Retrieving the most relevant context for your LLMs

Project description




Quick start
Installation
You have two ways to get started:
- Install our python library :
pip install embedstore - Directly call the endpoint :
https://api.embedding.store/retrieve
Get API Key here
Note: Currently we are rate-limiting all API keys to 100 requests/day
Set the EMBEDSTORE_API_KEY as environment variable
import os
os.environ["EMBEDSTORE_API_KEY"] = <YOUR API KEY>
Pass the API key as header if you are calling the endpoint directly. More details about the endpoint
headers = {'API-Key': <YOUR_API_KEY>}
Retrieve context
In a few lines of code, you can now start retrieving relevant context to get better answers from your LLM. We have already embedded Podcast Transcripts and Arxiv Research Papers, with new dataset drops every week (full list here)
from embedstore.rag.retrievers import EmbedStoreRetriever
# Initialize the retriever
arxiv_retriever = EmbedStoreRetriever(dataset_id = "arxiv_01", num_docs=3)
# Query the retriever
context = arxiv_retriever.query("What is the state of the art in Autonomous Driving security and safety?")
# Examine the retrieved context and then append it to the prompt before you call your LLM
print(context[0])
Read more here for detailed usage guidelines.
What is this?
We are building context retrieval apis for developers creating chatbots, copilots and search tools on top of LLMs. You no longer need to maintain scraping and embedding pipelines, and instead focus on building your product.
Read more about RAG (retrieval augmented generation) here.
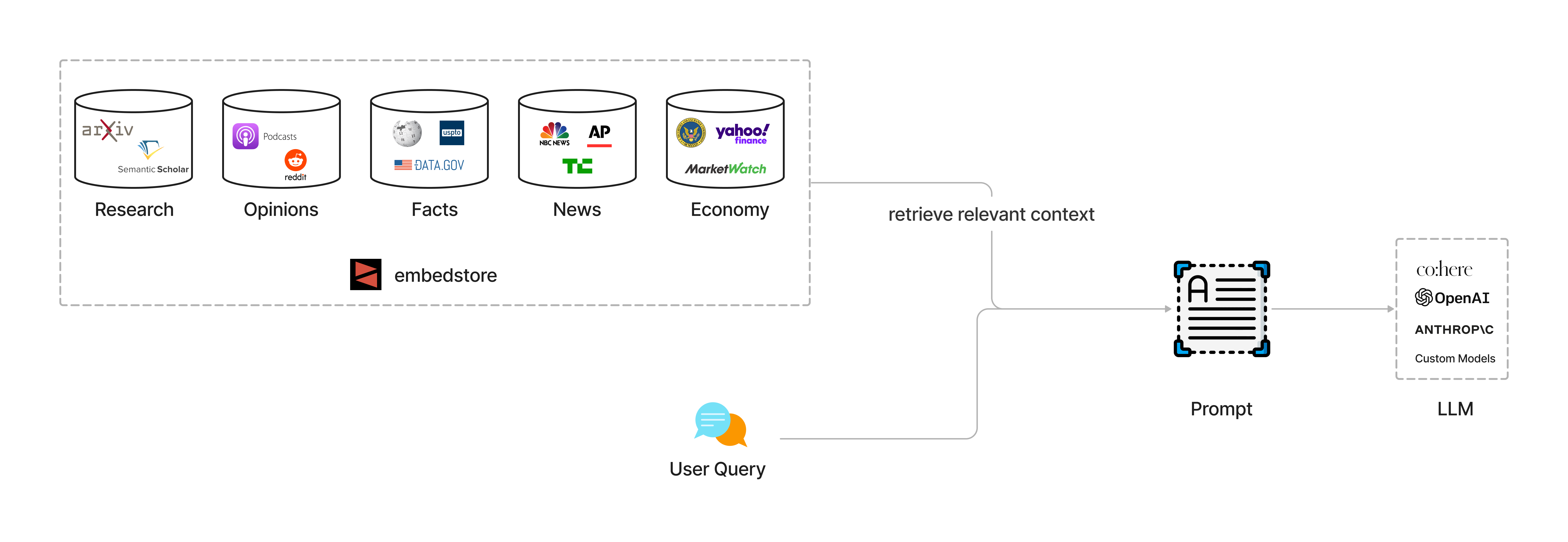
Usage
More about EmbedStoreRetriever class
EmbedStoreRetriever serves as the single point of entrance to interact with the embedstore.
Parameters to initialize the class :
dataset_id (str): Dataset to query and retrieve context from (eg:arxiv_01,podcasts_01)num_docs (int): Number of context to retrieve from the embeddings
Advanced filtering while querying
You can use EmbedStoreRetriever.query() to get context based on the user prompt and also perform filtering.
