AI memory system with hybrid search, git-aware ingestion, and garbage collection
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

EngramKit
AI memory system with hybrid search, git-aware ingestion, and garbage collection.
EngramKit gives AI assistants long-term memory over your codebase. Mine a repository once, then search it with sub-200ms hybrid queries that combine semantic understanding with exact keyword matching. Built as a next-generation replacement for MemPalace, keeping what works and fixing what doesn't.
Standing on MemPalace's Shoulders
MemPalace proved several important ideas:
- Verbatim storage works. Never summarize, always store raw text. Let semantic search find what's relevant.
- 4-layer memory stack (L0 identity, L1 essential, L2 on-demand, L3 deep search) is a sound architecture for token-budgeted context.
- MCP integration makes the memory system usable from Claude, ChatGPT, and other assistants.
Note on benchmarks: MemPalace's headline 96.6% R@5 on LongMemEval actually measures ChromaDB's embedding model (all-MiniLM-L6-v2), not the palace architecture. The test bypasses wings, rooms, and AAAK compression entirely. Any app using ChromaDB with the same model would get the same score. See the community discussion for details.
EngramKit preserves MemPalace's core ideas. What it changes is the engineering underneath.
What EngramKit Fixes
| Problem in MemPalace | EngramKit's Solution |
|---|---|
Positional chunk IDs (MD5(path+index)) break when files are edited |
Content-addressed IDs: SHA256(content)[:24] |
| No garbage collection -- orphaned chunks stay forever | Generation-based mark-and-sweep GC with configurable retention |
| Sequential 1-at-a-time ChromaDB upserts | Per-file streaming upserts (94s vs MemPalace 115s, same repo) |
| Semantic-only search | Hybrid search: semantic + BM25 via SQLite FTS5, fused with RRF |
| No git awareness -- full rescan every time | git diff incremental mining; re-mine in 0.1s when nothing changed |
.env files indexed with secrets |
Auto-filters secret files and scans chunks for credential patterns |
| Dumb hooks (count to 15, then save) | Content-aware importance scoring with signal detection |
| Importance-only L1 scoring | Recency decay + importance + access frequency |
len // 4 token counting |
Exact counting via tiktoken (cl100k_base) |
| No deduplication | Deduplication by content hash + near-duplicate prefix detection |
| 10k drawer status cap (in-memory dict) | SQLite metadata spine -- no cap, survives restarts |
Features
- Hybrid search -- Semantic (ChromaDB) + lexical (SQLite FTS5 BM25), fused with Reciprocal Rank Fusion. 15x faster than semantic-only.
- Git-aware mining -- Uses
git diffto detect changed files. Only re-processes what actually changed. - Content-addressed storage -- Chunks are keyed by
SHA256(content). Edit a file and only the changed chunks get updated. - Generation-based GC -- Stale chunks are marked, not deleted. GC sweeps them after a configurable retention period.
- Secret filtering --
.env,.pem, credential files are auto-excluded. Individual chunks are scanned for API keys, tokens, and passwords. - 4-layer memory stack -- L0 identity, L1 essential context (recency + importance scored), L2 on-demand recall, L3 hybrid search.
- Token budgets -- Each layer has a configurable token budget. Chunks are scored, deduplicated, and packed greedily.
- Knowledge graph -- Temporal entity-relationship graph with
valid_from/valid_tofor tracking how things change over time. - MCP server -- 12 tools for Claude, ChatGPT, and other MCP-compatible assistants.
- REST API -- FastAPI backend powering the dashboard (search, chat, vaults, KG, memory).
- Next.js dashboard -- Web UI with RAG chat, search, vault management, knowledge graph explorer, and GC controls.
- Git hooks -- Auto-mine on commit and pull with
engramkit hooks install.
