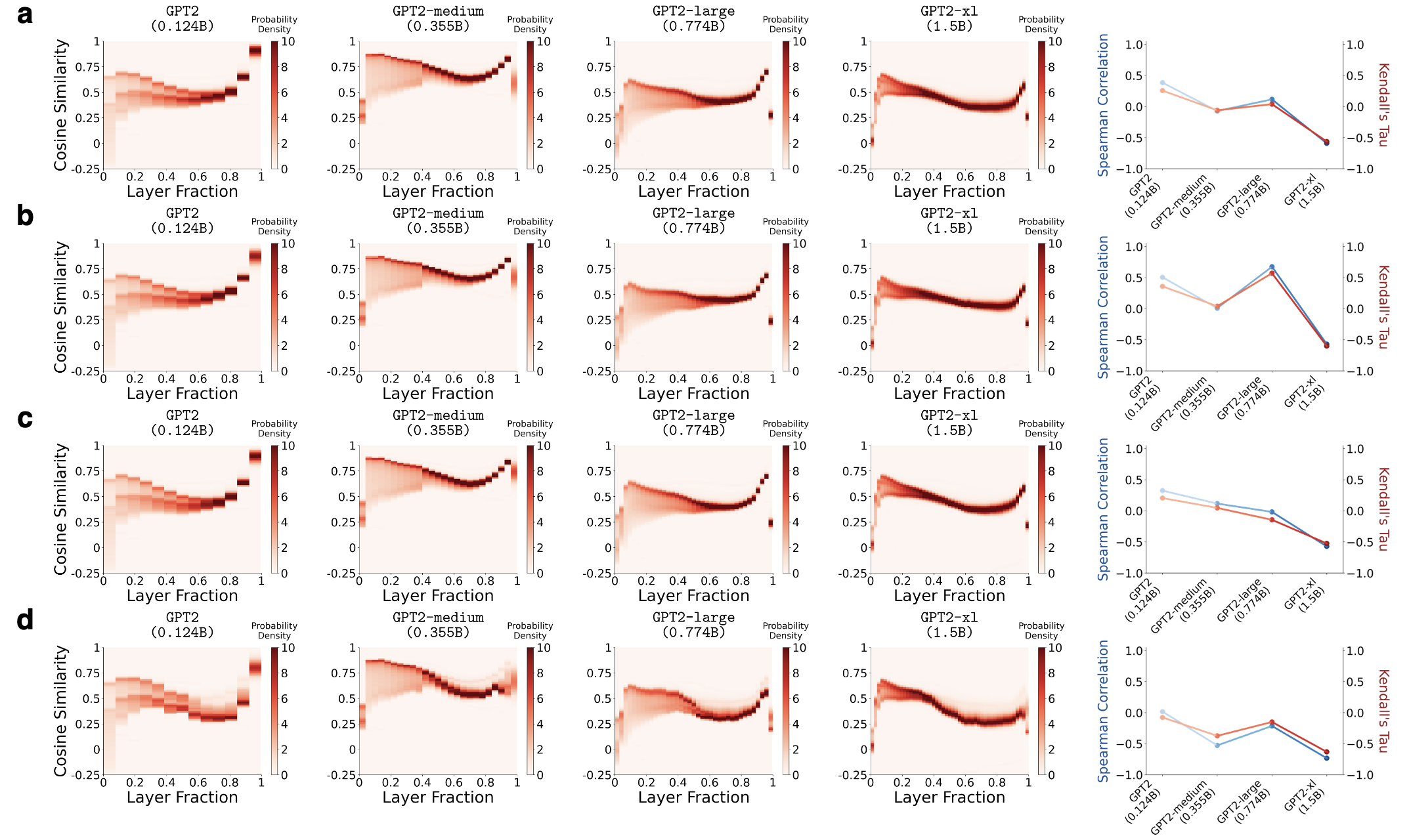
Feature 2: Reproducible when controlling for confounders.
To isolate the effect of model size from other confounding factors, we conduct a controlled experiment where we pre-train GPT2-like models, varying only the MLP dimension while keeping all other components fixed, including the number of layers, embedding dimension, dataset, and training settings. The same phenomenon is observed.

