Tool for analyzing and comparing embedding models through pairwise cosine similarity distributions

Project description
Embeddings Evaluator
A Python package for analyzing and comparing embedding models through pairwise cosine similarity distributions.
Features
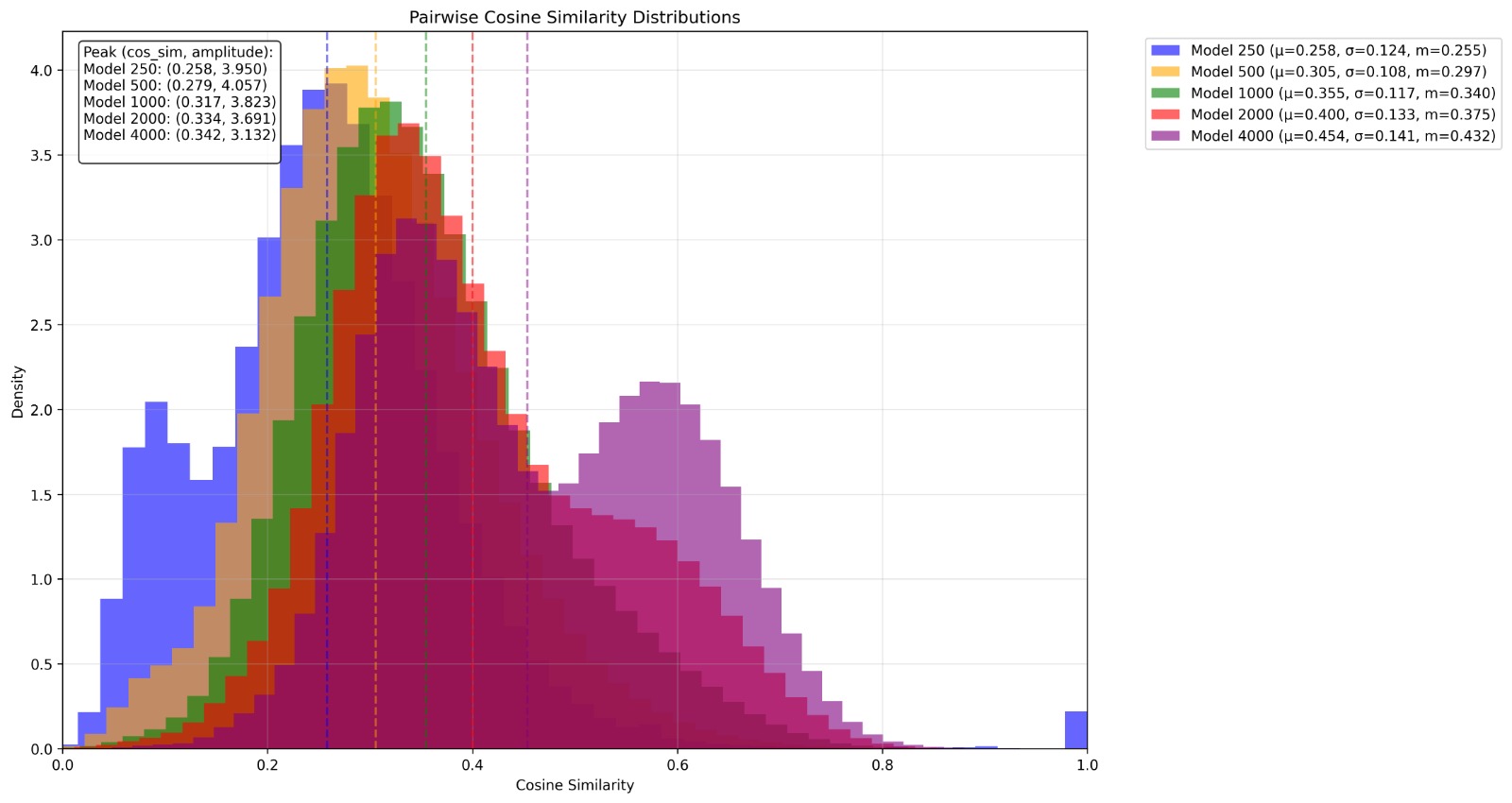
- Pairwise cosine similarity distribution analysis
- Statistical measures:
- Mean (μ)
- Standard deviation (σ)
- Median (m)
- Peak location and amplitude
- Multi-model comparison visualization
Why This Matters for RAG Systems
The Core Insight
For RAG (Retrieval-Augmented Generation) and semantic search, embedding quality isn't just about accuracy—it's about discriminative power.