Architecture

~/.engramkit/
├── config.toml (optional global config)
├── identity.txt (L0 identity context)
└── vaults/<repo-hash>/
├── meta.sqlite3 (chunks + FTS5 + files + GC log)
├── vectors/ (ChromaDB embeddings)
└── knowledge_graph.sqlite3
Each repository gets its own vault, identified by a deterministic hash of the repo path. The SQLite database is the metadata spine: it stores chunk content, file tracking, generation counters, access stats, and a full-text search index. ChromaDB handles the vector embeddings. The knowledge graph lives in a separate SQLite database per vault.
Quick Start
# Install (core: CLI, MCP, REST API, dashboard, hybrid search)
pipx install engramkit
# Optional — enables the RAG chat feature inside the dashboard
pipx install 'engramkit[chat]' --force # requires Python 3.10+
# Mine a project
engramkit mine ~/my-project
# Search it
engramkit search "how does auth work"
# Open the web dashboard
engramkit dashboard
# Check status
engramkit status
What's in each install?
engramkit— everything except RAG chat: CLI, MCP server, REST API, web dashboard, hybrid search, knowledge graph, GC.engramkit[chat]— adds the Claude Agent SDK so the dashboard's chat panel can answer questions over your vault. Needs Python ≥ 3.10.
Claude Code Integration
Three commands — two in the terminal, two in Claude Code — then memory runs itself.
1. Install the Python package (once per machine)
pipx install engramkit
This provides the engramkit CLI and the engramkit-mcp binary the plugin will call.
2. Install the Claude Code plugin (once per user)
Inside any claude session, type:
/plugin marketplace add hmqiwtCode/engramkit
/plugin install engramkit@engramkit
This registers the MCP server and the SessionStart / Stop / PreCompact hooks. No settings.json to hand-edit.
3. Index a project (once per project)
cd ~/your-project
engramkit mine .
claude # memory auto-loads on session start
From here, every Claude session in that project is primed with the project's memory before you type a single word.
Upgrading
pipx upgrade engramkit # if you installed with pipx
pip install --upgrade engramkit # if you installed with pip
Pin to a specific version with engramkit=={version} (e.g. engramkit==0.1.4). See releases for what shipped in each version.
Verify it's working
Shell check (runs the hook directly and tells you what Claude will see):
echo '{}' | engramkit-hook session-start | python3 -c "import json,sys; ctx=json.load(sys.stdin).get('hookSpecificOutput',{}).get('additionalContext',''); print(f'✓ injected {len(ctx)} chars') if ctx else print('✗ empty — no vault for this dir, or upgrade needed')"
✓ injected <N> chars— the hook is producing context. Claude will receive the same text at every session start.✗ empty— either the current directory doesn't have a mined vault (engramkit mine .), or you're on a version older than 0.1.4 (pip install --upgrade engramkit).
In-Claude check (paste this into a fresh claude session inside a mined project):
Run this full diagnostic in order and report each result:
1. Did you receive an `additionalContext` block labeled "EngramKit memory" at session start?
If yes, quote the first 200 characters verbatim. If no, say "no injection".
2. Call the MCP tool `engramkit_status` and show the exact JSON. If it errors, show the error.
3. Call `engramkit_search` with query "decisions" and n_results: 3. Report how many chunks came back.
4. Based on 1-3, is engramkit fully working, partially working (which part), or not working?
Expected results:
- Q1 — a real quote from your vault → SessionStart injection fired ✓
- Q2 — JSON containing
total_drawers,wings, and aprotocolfield → MCP + protocol wired ✓ - Q3 —
3chunks → hybrid search path works end-to-end ✓ - Q4 — "fully working" → you're done.
If Q1 fails but Q2/Q3 pass, the MCP server is fine but the SessionStart hook isn't firing. Usually a stale plugin install — refresh it with:
/plugin marketplace update engramkit
/plugin uninstall engramkit@engramkit
/plugin install engramkit@engramkit
Then fully quit and reopen Claude Code (close the app, not just the session) so hooks re-register at startup. Re-run the in-Claude diagnostic.