The query() function takes two inputs:
prompt (str): The user prompt that you are querying forpost_processing_config (dict): A dictionary of dataset specific filters (check here for available options)
Example : Temporal filter on Arxiv research papers
from embedstore.rag.retrievers import EmbedStoreRetriever
# Initialize the retriever
arxiv_retriever = EmbedStoreRetriever(dataset_id = "arxiv_01", num_docs=3)
# Query the retriever
user_query = "What are some recent papers about CRISPR? Give me a brief summary of major trends."
# Filter to do semantic search on papers published in the last 6 months
post_processing_config = {"filters":{"publish_date_start":"2022-12-01T0:0:0Z"}}
# Calling the `query()` function
context = arxiv_retriever.query(user_query,post_processing_config)
Example : Categorical filter on Podcast Transcripts
# Initialize the retriever
podcast_retriever = EmbedStoreRetriever(dataset_id = "podcasts_01", num_docs=3)
# Query the retriever
user_query = "What are people saying about the new Twitter CEO?"
# Filter to search on Business and Technology podcast episodes
post_processing_config = {"filters":{"category":["Business","Technology"]}}
# Calling the `query()` function
context = podcast_retriever.query(user_query,post_processing_config)
Download raw embeddings
You can download raw vector embeddings along with the metadata.
Note: we are limiting the downloads to 5000 vectors. If you want the full set of embeddings, reach out to us at hello@embedding.store.
from embedstore.rag.datadownloaders import download_embeddings
path_to_folder = "" #local path where you want to download the embeddings
download_embeddings('podcasts_01', path_to_folder)
download_embeddings() downloads the embeddings in .pkl format. You can load the file using the following code. The embeddings are stored in a list of tuples (vector[], metadata{})
with open(path_to_pickle_file, 'rb') as f:
import pickle
data = pickle.load(f)
Using /retrieve endpoint
Sample code
import requests
url = 'https://api.embedding.store/retrieve'
headers = {'API-Key': <YOUR_API_KEY>}
# creating the payload
payload = {"query": <PROMPT>,"dataset_params": {"dataset_id":"podcasts_01", "filters":{"category":["Business"]}}}
response = requests.post(url, headers=headers,payload=payload)
# check the response
print(response.json())
Authorization
Add the API key in the header : {'API-Key'='<YOUR_API_KEY>'
Parameters
| Param | Details | Type | Example |
|---|---|---|---|
| query | the prompt on which context need to be retrieved | str |
What does Tim Ferris say about productivity? |
| dataset_params | a dictionary of dataset specific parameters like dataset_id and filters. check here for available filters | dict |
{"dataset_id":"podcasts_01", "filters":{"category":["Business"]} |
By default, the API returns the top 3 contexts right now. We will be adding options to control this soon.
Sample Response
{
"success":"true",
"contexts" : [
{"episode_published_time": "2023-03-10T11:00:00Z", "episode_summary": "In this episode of My First Million, the hosts discuss a range of topics including making more money using what you already have, Elon Musk's recent controversies, a study on money and happiness, the potential ban of TikTok, and the emergence of the Power Slap League. They express skepticism towards the study on money and happiness and discuss the potential risks of TikTok. The hosts also express their disgust at the violence in the Power Slap League and recommend the Korean reality show Physical 100. ", "podcast_name": "My First Million", "speakers": ["the hosts"], "transcript_snippet": "to an extent. But I'm like, there's, but just because you say it like it is, like, well, he's just doing what he wants. Yeah, but he just, you just punched someone. Like, hitting people isn't good. Do you know what I mean? It's like, yeah, I want to do what I want. Does that mean I'm going to, like, go take a dump in the corner of the room? Like, you know, there's like, let's be polite to one another also, if possible. Right. We don't, we're not going to be needlessly, needlessly rude to one another. And that's kind of how I feel he acts right now. And that's not cool. Two other, two other parts of this news story. One, it's going around that this guy's payout was $100 million, which makes no sense. Anybody who's in business is like, well, that number makes no sense. There's no way he's getting paid $9 million a year of salary. There's no way that they bought his agency for $100 million. That's not how much you would acquire an agency for. It's probably more like 10. But it, and I"},
