Emotional memory library for LLMs based on Affective Field Theory
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
emotional_memory









Emotional memory for LLMs based on Affective Field Theory (AFT) — a 5-layer model that encodes not just what happened, but how it felt, how that feeling was moving, and what mood colored the moment.
Pre-registered evaluation on realistic_recall_v2: English (N=200, SBERT Δ=+0.21, d=0.49) and French (N=120, me5, Δ=+0.18, p<0.0001, Hedges g=0.42 — Addendum M Branch A PASS). Italian/Spanish me5 at declared power (N=120) FAIL; English-SBERT and SBERT-Spanish (N=80) hold. External-QA evaluation (LoCoMo) and naturalistic dialogue (DailyDialog) FAIL — the AFT advantage is regime-specific to affect-discriminative recall, not general superiority. Full claim-validation matrix.
Why emotional_memory?
Most LLM memory libraries treat retrieval as semantic-only: vector similarity over text. Real human recall is driven by more:
- Affective congruence — we remember things that feel like how we feel now (Bower 1981)
- Arousal-modulated consolidation — emotionally-charged events consolidate more strongly (Cahill & McGaugh 1995; ACT-R power-law with arousal floor, McGaugh 2004)
- Reconsolidation — retrieved memories become labile and update with prediction error (Nader & Schiller 2000; APE-gated lability window)
- Dual-path encoding — fast affective signal precedes slow appraisal (LeDoux 1996)
- 3D affect — perceived control (dominance) discriminates fear from anger (Mehrabian & Russell 1974; PAD)
emotional_memory operationalizes these as a single retrieval pipeline. Validated against 20 published psychological phenomena (127 fidelity tests) and 12+ pre-registered confirmatory studies — including committed negative results.
How it compares
| Library | Memory model | Affective retrieval | Reconsolidation | Decay model | Psychological fidelity tests |
|---|---|---|---|---|---|
| emotional_memory | 5-layer AFT (semantic + valence/arousal + momentum + mood + appraisal) | ✅ mood-congruent + APE-gated | ✅ Nader & Schiller 2000 | ACT-R power-law + arousal modulation | 127 tests, 20 phenomena |
| MemGPT / Letta | Hierarchical context (working + archival) | ❌ | ❌ | None | — |
| mem0 | Fact extraction + vector store | ❌ | ❌ | None | — |
| A-MEM | Atomic notes + dynamic links | ❌ | ❌ | None | — |
| LangMem | Hot/cold memory tiers | ❌ | ❌ | Time-based eviction | — |
| Generative Agents (Park et al.) | Importance + recency + relevance | Partial (importance only) | ❌ | Exponential | — |
This is not a replacement for those tools — emotional_memory is a focused primitive that can plug into any of them via the MemoryStore protocol (LangChain adapter included).
30-second example
from emotional_memory import EmotionalMemory, InMemoryStore, CoreAffect
# MyEmbedder = any object with `.embed(text) -> list[float]` (see Quickstart for a
# real one via the [sentence-transformers] extra).
em = EmotionalMemory(store=InMemoryStore(), embedder=MyEmbedder())
em.set_affect(CoreAffect(valence=-0.6, arousal=0.7)) # stressed
em.encode("The deployment failed at 3am.")
em.encode("Beautiful sunset on the lake.")
em.set_affect(CoreAffect(valence=-0.5, arousal=0.6)) # similar mood later
results = em.retrieve("yesterday", top_k=2)
# → deployment memory ranks higher than sunset, even with equal semantic distance.
Installation
uv pip install emotional-memory
uv pip install "emotional-memory[sentence-transformers]" # real semantic embeddings (recommended)
uv pip install "emotional-memory[sqlite]" # SQLite persistence via sqlite-vec
uv pip install "emotional-memory[qdrant]" # Qdrant vector database
uv pip install "emotional-memory[chroma]" # ChromaDB vector database
uv pip install "emotional-memory[otel]" # OpenTelemetry tracing (no-op without this extra)
uv pip install "emotional-memory[redis]" # shared affective-state persistence via Redis
uv pip install "emotional-memory[viz]" # matplotlib visualization
uv pip install "emotional-memory[dotenv]" # .env file loading via python-dotenv
For development:
git clone https://github.com/gianlucamazza/emotional-memory
cd emotional-memory
make install
# optional local demo stack:
make install-demo
Quickstart
uv pip install "emotional-memory[sentence-transformers]"
from emotional_memory import EmotionalMemory, InMemoryStore, CoreAffect
from emotional_memory.embedders import SentenceTransformerEmbedder
em = EmotionalMemory(
store=InMemoryStore(),
embedder=SentenceTransformerEmbedder(), # all-MiniLM-L6-v2 by default
)
# Set current emotional state
em.set_affect(CoreAffect(valence=0.8, arousal=0.6))
# Encode memories — each one captures the full affective context
em.encode("Just shipped the feature after three hard weeks.")
em.encode("Team celebration in the office.", metadata={"source": "slack"})
# Retrieve — ranked by semantic relevance AND emotional congruence
results = em.retrieve("difficult project success", top_k=3)
for mem in results:
print(mem.content, mem.tag.core_affect)
# Or inspect why a memory ranked where it did
explained = em.retrieve_with_explanations("difficult project success", top_k=1)
top = explained[0]
print(top.score)
print(top.breakdown.raw_signals)
Bring your own embedder — any object with .embed(text) -> list[float] works:
class MyEmbedder:
def embed(self, text: str) -> list[float]: ...
def embed_batch(self, texts: list[str]) -> list[list[float]]: ...
Or subclass SequentialEmbedder and implement only embed() — embed_batch() is provided.
Async
import asyncio
from emotional_memory import EmotionalMemory, InMemoryStore, as_async
from emotional_memory.embedders import SentenceTransformerEmbedder
sync_em = EmotionalMemory(store=InMemoryStore(), embedder=SentenceTransformerEmbedder())
em = as_async(sync_em) # wraps sync components with asyncio.to_thread bridges
async def main():
await em.encode("Meeting went surprisingly well today.")
results = await em.retrieve("work meeting", top_k=3)
asyncio.run(main())
For native async embedders or stores, construct AsyncEmotionalMemory directly with
SyncToAsyncEmbedder, SyncToAsyncStore, or your own AsyncEmbedder/AsyncMemoryStore.
Affective Field Theory
AFT models emotion as a field — distributed, dynamic, multi-layer — rather than a discrete label or a single coordinate. Five layers are captured at encoding time:
| Layer | Model | What it captures |
|---|---|---|
| CoreAffect | Russell-Mehrabian PAD model | Continuous (valence, arousal, dominance) — the emotional substrate |
| AffectiveMomentum | Spinoza — affect as transition | Velocity and acceleration of affect change |
| MoodField | Heidegger — Stimmung as attunement | Slow-moving global mood with inertia (EMA) |
| AppraisalVector | Scherer/Lazarus/Stoics | Emotion derived from evaluation: novelty, goal-relevance, coping, norm-congruence, self-relevance |
| ResonanceLinks | Aristotle/Hume/Bower/Collins & Loftus/Hebb | Associative bidirectional graph: semantic, emotional, temporal, causal, contrastive links; multi-hop spreading activation + Hebbian co-retrieval strengthening |
Full theoretical foundations: docs/research/
API Reference
The full API is auto-generated from docstrings and published at gianlucamazza.github.io/emotional-memory.