💡 Workaround if SessionStart still won't fire. Once per session, paste this to Claude: "Use engramkit to search for anything relevant to this project before we start." Claude will call
engramkit_searchvia MCP, receive theprotocolstring in the response, and from that point treat engramkit as its memory for the rest of the session. The MCP path works even when the hook doesn't — it's a single-message fallback until the plugin install is refreshed.
Prefer manual wiring?
If you don't want the plugin and would rather wire things up yourself:
engramkit hooks install -d . # installs git hooks + Claude Code hooks
claude mcp add engramkit -- engramkit-mcp # registers the MCP server
What runs when
| Moment | What fires | What it does |
|---|---|---|
You open claude in a mined project |
SessionStart hook → engramkit wake-up |
Reads identity + L1 essential context (~170 tokens) and injects it directly into Claude's context. No tool call needed — Claude starts the session already knowing the project. |
| You ask Claude a code or history question | Claude calls engramkit_search (hinted by the protocol baked into every engramkit_wake_up / engramkit_status response) |
Hybrid semantic + BM25 search across the vault, returns ranked chunks. |
| A meaningful decision, fix, or insight is discussed | Stop hook importance-scores the transcript |
When the score crosses threshold it blocks the stop event and tells Claude to engramkit_save before continuing — the conversation picks up immediately after. |
| Claude is about to compress context | PreCompact hook |
Blocks and tells Claude to save everything important now, before detail is lost. |
You never have to say "check engramkit" — the protocol + hooks do that for you.
Available Tools (12)
Read tools:
| Tool | Description |
|---|---|
engramkit_status |
Vault overview: chunks, wings, rooms, generation |
engramkit_search |
Hybrid search (semantic + BM25) across the vault |
engramkit_wake_up |
Load L0 + L1 wake-up context for session start |
engramkit_recall |
L2 on-demand recall filtered by wing/room |
engramkit_kg_query |
Query knowledge graph for entity relationships |
engramkit_kg_timeline |
Chronological timeline of knowledge graph facts |
Write tools:
| Tool | Description |
|---|---|
engramkit_save |
Save content to vault with auto content-hash dedup |
engramkit_kg_add |
Add a fact: subject -> predicate -> object |
engramkit_kg_invalidate |
Mark a knowledge graph fact as no longer valid |
engramkit_diary_write |
Write a diary entry (agent's personal journal) |
Admin tools:
| Tool | Description |
|---|---|
engramkit_gc |
Run garbage collection on stale chunks |
engramkit_config |
Get or set vault configuration |
CLI Reference
engramkit init <directory> [--wing NAME]
Initialize a vault for a repository. Sets up SQLite schema, ChromaDB collection, and stores the wing name.
engramkit mine <directory> [--wing NAME] [--room NAME] [--full] [--dry-run] [--ignore PATTERN ...]
Mine a project into its vault. Uses git diff for incremental mining when available. --full forces a complete rescan. --dry-run previews without storing.
--ignore takes gitignore-style patterns (the same syntax you already use in .gitignore). User-supplied patterns and the project's .gitignore are merged into one spec with identical precedence rules, including ! negation. Repeat the flag or comma-separate:
| Pattern | Meaning |
|---|---|
--ignore docs |
any folder named docs, at any depth (root or nested) |
--ignore /docs |
anchored to the project root only |
--ignore docs/ |
trailing slash restricts the match to directories |
--ignore lib/docs |
a slash in the middle anchors the pattern — only that exact path |
--ignore "lib/**" |
everything under lib/, recursively |
--ignore "*.log" |
any .log file, at any depth |
--ignore "!keep.md" |
negation — re-include something matched by an earlier pattern |
--ignore docs,examples |
shorthand for --ignore docs --ignore examples |
Pattern semantics are from Python's pathspec gitwildmatch matcher, which is what tools like pip, twine, black, and setuptools-scm use.
engramkit search <query> [-d DIRECTORY] [--wing NAME] [--room NAME] [-n COUNT]
Hybrid search across a vault. Returns ranked results with file paths, scores, and source indicators (semantic, lexical, or both).