{"episode_published_time": "2023-05-11T20:53:23Z", "episode_summary": "In this collection of podcast episode summaries, we learn that Lyft is discontinuing its pooled rides service, WhatsApp is tackling spam calls in India, and U.S. chip imports rose 13% in Q1 2023. Twitter launched encrypted direct messages for verified users, Peloton recalled 2.2 million bikes, and Disney lost streaming subscribers for the second quarter in a row. Disney is set to launch a single app for both Hulu and Disney Plus, while Fairphone has launched FairBuds XL, a pair of over-ear wireless noise-canceling headphones. The Daily Tech News Show discussed the new Asus Rogue Ally, a Windows-based handheld gaming device, and the disappointment of Google's Pixel tablet not being able to function as a home hub. They also talked about a recent Antiques Roadshow episode where a binder containing all 102 original base set Pokemon cards was appraised for a value of up to $10,000.", "podcast_name": "Daily Tech News Show", "speakers": ["The hosts", "Scott Johnson"], "transcript_snippet": "Steam Deck and you'll run your Steam games. It'll feel like a Steam Deck in many ways. But there is something nice about the Steam Deck's integration with the ecosystem that makes that a great experience if you're in that ecosystem, right. And a lot of gamers aren't. A lot of people are like, I don't want to be tied to Steam or Epic or anyone else. I want to have my games just loose on my hard drive and I want to install them the way I want to. That's always an option for most games still. Those people are going to be stoked about this. And that screen looks nice. Like there are a lot of good things to say but to answer your question more succinctly I think that battery life does matter and that will make a difference in the long run. So slimness is nice. Battery life is nicer. Well while you're enjoying battery life, maybe you're, I don't know, watching a television that runs on a battery. I don't know. But if you're not familiar with the long running TV series Antiques Roadshow, you"},
{"episode_published_time": "2023-05-05T20:50:12Z", "episode_summary": "In this episode of Daily Tech News Show, the hosts discuss various technology-related news. Microsoft is reportedly collaborating with AMD to develop processors for AI workloads. 8BitDo has released a new wireless controller compatible with multiple devices. JBL's Tour Pro 2 buds have been released with a charging case featuring its own LCD display. Apple's earnings were unremarkable, but CEO Tim Cook confirmed the company's focus on AI. The hosts also discuss Grasp, a new search engine that allows users to create a customized search index based on websites they follow. They also predict what to expect from Google's upcoming I/O conference. The episode ends with a food technology quiz for patrons during the Good Day Internet segment.", "podcast_name": "Daily Tech News Show", "speakers": ["Tom Merritt", "Sarah Lane", "Roger Chang", "Rich Stroffolino", "Joe Kuntz", "Dan Campos", "Jen Cutter", "Dr. Nikki Ackermans", "Zoe Detterding", "Chris Ashley", "Nika Monfort", "Scott Johnson", "Justin Robert Young", "Shannon Morse"], "transcript_snippet": "the other products like the 7a, that one looks really interesting. I recently posted a video about comparing that to the Pixel 7 and how I probably wouldn't wait, especially since it's going to increase in price most likely to $500 while the 6a was $450. So you say jump on the 6a because it's cheaper? I would actually jump on the 7, even though it's a little bit more expensive. Yeah, because the tech is a little bit better. So that's just my personal opinion. I would love to see the tablet come out. Hopefully that does get announced, even though they haven't officially said anything. It's about time. I would be shocked if they don't announce it. It is about time, yes. I'm really curious if it's going to be another cheap Android tablet or if we've seen a few rumors about prices, but not a lot about the specs. So if it's a tablet that I could actually get some work done on, then I would seriously consider it because that would integrate very, very well into an Android content creator"}
]
}
Datasets
| Dataset | dataset_id | Description | Status | Filters Available |
|---|---|---|---|---|
| Podcast Transcripts | podcasts_01 | 30 most recent podcasts across Finance, Business and Technology | Live | - category : ["Finance","Business","Technology"] |
| arXiv | arxiv_01 | 2M arxiv papers | Live | - category : ['Computer Science', 'Quantitative Biology', 'Economics', 'Quantitative Finance', 'Statistics', 'Electrical Engineering and Systems Science', 'Mathematics', 'Physics']- publish_date_start : To filter papers published after this date (string in %Y-%m-%dT%H:%M:%SZ) |
| Wikipedia | wikipedia_01 | 50K popular pages (get access to the full dataset here) | Live | - category : ['Arts and Entertainment', 'Sports', 'People', 'Science and Technology', 'Geography', 'Politics and Government', 'History'] |
| News | news_01 | Launching Soon - Subscribe |
Get involved
We are early, and we want to know how you use this library and what else would you want to make the most out of it.
Join us on our discord, or feel free to email us at hello@embedding.store!


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file embedstore-0.0.6-py3-none-any.whl.
File metadata
- Download URL: embedstore-0.0.6-py3-none-any.whl
- Upload date:
- Size: 11.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ab77e6bb97261686bfd3b3de9b9415a4e1d249373407af90c055116ffe6b3a3e
|
|
| MD5 |
b820f94ba43ca43fa985bdd1720d8308
|
|
| BLAKE2b-256 |
2b04e29ca004292db5cc6dd98114eed3faca594ae4d7ced666cd46fa993795c0
|