When your pairwise similarity distribution is biased toward 0 (low similarity), it indicates:
✅ High Discriminative Power: Documents are well-separated in embedding space ✅ Distinct Representations: Each document has a unique semantic signature ✅ Better Retrieval Precision: Top-k results are genuinely the most relevant, not just "everything is somewhat similar" ✅ Reduced Noise: Fewer false positives in retrieval results
The Problem with High Similarity Distributions
If most pairwise similarities are high (biased toward 1):
❌ Poor Separation: Documents cluster together in embedding space ❌ Ambiguous Retrieval: Hard to distinguish between relevant and irrelevant content ❌ Noisy Results: Many false positives that "look similar" but aren't truly relevant ❌ Redundant Context: Retrieved chunks may be too similar to each other
Interpreting Results for RAG
Good Distribution Characteristics for RAG:
- Lower mean similarity: Documents are well-separated in embedding space
- Sufficient standard deviation: Variety in similarity scores allows discrimination
- Peak shifted toward lower values: Most document pairs are dissimilar
- Right-skewed distribution: Only truly similar documents have high similarity scores
Warning Signs:
- High mean similarity: Poor discriminative power - documents cluster together
- Low standard deviation: Limited ability to distinguish between relevant and irrelevant
- Peak near maximum similarity: Documents are too clustered
- Narrow distribution: Reduced capacity to filter and rank effectively
Comparative Analysis: When comparing models, prefer the one with:
- Lower mean pairwise similarity (better separation)
- Higher standard deviation (more discriminative range)
- Distribution peak closer to 0 (most pairs are dissimilar)
Practical Use Cases
-
Model Selection for RAG
# Compare embedding models before deployment embeddings_dict = { "Model A": load_qdrant_embeddings("model_a_collection"), "Model B": load_qdrant_embeddings("model_b_collection"), "Model C": load_qdrant_embeddings("model_c_collection") } fig = plot_model_comparison(embeddings_dict) # Choose the model with lowest mean similarity and good separation
-
Validate Chunking Strategy
# Test if your chunking creates distinct enough pieces embeddings_dict = { "500 tokens": load_qdrant_embeddings("chunks_500"), "1000 tokens": load_qdrant_embeddings("chunks_1000"), "2000 tokens": load_qdrant_embeddings("chunks_2000") } fig = plot_model_comparison(embeddings_dict) # Optimal chunk size should have low pairwise similarity
-
Evaluate Fine-tuning Impact
# Check if fine-tuning improved discriminative power embeddings_dict = { "Base Model": load_qdrant_embeddings("base_embeddings"), "Fine-tuned": load_qdrant_embeddings("finetuned_embeddings") } fig = plot_model_comparison(embeddings_dict) # Fine-tuned model should show lower mean similarity
-
Debug Retrieval Quality
# Investigate why retrieval is returning irrelevant results embeddings = load_qdrant_embeddings("production_embeddings") # High mean similarity explains poor retrieval precision
Key Principle
"Good embeddings for retrieval should make dissimilar things dissimilar, not just similar things similar."
This tool makes this principle measurable and visible through distribution analysis.
Installation
pip install -r requirements.txt
Usage
import numpy as np
from embeddings_evaluator import plot_model_comparison
from embeddings_evaluator.comparison import save_comparison_plot
# Load your embeddings into a dictionary
embeddings_dict = {
"Model A": embeddings_a, # numpy array of shape (n_docs, embedding_dim)
"Model B": embeddings_b
}
# Generate comparison plot
fig = plot_model_comparison(embeddings_dict)
save_comparison_plot(fig, 'comparison.png')
Loading Embeddings from Different Sources
The package provides convenient loaders for various embedding sources:
From FAISS Indices
from embeddings_evaluator import load_faiss_embeddings, plot_model_comparison
from embeddings_evaluator.comparison import save_comparison_plot
# Load embeddings from FAISS index
embeddings = load_faiss_embeddings("path/to/index.faiss")
# Load multiple models
embeddings_dict = {}
for size in [250, 500, 1000, 2000, 4000]:
embeddings_dict[f"Model {size}"] = load_faiss_embeddings(
f"faiss_embeddings/{size}/index.faiss"
)
# Generate visualization
fig = plot_model_comparison(embeddings_dict)
save_comparison_plot(fig, 'model_comparison.png')
From Qdrant Vector Database
from embeddings_evaluator import load_qdrant_embeddings, plot_model_comparison
# Load from local Qdrant instance
embeddings = load_qdrant_embeddings(
collection_name="my_embeddings",
url="http://localhost:6333"
)
# Load from Qdrant Cloud
embeddings = load_qdrant_embeddings(
collection_name="my_embeddings",
url="https://xyz.cloud.qdrant.io:6333",
api_key="your_api_key"
)