engramkit status [-d DIRECTORY] [--all]
Show vault statistics: chunk counts, wings, rooms, generation number, stale/secret counts. --all lists every vault.
engramkit wake-up [-d DIRECTORY] [--wing NAME] [--l0-tokens N] [--l1-tokens N]
Load L0 + L1 wake-up context for a session. Token-budgeted and deduplicated.
engramkit gc [-d DIRECTORY] [--dry-run] [--retention DAYS]
Garbage collection. Removes stale chunks older than the retention period (default: 30 days). Logs all removals.
engramkit hooks install [-d DIRECTORY]
Install git hooks (post-commit, post-merge) for automatic mining on commit and pull.
Dashboard
The Next.js dashboard provides a web UI for interacting with EngramKit:
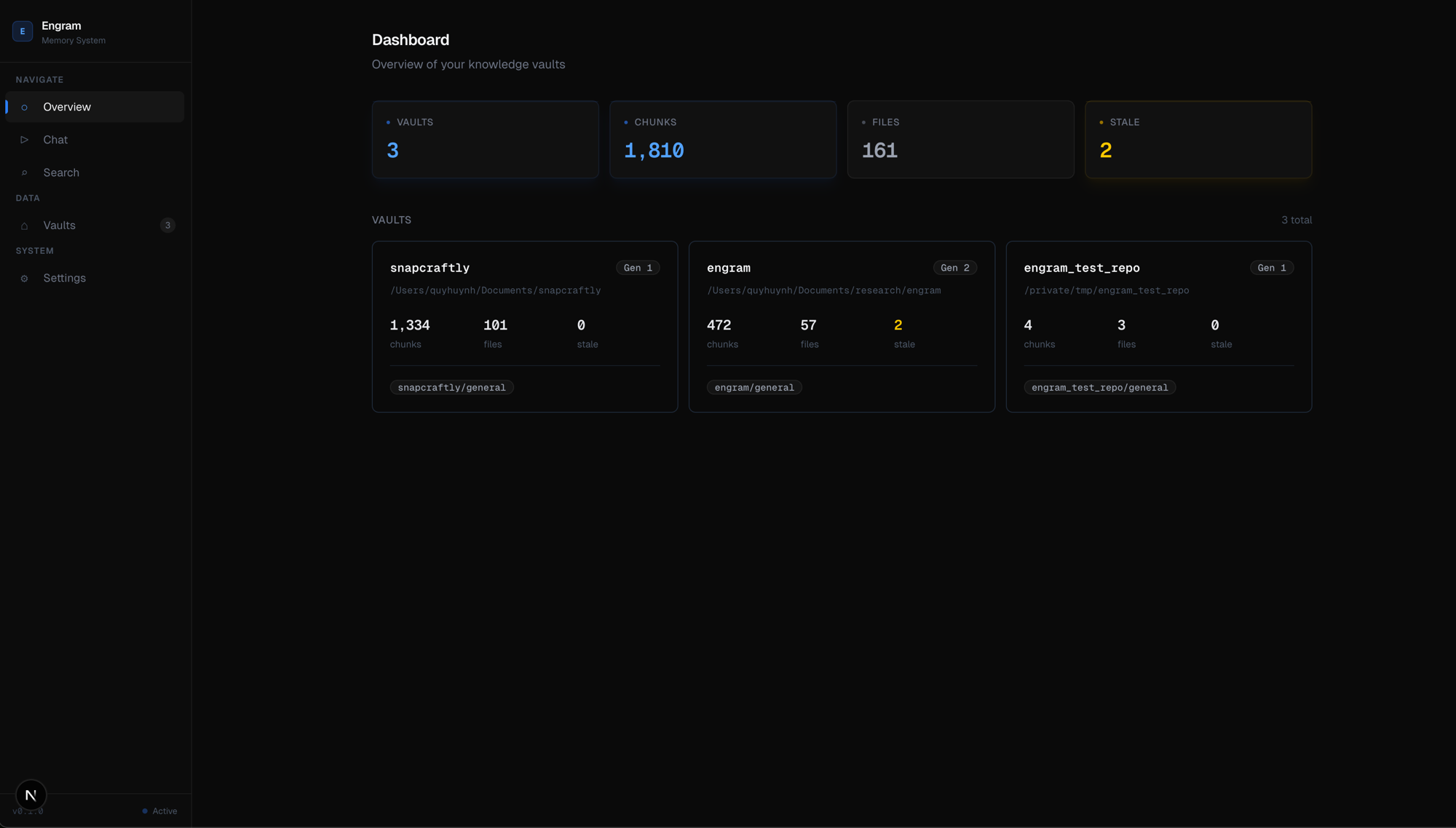
Dashboard — vault overview with stats, chunk counts, and wing/room breakdown
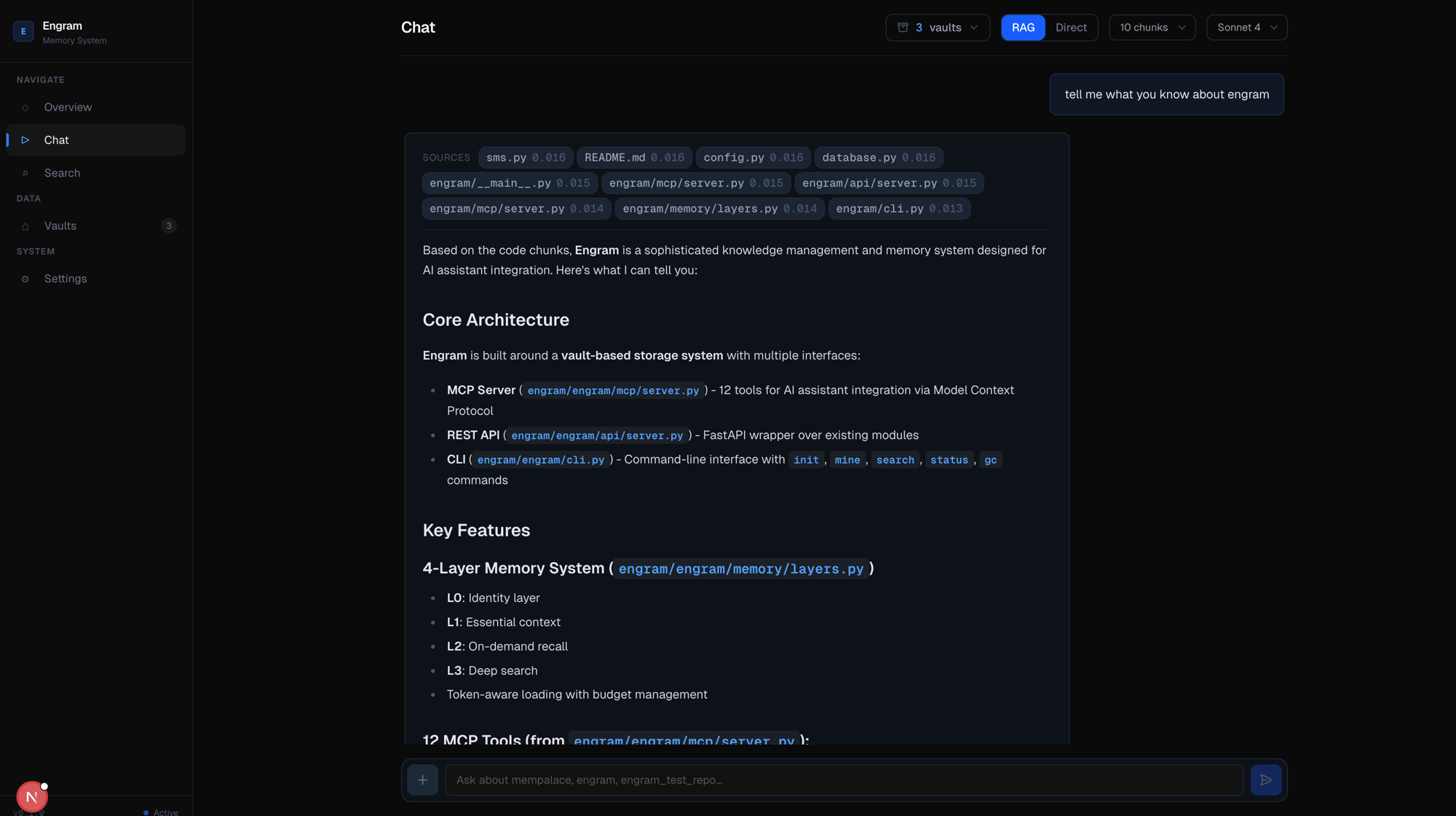
RAG Chat — search your codebase and ask questions with cited sources, token usage, and tool tracking
Features
- Chat — RAG-powered chat with Claude. Searches your vaults for context, streams responses with source references. Toggle between RAG (pre-searched context) and Direct (Claude explores on its own) to compare cost and speed.
- Search — Hybrid search with filters by wing, room, and result count. Shows which path found each result (semantic, lexical, or both).
- Vaults — Browse all vaults, view chunks, files, and statistics. Mine repos, run GC, install git hooks.
- Knowledge Graph — Explore entities, relationships, and timelines. Add and expire facts.
- Settings — Global configuration, token budgets, search weights.
Quick Start
# Install dashboard dependencies
cd dashboard && npm install
# Start both servers
python -m engramkit.api.server # API on :8000
npm run dev # Dashboard on :3000
The dashboard runs at http://localhost:3000 and talks to the API at http://localhost:8000.
Benchmark Results
Retrieval Accuracy (ConvoMem, 250 QA pairs)
Tested on the same ConvoMem dataset used by MemPalace. Three search modes compared:
| Mode | Avg R@10 | Perfect | Zero |
|---|---|---|---|
| EngramKit Hybrid (semantic + BM25) | 94.5% | 235/250 | 13/250 |
| Raw ChromaDB (semantic only) | 92.9% | 230/250 | 16/250 |
| BM25 only (keyword) | 84.3% | 210/250 | 38/250 |
Per-category breakdown:
| Category | Hybrid | Raw | BM25 |
|---|---|---|---|
| Assistant Facts | 100% | 100% | 100% |
| User Facts | 98.0% | 98.0% | 98.0% |
| Preferences | 92.0% | 86.0% | 68.0% |
| Implicit Connections | 91.3% | 89.3% | 65.7% |
| Abstention | 91.0% | 91.0% | 90.0% |
Hybrid search adds +1.6% over raw semantic on conversation data. On code search (function names, variable names), the gap is much larger.
Note: MemPalace reports 96.6% R@5 on LongMemEval, but that score measures ChromaDB's all-MiniLM-L6-v2 model — the palace architecture is not involved. Our benchmark tests the actual search pipeline end-to-end.
Mining & Search Performance
Head-to-head on the same repository (102 files):
| Metric | EngramKit | MemPalace | Delta |
|---|---|---|---|
| First mine | 94s | 115s | 1.2x faster |
| Re-mine (no changes) | 0.1s | 115s | 1,150x faster |
| Avg search latency | 153ms | 2,378ms | 15.6x faster |
| Search modes | Semantic + BM25 | Semantic only | -- |
| Content-addressed IDs | Yes (SHA256) | No (MD5+pos) | -- |
| Garbage collection | Yes | No | -- |
| Git-aware mining | Yes | No | -- |
| Secret filtering | Yes | No | -- |
| Token counting | tiktoken (exact) | len//4 (approx) | -- |
Run Benchmarks Yourself
# Retrieval accuracy (ConvoMem dataset)
python benchmarks/convomem_bench.py --limit 50 --mode all
# Mining & search performance
python benchmarks/compare_mempalace.py /path/to/repo
How It Works
Smart Chunking
Files are split into ~800 character chunks with boundary-aware splitting. The chunker prefers to break at blank lines (paragraph/function boundaries), then def/class definitions, then any newline. Chunks overlap by 100 characters to preserve context across boundaries.