- Engine —
EmotionalMemory(sync) andAsyncEmotionalMemoryshare the same method surface:encode,observe,encode_batch,retrieve,retrieve_with_explanations,elaborate/elaborate_pending,prune,export_memories/import_memories, and state persistence. Both support context managers for automatic resource cleanup. - Configuration —
EmotionalMemoryConfigplus nestedRetrievalConfig,ResonanceConfig,DecayConfig,MoodDecayConfig,AdaptiveWeightsConfig,LLMAppraisalConfig,QueryClassifierConfig. Top-level flags:dual_path_encoding,elaboration_learning_rate,auto_categorize, and ablation toggles (enable_appraisal,enable_mood_signal,enable_momentum,enable_resonance,enable_reconsolidation). - Bring your own —
Embedder,MemoryStore, andAffectiveStateStoreare duck-typed protocols. Included stores:InMemoryStore,SQLiteStore(sqlite-vec ANN),QdrantStore,ChromaStore. Included affective-state stores: in-memory, SQLite, Redis (pass one asstate_store=for cross-session mood continuity). - Appraisal —
LLMAppraisalEngine(wrap any LLM callable) orKeywordAppraisalEngine(zero-dependency fallback); swap the Scherer CPM prompt for anyAppraisalSchema(OCC, GRID, custom) — see the custom-appraisal tutorial. - Async —
as_async()wraps a sync engine;SyncToAsyncEmbedder/SyncToAsyncStore/SyncToAsyncAppraisalEnginebridge sync I/O. See the async tutorial. - Query routing — a pluggable
QueryClassifierselects per-query-type retrieval weights (HeuristicQueryClassifier+LOCOMO_ROUTING, orLLMQueryClassifier). See the query-routing tutorial.
For how the modules compose into the pipeline, see Module Overview.
Use retrieve() for normal recall; retrieve_with_explanations() exposes the per-signal
ranking decomposition (semantic, mood, affect, momentum, recency, resonance)
for debugging, evaluation, or UI inspection. Both engines support context managers:
with EmotionalMemory(store=SQLiteStore("mem.db"), embedder=MyEmbedder()) as em:
em.encode("Session start")
results = em.retrieve("relevant context")
# SQLiteStore.close() called automatically
Visualization
The optional viz extra provides 8 plotting functions for inspecting and presenting the model's internals. Each function accepts an optional ax parameter for subplot composition and returns a matplotlib.Figure.
from emotional_memory.visualization import plot_circumplex, plot_decay_curves
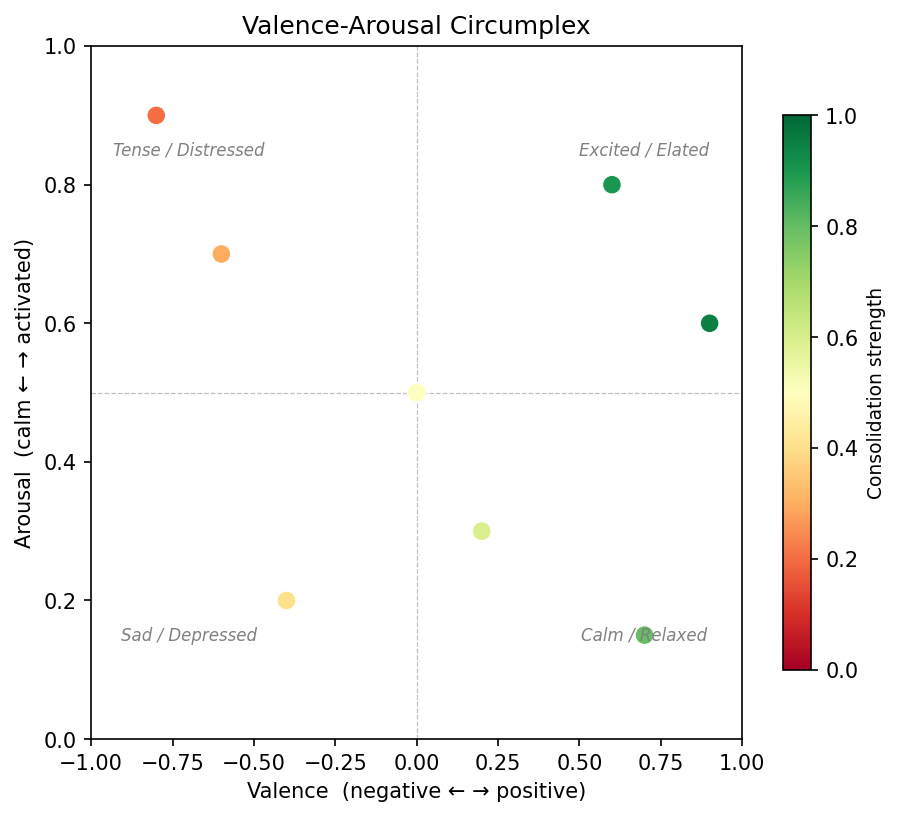
Valence-Arousal Circumplex
Memories plotted on the Russell-Mehrabian PAD model (valence-arousal plane), colored by consolidation strength.
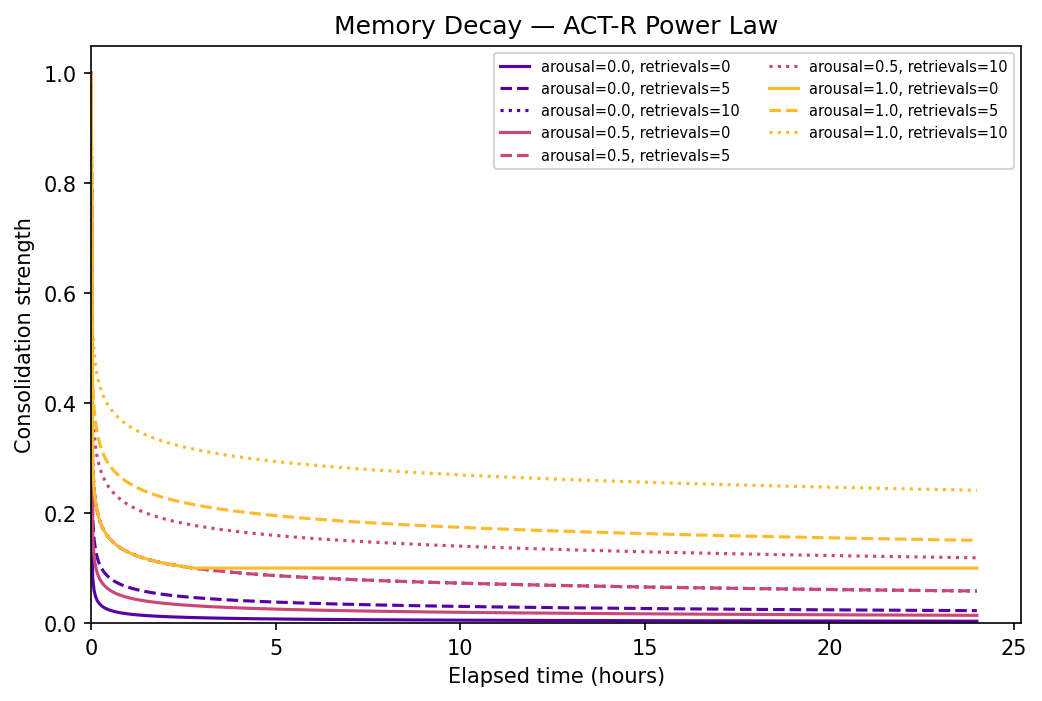
Decay Curves (ACT-R Power Law)
Family of curves showing how arousal (McGaugh 2004) and retrieval count (spacing effect) modulate memory decay.