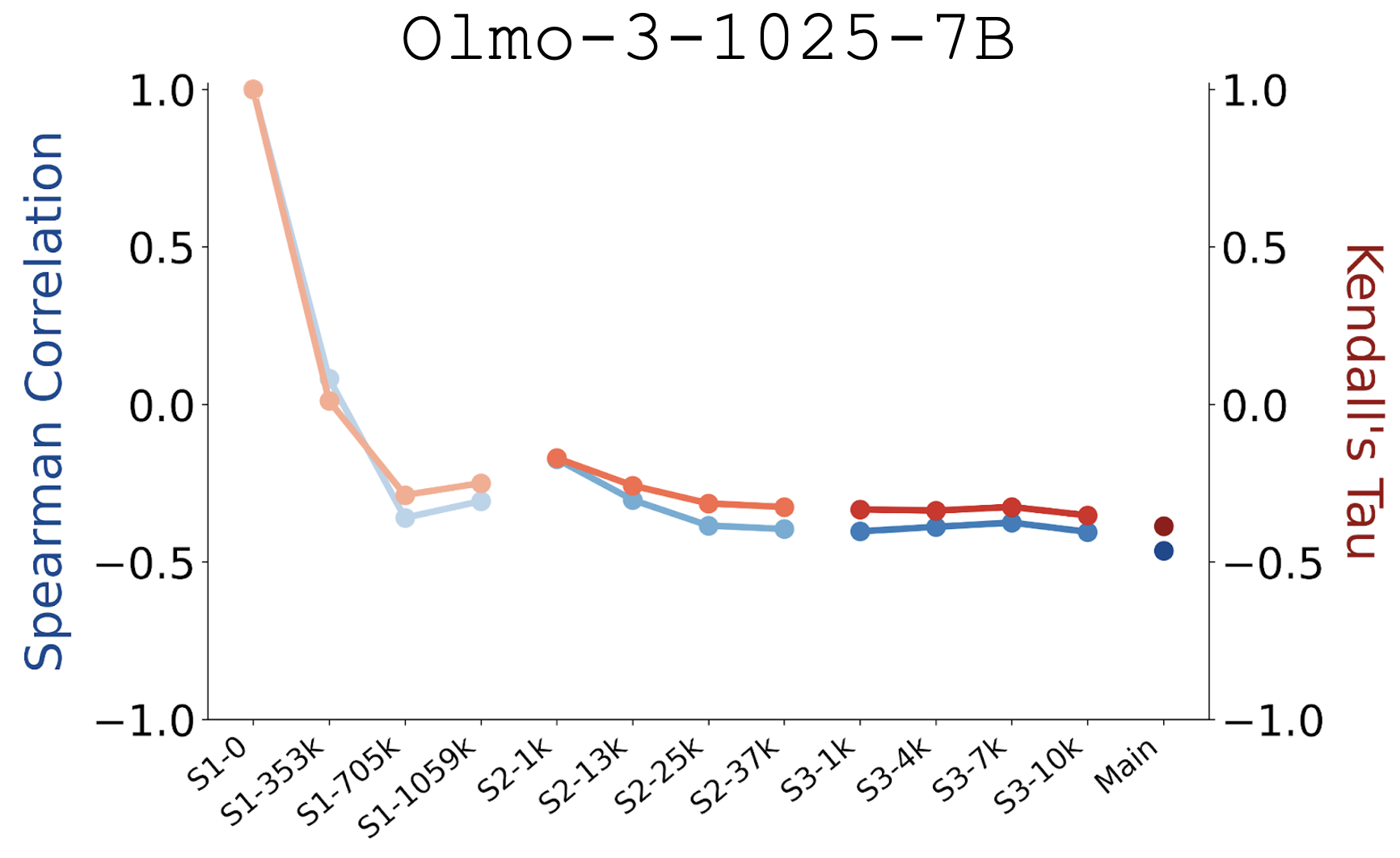
Feature 3: Condensation occurs early on.
The embedding condensation phenomenon emerges at model initialization and is gradually mitigated, not exacerbated, by pre-training.
Feature 4: Distillation is not a solution.
Knowledge distillation from a larger model does not transfer the desired resistance to embedding condensation.
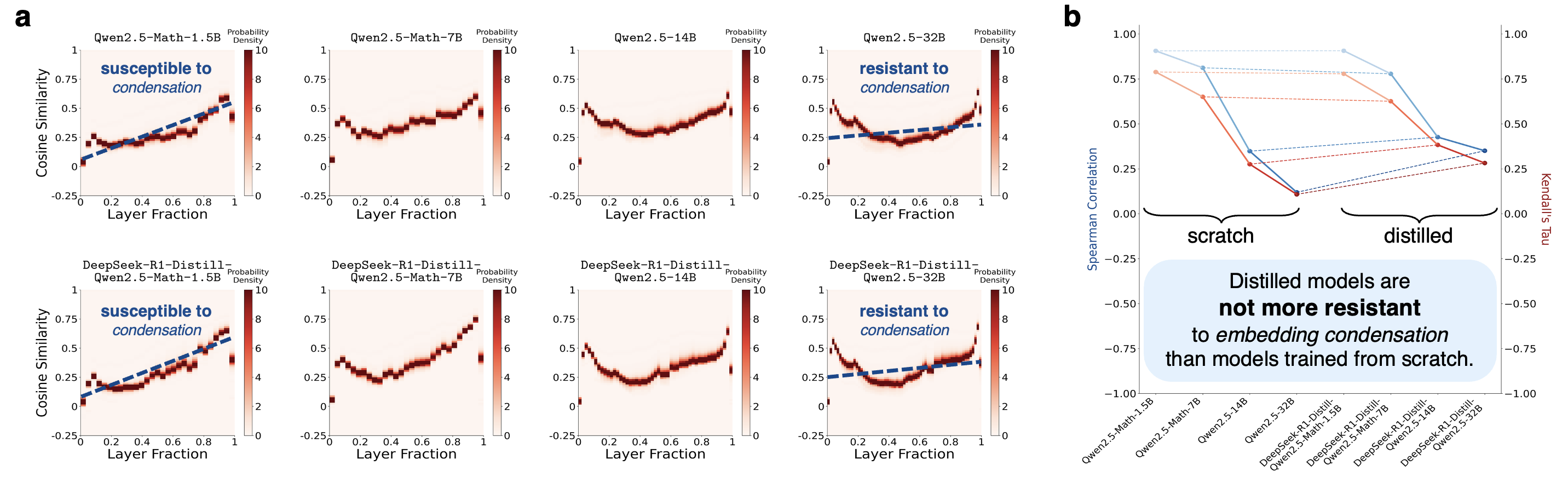
Dispersion loss
Embedding condensation reduces the expressivity of Transformers by collapsing token embedding vectors into narrow cones, under-utilizing the representation space. We hypothesize that by dispersing embeddings during training, smaller models can achieve representational qualities more similar to larger models, thus narrowing the performance gap without increasing the number of parameters.
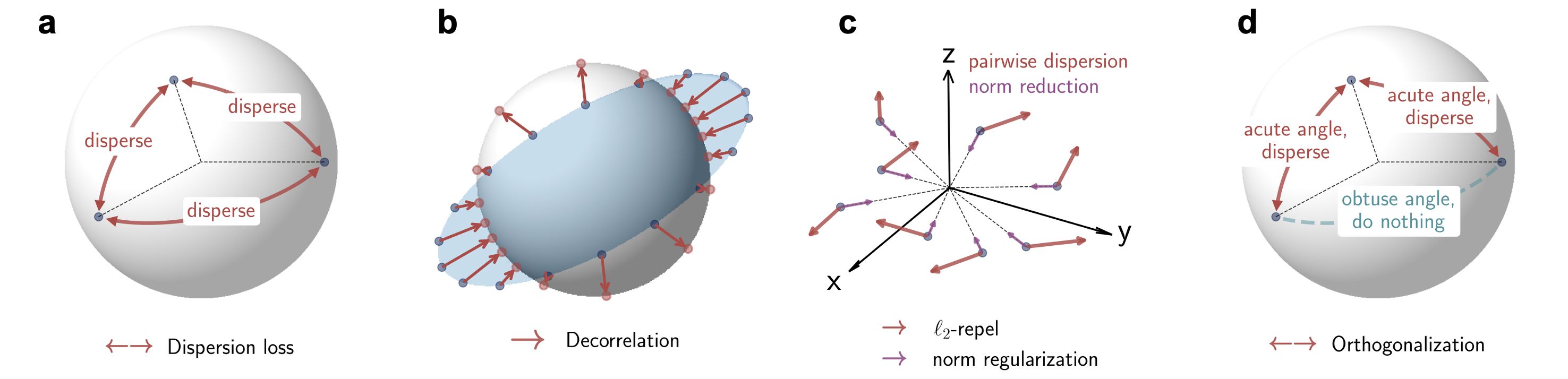
Our dispersion loss is inspired by the "Diffuse and Disperse" paper with practical modifications.

Dispersion loss counteracts the embedding condensation effect during mid-training and pre-training. A qualitative result is shown below, while more quantitative results can be found in the paper.
Disclaimers and future directions
Please see our project website for disclaimers and some future directions we suggest.
[New] PyPI support: embedding condensation
We have provided the computation and visualzation of embedding condensation into a PyPI package!
- Install or upgrade the package.
pip install embedding-condensation --upgrade
- Use it by simply passing in a
transformersmodel and tokenizer, as shown in the example below.
max_lengthdetermines the number of tokens in the context.datasetcurrently supports [wikipedia,pubmed,imdb,squad].min_word_countandmax_word_countfaciliates the text parser when grabbing a random part from thedatasetcorpse.- If you have a specific text corpse, you can pass it in using the
textsargument (expected format isSequence[str]). This would bypassdataset,min_word_countandmax_word_count.
import numpy as np
from transformers import AutoModel, AutoTokenizer
from embedding_condensation import measure_embedding_condensation
model = AutoModel.from_pretrained("gpt2")
model.eval()
tokenizer = AutoTokenizer.from_pretrained("gpt2")
result = measure_embedding_condensation(
model,
tokenizer,
repetitions=10,
max_length=512,
dataset="wikipedia",
min_word_count=1024,
max_word_count=1280,
plot=True,
show_progress=True,
save_path="./test_embedding_condensation.png",
)
print(result.cossim_by_layer.shape)
Citation
@inproceedings{liu2026dispersion,
title={Dispersion loss counteracts embedding condensation and improves generalization in small language models},
author={Liu, Chen and Sun, Xingzhi and Xiao, Xi and Van Tassel, Alexandre and Xu, Ke and Reimann, Kristof and Liao, Danqi and Gerstein, Mark and Wang, Tianyang and Wang, Xiao and Krishnaswamy, Smita},
booktitle={International conference on machine learning},
year={2026},
organization={PMLR}
}
Acknowledgements
- This work was initially motivated by the paper "A mathematical perspective on Transformers". We started this project early Apr 2025 after we watched a talk on that paper.
- The design of the dispersion loss was largely inspired by Runqian and Kaiming's paper "Diffuse and Disperse: Image Generation with Representation Regularization".


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file embedding_condensation-2.0.tar.gz.
File metadata
- Download URL: embedding_condensation-2.0.tar.gz
- Upload date:
- Size: 7.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c41720883c5d7f2447e86321ec9313883b123816d5b64e27ed002b5396a7a7b9
|
|
| MD5 |
bd3f6a78aa7e15d644cd0c610c7ddb08
|
|
| BLAKE2b-256 |
7230067c92ef7a676445b666258c84ff931cc7a5a77952408c134243eb872b7b
|
File details
Details for the file embedding_condensation-2.0-py3-none-any.whl.
File metadata
- Download URL: embedding_condensation-2.0-py3-none-any.whl
- Upload date:
- Size: 7.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9d7254dab2384a4779332280fcbc5545e392333f83da04a2f7607ceec72e2129
|
|
| MD5 |
86b24d2fb80051093d9fb0a98d262401
|
|
| BLAKE2b-256 |
80543a8b06822b989c7020d8559c8c156f26bd668116a5d02264673f110d157a
|