# Load with filters
embeddings = load_qdrant_embeddings(
collection_name="my_embeddings",
url="http://localhost:6333",
filter_conditions={"category": "science", "year": 2024}
)
# Load limited number of vectors
embeddings = load_qdrant_embeddings(
collection_name="my_embeddings",
url="http://localhost:6333",
limit=1000
)
# Compare multiple Qdrant collections
embeddings_dict = {
"Model A": load_qdrant_embeddings("collection_a"),
"Model B": load_qdrant_embeddings("collection_b"),
"Model C": load_qdrant_embeddings("collection_c")
}
fig = plot_model_comparison(embeddings_dict)
From Numpy Arrays
from embeddings_evaluator import load_numpy_embeddings
# Load from .npy file
embeddings = load_numpy_embeddings("embeddings.npy")
# Load from .npz file
embeddings = load_numpy_embeddings("embeddings.npz")
Generic Loader (Auto-detection)
from embeddings_evaluator import load_embeddings
# Auto-detect source type from file extension
embeddings1 = load_embeddings("index.faiss") # Detects FAISS
embeddings2 = load_embeddings("embeddings.npy") # Detects numpy
# Explicit source type for Qdrant
embeddings3 = load_embeddings(
"my_collection",
source_type="qdrant",
url="http://localhost:6333"
)
# From numpy array directly
import numpy as np
embeddings4 = load_embeddings(np.random.rand(100, 384))
Mixed Sources Comparison
from embeddings_evaluator import (
load_faiss_embeddings,
load_qdrant_embeddings,
load_numpy_embeddings,
plot_model_comparison
)
# Compare embeddings from different sources
embeddings_dict = {
"FAISS Model": load_faiss_embeddings("index.faiss"),
"Qdrant Model": load_qdrant_embeddings("my_collection"),
"Numpy Model": load_numpy_embeddings("embeddings.npy")
}
fig = plot_model_comparison(embeddings_dict)
Output
The tool provides:
- Statistical Measures for each model:
- Mean cosine similarity (μ)
- Standard deviation (σ)
- Median (m)
- Peak location and amplitude
- Visualization:
- Overlaid probability density histograms
- Statistical annotations
- Peak coordinates
- Vertical lines at mean values
- [0,1] bounded cosine similarity range
Project Structure
embeddings_evaluator/
├── embeddings_evaluator/ # Core library package
│ ├── __init__.py
│ ├── comparison.py # Comparison and visualization functions
│ ├── loaders.py # Data loaders for various sources
│ ├── metrics.py # Similarity metrics
│ └── metrics_optimized.py # Optimized metrics for large datasets
├── examples/ # Example scripts and usage demonstrations
│ ├── optimization_example.py
│ └── qdrant_example.py
├── scripts/ # Utility and test scripts
│ └── test_qdrant_comparison.py
├── docs/ # Additional documentation
│ ├── EMBEDDING_DRIFT.md
│ └── OPTIMIZATION_GUIDE.md
├── outputs/ # Generated outputs (gitignored)
│ ├── plots/ # Generated visualization plots
│ └── reports/ # Generated analysis reports
├── README.md
├── LICENSE
├── setup.py
├── requirements.txt
└── .env.example
Performance Optimization
For large datasets, the package provides multiple optimized methods for calculating pairwise similarities:
- Auto-select: Automatically chooses the best method based on dataset size and hardware
- Sampling: 100-2000x faster for large datasets with ~99.9% statistical accuracy
- Chunked: Memory-efficient processing for constrained systems
- CPU Parallel: Multi-core CPU acceleration
- GPU Single: CUDA GPU acceleration (50-100x faster)
- Multi-GPU: Multiple GPU support for maximum performance
See docs/OPTIMIZATION_GUIDE.md for detailed documentation and examples.
Quick Example
from embeddings_evaluator import pairwise_similarities_auto
# Automatically select the best optimization method
similarities = pairwise_similarities_auto(embeddings)
Requirements
- numpy
- pandas
- plotly
- scipy
- scikit-learn (for distance metrics and nearest neighbors)
- faiss-cpu (for FAISS index support)
- qdrant-client (for Qdrant vector database support)
- matplotlib (for visualization)
Optional (for GPU acceleration)
- cupy-cuda11x or cupy-cuda12x (for GPU support)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file embeddings_evaluator-1.0.1.tar.gz.
File metadata
- Download URL: embeddings_evaluator-1.0.1.tar.gz
- Upload date:
- Size: 20.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
90b6393ecdbb60f204a92b39542b4af9f2cc3dda4a51d7c1e363c10be47672f8
|
|
| MD5 |
33239d1193d83400773ccf77e332f22a
|
|
| BLAKE2b-256 |
c5e2a42961eb66a77e72f2aa1926c317bbb6cbd8029459f21f2a0fe26aac7d24
|
File details
Details for the file embeddings_evaluator-1.0.1-py3-none-any.whl.
File metadata
- Download URL: embeddings_evaluator-1.0.1-py3-none-any.whl
- Upload date:
- Size: 18.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
affbdca92c1a46d55e9ed1862cfd491aec58a85be1eca75fb94a73a0015da49f
|
|
| MD5 |
7ab1aa45f4b405a7caaf6434383bdc0e
|
|
| BLAKE2b-256 |
7004eb7c9de4e70a7bb88e251f4e3cdf7e424864c21a2dc41d84994391159c13
|