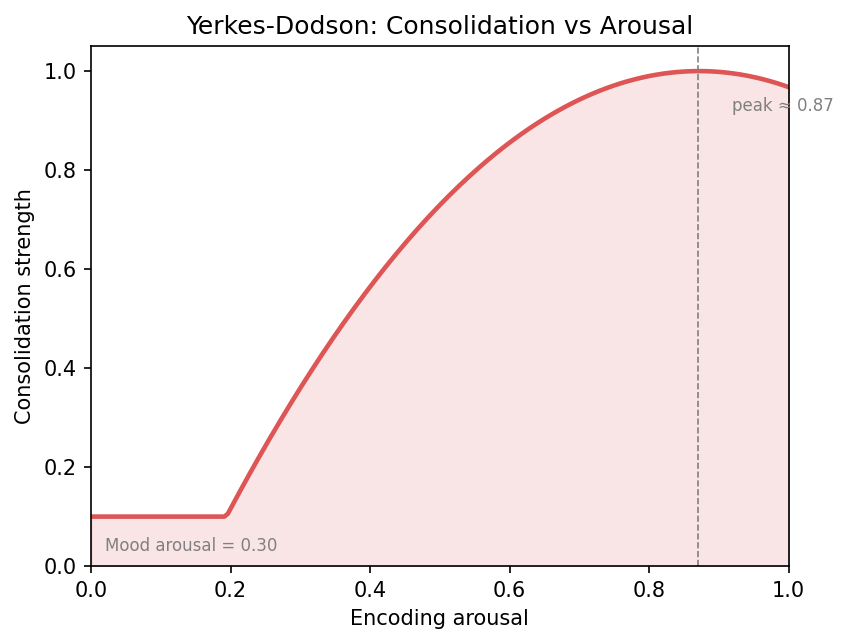
Yerkes-Dodson Inverted-U
Consolidation strength peaks near effective arousal 0.7, then drops — the classic Yerkes-Dodson curve.
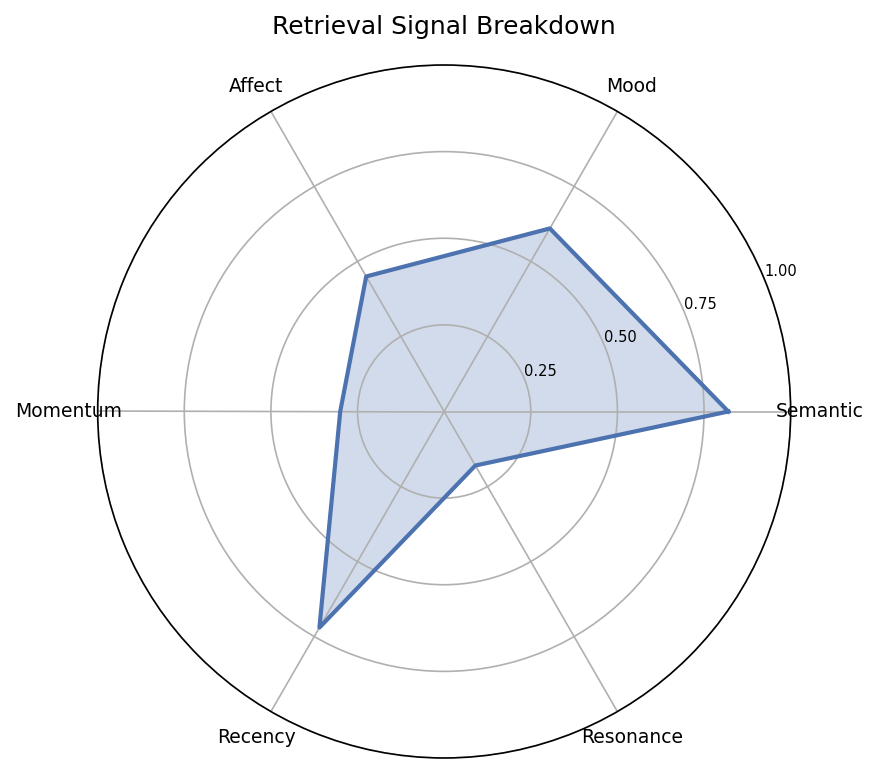
6-Signal Retrieval Breakdown
Radar chart of the six retrieval signals: semantic similarity, mood congruence, affect proximity, momentum alignment, recency, and resonance boost.
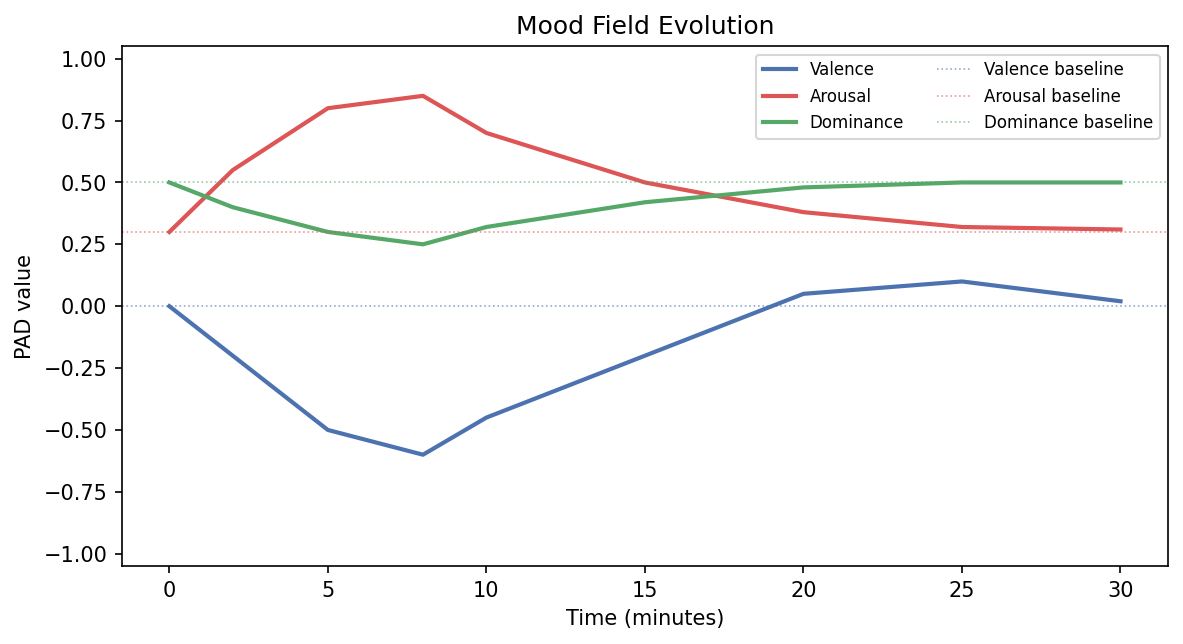
Mood Field Evolution
Time series of valence, arousal, and dominance with dashed baselines showing the regression attractors.