Content-Addressed Storage
Every chunk is identified by SHA256(content)[:24]. This means:
- Identical content always maps to the same ID (deduplication for free).
- Editing a file only invalidates chunks whose content actually changed.
- Moving or renaming a file doesn't orphan its chunks.
Hybrid Search
Queries hit two indexes in parallel:
- Semantic search via ChromaDB (embedding similarity)
- Lexical search via SQLite FTS5 (BM25 ranking)
Results are merged using Reciprocal Rank Fusion (RRF) with configurable weights (default: 0.7 semantic, 0.3 lexical), then deduplicated by content hash and enriched with metadata from SQLite.
Generation-Based GC
Each mining run increments a generation counter. When a file changes, its old chunks are marked stale (not deleted). GC runs separately, removing stale chunks older than the retention period and logging every removal to the gc_log table.
Git-Aware Change Detection
On engramkit mine, if the repository is a git repo and a previous commit hash is stored:
- Run
git diff --name-status <last_commit> HEAD - Only process files with status A (added), M (modified), or R (renamed)
- Mark files with status D (deleted) as deleted in the vault
- Store the new HEAD commit for next time
If nothing changed, re-mining completes in ~0.1 seconds.
Token Budget with Recency Scoring
L1 context loading scores each chunk by:
- Importance (1-5 scale, default 3)
- Recency decay (exponential, half-life ~7 days)
- Access frequency (logarithmic boost)
Chunks are sorted by score, near-duplicates are removed (Jaccard similarity on character trigrams), and the top chunks are greedily packed into the token budget.
Project Structure
engramkit/
├── engramkit/ # Python package (~3,400 lines)
│ ├── cli.py # CLI: init, mine, search, status, gc, hooks
│ ├── config.py # Configuration and defaults
│ ├── api/ # FastAPI REST API
│ │ ├── server.py # App setup with CORS
│ │ ├── routes_search.py # /search endpoint
│ │ ├── routes_vaults.py # /vaults CRUD
│ │ ├── routes_memory.py # /memory wake-up and recall
│ │ ├── routes_kg.py # /kg knowledge graph
│ │ ├── routes_chat.py # /chat RAG endpoint
│ │ └── helpers.py # Shared utilities
│ ├── ingest/ # Mining pipeline
│ │ ├── pipeline.py # Orchestrator: scan, chunk, diff, store
│ │ ├── chunker.py # Smart 800-char chunker
│ │ ├── git_differ.py # Git-aware change detection
│ │ └── secret_scanner.py # Credential detection
│ ├── search/ # Search engines
│ │ ├── hybrid.py # Semantic + BM25 with RRF fusion
│ │ └── fts.py # SQLite FTS5 wrapper
│ ├── storage/ # Data layer
│ │ ├── vault.py # Vault + VaultManager
│ │ ├── schema.py # SQLite schema with FTS5 triggers
│ │ ├── chromadb_backend.py# ChromaDB wrapper
│ │ └── gc.py # Garbage collection
│ ├── memory/ # Memory stack
│ │ ├── layers.py # L0-L3 memory layers
│ │ └── token_budget.py # tiktoken counting, scoring, dedup
│ ├── graph/ # Knowledge graph
│ │ └── knowledge_graph.py # Temporal KG with SQLite
│ ├── hooks/ # Git integration
│ │ ├── hook_manager.py # Content-aware importance scoring
│ │ └── git_hooks.py # Post-commit/merge hook installer
│ └── mcp/ # MCP server
│ └── server.py # 12-tool JSON-RPC MCP server
├── tests/ # Test suite (69 tests, ~500 lines)
│ ├── test_vault.py
│ ├── test_chunker.py
│ ├── test_search.py
│ ├── test_token_budget.py
│ ├── test_knowledge_graph.py
│ ├── test_hooks.py
│ ├── test_mcp.py
│ └── test_secret_scanner.py
├── benchmarks/
│ └── compare_mempalace.py # Head-to-head benchmark script
├── dashboard/ # Next.js web UI
│ └── src/
│ ├── app/ # Pages: chat, search, vaults, KG, settings
│ ├── components/ # Sidebar, badges, stat cards
│ └── lib/ # API client and types
└── pyproject.toml
Configuration
EngramKit works out of the box with sensible defaults. To customize, create ~/.engramkit/config.toml:
chunk_size = 800
chunk_overlap = 100
min_chunk_size = 50
search_n_results = 5
semantic_weight = 0.7
lexical_weight = 0.3
gc_retention_days = 30
[token_budget]
l0_max_tokens = 150
l1_max_tokens = 1000
l2_max_tokens = 2000
l3_max_tokens = 4000
Development
# Clone and install in dev mode
git clone https://github.com/user/engramkit.git
cd engramkit
pip install -e ".[dev]"
# Run tests
pytest
# Lint
ruff check engramkit/
Credits
- MemPalace for the original architecture, proving that verbatim storage with a 4-layer memory stack works, and inspiring this project.
- ChromaDB for embedding storage and semantic search.
- SQLite for the metadata spine, FTS5, and knowledge graph.
- tiktoken for accurate token counting.
License
MIT License. See LICENSE.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file engramkit-0.2.4.tar.gz.
File metadata
- Download URL: engramkit-0.2.4.tar.gz
- Upload date:
- Size: 547.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
461a503aa5c822e23526ebbd87136fd39d492cdf225ab5ae466d036d44106aae
|
|
| MD5 |
e617d1bd3050ac8cf8f2196e09ce20e9
|
|
| BLAKE2b-256 |
f07e2543218b45914a8d5bced8d6b945ad8bf147995cf2ffdd73c12ac69f5aab
|
Provenance
The following attestation bundles were made for engramkit-0.2.4.tar.gz:
Publisher:
release.yml on hmqiwtCode/engramkit
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
engramkit-0.2.4.tar.gz -
Subject digest:
461a503aa5c822e23526ebbd87136fd39d492cdf225ab5ae466d036d44106aae - Sigstore transparency entry: 1314602114
- Sigstore integration time:
-
Permalink:
hmqiwtCode/engramkit@5411db92d7c5a55f5ee40e3c3fb3244bbb113852 -
Branch / Tag:
refs/tags/v0.2.4 - Owner: https://github.com/hmqiwtCode
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@5411db92d7c5a55f5ee40e3c3fb3244bbb113852 -
Trigger Event:
push
-
Statement type:
File details
Details for the file engramkit-0.2.4-py3-none-any.whl.
File metadata
- Download URL: engramkit-0.2.4-py3-none-any.whl
- Upload date:
- Size: 570.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7278ff38818ae65b6e4b19193f3374fa56cfbaf1532eeb07db4e82125f068cfb
|
|
| MD5 |
e8cc75ffc68c42db9fca64c53870881b
|
|
| BLAKE2b-256 |
b3fdff7711433a585cf9a9084d25819d63bb3af93385ddbfc9d869768b400814
|
Provenance
The following attestation bundles were made for engramkit-0.2.4-py3-none-any.whl:
Publisher:
release.yml on hmqiwtCode/engramkit
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
engramkit-0.2.4-py3-none-any.whl -
Subject digest:
7278ff38818ae65b6e4b19193f3374fa56cfbaf1532eeb07db4e82125f068cfb - Sigstore transparency entry: 1314602205
- Sigstore integration time:
-
Permalink:
hmqiwtCode/engramkit@5411db92d7c5a55f5ee40e3c3fb3244bbb113852 -
Branch / Tag:
refs/tags/v0.2.4 - Owner: https://github.com/hmqiwtCode
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@5411db92d7c5a55f5ee40e3c3fb3244bbb113852 -
Trigger Event:
push
-
Statement type:







