A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups

Project description

A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups





EMLP is a jax library for the automated construction of equivariant layers in deep learning based on the ICML2021 paper A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups. You can read the documentation here.
What EMLP is great at doing
-
Computing equivariant linear layers between finite dimensional representations. You specify the symmetry group (discrete, continuous, non compact, complex) and the representations (tensors, irreducibles, induced representations, etc), and we will compute the basis of equivariant maps mapping from one to the other.
-
Automatic construction of full equivariant models for small data. E.g. if your inputs and outputs (and intended features) are a small collection of elements like scalars, vectors, tensors, irreps with a total dimension less than 1000, then you will likely be able to use EMLP as a turnkey solution for making the model or atleast function as a strong baseline.
-
As a tool for building larger models, but where EMLP is just one component in a larger system. For example, using EMLP as the convolution kernel in an equivariant PointConv network.
What EMLP is not great at doing (yet?)
-
An efficient implementation of CNNs, Deep Sets, typical translation + rotation equivariant GCNNs, graph neural networks.
-
Handling large data like images, voxel grids, medium-large graphs, point clouds.
Given the current approach, EMLP can only ever be as fast as an MLP. So if flattening the inputs into a single vector would be too large to train with an MLP, then it will also be too large to train with EMLP.
Showcasing some examples of computing equivariant bases
We provide a type system for representations. With the operators ρᵤ⊗ρᵥ, ρᵤ⊕ρᵥ, ρ* implemented as *,+ and .T build up different representations. The basic building blocks for representations are the base vector representation V and tensor representations T(p,q) = V**p*V.T**q.
For any given matrix group and representation formed in our type system, you can get the equivariant basis with rep.equivariant_basis() or a matrix which projects to that subspace with rep.equivariant_projector().
For example to find all O(1,3) (Lorentz) equivariant linear maps from from a 4-Vector Xᶜ to a rank (2,1) tensor Mᵇᵈₐ, you can run
from emlp.reps import V,T
from emlp.groups import *
G = O13()
Q = (T(1,0)>>T(2,1))(G).equivariant_basis()
or how about equivariant maps from one Rubik's cube to another?
G = RubiksCube()
Q = (V(G)>>V(G)).equivariant_basis()
Using + and * you can put together composite representations (where multiple representations are concatenated together). For example lets find all equivariant linear maps from 5 node features and 2 edge features to 3 global invariants and 1 edge feature of a graph of size n=5:
G=S(5)
repin = 10*T(1)+5*T(2)
repout = 3*T(0)+T(2)
Q = (repin(G)>>repout(G)).equivariant_basis()
From the examples above, there are many different ways of writing a representation like 10*T(1)+5*T(2) which are all equivalent.
10*T(1)+5*T(2) = 10*V+5*V**2 = 5*V*(2+V)
You can even mix and match representations from different groups. For example with the cyclic group ℤ₃, the permutation group 𝕊₄, and the orthogonal group O(3)
rep = 2*V(Z(3))*V(S(4))+V(O(3))**2
Q = (rep>>rep).equivariant_basis()
Outside of these tensor representations, our type system works with any finite dimensional linear representation and you can even build your own bespoke representations following the instructions here.
You can visualize these equivariant bases with vis(repin,repout), such as with the three examples above
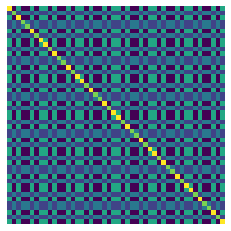
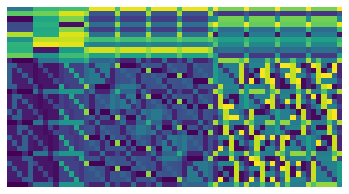
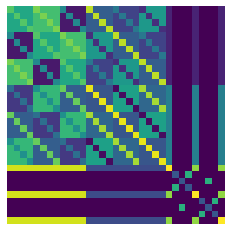
Checkout our documentation to see how to use our system and some worked examples.
Simple example of using EMLP as a full equivariant model
Suppose we want to construct a Lorentz equivariant model for particle physics data that takes in the input and output 4-momentum of two particles in a collision, as well as a some metadata about these particles like their charge, and we want to classify the output as belonging to 3 distinct classes of collisions. Since the outputs are simple logits, they should be unchanged by Lorentz transformation, and similarly with the charges.
import emlp
from emlp.reps import T
from emlp.groups import Lorentz
import numpy as np
repin = 4*T(1)+2*T(0) # 4 four vectors and 2 scalars for the charges
repout = 3*T(0) # 3 output logits for the 3 classes of collisions
group = Lorentz()
model = emlp.nn.EMLP(repin,repout,group=group,num_layers=3,ch=384)
x = np.random.randn(32,repin(group).size()) # Create a minibatch of data
y = model(x) # Outputs the 3 class logits
Here we have used the default Objax EMLP, but you can also use our PyTorch, Haiku, or Flax versions of the models. To see more examples, or how to use your own representations or symmetry groups, check out the documentation.
Installation instructions
To install as a package, run
pip install emlp
To run the scripts you will instead need to clone the repo and install it locally which you can do with
git clone https://github.com/mfinzi/equivariant-MLP.git
cd equivariant-MLP
pip install -e .[EXPTS]
Experimental Results from Paper
Assuming you have installed the repo locally, you can run the experiments we described in the paper.
To train the regression models on one of the Inertia, O5Synthetic, or ParticleInteraction datasets found in emlp.datasets.py you can run the script experiments/train_regression.py with command line arguments specifying the dataset, network, and symmetry group. For example to train EMLP with SO(3) equivariance on the Inertia dataset, you can run
python experiments/train_regression.py --dataset Inertia --network EMLP --group "SO(3)"
or to train the MLP baseline you can run
python experiments/train_regression.py --dataset Inertia --network MLP
Other command line arguments such as --aug=True for data augmentation or --ch=512 for number of hidden units and others are available, and you can browse the options and their defaults with python experiments/train_regression.py -h. If no group is specified, EMLP will automatically choose the one matched to the dataset, but you can also go crazy with any of the other groups implemented in groups.py provided the dimensions match the data (e.g. for the 3D inertia dataset you could do --group= "Z(3)" or "DkeR3(3)" but not "Sp(2)" or "SU(5)").
For the dynamical systems modeling experiments you can use the scripts
experiments/neuralode.py to train (equivariant) Neural ODEs and experiments/hnn.py to train (equivariant) Hamiltonian Neural Networks.
For the dynamical system task, the Neural ODE and HNN models have special names. EMLPode and MLPode for the Neural ODEs in neuralode.py and EMLPH and MLPH for the HNNs in hnn.py. For example,
python experiments/neuralode.py --network EMLPode --group="O2eR3()"
or
python experiments/hnn.py --network EMLPH --group="DkeR3(6)"
These models are trained to fit a double spring dynamical system. 30s rollouts of the dataset, along with rollout error on these trajectories, and conservation of angular momentum are shown below.
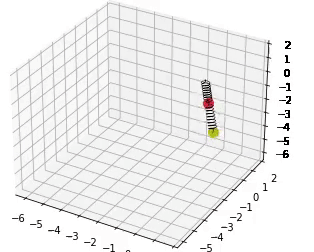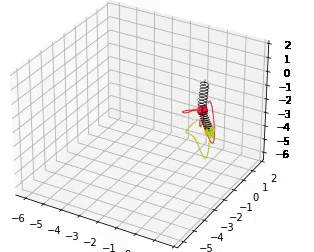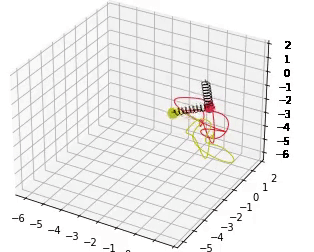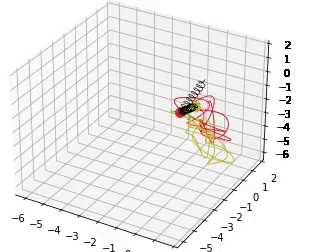
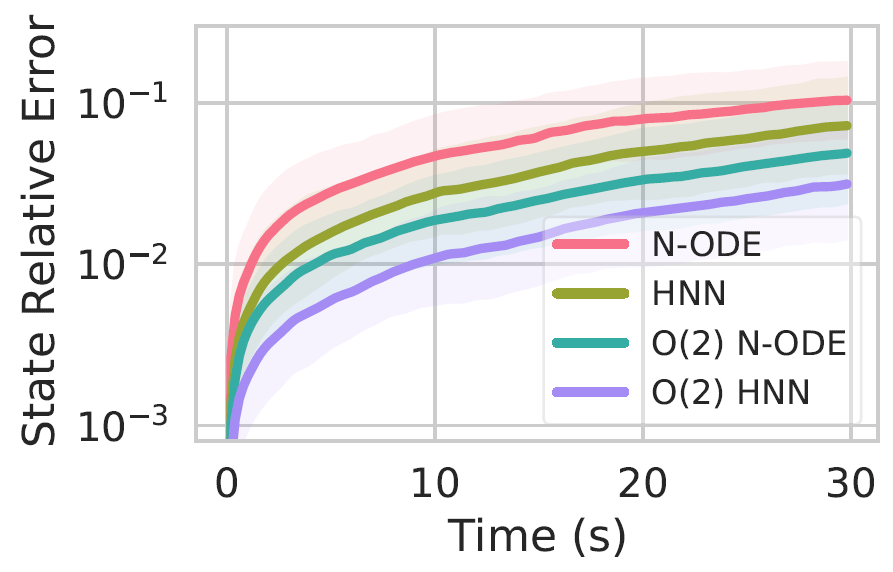
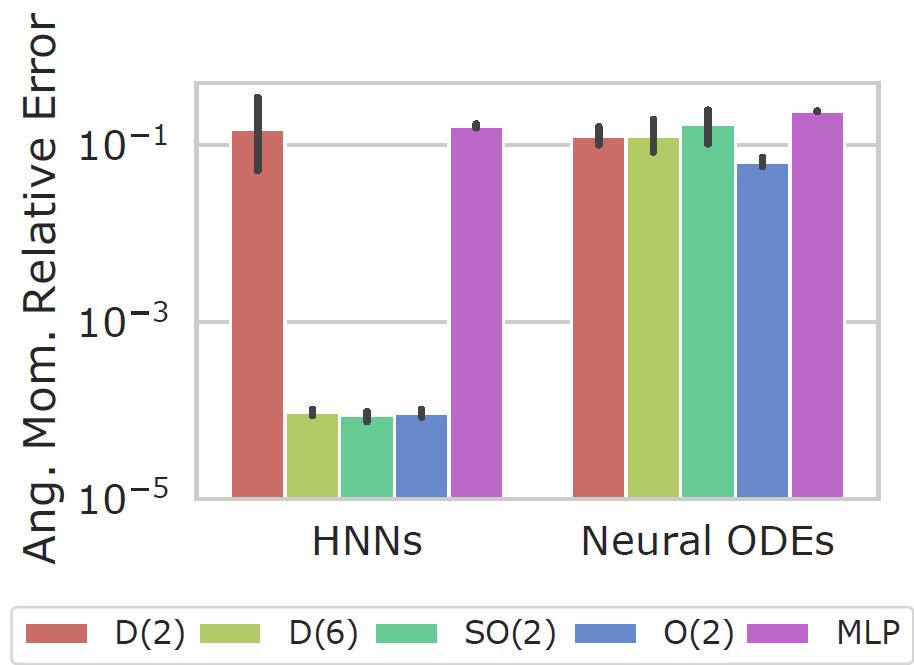
If you find our work helpful, please cite it with
@article{finzi2021emlp,
title={A Practical Method for Constructing Equivariant Multilayer Perceptrons for Arbitrary Matrix Groups},
author={Finzi, Marc and Welling, Max and Wilson, Andrew Gordon},
journal={Arxiv},
year={2021}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file emlp-1.0.3.tar.gz.
File metadata
- Download URL: emlp-1.0.3.tar.gz
- Upload date:
- Size: 44.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.0.1 pkginfo/1.7.1 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.60.0 CPython/3.7.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a168e20b860302751fd00d35312eb6716e8d471b8bb37f0405d4f134a10a8a22
|
|
| MD5 |
97ecf5066ae8af54e5b7e828ef8bf08b
|
|
| BLAKE2b-256 |
170d86203685a666651072585de9cc840ba77c96589014a2c7d4f1b8a148106c
|