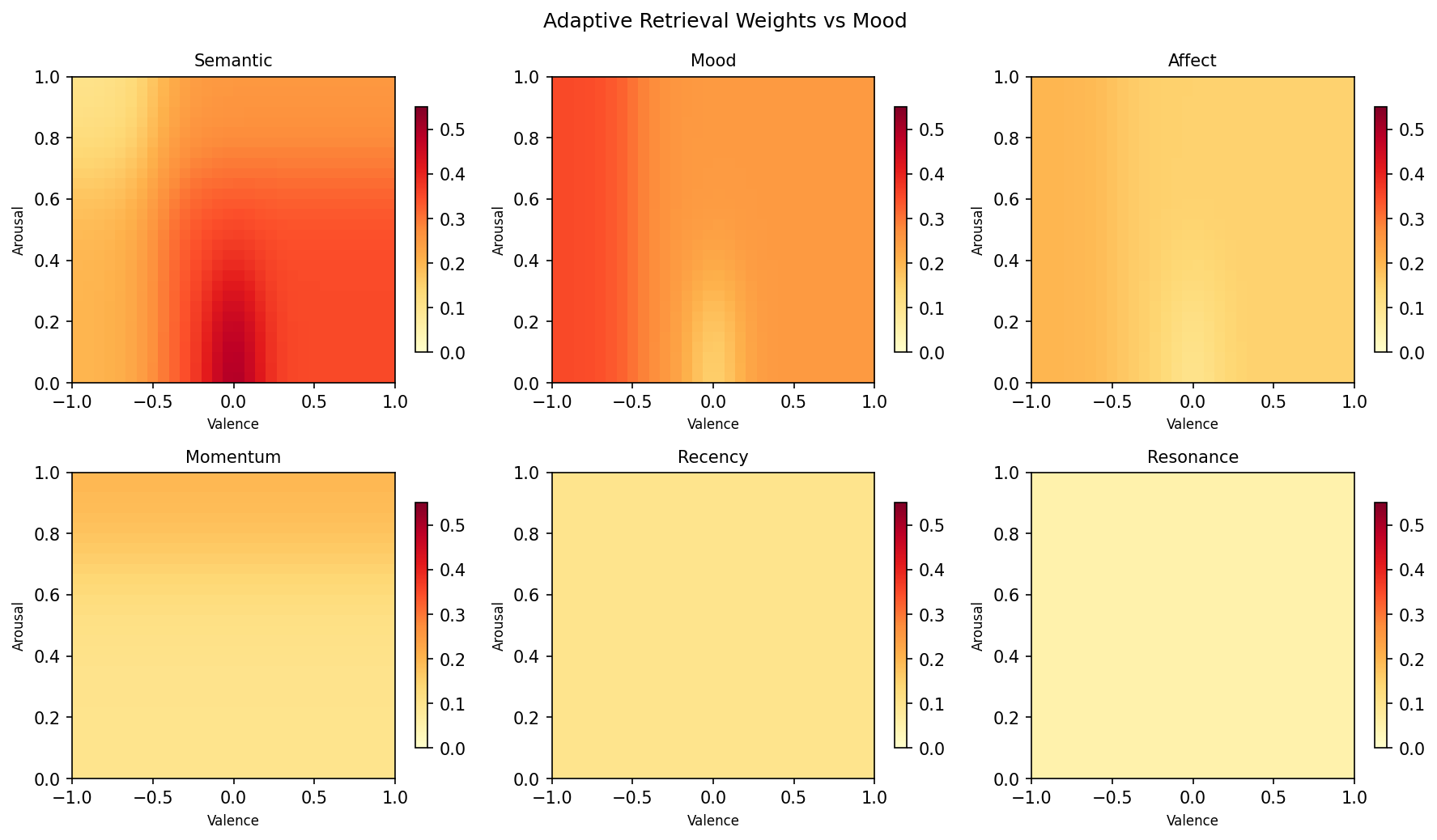
Adaptive Retrieval Weights
Heatmap showing how retrieval weights shift across different mood states (valence x arousal grid).
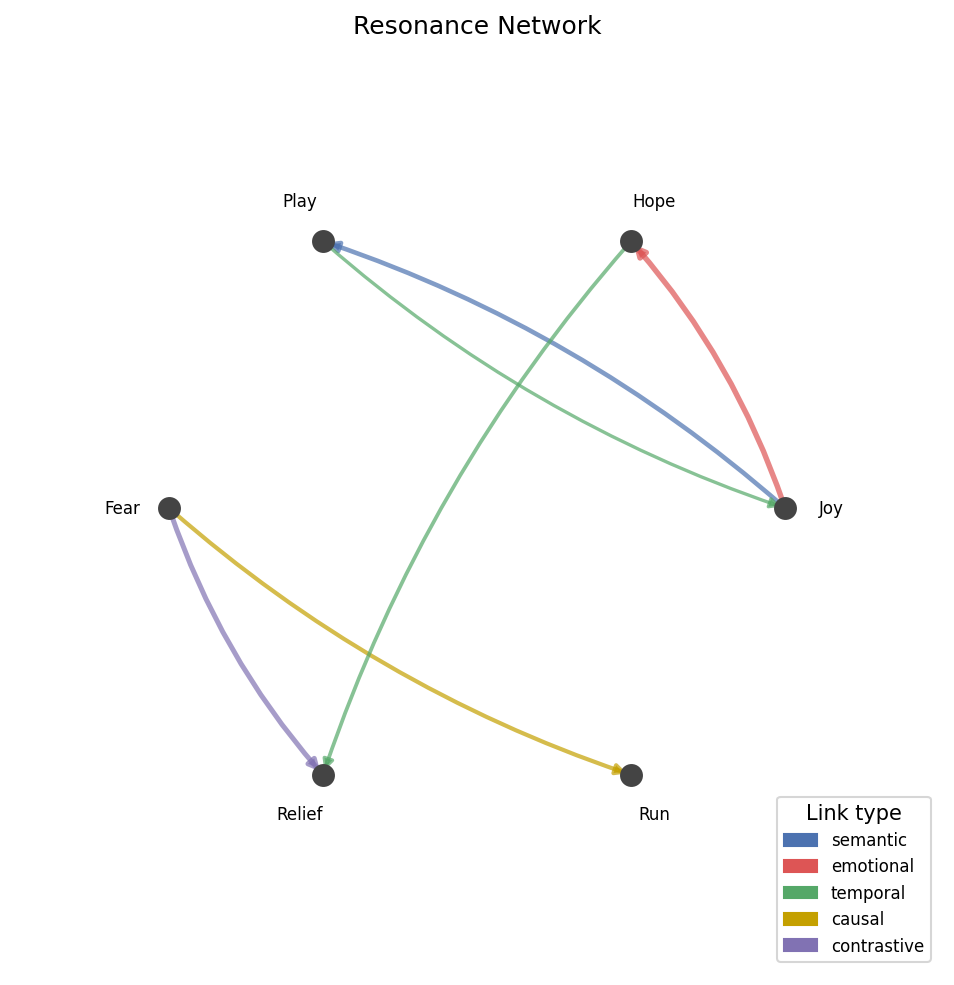
Resonance Network
Directed graph with memories as nodes and edges colored by link type (semantic, emotional, temporal, causal, contrastive).
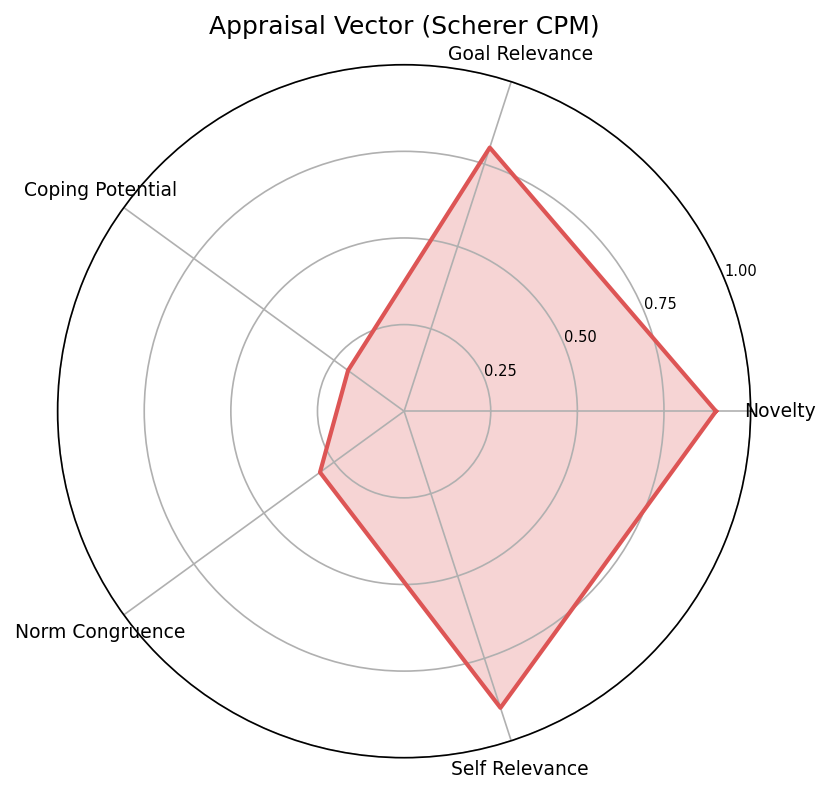
Appraisal Radar (Scherer CPM)
Spider chart of the 5 Stimulus Evaluation Check dimensions.
Generating images
make docs-images # regenerate all PNGs in docs/images/
make research-figures # regenerate benchmark evidence figures
Evidence Figures
The research figures below are generated from committed benchmark JSON artefacts, not from rerunning long studies.
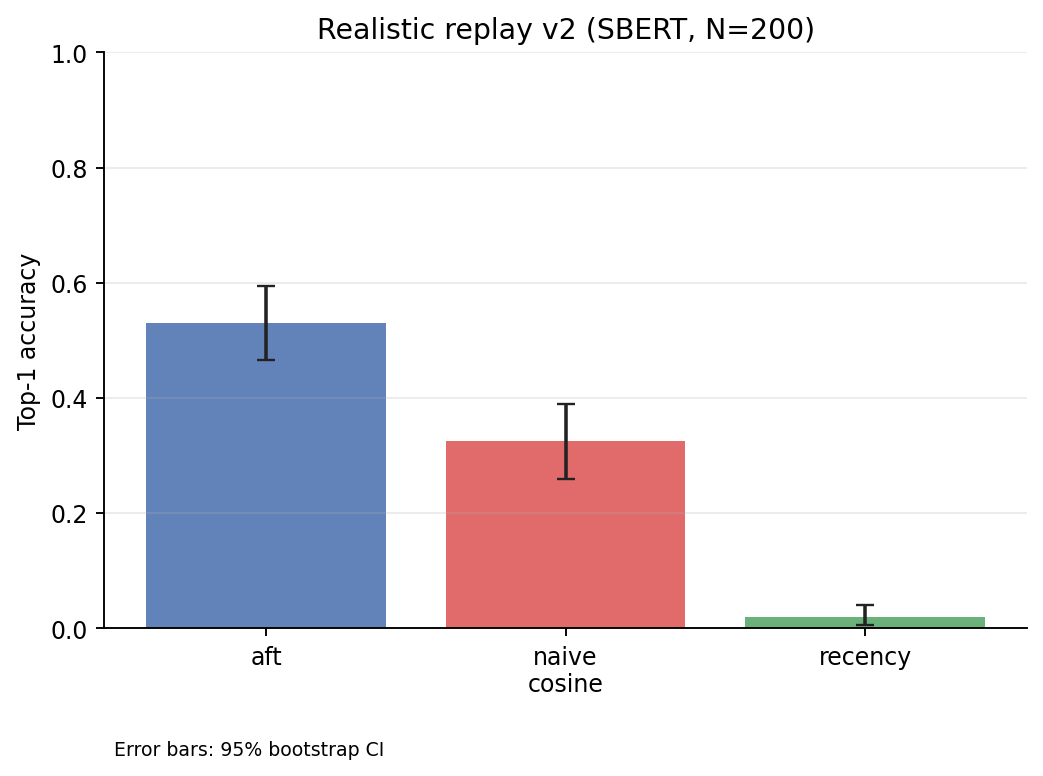
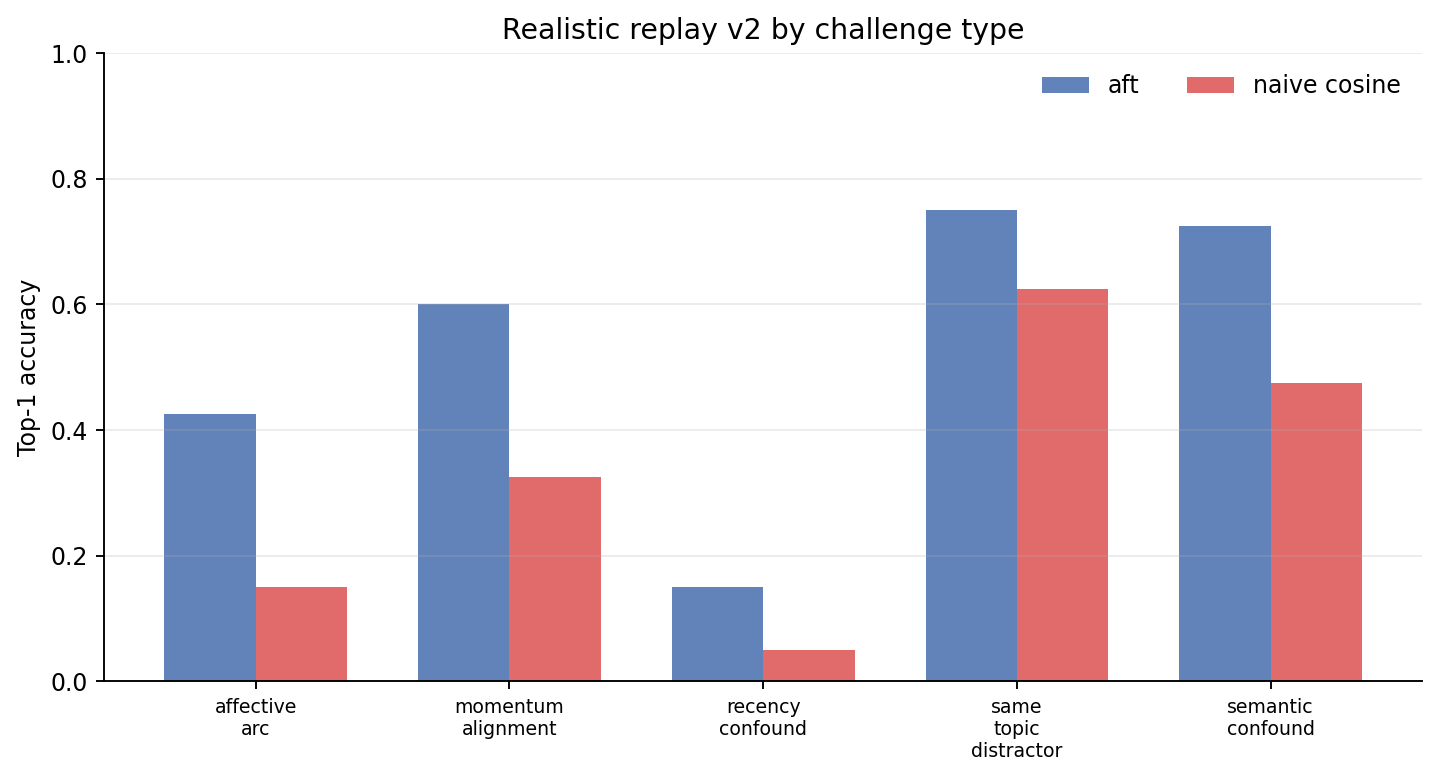
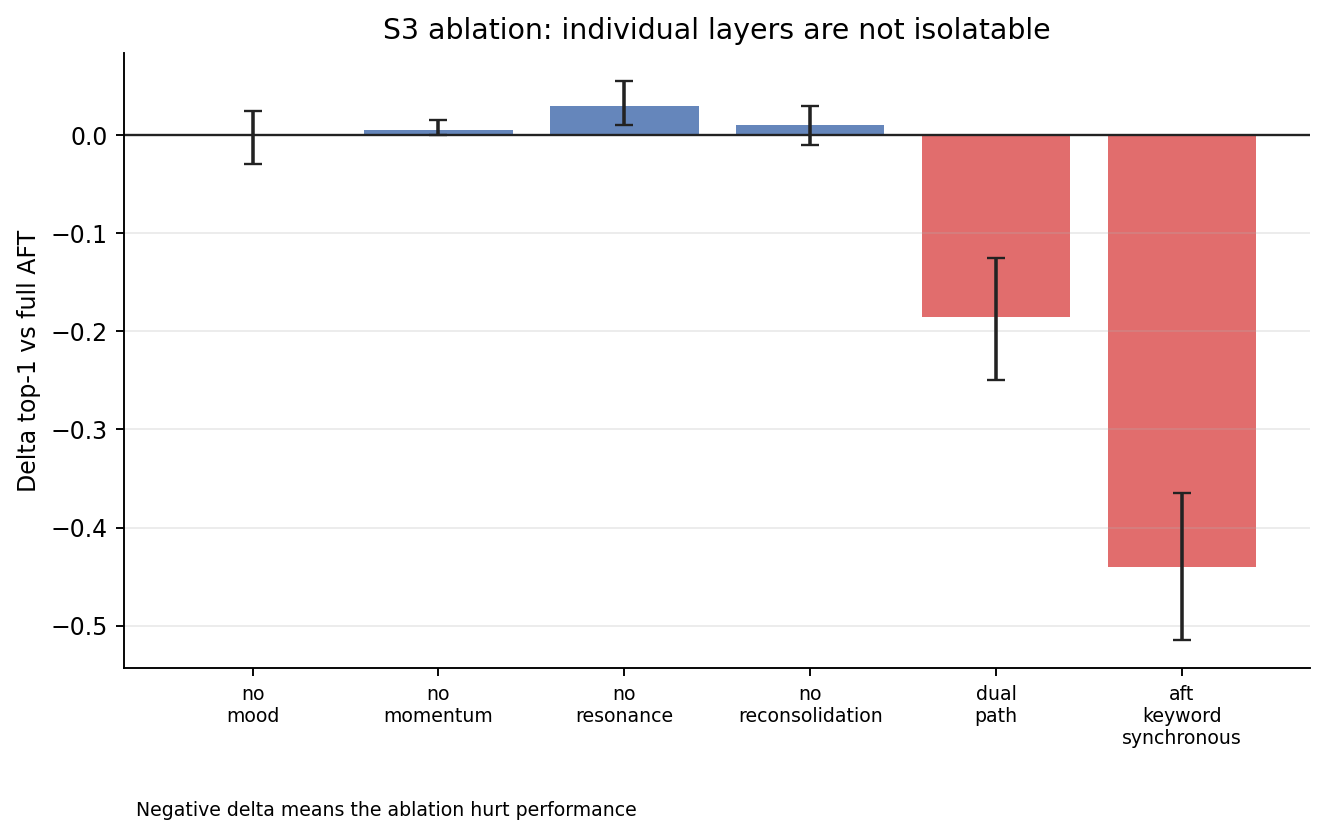
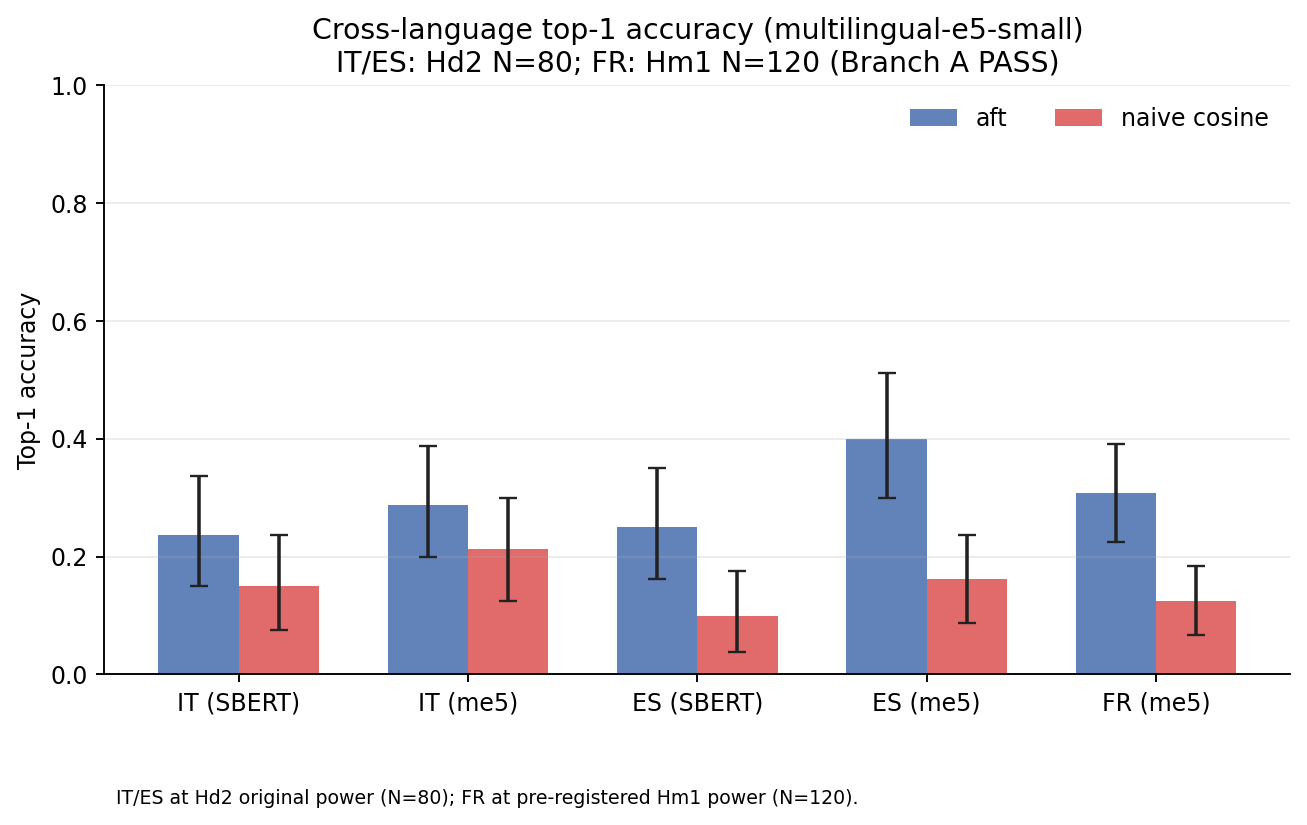
Comparison
emotional_memory is a focused affective-memory primitive, not a general-purpose memory
framework. For a feature-by-feature table against Mem0, Letta, Zep, and LangChain Memory,
see Comparison with Existing Systems; the "How it compares" table
above gives the one-line summary.
Validation & Benchmarks
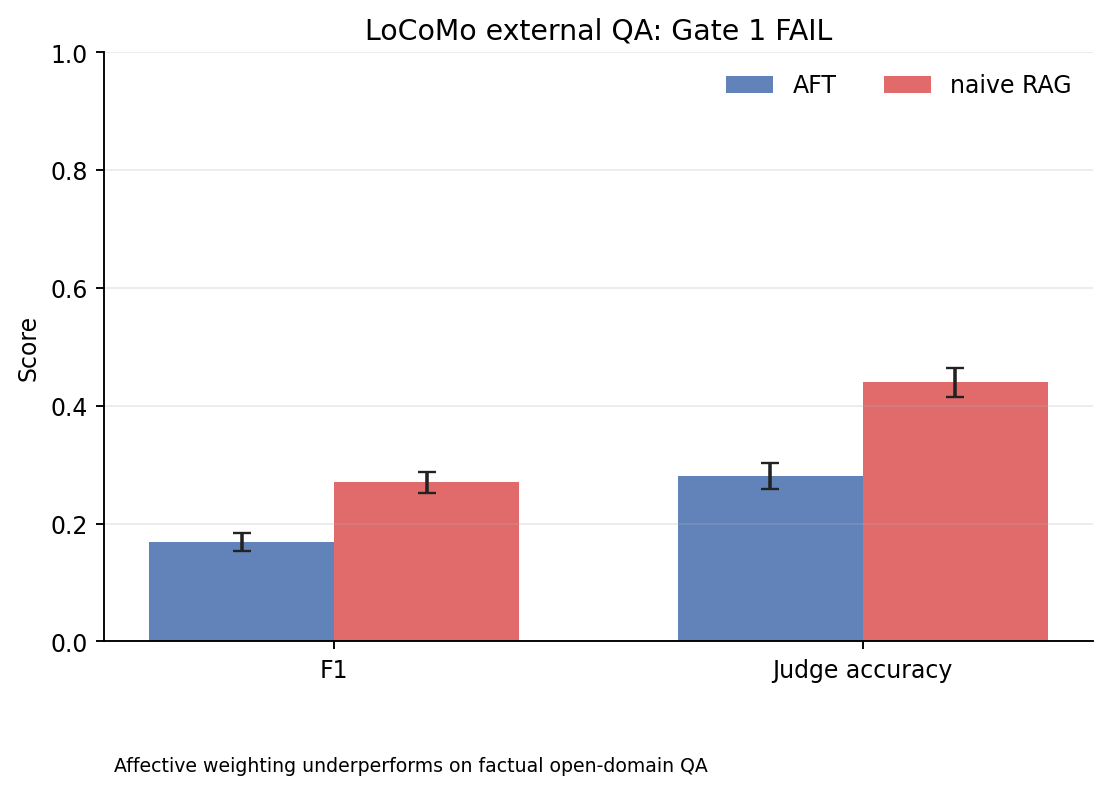
AFT is validated against 20 published psychological phenomena (127 fidelity tests) and 12+ pre-registered confirmatory studies, including committed negative results. On affect-discriminative recall the advantage is real and embedder-robust (English N=200, SBERT Δ=+0.21, d=0.49; French N=120, me5, Δ=+0.18, p<0.0001) — but it does not generalize: external QA (LoCoMo F1 0.168 vs 0.271), naturalistic dialogue (DailyDialog), end-to-end LLM appraisal (Hg1/Addendum P), query-type routing (Addendum L), and per-query affect gating (Addendum Q — gating recovers the always-on penalty but cannot exceed cosine) all FAIL. The AFT advantage is regime-specific to affect-discriminative recall, not a general superiority claim.
Oracle-affect boundary: results measured with preset valence/arousal injected at encode time (oracle affect, appraisal bypassed) measure a different regime from end-to-end runs. The
requires_oracle_affectfield in the claim-validation matrix encodes this per claim.
- Current Evidence — study ladder and claim-to-evidence matrix
- Benchmarks — fidelity (20 phenomena), performance, and appraisal-quality suites
- Machine-readable claims:
docs/research/claim_validation_matrix.json
Current validation status
The advantage is regime-specific, not a general superiority claim: controlled evidence on
realistic_recall_v2 under oracle affect (EN/FR), with committed negative results on
external QA (LoCoMo) and naturalistic dialogue (DailyDialog), and automatic LLM appraisal not
yet recovering the oracle-affect advantage. The authoritative per-claim status — including which
claims require oracle affect and which are falsified — is the
current claim-to-evidence matrix: docs/research/claim_validation_matrix.json.
Production readiness
Trusted Publishing (OIDC), SLSA Level 3 provenance, CycloneDX SBOM, PEP 740 signed
attestations, CodeQL SAST, pip-audit, SHA-pinned actions, mypy strict, and ≥80% branch
coverage on every release. Details and the gh attestation verify recipe:
Production Readiness.
mem0 integration
EmotionalMemoryMem0Backend exposes the mem0 Memory API (add / search / get_all /
delete / delete_all / reset / close) backed by the full AFT retrieval pipeline.
No runtime mem0ai dependency is required — it's always available:
uv pip install "emotional-memory[sentence-transformers]"
from emotional_memory import EmotionalMemory, InMemoryStore
from emotional_memory.embedders import SentenceTransformerEmbedder
from emotional_memory.integrations import EmotionalMemoryMem0Backend
em = EmotionalMemory(store=InMemoryStore(), embedder=SentenceTransformerEmbedder())
backend = EmotionalMemoryMem0Backend(em, default_user_id="alice")
backend.add([{"role": "user", "content": "I had a wonderful day at the park."}])
results = backend.search("outdoors positive experiences")
print(results["results"][0]["memory"])
The backend stores memories verbatim. For LLM-based fact extraction, chain a real mem0.Memory
instance as a pre-processor and store its extracted facts here. See
the mem0 tutorial for the chain pattern.
LangChain integration
EmotionalMemoryChatHistory is a drop-in replacement for any LangChain chat history object.
It backs the transcript with an EmotionalMemory instance so the affective state evolves
naturally as the conversation unfolds, while letting you control which messages become
retrievable memories.
uv pip install "emotional-memory[langchain,sentence-transformers]"
from emotional_memory import EmotionalMemory, InMemoryStore
from emotional_memory.embedders import SentenceTransformerEmbedder
from emotional_memory.integrations import (
EmotionalMemoryChatHistory,
recommended_conversation_policy,
)
em = EmotionalMemory(
store=InMemoryStore(),
embedder=SentenceTransformerEmbedder(),
)
history = EmotionalMemoryChatHistory(em, message_policy=recommended_conversation_policy)
# Works anywhere BaseChatMessageHistory is accepted:
history.add_user_message("I'm anxious about the deadline.")
history.add_ai_message("Let's break the work into smaller steps.")
print(history.messages) # [HumanMessage(...), AIMessage(...)]
# The underlying engine has tracked the affective state:
state = em.get_state()
print(f"valence={state.core_affect.valence:.2f} arousal={state.core_affect.arousal:.2f}")
With recommended_conversation_policy, user messages become retrievable memories, assistant
messages update affective state without being stored, and control commands such as
recall ... are ignored by retrieval. The adapter uses dependency injection — pass a
fully-configured EmotionalMemory so you control the store backend and embedder.
clear() removes stored memories, clears the transcript, and resets affective state.
Logging & Observability
The library uses the standard logging module. Enable debug output to trace the full pipeline:
import logging
logging.basicConfig(level=logging.DEBUG)
# or just for emotional_memory:
logging.getLogger("emotional_memory").setLevel(logging.DEBUG)
Debug events include: encode start/stored/resonance, retrieve start/done, reconsolidation triggers, LLM appraisal cache hits, and fallback activations.
A convenience helper configures the root logger with sensible defaults, optional JSON formatting, and environment-variable level control:
from emotional_memory import configure_logging
configure_logging(level="DEBUG") # or "INFO", "WARNING", "ERROR"
# JSON output for production pipelines:
configure_logging(level="INFO", json_format=True)
Set the level via environment variable without code changes:
EMOTIONAL_MEMORY_LOG_LEVEL=DEBUG uv run python my_script.py
OpenTelemetry tracing
Install the optional [otel] extra to get distributed spans on every engine operation:
uv pip install "emotional-memory[otel]"
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from opentelemetry.sdk.trace.export.in_memory_span_exporter import InMemorySpanExporter
provider = TracerProvider()
exporter = InMemorySpanExporter()
provider.add_span_processor(SimpleSpanProcessor(exporter))
# wire to your OTLP/Jaeger/Zipkin backend instead of InMemorySpanExporter
from opentelemetry import trace
trace.set_tracer_provider(provider)
# now all em.encode(), em.retrieve(), em.prune(), etc. emit spans automatically
Root spans are emitted for encode, retrieve, encode_batch, elaborate, observe, and
prune. Child spans cover individual embed and store.search_by_embedding calls.
Without the [otel] extra, all tracing is zero-overhead no-op.
Examples
The examples/ directory contains runnable scripts covering the full API.
All scripts are self-contained and use a deterministic HashEmbedder so they run without
any ML dependencies.
| Script | Description | Extra |
|---|---|---|
basic_usage.py |
Encode/retrieve, reconsolidation, resonance links | — |
advanced_config.py |
ACT-R decay, mood regression, adaptive weights | — |
appraisal_engines.py |
Keyword, static, and custom appraisal rules | — |
reconsolidation.py |
Two-retrieval lability window (Nader & Schiller 2000) | — |
async_usage.py |
as_async(), SyncToAsync* adapters, encode_batch |
— |
persistence.py |
SQLiteStore, save/load state, export/import, prune | [sqlite] |
emotional_journal.py |
Multi-session journaling with full lifecycle | [sqlite] |
llm_appraisal.py |
LLM-backed appraisal via OpenAI-compatible API | openai |
httpx_llm_integration.py |
httpx LLMCallable, .env config, 7 API deep-dives |
httpx |
sentence_transformers_embedder.py |
SequentialEmbedder with real embeddings |
sentence-transformers |
visualization.py |
All 8 matplotlib plot types | [viz] |
resonance_network.py |
Resonance graph and link-type distribution | [viz] |
retrieval_signals.py |
6-signal decomposition, radar chart, weight heatmap | [viz] |
Run any script: uv run python examples/<script>.py
Development
make check # lint + typecheck + test
make cov # tests with branch coverage report
make bench # fidelity + performance benchmarks
# Real-LLM tests (require API key):
make llm-config # print resolved LLM config (no secrets)
make test-llm # end-to-end integration tests
make bench-appraisal # Scherer CPM prompt quality benchmarks
LLM test environment variables
| Variable | Default | Purpose |
|---|---|---|
EMOTIONAL_MEMORY_LLM_API_KEY |
— | API key (required) |
EMOTIONAL_MEMORY_LLM_BASE_URL |
https://api.openai.com/v1 |
OpenAI-compatible endpoint |
EMOTIONAL_MEMORY_LLM_MODEL |
gpt-5-mini |
Model |
EMOTIONAL_MEMORY_LLM_REASONING_EFFORT |
"" |
Reasoning budget for o-series / gpt-5 models (minimal / low / medium / high); omitted when empty |
EMOTIONAL_MEMORY_LLM_OUTPUT_MODE |
plain |
LLM response mode: plain or json_object |
EMOTIONAL_MEMORY_LLM_TIMEOUT_SECONDS |
30 |
HTTP timeout for OpenAI-compatible calls |
EMOTIONAL_MEMORY_LLM_REPEATS |
3 |
Repeats per phrase in quality benchmarks |
Full reference: LLM Environment Variables.
Citing
If you use emotional-memory in research, please cite:
@software{mazza_emotional_memory_2026,
author = {Mazza, Gianluca},
title = {{emotional-memory: Affective Field Theory for LLM Memory}},
year = {2026},
version = {0.11.4},
doi = {10.5281/zenodo.20634961},
url = {https://github.com/gianlucamazza/emotional-memory},
license = {MIT},
}
- Concept DOI (all versions): 10.5281/zenodo.19972258
- Paper draft (PDF) — Affective Field Theory: A Multi-Layer Model for Emotion-Aware Memory in LLMs
- arXiv-ready bundle:
paper/arxiv-submission.tar.gz - Pre-registration corpus:
benchmarks/preregistration*.md
License
MIT — see LICENSE
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file emotional_memory-0.11.4.tar.gz.
File metadata
- Download URL: emotional_memory-0.11.4.tar.gz
- Upload date:
- Size: 90.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9c903af527acc0762d90db2154ecc7575ca3a592a6eb898f0c6dbfa77a84a7b6
|
|
| MD5 |
ba3cd136f200f9203f54cc70a3e329df
|
|
| BLAKE2b-256 |
86999442b8363b6e3835fb04e30829d6c4b213fdc9812858c12985d622f7d35b
|
Provenance
The following attestation bundles were made for emotional_memory-0.11.4.tar.gz:
Publisher:
release.yml on gianlucamazza/emotional-memory
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
emotional_memory-0.11.4.tar.gz -
Subject digest:
9c903af527acc0762d90db2154ecc7575ca3a592a6eb898f0c6dbfa77a84a7b6 - Sigstore transparency entry: 1785588534
- Sigstore integration time:
-
Permalink:
gianlucamazza/emotional-memory@35790d7f4d36ec2bc443998df26fa5fb4ad219df -
Branch / Tag:
refs/tags/v0.11.4 - Owner: https://github.com/gianlucamazza
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@35790d7f4d36ec2bc443998df26fa5fb4ad219df -
Trigger Event:
push
-
Statement type:
File details
Details for the file emotional_memory-0.11.4-py3-none-any.whl.
File metadata
- Download URL: emotional_memory-0.11.4-py3-none-any.whl
- Upload date:
- Size: 109.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f1c793897a35ca6665333a55fd65c78eb1abba411e7210f174a68aa35ff98e7e
|
|
| MD5 |
ef20e9666f9752a881246cf90cf409cf
|
|
| BLAKE2b-256 |
f51019e039627b40a6ef8a709767f9e7d140bd8b7cfe1a83f4a9a00ff4f17624
|
Provenance
The following attestation bundles were made for emotional_memory-0.11.4-py3-none-any.whl:
Publisher:
release.yml on gianlucamazza/emotional-memory
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
emotional_memory-0.11.4-py3-none-any.whl -
Subject digest:
f1c793897a35ca6665333a55fd65c78eb1abba411e7210f174a68aa35ff98e7e - Sigstore transparency entry: 1785588571
- Sigstore integration time:
-
Permalink:
gianlucamazza/emotional-memory@35790d7f4d36ec2bc443998df26fa5fb4ad219df -
Branch / Tag:
refs/tags/v0.11.4 - Owner: https://github.com/gianlucamazza
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@35790d7f4d36ec2bc443998df26fa5fb4ad219df -
Trigger Event:
push
-
Statement type:







